环境:
基于ambari 2.7.4搭建
hadoop 3.1.1 ( 实现namenode HA )
hive 3.1.0 (mysql存储元数据)
实现步骤:
- 添加pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>aisino_api</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>7</source>
<target>7</target>
</configuration>
</plugin>
</plugins>
</build>
<!-- <name>ca.test</name>-->
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<commons.io.version>2.4</commons.io.version>
<commons.codec.version>1.6</commons.codec.version>
</properties>
<dependencies>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>${commons.io.version}</version>
</dependency>
<dependency>
<groupId>org.apache.directory.studio</groupId>
<artifactId>org.apache.commons.codec</artifactId>
<version>${commons.codec.version}</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.5</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.31</version>
</dependency>
<!-- 以上dependency 可以不用导-->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.1</version>
</dependency>
</dependencies>
-
resources目录下创建 xxx.properties文件
hive_driver=org.apache.hive.jdbc.HiveDriver hive_url=jdbc:hive2://hostname1:2181,hostname2:2181,hostname3:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2 hive_username=**** hive_password=****a. 若使用windows跑程序,hosts文件添加服务器hosts ,或者上面配置hostname改成服务器ip
b. ambari查看hiveserver2 url
ambari打开到hive页面复制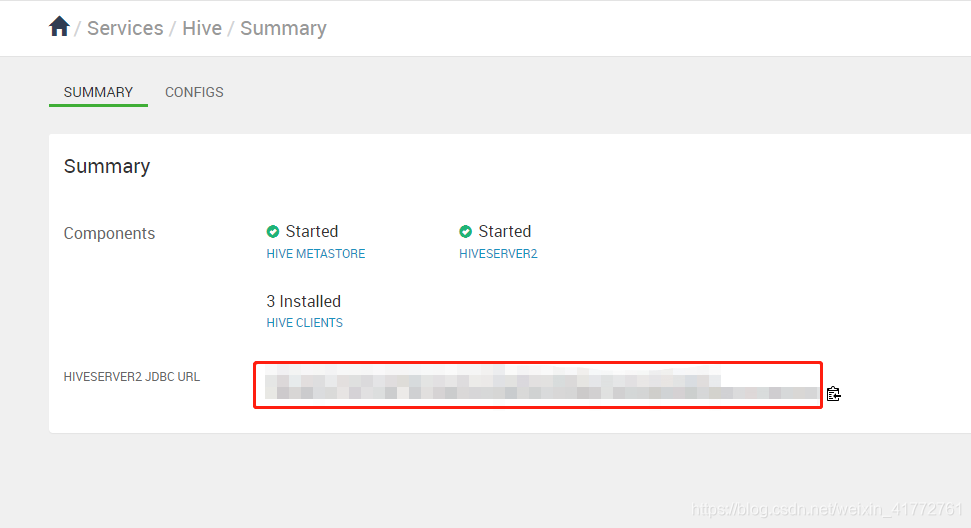
c. username 和 password在搭建hive的时候看自己创建的啥 -
随便写了个HiveJdbctUtil
package util; import org.apache.log4j.Logger; import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; import java.sql.Statement; import java.util.List; import java.util.ResourceBundle; import java.util.concurrent.locks.Lock; import java.util.concurrent.locks.ReentrantLock; public class HiveJDBCUtil { private static String hive_driver; private static String hive_url; private static String hive_username; private static String hive_password; private final static Logger LOG = Logger.getLogger(HiveJDBCUtil.class); private static Connection conn; private static Lock lock = new ReentrantLock(); static { #第二步创建properties取的名字 ResourceBundle bundle = ResourceBundle.getBundle("xxx"); hive_driver = bundle.getString("hive_driver"); hive_url = bundle.getString("hive_url"); hive_username = bundle.getString("hive_username"); hive_password = bundle.getString("hive_password"); try { Class.forName(hive_driver); LOG.info("加载hiveJdbcDriver成功"); } catch (ClassNotFoundException e) { LOG.error("加载hiveJdbcDriver失败:" + e); } } public static Connection getHiveConnection() throws SQLException { if (conn == null || conn.isClosed()) { lock.lock(); if (conn == null || conn.isClosed()) { conn = DriverManager.getConnection( hive_url, hive_username, hive_password); } lock.unlock(); } return conn; } public static boolean executeSql(String sql) { Connection hiveConn = null; Statement stmt = null; try { hiveConn = getHiveConnection(); stmt = hiveConn.createStatement(); LOG.info("Executing sql: " + sql); stmt.executeQuery(sql); } catch (Exception e) { LOG.error(e); return false; } return true; } public static boolean executeSqls(List<String> sqls) { Connection hiveConn = null; Statement stmt = null; try { hiveConn = getHiveConnection(); stmt = hiveConn.createStatement(); for (String sql : sqls) { LOG.info("Executing sql: " + sql); stmt.executeQuery(sql); } } catch (Exception e) { LOG.error(e); return false; } return true; } } -
简单测试
import util.HiveJDBCUtil; import java.sql.Connection; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; public class TEST { public static void main(String[] args) { Connection hiveConnection = null; Statement statement = null; ResultSet rs = null; try { hiveConnection = HiveJDBCUtil.getHiveConnection(); statement = hiveConnection.createStatement(); String sql = "select id from test.test limit 100"; rs = statement.executeQuery(sql); while (rs.next()) { System.out.println(rs.getString("id")); } } catch (Exception throwables) { throwables.printStackTrace(); } finally { try { rs.close(); } catch (SQLException throwables) { throwables.printStackTrace(); } try { statement.close(); } catch (SQLException throwables) { throwables.printStackTrace(); } try { hiveConnection.close(); } catch (SQLException throwables) { throwables.printStackTrace(); } } } } -
结果
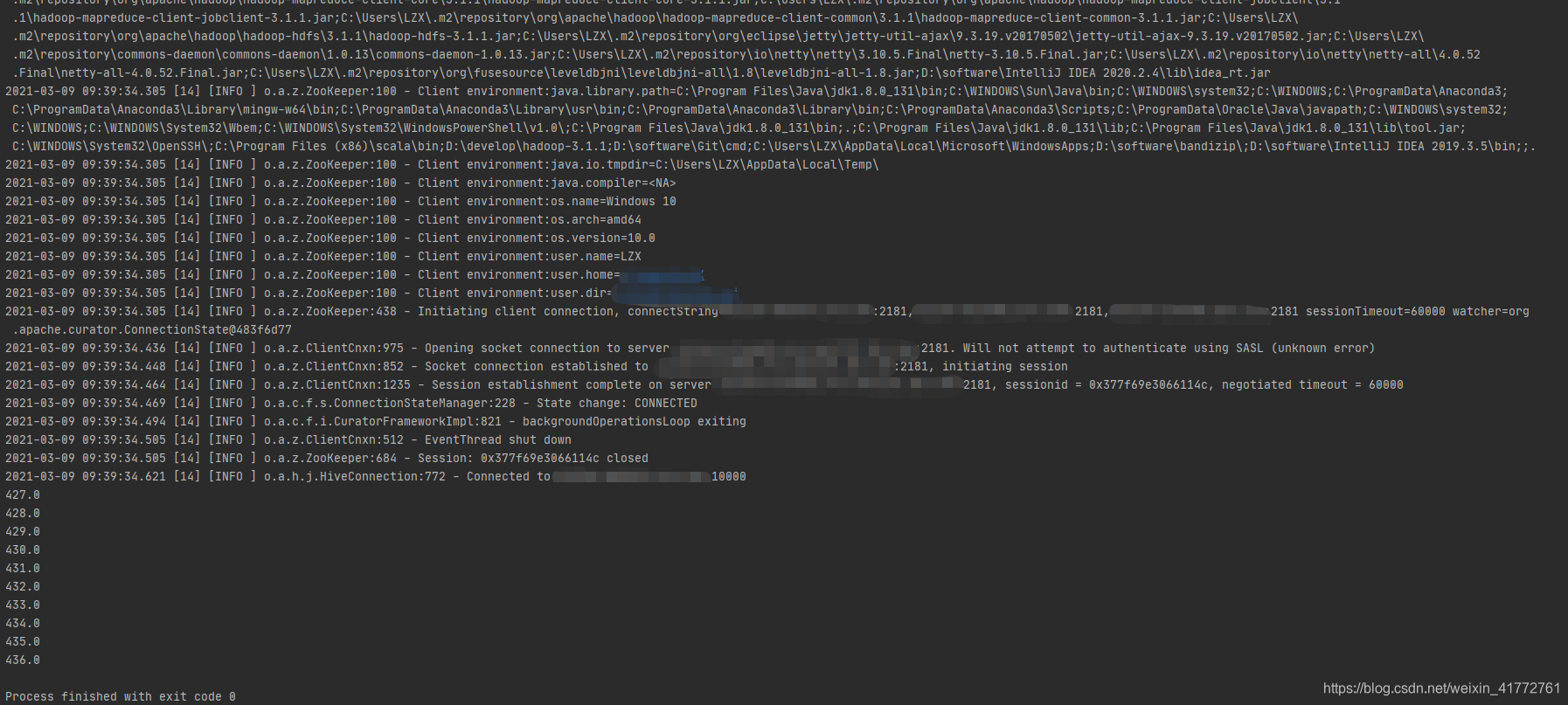
出现的问题:
一开始连接不上,超时,发现是端口管控,10000端口没有开放。