内存使用
计算机是如何工作的
计算机工作是一个取指执行的过程,将程序放到内存中,然后开始取指执行,从内存中进行取指,然后放到CPU中进行执行,再取指执行,这样计算机就开始工作了。
计算机工作示意图如下所示:

从上图中可以看到,程序需要放到内存中,然后能从内存中进行取指操作,说明内存已经开始使用了。
如何让程序放到内存中
从上面的小节中可以看出,程序会被编译成汇编指令,然后放到内存中,如果程序可以跑起来的话,内存就使用起来了。
下面我们来看一段程序:

从图中可以看出,main函数是一个C函数,经过编译后,成为右边的汇编指令,其中_entry表示入口地址,而编译完成后_main也变成一个地址,这里假设是40,是相对于0的偏移,则call _main就变成了call 40,以此在内存中从0开始找到地址40处,就是main函数的开始地址。
这时,我们将编译成的汇编指令放到内存中,就成为下图所示:
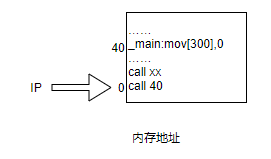
从图中可以看出,将编译出来的汇编程序放到0地址处开始,然后IP指向0地址处,取指执行call 40,表示main函数的第一条指令放到内存地址为40的位置,那么要想main函数的入口地址也就是第一条指令地址位于40处,则_entry就得放在0地址处,这样将IP指向0的时候就会执行call 40,找到物理内存中main函数的入口地址,进而取指执行main函数。
需要注意的是,call 40这条汇编指令放到内存中的任何地址处,40这个值是不会改变的,也就是说无论将call 40放到何处,都会跳转到40地址处去执行,往地址总线上发送40,然后到内存中寻址地址40。
那么有几个问题:
1、0地址处是想用就能用的吗?
2、0地址处就一定是空闲的吗?
3、当我们的main函数在使用0地址处时,其他程序也要使用0地址处,这样会产生冲突吗?
对于上面的3个问题,答案其实很明显,0地址处当然不是想用就能用的,因为我们的0地址处存放的是操作系统,这就表明了应用程序不能放到0地址处。
那么不能放到0地址处,我们的应用程序要放到什么位置呢?
应该在内存中找一处空闲区域,将程序放到空闲区域中,如下所示:

上图表示,在内存区域中1000开始的地址空间是空闲的,于是将main程序从内存地址空间1000处开始存放。
这又会引出一个问题,上面我们说到,call 40会往地址总线上发送40地址,然后会到内存中寻找40地址处执行,那么我们将IP赋值为1000,取出指令call 40后,又会去寻找40地址执行,就无法找到main函数的初始地址1040了。
所以,我们要修改call 40汇编指令中的40地址,这里40地址是一个相对地址,相对于_entry程序入口来说的,就是我们常说的逻辑地址,因此要想main函数正常执行,就要将逻辑地址转换成物理地址。
那么,针对上面的程序,需要将40地址修改为1040地址,这时IP就会被赋值为1040,会跳转到main函数的初始地址去执行,如图所示:

将40地址转换成1040地址的过程——重定位过程。
重定位的时机
编译时重定位
编译时重定位,需要了解在程序编译时哪些地址是空闲的,但是有些地址在编译时是空闲的,到了程序执行时又已经被其他程序占用了,所以编译时重定位是不建议采用的。
载入时重定位
当载入时,发现内存地址1000处是空闲的,将所有程序地址都加上1000,根据当前内存中的空闲地址作为基址,然后将程序地址都加上基址。
缺点:载入重定位的程序一旦载入内存后,就不能移动。
但是,程序在载入内存之后,会进行移动(PS:主要和CPU、进程切换有关。)

