上一讲我介绍了三段分解法,教你把“10 年成为大牛”这个宏大的目标,分解成 1~2 个月的可落地计划,然后再按周来执行实际的行动。
但是,不同级别的核心要求是不一样的,晋升时评委的考察重点也不一样,所以在成长过程中,我们主要提升的技术维度也在发生变化。
一般来说,P5/P6/P7 主要提升技术深度,P7/P8 主要提升技术宽度,P8/P9 主要提升技术广度。(我在第 11 讲和第 16 讲分别以前端和 Java 后端为例,解释了这三个维度的区别。)
这三个不同的技术维度,分别适合用不同的方法来提升,这一讲我就会为你一一介绍,让你的学习更有针对性,在回答晋升评委提问的时候也能做到游刃有余。
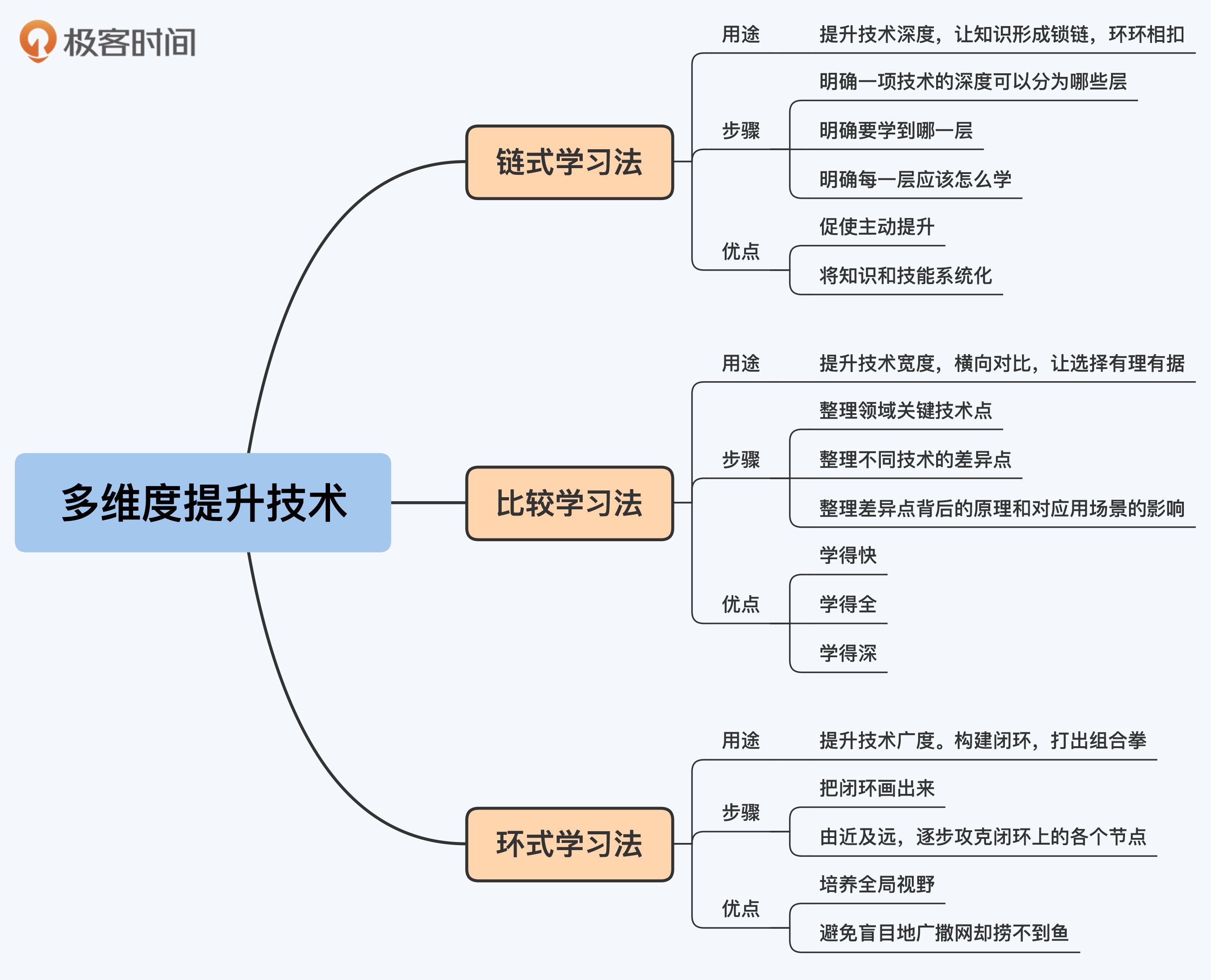
链式学习法:提升技术深度
提升技术深度,最好使用链式学习法。
如果你参加过晋升答辩,一定经历过评委的“追命连环问”,比如:
- 你在讲解 PPT 的时候提到,某个项目使用了 Netty 技术,评委首先会问你 Netty 的一些技术点;
- 当你回答说 Netty 的本质是 Reactor 网络模型时,评委又会问你 Reactor 网络模型的原理;
- 当你回答说 Reactor 的基础是 Java NIO 的时候,评委又会问你 Java 的 NIO/BIO 的技术细节;
- 当你回答说 Java 的 NIO 在 Linux 平台上是基于 epoll 来实现时,评委又问你 Linux 的 epoll/select 等的原理。
- ……
面对这种“打破砂锅问到底”的方式,如果平时没有充足的准备,你很可能会卡住。
所谓“链式学习法”,顾名思义,就是学习的过程好像从水里拉起一根链条,拉出一环后面又接着一环,最后将整个链条全部拉出来。
当知识联结成锁链,环环相扣,你对技术的理解就很透彻,评委问到底,你就能答到底。
但是知识的锁链不是胡乱连接的,环环相扣的方式很有讲究。常见的方式有两种:
第一种是自顶向下、层层关联,打通一项技术的领域分层。
第二种是由表及里、层层深入,打通一项技术的细节分层。
以 Netty 网络编程为例,相关领域一共可以分为 6 层,要么上层依赖下层,比如 Netty 依赖 Java 网络编程,Java 网络编程在 Linux 上又依赖 Linux 提供的网络编程接口;要么下层是上层的应用和实现,比如 TCP/IP 是原理,而 Linux 网络调优和工具是 TCP/IP 的具体应用。它的领域分层图如下所示:
