hashmap中获取key数组下标index的步骤大致为一下散布:
- 获取到key的hashcode (32为的int值)
- 通过扰动函数(哈希函数)得到 newhash
- 下标 index = newhash & ( table.length - 1)
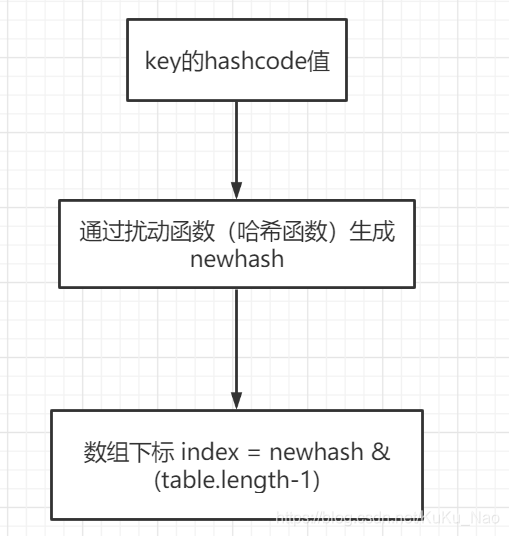
下面展开对这三步进行分析:
- 第一步:key.hashCode()函数调用的是key键值类型自带的哈希函数,返回int型散列值。int值范围为**-2147483648~2147483647**
第一步就是拿到 hashcode 很好理解,重点在第二步和第三步,面试重点也是第二步和第三步。
- 第二步:通过扰动函数得到 newhash
面试一:这里的扰动函数具体是怎么实现的呢?
是用第一步的 hashcode(32位) 高16位和低16位异或 ,源码如下图:

面试二:什么是高16位和低16位异或呢?举个例子:
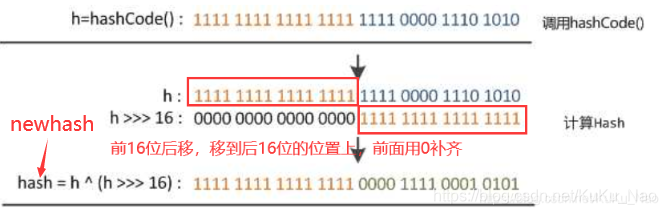
异或: 相同为0,不同为1;
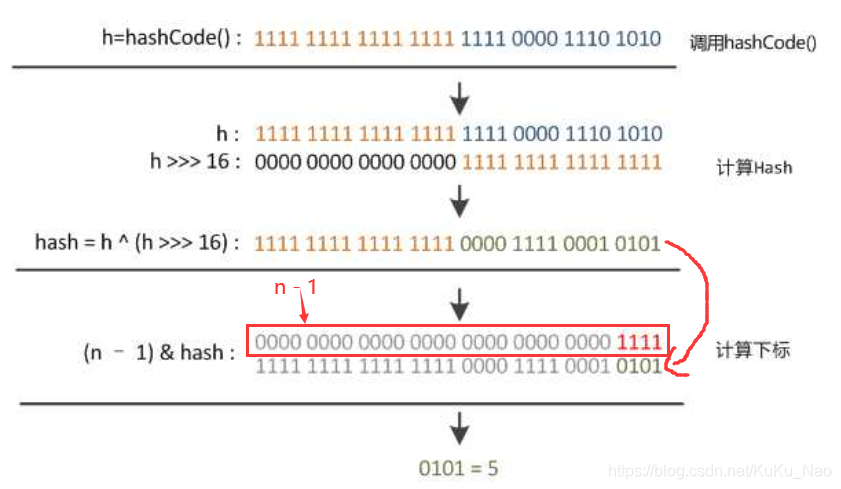
- 第三步:index = newhash & ( table.length - 1)
第二步得到的 newhash 和数组长度-1 做与运算 就得到了下标index
面试三:这里一定会产生疑惑,为什么要 newhash & ( table.length - 1) 这样算呢?
先上图!!
面试四:这里就涉及到了 hashmap的容量为什么要是2的整数次幂了。
举例:16 = 2^4
转为二进制也就是 0000 0000 0000 0000 0000 0000 0001 0000
那么 16 - 1 二进制:0000 0000 0000 0000 0000 0000 0000 1111
高位都为0,相当于一个低位掩码,和 newhash 与操作的时候 就会保留下 后四位 正好可以作为数组下标。
面试五:那么,还有一个疑问:为什么不直接用hashcode 直接和 table - 1 做与操作呢?扰动函数不可以省略吗?实际意义是什么?
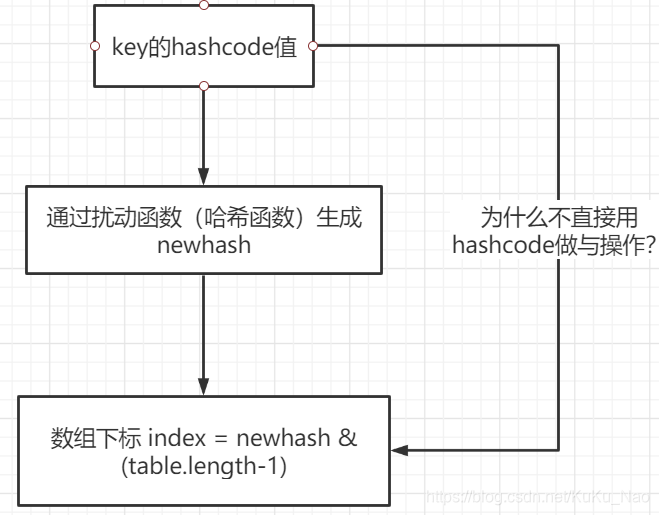
设计扰动函数的原因有两点:
- 一定要尽可能降低hash碰撞,越分散越好
- 算法一定要尽可能高效,因为这是高频操作, 因此采用位运算;
尽可能降低碰撞?怎么说?
hashcode —> newhash 只能说是一个更加散列的操作
通俗点说就是,hashcode还不够散列,通过扰动使它更加散列
假设hashmap容量为16,table - 1 肯定是取后四位 1111 去做与操作,如果没有扰动, hashcode 的后四位如果都是0 ,那么前面高位不管是多少结果下标 index 都是0,因为 0 和 任何做与都是0,所以碰撞的几率大。
而扰动后,前16位和后16位异或之后,混合了高位和地位,加大了随机性。
举个例子:扰动函数优化前:1954974080 % 16 = 1954974080 & (16 - 1) = 0 扰动函数优化后:1955003654 % 16 = 1955003654 & (16 - 1) = 6 很显然,减少了碰撞的几率。
希望这篇文章对你有帮助!加油!