从上面的图可以看出,当我们的程序由于各种原因被阻塞的时候,对应的内存中的进程会进入休眠状态,这个时候为了计算机的使用需要进行交换,将睡眠的进程从内存中换出,而将磁盘中已经准备好的进程换入到内存中,图中睡眠状态的进程1和进程3换出到磁盘中,而把磁盘中已经准备好的进程2换入到内存中。
会有这样一种情况,进程1在经历了一次换出再换入的过程后,在换出之前,进程1中的地址是call 1040,在重新换入内存后还是call 1040,但是这个时候进程1已经放到了以2000为基址的空闲地址中,这个时候如果继续按照call 1040来执行,就会执行1040地址内容,但是现在的1040地址是属于另外一个进程的,根据进程之间不能相互影响的规则,这样做是有问题的。
如图所示:

从上图可以看出,当将进程从磁盘换入到内存中时,由于是载入时重定位,所以进程中仍然是call 1040,这个时候会将IP置为2000,然后取指call 1040,就会去找到1040地址,而这个时候1040地址中存放的是进程2的内容,这样就违反了进程之间不能相互影响的原则,因此不推荐使用载入时重定位。
运行时重定位
运行时重定位是在运行每条指令的时候才完成重定位操作。
如图所示:

根据上图,不管base在内存中的任何地方,main函数中的指令都是call 40,但是当我们开始执行程序时,会出现如下的过程:

上图就很好的体现了运行时重定位的过程。
问题:base基址存放在哪里?怎么去找到基址?
答: 由于进程在执行过程中发生了变化,其中就包括了base基址,所以base基址会放到进程控制块PCB中,会一直存放在PCB中。
上述例子中进程1换出到磁盘时PCB中的base是1000,当从磁盘换入到内存中时,PCB中的base变成了2000。
【PCB定义 linux-2.6/include/linux/sched.h】
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
struct thread_info *thread_info;
atomic_t usage;
unsigned long flags; /* per process flags, defined below */
unsigned long ptrace;
int lock_depth; /* Lock depth */
int prio, static_prio;
struct list_head run_list;
prio_array_t *array;
unsigned long sleep_avg;
unsigned long long timestamp, last_ran;
int activated;
unsigned long policy;
cpumask_t cpus_allowed;
unsigned int time_slice, first_time_slice;
#ifdef CONFIG_SCHEDSTATS
struct sched_info sched_info;
#endif
struct list_head tasks;
/*
* ptrace_list/ptrace_children forms the list of my children
* that were stolen by a ptracer.
*/
struct list_head ptrace_children;
struct list_head ptrace_list;
struct mm_struct *mm, *active_mm; //定义进程内存管理信息,结构体为mm_struct
/* task state */
struct linux_binfmt *binfmt;
long exit_state;
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
/* ??? */
unsigned long personality;
unsigned did_exec:1;
pid_t pid;
pid_t tgid;
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->parent->pid)
*/
struct task_struct *real_parent; /* real parent process (when being debugged) */
struct task_struct *parent; /* parent process */
/*
* children/sibling forms the list of my children plus the
* tasks I'm ptracing.
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
/* PID/PID hash table linkage. */
struct pid pids[PIDTYPE_MAX];
struct completion *vfork_done; /* for vfork() */
int __user *set_child_tid; /* CLONE_CHILD_SETTID */
int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */
unsigned long rt_priority;
unsigned long it_real_value, it_real_incr;
cputime_t it_virt_value, it_virt_incr;
cputime_t it_prof_value, it_prof_incr;
struct timer_list real_timer;
cputime_t utime, stime;
unsigned long nvcsw, nivcsw; /* context switch counts */
struct timespec start_time;
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt;
/* process credentials */
uid_t uid,euid,suid,fsuid;
gid_t gid,egid,sgid,fsgid;
struct group_info *group_info;
kernel_cap_t cap_effective, cap_inheritable, cap_permitted;
unsigned keep_capabilities:1;
struct user_struct *user;
#ifdef CONFIG_KEYS
struct key *session_keyring; /* keyring inherited over fork */
struct key *process_keyring; /* keyring private to this process (CLONE_THREAD) */
struct key *thread_keyring; /* keyring private to this thread */