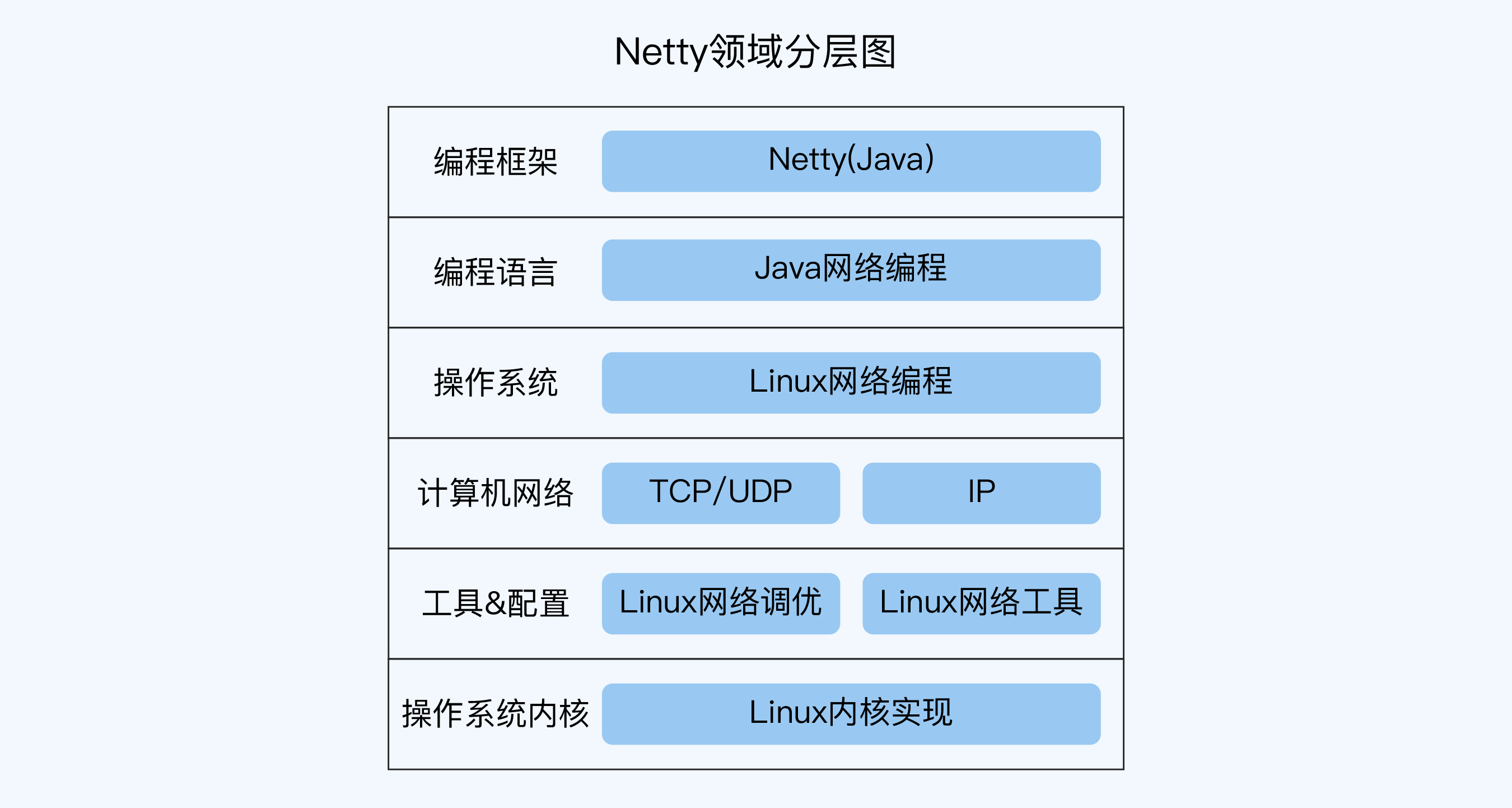
注:
以上图示仅为示例,你需要根据自己的实际工作情况来分析。如果你是在 Windows 平台上做开发,那么上图“操作系统”这一层就要改为“Windows 网络编程”,“工具 & 配置”这一层就要改为“Wireshark”之类的。
具体分层关系并没有业界统一的标准,比如“工具 & 配置”这一层,如果你认为应该放在“计算机网络”那一层的上面,其实也是可以的。
同样以 Netty 网络编程为例,技术细节可以分为 4 层,它的细节分层图如下所示:
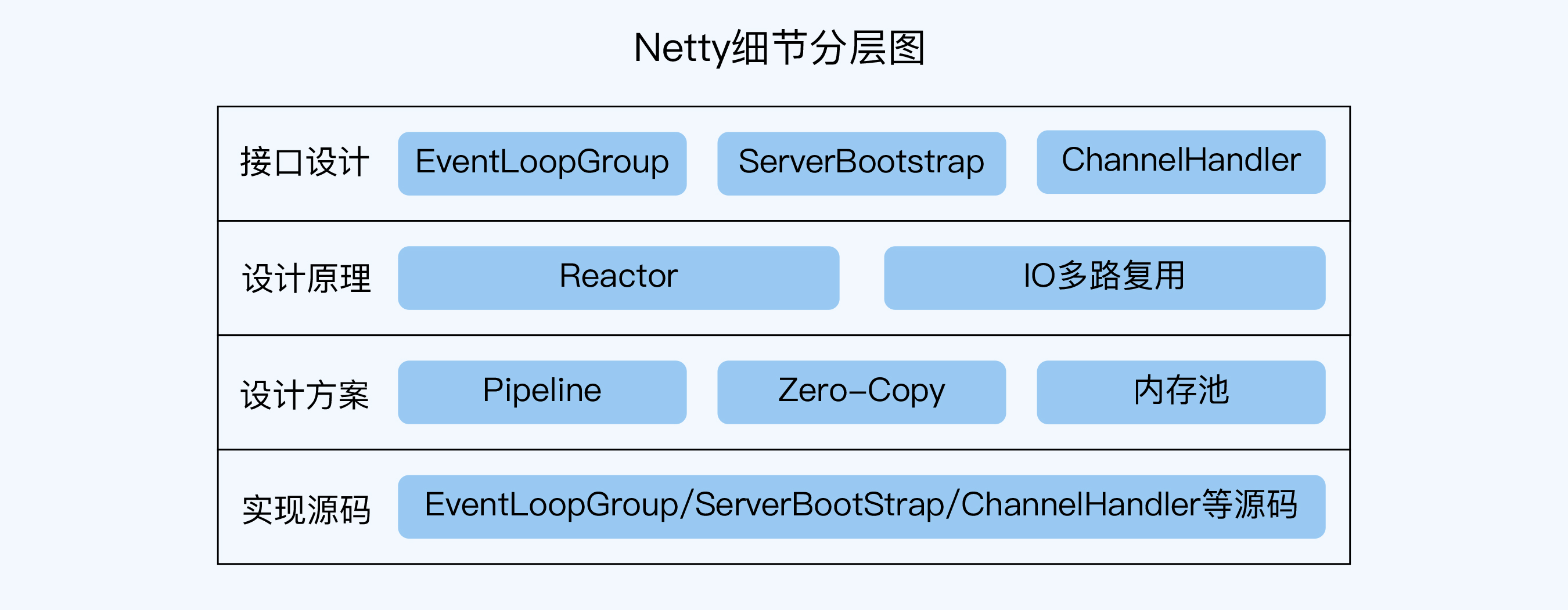
链式学习法的步骤
链式学习法的第一步,就是要明确一项技术的深度可以分为哪些层。
具体来说,就是画出“领域分层图”和“细节分层图”。一开始你可能会觉得画不出来,这恰恰说明你对深度的理解还不够,而尝试画图本身就是一个梳理结构、强化认知的过程。
画出了两张图之后,第二步就是要明确你自己要学到哪一层。
学得太浅,达不到提升深度的目的;学得太深,又会耗费太多的时间和精力。以 Netty 网络编程为例,从我自己实践和指导别人的经验来看,领域分层图的 6 层不用都学,大部分人学个 3~5 层就够了;不过细节分层图的 4 层,还是建议你每一层都学。
确定学到哪一层之后,第三步就是要明确每一层应该怎么学。
在领域分层图中,越往上越偏应用,实际工作中用得越多,越往下越偏原理(包括相关的工具和配置),实际工作中用得越少。所以总的原则是,在上层投入更多时间,更关注细节和熟练使用,在下层投入相对少的时间,更加关注原理和简单应用。
比如对于 Netty 网络的领域分层图,如果你不是 Netty 项目的开发人员,而是只想使用 Netty 来搭建自己的系统,那么“Linux 网络编程”这一层,你只要掌握 select/epoll 等技术原理和优缺点就行了,epoll 提供的 API 你有时间可以大概看看,没时间不看也可以;但是对于 Netty 本身提供的 API,则是越熟练越好。
