Elasticsearch聚合分析(二)—Bucket聚合分析
- Bucket,分桶类型,类似SQL语法中的group by语法
- Bucked,意为桶,即按照一定的规则将文档分配到不同的桶中,达到分类分析的目的。
- 分桶策略:Terms、Range、Date Range、Histogram、Date Histogram。
Bucket 聚合分析
Terms
Bucket聚合分析之Terms,该分桶策略最简单了,直接按照term来分桶,如果是text类型,则按照分词后的结果分桶。
- 按照省份分桶
GET /LGlink/_search
{
"size": 0,
"aggs": {
"city_bucket": {
"terms": {
"field": "city",
"size": 10
}
}
}
}
- 按照用户名分桶
GET /LGlink/_search
{
"size": 0,
"aggs": {
"username_bucket": {
"terms": {
"field": "username",
"size": 10
}
}
}
}
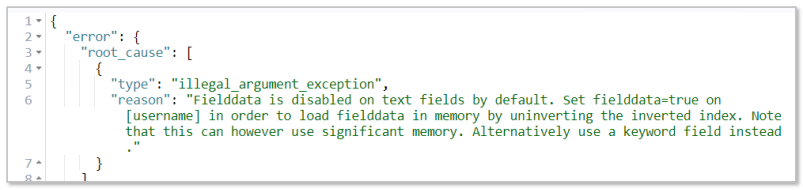
- text的聚合操作,使用fielddata进行处理,需要单独开启
PUT /LGlink/_mapping/user
{
"properties": {
"username": {
"type": "text",
"analyzer": "ik_max_word",
"fielddata": true
}
}
}
Range
Bucket聚合分析之Range,通过指定数值的范围来设定分桶规则。
GET /LGlink/_search
{
"size": 0,
"aggs": {
"age_range": {
"range": {
"field": "age",
"ranges": [
{
"to": 15
},
{
"from": 15,
"to": 20
},
{
"from": 20
}
]
}
}
}
}
Histogram
Bucket聚合分析之Histogram,直方图,以固定间隔的策略来分割数据。
- interval:指定间隔大小
- extended_bounds:指定数据范围
GET /LGlink/_search
{
"size": 0,
"aggs": {
"age_hist": {
"histogram": {
"field": "age",
"interval": 5,
"extended_bounds": {
"min": 10,
"max": 30
}
}
}
}
}
看完如果对你有帮助,感谢点赞支持!
如果你是电脑端,看到右下角的 一键三连 了吗,没错点它[哈哈]
