文章目录
多任务
多任务建模中需要注意的问题
1、如果子任务差异很大,往往导致多任务模型效果不佳。
2、不同任务的loss大小不一样,需要调整loss的权重。
shared-bottom
优点:这种结构本质上可以减少过拟合的风险。浅层参数共享,互相补充学习,任务相关性越高,模型的loss可以降低到更低。
缺点:但是效果上可能受到任务差异和数据分布带来的影响。如果任务没有好的相关性时,这种Hard parameter sharing会损害效果。
其他结构
1、shared-bottom
2、两个任务的参数不共用,但是通过对不同任务的参数增加L2范数的限制;
3、对每个任务分别学习一套隐层然后学习所有隐层的组合。
和shared-bottom结构相比,这些模型对增加了针对任务的特定参数,在任务差异会影响公共参数的情况下对最终效果有提升。
缺点就是模型增加了参数量所以需要更大的数据量来训练模型,而且模型更复杂并不利于在真实生产环境中实际部署使用。
样本Loss加权
保证一个主目标的同时,将其它目标转化为样本权重,改变数据分布,达到优化其它目标的效果。
优点:
模型简单,仅在训练时通过梯度乘以样本权重实现对其它目标的加权。
模型上线简单,和base完全相同,不需要额外开销。
在主目标没有明显下降时,其它目标提升较大。
缺点:
本质上并不是多目标建模,而是将不同的目标转化为同一个目标。样本的加权权重需要根据AB测试才能确定。
ESMM
ESMM(Entire Space Multi-Task Model)
阿里。shared-bottom结构。任务之间有先后关系。cvr任务在训练时只能利用点击后的样本,而预测时,是在整个样本空间,这样导致训练和预测样本分布不一致,即样本选择性偏差。同时点击样本只占整个样本空间的很小比例,比如在新闻推荐中,点击率通常只有不到10%,即样本稀疏性问题。
AITM
MMOE(MOE)
MMOE(Multi-gate Mixture-of-Experts)
MOE(One-ga te Mixture-of-Experts)
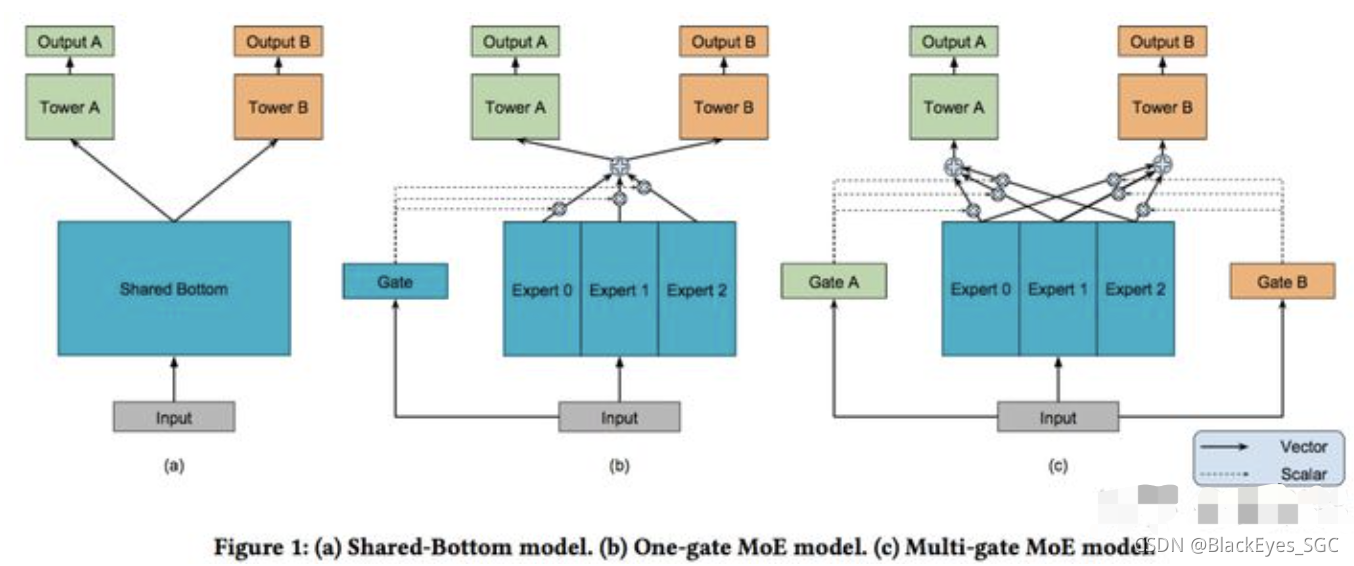
google,KDD2018 Research Track。
优点:不同任务对应的门控网络可以学习到不同的Experts 组合模式,因此模型更容易捕捉到子任务间的相关性和差异性。
缺点:存在跷跷板现象。为什么会存在跷跷板现象?任务被某些任务主导。为什么会被某些任务主导?任务之间的loss不同。
1、MMOE中所有的Expert是被所有任务所共享的,这可能无法捕捉到任务之间更复杂的关系(虽然理论上限是ple),从而给部分任务带来一定的噪声。
2、不同的Expert之间没有交互,联合优化的效果有所折扣。(极端情况,a任务更新expert1,a任务更新expert2、3)
每个experts都相同的特征和网络结构的情况下,为什么会对每个task的贡献度不一样?
1、初始化的时候每个网络的初始状态是随机的,都不相同。如果数据确实存在多个专家的模式,那么在训练学习过程中就会倾向于每个expert去学成那种模式。2、对每个task的贡献度是gate 决定的,所有任务共享experts,但是每个任务都有单独的gate。3、学习的label也不一样。
2、OMOE所有task共用一个gate,有什么用呢?不同task(i)的差异还是要通过最后的tower(i)去学吗?
3、任务相关性:经验称,如果任务相关度非常高,则OMoE和MMoE的效果近似,但是如果任务相关度很低,则OMoE的效果相对于MMoE明显下降。那么在拿到一个多任务模型训练之前,如何判定目标之间的相关程度呢。
1、根据经验,比如点击和观看相关,点击和点赞不相关?2、用皮尔森系数进行判断。
十字绣网络
Cross-stitch Networks for Multi-task Learning

闸式网络
sluice network
ple(cgc)
Customized Gate Control (CGC) Model
2020腾讯。主要解决的问题:解决负迁移,跷跷板现象。
优点:考虑了不同Expert之前的交互。
缺点:
star
任务之间做隔离
信息选择
包括特征选择,高层特征选择、隐层选择。
为什么要信息选择?针对同一个样本不同的任务起决定性的特征也不一样。不同任务在提取特征时不能一视同仁。
cea
多任务的使用
1、serving时需要一个打分公式:比如CTR * log(时长) 或者w1 * CTR + w2 * log(时长),或者一个LTR的模型,优点是可以手工调权在不同的业务期实现不同的目标。
2、做时长跟点击率的多目标模型,loss相差的量级?
label变换:时长的label最好先去log,log后目标更符合正态分布,同时loss量级也更小和稳定。loss调权:多个目标的loss,简单点就是把loss加权重调到同一量级,一般就比较work了。loss量级一致不代表梯度量级一致,还是可能出现某个task梯度主导训练的问题,这个可以看一看多目标优化的一些文章,基于梯度动态调整loss权重 和帕累拖的一些方法。