在细节分层图中,你需要详细地学习每一层。要注意的是,对于“实现源码”这一层,你不需要去掌握每一行源码,只要掌握关键源码就行了,也就是和设计原理以及设计方案相关的源码。
链式学习法的优点
链式学习法主要有两个优点:
1. 促使我们主动提升
大部分人在实际工作中,很多技术都只接触到了领域分层图和细节分层图中的前 2 层,没有进一步地去了解。
而如果采用链式学习法,你就会意识到,使用一项技术完成了工作,并不意味着你就完全掌握了这项技术。你还需要把刚刚自己用到的技术作为切入点,画出完整的领域分层图和细节分层图,然后逐一攻破,这样才能提升深度,达到精通水平。
2. 将知识和技能系统化
明确知识和技能点之间的关联关系,有助于更好的理解和应用这些知识和技能。
例如,如果我们要在 Linux 平台上基于 Netty 开发并发 10 万连接的高性能服务器,既要深入掌握 Netty 的技术细节,又要深度掌握领域深度相关的技术,包括:
Netty 技术细节:需要设置 Netty 的相关参数(ChannelOption.SO_BACKLOG,ChannelOption.TCP_NODELAY,ChannelOption.SO_REUSEADDR 等)。
Java 网络编程:调试的时候需要知道 Java 的网络编程 API 等等。
Linux 网络工具:需要使用 Linux 网络工具定位问题。
Linux 操作系统配置:需要修改 Linux 的最大文件句柄数、需要优化 Linux 的 TCP/IP 参数(net.ipv4.tcp_tw_reuse,net.ipv4.tcp_keepalive_time 等)。
只有使用链式学习法,你才能系统地了解到这些关联的知识和技能,以及如何将它们串起来。
链式学习法小结
现在,我们回顾一下链式学习法的重点:
- 链式学习法是让知识形成锁链,环环相扣,主要用来提升技术深度。
- 链式学习法的步骤包括:明确一项技术的深度可以分为哪些层,明确要学到哪一层,明确每一层应该怎么学。
- 链式学习法的优点有:促使我们主动提升,将知识和技能系统化。
比较学习法:提升技术宽度
提升技术宽度,最好使用比较学习法。
如果你有过晋升 P7 或者更高级别的经历,肯定被问到过大量跟“Why”有关的问题,比如:
为什么选择 Redis,为什么不用 Memecached?
为什么选择 MySQL 而不是 Redis?
