1、Hive的参数配置
./hive 是hive的第一代客户端,次客户端,主要有两大作用 用于执行一些交互式或者批处理的操作,第二大作用,是用于启动hive的各项服务
- 第一大作用:交互式(了解)
./hive 进入交互式
进入之后,可以在客户端内部,不断和hive进行相关操作,在一个会话中,可以不断和hive进行交互
- 批处理
批处理: 指的在不进入hive的交互窗口下, 即可操作hive, 主要是linux的命令行下操作
好处: 主要的目的是为了后续在linux的脚本中连接hive进行操作
第一种操作: ./hive -e 'sql语句'
例如: ./hive -e 'show databases; show tables;'
第二种操作: ./hive -f 'SQL的脚本文件'
第一步: 在node1的/root/hivedata/ 下创建index.sql
内容如下:
show databases;
show tables;
第二步: 执行SQL脚本:
例如: ./hive -f '/root/hivedata/index.sql'
- 第二大作用: 启动hive服务:
比如启动metastore 和 hiveserver2的服务项
nohup ./hive --service metastore &
nohup ./hive --service hiveserver2 &
2、hive的相关函数
- 查看hive支持的内置函数有哪些
show functions;
- 如何使用某一个函数呢?
describe function extended 函数名称;
常用的内置函数:
数值函数:
1) 取整函数: round
语法: round(double a) 获取小数中整数位(四舍五入)
2) 向上向下取整函数: ceil , floor
语法: ceil(double a),floor(double a)
3) 指定精度取整函数: round 固定小数位
语法: round(double a, int d) 会四舍五入操作
日期函数:
1) UNIX 时间戳转日期函数: from_unixtime
格式: : from_unixtime(bigint unixtime[, string format])
案例:
select from_unixtime(1632020150) --> 2021-09-19 02:55:50
select from_unixtime(1632020150,'yyyy-MM-dd HH/mm/ss'); --> 2021-09-19 02/55/50
2) 获取当前 UNIX 时间戳函数: unix_timestamp
格式: unix_timestamp()
3) 日期转 UNIX 时间戳函数: unix_timestamp
格式: unix_timestamp('日期'[, string format]);
案例:
select from_unixtime(1620304259);
select unix_timestamp('2021/05/06 12/30/59','yyyy/MM/dd HH/mm/ss');
4) 获取日期时间中的日期数据: to_date
格式: to_date('标准格式日期时间')
案例:
select to_date('2012-05-01 12:51:47'); -- 2012-05-01
5) 获取日期中各个部分的信息:
year(), month(), day(), hour(),minute(),second(),weekofyear()
6) 日期比较函数: datediff
格式: datediff(string enddate, string startdate)
案例:
select datediff('2021-09-19','2021-09-01');
7) 日期增加和减少的函数:
格式: date_add((string startdate, int days);
案例:
select date_add('2021-09-19',-3); -- 2021-09-16
select date_add('2021-09-19',3); -- 2021-09-22
条件函数:
1) if函数:
格式: if(条件,'true执行内容','false执行内容');
说明: 当参数1的条件成立的时候, 执行参数2的内容, 否则执行参数3的内容
案例:
select if(1=2,'nan','nv'); 返回 nv
select if(1=1,'nan','nv'); 返回 nan
支持嵌套使用: 无限制
select if(1=1,if(2=2,'222','111'),'333');
2) case when操作:
格式1: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
说明: 当a=b的时候, 返回 c 当a=d的时候返回e,否则返回f
格式2: CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END
说明: 当a的条件成立时, 返回b, 当c的条件成立时返回d, 否则返回e,
说明: 前面条件匹配成功, 那么不看后续条件
案例:
with t1 as (select 'nv' as sex)
select case sex
when 'nan' then '我是个男人'
when 'nv' then '我是个女人'
else '不男不女' end
from t1;
with t1 as (select 'nv' as sex)
select case when sex='nan' then '我是个男人' when sex='nv' then '我是个女人' else '不男不女' end from t1;
3) 非空查找函数: COALESCE
语法: COALESCE(T v1, T v2, …)
说明: 返回参数中的第一个非空值;如果所有值都为 NULL,那么返回 NULL
案例:
select COALESCE('zhangsan',null,'lisi',null); --> zhangsan
select COALESCE(null,null,'lisi',null); --> lisi
select COALESCE(null,null,null,null); --> null
字符串函数:
1) 字符串的切割函数: substr(), substring()
格式:
substr(字符串,从第几位开启切[,切多少位])
substring(字符串,从第几位开启切[,切多少位])
案例:
select substr('2021-05-06 12:05:12',1,4); --> 2021
select substr('2021-05-06 12:05:12',6,2); --> 05
select substr('2021-05-06 12:05:12',6); --> 05-06 12:05:12
2) 字符串拼接函数: concat 和concat_ws
格式:
concat(字符串1,字符串2,字符串3...)