#endif
int oomkilladj; /* OOM kill score adjustment (bit shift). */
char comm[TASK_COMM_LEN];
/* file system info */
int link_count, total_link_count;
/* ipc stuff */
struct sysv_sem sysvsem;
/* CPU-specific state of this task */
struct thread_struct thread;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
/* namespace */
struct namespace *namespace;
/* signal handlers */
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked, real_blocked;
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
void *security;
struct audit_context *audit_context;
/* Thread group tracking */
u32 parent_exec_id;
u32 self_exec_id;
/* Protection of (de-)allocation: mm, files, fs, tty, keyrings */
spinlock_t alloc_lock;
/* Protection of proc_dentry: nesting proc_lock, dcache_lock, write_lock_irq(&tasklist_lock); */
spinlock_t proc_lock;
/* context-switch lock */
spinlock_t switch_lock;
/* journalling filesystem info */
void *journal_info;
/* VM state */
struct reclaim_state *reclaim_state;
struct dentry *proc_dentry;
struct backing_dev_info *backing_dev_info;
struct io_context *io_context;
unsigned long ptrace_message;
siginfo_t *last_siginfo; /* For ptrace use. */
/*
* current io wait handle: wait queue entry to use for io waits
* If this thread is processing aio, this points at the waitqueue
* inside the currently handled kiocb. It may be NULL (i.e. default
* to a stack based synchronous wait) if its doing sync IO.
*/
wait_queue_t *io_wait;
/* i/o counters(bytes read/written, #syscalls */
u64 rchar, wchar, syscr, syscw;
#if defined(CONFIG_BSD_PROCESS_ACCT)
u64 acct_rss_mem1; /* accumulated rss usage */
u64 acct_vm_mem1; /* accumulated virtual memory usage */
clock_t acct_stimexpd; /* clock_t-converted stime since last update */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *mempolicy;
short il_next;
#endif
};结构体中有一段代码struct mm_struct *mm, *active_mm; 其中会定义进程内存管理信息,结构体为mm_struct,路径为 linux-2.6/include/linux/mm_types.h,如下:
struct mm_struct {
struct vm_area_struct * mmap; /* list of VMAs */
struct rb_root mm_rb;
struct vm_area_struct * mmap_cache; /* last find_vma result */
#ifdef CONFIG_MMU
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
void (*unmap_area) (struct mm_struct *mm, unsigned long addr);
#endif
unsigned long mmap_base; /* base of mmap area */
unsigned long task_size; /* size of task vm space */
unsigned long cached_hole_size; /* if non-zero, the largest hole below free_area_cache */
unsigned long free_area_cache; /* first hole of size cached_hole_size or larger */从上面的代码可以看出,在mm_struct结构体中,含有base of mmap area,也就是基址base。
整体过程

过程:
1、进程1找到空闲内存地址2000,将程序代码放到空闲内存2000中,同时将基地址2000放到进程1的PCB中。
2、进程2找到空闲内存地址1000,将程序代码放到空闲内存1000中,同时将基地址1000放到进程2的PCB中。
3、假设最开始执行的是进程1,则将PC置为进程1的初始地址。
4、进行取指操作,将取出的指令放到CPU中
5、执行时,先进行地址翻译,用基地址加上偏移量得到物理地址,其中基地址来自进程1的PCB中。
6、进行Switch进程切换,现有基址寄存器中的基址写回到进程1的PCB中,然后将进程2的PCB中的base基址写入到基址寄存器中。
7、进程2执行取指操作,同样将取出的指令放到CPU中,然后进行地址翻译,其中基址寄存器的值从2000切换成了进程2的1000,然后加上偏移量100,找到进程2执行的初始物理地址,然后继续进行执行,这就是整个进程切换的过程。
引入分段
在运行时重定位中讲到,在内存中找到一段空闲空间,然后将程序放到内存空间中,这时我们指的是整个程序,但是实际上我们不能将整个程序放到一个内存空间中。
主要原因:程序的部分和部分之间有不同的特性,例如