选择 Flink 的理由是什么?(除了 Flink 本身的技术特点外,还需要你回答为什么选择 Flink 而不是 Spark 或者 Storm。)
……
这些问题大部分都是考察你思考、判断和决策的逻辑和过程。如果你只有技术深度而没有技术宽度,这时就会陷入窘境:单个技术细节你都很熟悉,但是却无法解释为什么用这个,而不用那个。
所谓比较学习法,就是横向比较同一个领域中类似的技术,梳理它们异同,分析它们各自的优缺点和适用场景。
这样你就能加深对整个领域的理解,评委问的每个为什么,你都能回答得有理有据。
比较学习法的步骤
比较学习法的具体操作步骤如下:
先用链式学习法掌握某个领域的一项技术,将这个领域的关键技术点整理成表格。
基于整理好的技术点,学习这个领域的另一项技术,将它们在技术点上的差异整理成思维导图。
找出差异较大的技术点,将背后的原理和对应用场景的影响整理成表格。
接下来,我以缓存领域的 Memcache 和 Redis 为例,说明一下比较学习法的用法。
先用链式学习法掌握 Memcache 技术,整理出缓存领域的 6 个关键技术点。
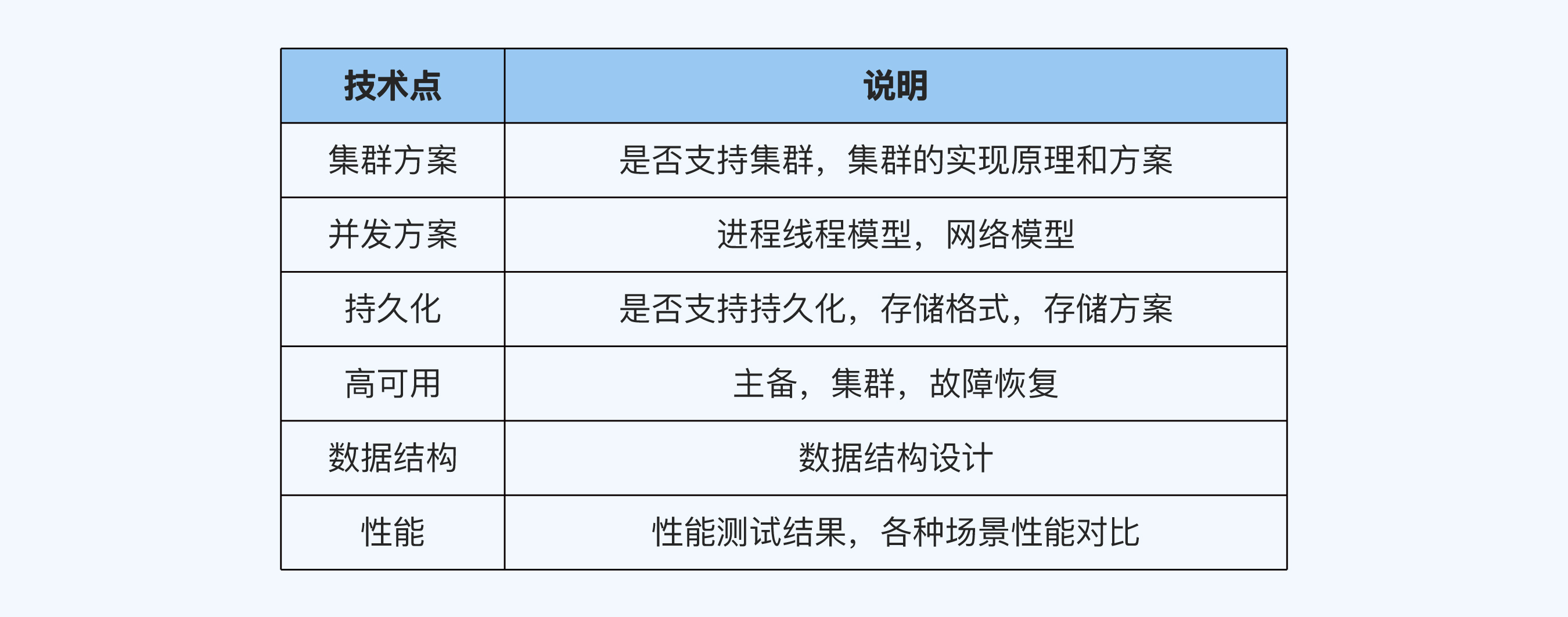
基于这 6 点快速掌握 Redis 技术,整理出 Memcache 和 Redis 在这些点上的差异。
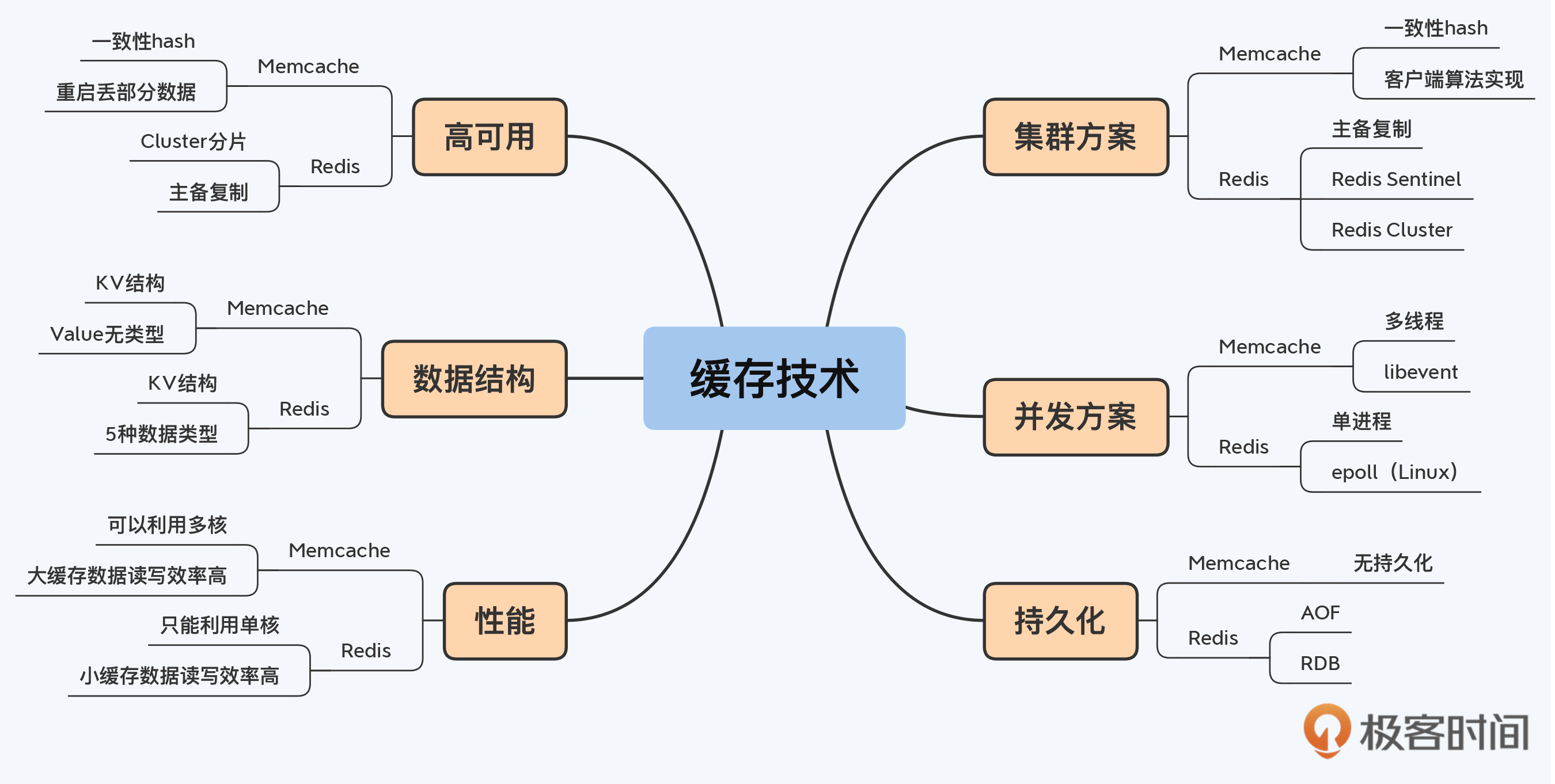
找出差异较大的技术点,包括并发方案、数据结构、高可用和持久化,整理出它们背后的原理和对应用场景的影响。
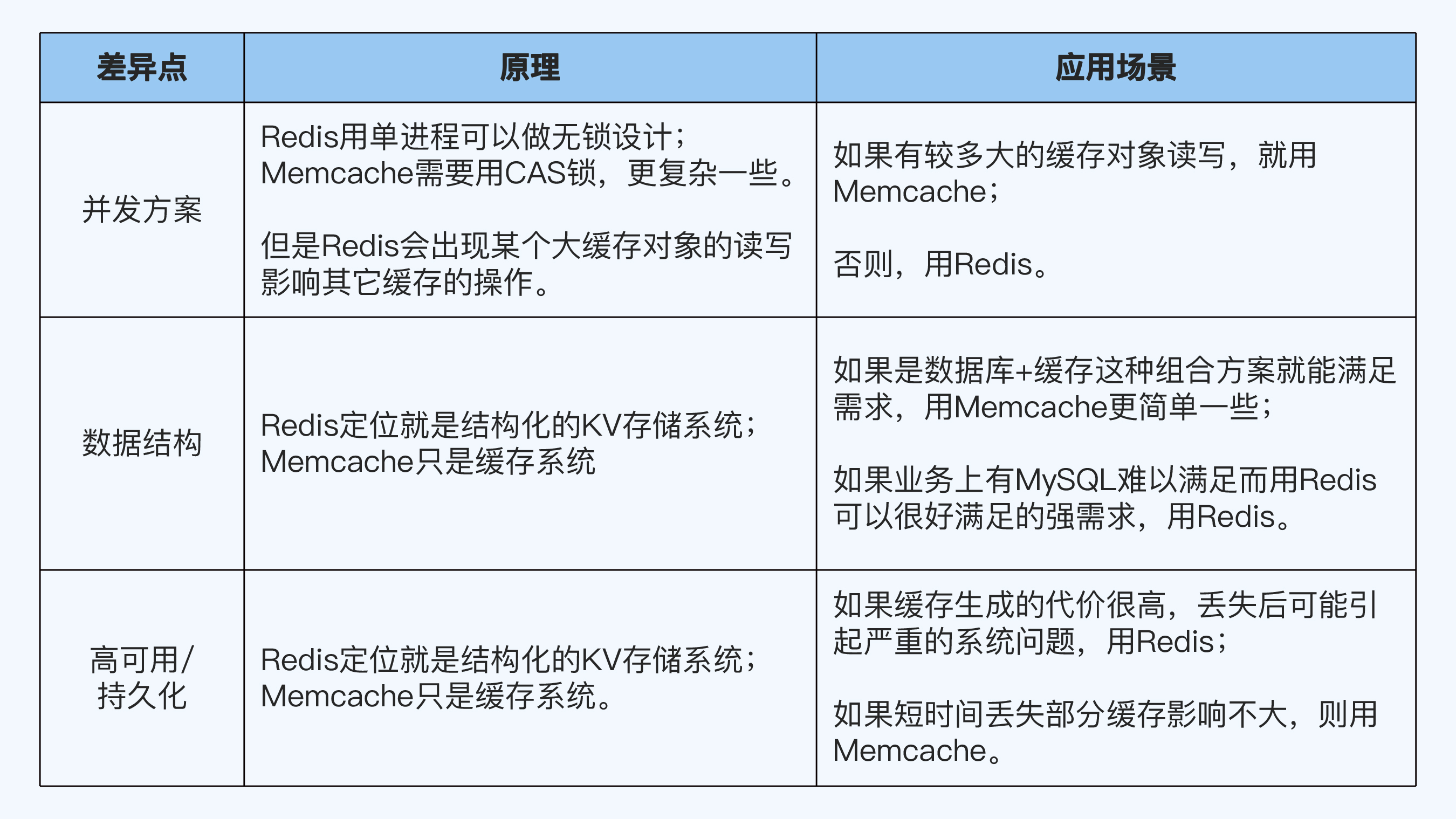
注:表格内容仅为示例,实际内容不止这么多,如果你有兴趣,可以上网搜索或者自行补充完整。
比较学习法的优点
比较学习法主要有三个优点:
1. 学得快
同一个领域的技术在功能上大都是类似的,区别往往在于实现方案和细节。所以当你掌握了一项技术之后,再去同一个领域的另一项技术,就不需要从 0 开始了,因为基础的部分你已经学会了,只要重点关注它们的差异点就能够快速掌握。
2. 学得全
整理关键技术点和制作思维导图的过程,会促使你把一个领域的技术体系化,更全面、更系统地掌握这个领域。
3. 学得深
从差异点到背后的原理再到应用场景的思考过程,会让你对技术的取舍之道理解得更深,在每一次技术选择时都能给出让人信服的理由。
比较学习法小结
现在,我们回顾一下比较学习法的重点:
比较学习法是横向对比,让选择有理有据,主要用来提升技术宽度。
比较学习法的步骤包括:整理领域关键技术点,整理不同技术的差异点,整理差异点背后的原理和对应用场景的影响。
比较学习法的优点有:学得快,学得全,学得深。
环式学习法:提升技术广度