concat_ws('分隔符号',字符串1,字符串2... | 集合类型)
案例:
select concat('zhangsan',' ','lisi',' ','wangwu');
select concat_ws(' ','zhangsan','lisi','wangwu');
函数的分类:
- UDF:普通函数
- 特点:一进一出函数
- 大部分的函数都是属于这种函数
- UDAF:聚合函数
- 特点: 一进多出的函数
- 聚合函数属于 sum max min avg ·····
- UDTF:表生成函数
- 特点:一进多出的函数
- 比如:explode(爆炸函数)
- 此种函数见一个归纳一个即可
3、hIve的函数高阶
3.1 explode的函数
explode函数 接收map或者array类型的数据作为参数,然后把参数中的内阁元素炸开编程一行数据,一个元素一行,这样效果正好满足输入一行输出多行
'explode(array)将array列表里的每个元素生成一行;'
'explode(map)将map里的每一对元素作为一行,其中key为一列,value为一列;'
下面做一个案例:
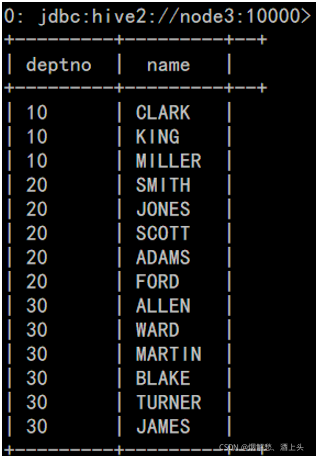
数据:
10 CLARK|KING|MILLER
20 SMITH|JONES|SCOTT|ADAMS|FORD
30 ALLEN|WARD|MARTIN|BLAKE|TURNER|JAMES
结果需要变成
解决方法:
'第一步:'在node1的/root/hivedata/下, 创建一个dept.txt文件, 添加以下数据:
10 CLARK|KING|MILLER
20 SMITH|JONES|SCOTT|ADAMS|FORD
30 ALLEN|WARD|MARTIN|BLAKE|TURNER|JAMES
'第二步: '在hive中创建表
create database day04_hive;
use day04_hive;
create table day04_hive.dept(
dept_id int,
dept_name array<string>
)row format
delimited fields terminated by '\t'
collection items terminated by '|';
'第三步:' 导入数据到 dept表中
load data local inpath '/root/hivedata/dept.txt' into table day04_hive.dept;
'第四步:' 测试是否加载成功
select * from day04_hive.dept;
+---------------+----------------------------------------------------+
| dept.dept_id | dept.dept_name |
+---------------+----------------------------------------------------+
| 10 | ["CLARK","KING","MILLER"] |
| 20 | ["SMITH","JONES","SCOTT","ADAMS","FORD"] |
| 30 | ["ALLEN","WARD","MARTIN","BLAKE","TURNER","JAMES"] |
+---------------+----------------------------------------------------+
尝试使用explode:
select explode(dept_name) from day04_hive.dept;
结果为:
+---------+
| col |
+---------+
| CLARK |
| KING |
| MILLER |
| SMITH |
| JONES |
| SCOTT |
| ADAMS |
| FORD |
| ALLEN |
| WARD |
| MARTIN |
| BLAKE |
| TURNER |
| JAMES |
+---------+
接着尝试, 将 部门id加上:
select dept_id,explode(dept_name) as dept_name from day04_hive.dept;
发现, 报错了:
Error: Error while compiling statement: FAILED: SemanticException [Error 10081]: UDTF's are not supported outside the SELECT clause, nor nested in expressions (state=42000,code=10081)
UDTF函数特殊要求:
1) 如果UDTF函数被使用在select后面, 不允许在出现其他的列或者字段
2) UDTF函数不允许被其他的函数所嵌套, 但是他可以嵌套其他的函数
如何解决呢? 可以将这个结果作为临时表 ,然后和原有表进行关联即可
但是发现, 好像无法关联, 因为临时表和原有表没有关联条件, 此时如何办呢?
