监督学习:给机器的训练数据拥有“标记”或“答案”
- 主要处理分类、回归问题
- k近邻、线性回归和多项式回归
- 逻辑回归
- SVM
- 决策树和随机森林
非监督学习:给机器的训练数据没有“标记”或“答案”
- 对没有“标记”的数据进行分类-聚类分析:电商对初始顾客没有初始印象,后期出现分类(与监督学习有啥区别?)
- 对数据进行降维处理,特征提取:信用卡的信用评级与人的胖瘦无关?(方便可视化)
- 特征压缩:PCA(尽量少损失信息的情况下,将信息压缩)
- 异常检测:去除异常点
半监督学习:一部分数据有标记或答案,另一部分数据没有
- 更常见:各种原因产生的标记缺失
- 通常都使用无监督学习手段对数据做处理,之后使用监督学习手段做模型的训练和预测
增强学习:
- 根据周围的环境情况,采取行动,根据采取行动的结果,学习行动方式。
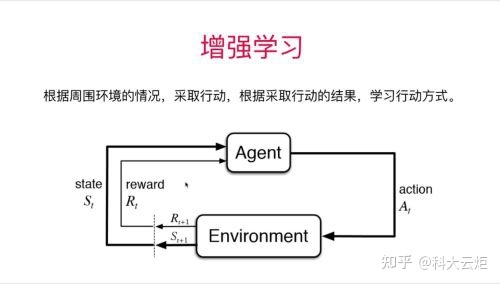
- alphago
- 无人驾驶、机器人
- 现在比较前沿,无法达到,监督学习和半监督学习是基础