提升技术广度,最好使用环式学习法。
很多人一听要提升广度,就以为学得越多越好,想到什么牛就学什么,看到什么热就追什么。学了一段时间,感觉学了很多,但好像啥也不会,网撒得很广,却没捞到几条鱼。
所谓环式学习法,就是构建一个完整的闭环过程,将多个领域的“鱼”一网打尽。
技术上常见的闭环是功能环,代表某个功能的处理过程。以一个最简单的“用户登录”为例,如果它的实现方式是前端在手机 App 上用做登录页面,后端用了微服务架构来存储,那么就可以构建这样一个功能环:

注意:
上图仅为示意,你可以根据实际情况自己完善,比如拆分为更多环,或者每个环增加更多的技术点。
上图我是用 PPT 画的,你也可以根据自己的喜好采用其他画图工具,比如 UML 类工具。
这里要说明一点,环式学习法更加适合业务系统相关的技术人员,而不太适合中间件(数据库、缓存、消息队列和服务中心等)相关的的技术人员,因为中间件的技术更加专注于深度和宽度,和具体的业务关系不大,对技术广度的要求并不高。
当然,如果你已经达到了 P8+/P9 这个级别,无论什么领域,都可以采用环式学习法来学习跨领域的技术。
除了功能环以外,还有很多构建闭环的思路,比如业务上常见的“业务环”,它代表某个业务的处理步骤,以及管理上常见的“流程环”,它代表某件事情的处理步骤。
所以,环式学习法不但可以用来提升技术广度,也可以用来提升业务能力和管理水平。
环式学习法的步骤
环式学习法的第一步,就是把闭环画出来。
具体的画法是将完整的闭环分为几个关键的环节,然后标出每个环节的关键内容。
就拿“用户登录”这个功能环来说,它可以分为前端、客户端、网络层、机房入口、Nginx、用户中心、安全中心和数据中心,总共 8 个环节;每个环节又会涉及不同的技术,比如客户端涉及 JsBridge 和 OkHttp,用户中心涉及微服务、MySQL 和 Redis 等,总共涉及的技术有 18 项。
通过这么一个简单的功能环,你就可以看出技术广度的边界和范围;而且这些技术都是业务上实际用到的,你完全不用担心自己是没有目的地乱学。
环式学习法第二步,就是由近及远,逐步攻克闭环上的各个节点。
就算是同一个闭环,不同领域的人学习顺序也是不同的。还是以用户登陆这个功能环为例,前端的人先需要学客户端的 JsBridge 和 OkHttp 等知识,然后再去学服务端相关的知识;而服务端用户中心的人,需要先学 Nginx 和安全中心相关的知识,之后再逐步扩展到客户端和前端。
通常来说,职业等级越高,技术广度的要求也越高,所以功能环上要求掌握的相关技术也越多。
对于单个技术,你还是需要用链式学习法来学习,但是因为数量太多,全部严格按照链式学习法的要求来学是不太现实的。我的建议是,可以先不去研究源码,只要学习接口设计、设计原理、设计方案这 3 层就行了;在合适的时候或者有时间的时候,可以看看核心源码加深理解。