答: hive为了解决这种问题, 可以采用"侧视图"的方案, 而侧视图一般就是和UDTF配合使用, 解决UDTF函数特殊问题
侧视图:lateral view
用法:lateral view udtf(expression) tableAlias AS columnAlias
放置位置: 在SQL的"最后面"
接下来, 使用侧视图解决问题:
扫描二维码关注公众号,回复:
13268740 查看本文章

select dept_id, name from day04_hive.dept lateral view explode(dept_name) t1 as name;
+----------+---------+
| dept_id | name |
+----------+---------+
| 10 | CLARK |
| 10 | KING |
| 10 | MILLER |
| 20 | SMITH |
| 20 | JONES |
| 20 | SCOTT |
| 20 | ADAMS |
| 20 | FORD |
| 30 | ALLEN |
| 30 | WARD |
| 30 | MARTIN |
| 30 | BLAKE |
| 30 | TURNER |
| 30 | JAMES |
+----------+---------+
思考: 如果刚刚建表的时候, 不使用array类型, 使用string类型, 如何解决呢?
select dept_id, name from day04_hive.dept lateral view explode(split(dept_name,'|')) t1 as name;
3.2行转列操作
行转列, 指的 多行转换为一列数据
涉及到的函数:
concat(str1,str2,...) 字段或字符串拼接
concat_ws(sep, str1,str2) 以分隔符拼接每个字符串
collect_set(col) 将某字段的值进行去重汇总,产生array类型字段
collect_list(col) 将某字段的值进行汇总(不去重),产生array类型字段
给个小案例 方便理解:
数据:
10 CLARK
10 KING
10 MILLER
20 SMITH
20 JONES
20 SCOTT
20 ADAMS
20 FORD
30 ALLEN
30 WARD
30 MARTIN
30 BLAKE
30 TURNER
30 JAMES
结果为:
10 CLARK|KING|MILLER
20 SMITH|JONES|SCOTT|ADAMS|FORD
30 ALLEN|WARD|MARTIN|BLAKE|TURNER|JAMES
具体操作:
1) 在node1的/root/hivedata/下 创建dept1.txt文件
内容如下:
10 CLARK
10 KING
10 MILLER
20 SMITH
20 JONES
20 SCOTT
20 ADAMS
20 FORD
30 ALLEN
30 WARD
30 MARTIN
30 BLAKE
30 TURNER
30 JAMES
2) 在hive中创建表:
create table dept1(
dept_id int,
dept_name string
) row format delimited fields terminated by '\t';
3) 加载数据到dept1表中
load data local inpath '/root/hivedata/dept1.txt' into table dept1;
4) 校验数据
select * from dept1;
+----------------+------------------+
| dept1.dept_id | dept1.dept_name |
+----------------+------------------+
| 10 | CLARK |
| 10 | KING |
| 10 | CLARK |
| 20 | SMITH |
| 20 | JONES |
| 20 | SCOTT |
| 20 | ADAMS |
| 20 | FORD |
| 30 | ALLEN |
| 30 | WARD |
| 30 | MARTIN |
| 30 | BLAKE |
| 30 | TURNER |
| 30 | JAMES |
+----------------+------------------+
行转列函数的使用:
select collect_set(dept_id)[0] as dept_id, concat_ws('|',collect_set(dept_name)) as dept_name from day04_hive.dept1 group by dept_id ;
结果:
+----------+---------------------------------------+
| dept_id | dept_name |
+----------+---------------------------------------+
| 10 | CLARK|KING|MILLER |
| 20 | SMITH|JONES|SCOTT|ADAMS|FORD |
| 30 | ALLEN|WARD|MARTIN|BLAKE|TURNER|JAMES |