提升业务能力也很重要
很多技术人员有一个误区,认为业务设计是产品经理的事情,产品经理设计好了,技术人员再把自己负责那部分做好就行了。
这种想法会让你在工作中非常被动,而且可能吃大亏。常见的吃亏场景包括:
讨论需求的时候,因为不懂业务,就算产品的业务需求不合理、实现代价很高,你也发现不了。结果到了设计甚至是编码阶段,你才发现自己做得累死累活,效果还不好。
处理线上故障的时候,因为不熟悉业务,只能被动接受别人的分析和推断,很容易背锅。
因为不熟悉业务,无法承担整体需求分析和方案设计这种任务,导致个人能力得不到锻炼,失去很多晋升机会。
无论是前端、客户端还是服务端的技术人员,最好都花点时间,通过业务环来了解业务的整个流程。
以下是用户登录的业务环,供你参考。
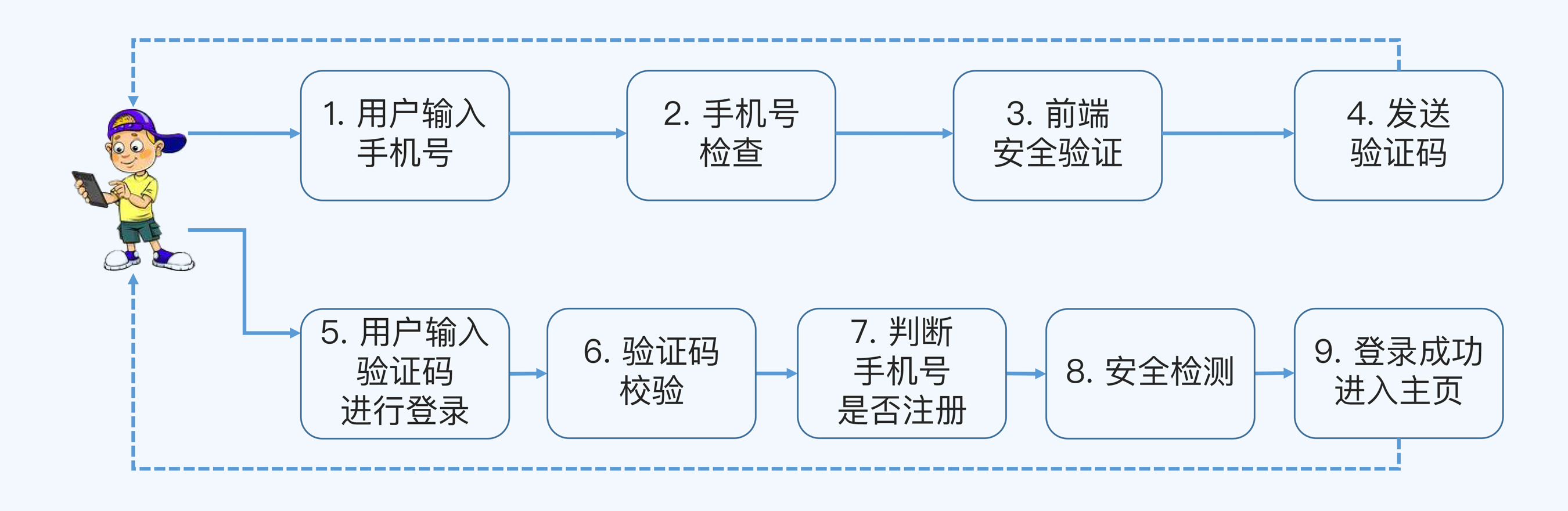
注意:上图仅为示例,省略了很多分支和细节,实际的业务流程图比这个要复杂,你可以直接参考产品经理的需求文档。
环式学习法的优点
环式学习法有两个优点:
1. 培养全局视野
在画出完整闭环的过程中,你可以端到端地了解全流程涉及哪些系统或者模块,每个模块的关键技术是什么,从而培养出全局的视野和能力。
2. 避免盲目地广撒网却捞不到鱼
环式学习法划定的范围是实际工作的闭环,能够形成一套有效的组合拳,而不是东一榔头西一棒槌的胡乱搭配,能够大大提升学习效率。所以你只要对照环来提升就可以了,不用再担心广撒网却捞不到鱼了。
环式学习法小结
现在,我们回顾一下环式学习法的重点:
环式学习法是构建闭环,打出组合拳,主要用来提升技术广度。
环式学习法的步骤包括:先把闭环画出来,然后由近及远,逐步攻克闭环上的各个节点。
环式学习法的优点有:培养全局视野,避免盲目地广撒网却捞不到鱼。
思考题
这就是今天的全部内容,留一道课后思考题给你吧。在你的面试或者晋升的过程中,有没有因为某个专业方面的问题没答上来而留下遗憾的经历?学完今天的内容后,你觉得可以用什么方式来学习,避免以后再留下类似的遗憾呢?
关于学习方法,最近看过一本书,书中有些学习方法别具一格,颠覆认知,书名——《认知天性:让学习变得轻而易举的心理学规律》。
这本书介绍了各种高效学习的方法,其中有几种方法,比较颠覆认知,书中认为学习时...
作者回复: 我最近刚看完这本书,里面提到的学习方法我自己其实一直就是这样做的。我会3~4个主题同时进行学习,每个主题每次都学30分钟左右,一段时间后又回过头来复习加深一下。
例如我最近同时在学:ClickHouse、Redis专栏、推荐系统专栏、朝鲜战争、认知天性。
怎么画领域分层图
在第 19 讲中,我为你介绍了用于提升技术深度的链式学习法。链式学习法的第一步,就是要明确一项技术的深度可以分为哪些层,并画出领域分层图和细节分层图。
其中细节分层图基本上可以按照固定的模板去画(接口设计、设计原理、设计方案和实现源码),但是领域分层图并没有统一的模板,因为不同技术领域的分层方式可能会有很大差异。
我之前没有详细讲解领域分层图的画法,而是跟你说“尝试画图本身就是一个梳理结构、强化认知的过程”。
因为我想强调的是:画图本身的技巧和效率并没有那么重要,对你成长帮助最大的,是为了画出这张图而去整理、思考和探索的过程。
不用担心画得不准确
你可能会担心,如果领域分层图画得不准确怎么办?
首先,领域分层图本来就是需要迭代优化的,很少有人一开始就能画得非常准确。
实际的情况是,你先画一个初稿,然后通过整理、思考和探索,对相关技术的理解更加深刻和全面,发现原来存在的一些问题,比如分层关系不合理、某一层遗漏了一些技术点等,然后再进行修改,经过不断地迭代优化,最终得到比较准确的版本。
其次,领域分层图就算画得不够准确,你学习的过程也没有白费。
一般情况下,你不会错得太离谱,你学到的内容就算跟当前想学的技术关联没有那么强,但下次提升另一项技术的深度时,很可能就用上了。而且随着你积累的经验越来越丰富,以后再画领域分层图的时候就会越来越熟练。
当然,你可能过几个月就要参加晋升了,没有多少时间用来慢慢试错迭代;或者你真的对自己的探索能力没什么把握,必须掌握一个具体可靠的画图方法才能放心。
考虑到这些情况,这一讲我就分享一下画领域分层图的具体经验吧。
拿来主义
最简单的方法当然就是拿来主义,你可以找团队内部熟悉某项技术的高手来帮你画,也可以根据网上搜到的相关文章或者思维导图来整理。
这种方法的好处是耗时少,也不会走偏,但是它也有缺点。
首先,你自己的理解深度还是不够,因为你缺少了自己去探索的过程。
其次,对外界的依赖太高,你并不是刚好每次都能找到这样的高手,而网上的资料也存在不完整、老旧过时甚至错误的风险。
最后,这种方法往往只适合热门、成熟的技术领域,而对于冷门、新兴的技术领域,你能拿来的内容非常少,还是得靠自己去产出。
画领域分层图的步骤
那么,假设你对某个技术完全不了解,团队里也没有人熟悉,在网上又只能找到非常基础的资料,这个时候,你要怎么画领域分层图呢?
以下是我最近学习 ClickHouse 时的画图过程,供你参考。
第一步,搜集资料。
有官方文档的情况下,先看官方文档是最保险的,比如我看的就是 ClickHouse 的英文官方文档,它已经很全面了。
你可能会有疑问,如果我想学的技术不像 ClickHouse 这样有比较成熟的官方文档,该怎么办呢?
我的想法是,成熟的项目一定有成熟的文档。如果一个项目没有官方文档或者官方文档很烂,只能靠你自己看代码去摸索,那么我建议你先不要去学。
首先,这样学效率太低了;其次,这说明项目本身就有问题,要么是还不成熟,容易误导你,要么就是没什么人维护,出了问题也没人管你,无论哪种情况你都很容易踩坑。
当然,不同的学习对象有不同形式的资料,但不管什么类型的资料,我推荐你首先都要看权威资料,包括官方文档、经典书籍、研究论文等,比如 ClickHouse 的官方文档、《UNIX 环境编程》《TCP/IP 详解》和谷歌的大数据论文等,都属于各自领域的权威资料。
第二步,挖掘技术点。
我根据官方文档中的内容,挖掘出了一些相关的技术点。
ClickHouse® is a column-oriented database management system (DBMS) for online analytical processing of queries (OLAP).
Why Column-Oriented Databases Work Better in the OLAP Scenario?
Column-oriented databases are better suited to OLAP scenarios: they are at least 100 times faster in processing most queries.
这两段话涉及两个技术点,列式数据库(Column-Oriented Database)和 OLAP。
There are two ways to do this:
A vector engine. All operations are written for vectors, instead of for separate values. This means you don’t need to call operations very often, and dispatching costs are negligible. Operation code contains an optimized internal cycle.
Code generation. The code generated for the query has all the indirect calls in it.
而这段话又涉及两个技术点,矢量计算(Vector)和代码生成(Code Generation)。
你可以看到,光是简单的一篇 ClickHouse 介绍文档,我已经挖掘出了至少 4 个关联的技术点。
第三步,针对技术点学习。
比如你已经挖出了列式数据库这个技术点,但是没有相关的积累,那么你可以立刻开始先学跟它相关的内容,也可以初步看完 ClickHouse 的资料之后再来学习。具体采用哪种方式,根据你的个人习惯来选择就行了。
我看到列式数据库这个技术点之后,就在网上找到了一篇不错的文章,里面又引出了 HBase、NSM、DSM 等相关的概念。当然,只看这一篇文章肯定是不够的,我会结合多篇资料,最后形成综合的理解。
第四步,画出初稿。
学习了解了这些重要的技术点之后,我尝试整理了 ClickHouse 领域分层图的初稿,如下所示:
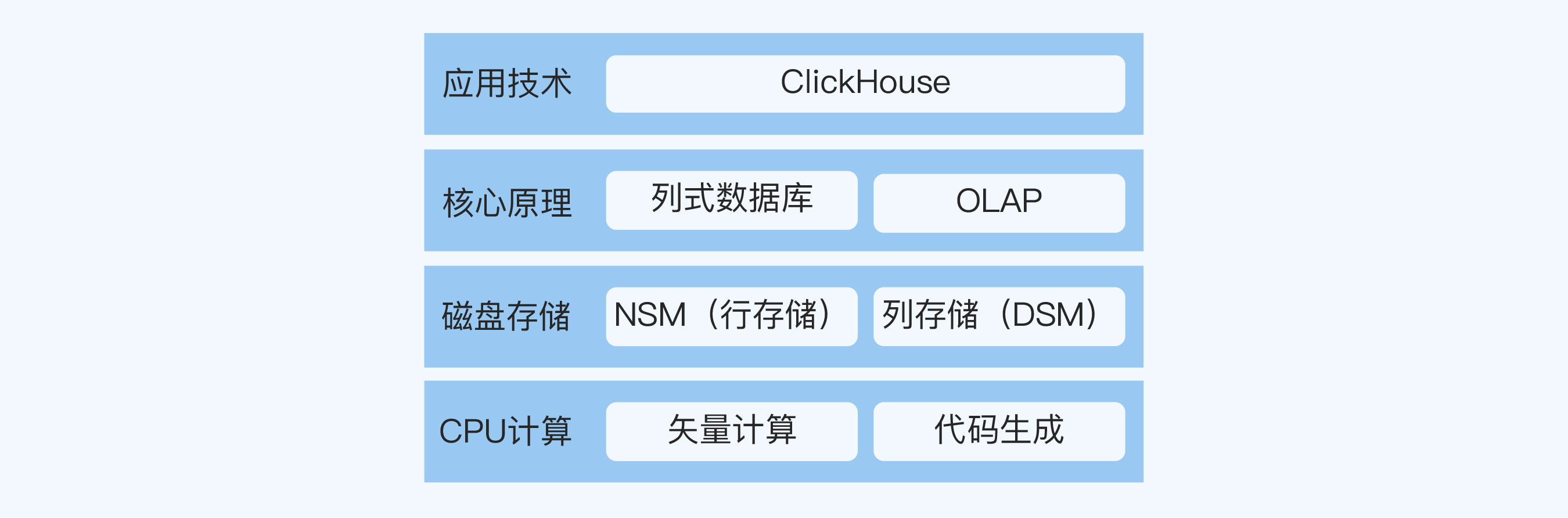
第五步,迭代优化。
你可能会觉得这张图好像比较简单。不过没关系,在阅读资料和思考的过程中,我会继续迭代优化这张图,比如之后还可能加上矢量计算相关的 CPU 结构。
即使是这张简单的领域分层图,内容已经足够我学上几个星期了,我会以这张图为基础先开始学,学习的过程又会拓展我对这个领域的认识,促使我继续迭代优化。
当我把图片上的内容学完之后,我可以通过培训的方式给团队讲解 ClickHouse,回答他们的疑问,借助群众的力量来帮助自己加深理解,进一步迭代优化这张图。
小结
现在,我们回顾一下这一讲的重点内容。
- 画领域分层图的技巧和效率并没有那么重要,对你成长帮助最大的,是为了画出这张图而去整理、思考和探索的过程。
- 画领域分层图最简单的方式是拿来主义,找团队内部熟悉某项技术的高手来帮你画,或者根据网上搜到的相关文章或者思维导图来整理。
- 如果拿来主义不能满足你的需求,或者你对自己有更高的要求,可以通过 5 个步骤来画领域分层图:搜集资料,挖掘技术点,针对技术点学习,画出初稿,迭代优化。