+----------+---------------------------------------+
3.3列转行操作 请参考3.1
3.4json 数据解析处理
json本质上是一个有格式的字符串,json常见的格式主要有三种:
一种格式: {
key:value,key:value}
另一种格式: [值1,值2,值3]
如何解析json数据 下面上个案例:
{
"device":"device_30","deviceType":"kafka","signal":98.0,"time":1616817201390}
{
"device":"device_40","deviceType":"route","signal":99.0,"time":1616817201887}
{
"device":"device_21","deviceType":"bigdata","signal":77.0,"time":1616817202142}
{
"device":"device_31","deviceType":"kafka","signal":98.0,"time":1616817202405}
{
"device":"device_20","deviceType":"bigdata","signal":12.0,"time":1616817202513}
{
"device":"device_54","deviceType":"bigdata","signal":14.0,"time":1616817202913}
{
"device":"device_10","deviceType":"db","signal":39.0,"time":1616817203356}
{
"device":"device_94","deviceType":"bigdata","signal":59.0,"time":1616817203771}
{
"device":"device_32","deviceType":"kafka","signal":52.0,"time":1616817204010}
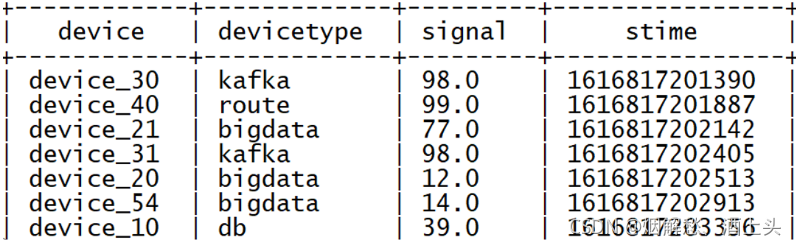
字段内容:
设备名称【device】、设备类型【deviceType】、信号强度【signal】和信号发送时间【time】,
要求将以上数据, 转换为以下结果:
具体做法:
1) 将资料中 device.json 文件上传 node1的/root/hivedata目录下
2) 在hive中创建表:
create table device_json(
json string
);
3) 加载数据:
load data local inpath '/root/hivedata/device.json' into table device_json;
4) 校验数据
select * from device_json;
+----------------------------------------------------+
| device_json.json |
+----------------------------------------------------+
| {
"device":"device_30","deviceType":"kafka","signal":98.0,"time":1616817201390} |
| {
"device":"device_40","deviceType":"route","signal":99.0,"time":1616817201887} |
| {
"device":"device_21","deviceType":"bigdata","signal":77.0,"time":1616817202142} |
| {
"device":"device_31","deviceType":"kafka","signal":98.0,"time":1616817202405} |
| {
"device":"device_20","deviceType":"bigdata","signal":12.0,"time":1616817202513} |
| {
"device":"device_54","deviceType":"bigdata","signal":14.0,"time":1616817202913} |
- 第一种方案:采用函数来解析数据 get_json_object (udf)
- 适合于表中某几个字段是json数据
select
get_json_object(json,'$.device') as device,
get_json_object(json,'$.deviceType') as deviceType,
get_json_object(json,'$.signal') as signal,
get_json_object(json,'$.time') as timestr
from device_json;
存在弊端:
执行多次重复的函数, 重复的数据, 需要加载多次json数据
- 方案二: 采用函数来解析数据 json_tuple(udtf)
- 适合于表中某几个字段是json数据
select
json_tuple(json,'device','deviceType','signal','time')
from device_json;
建议将以上的SQL更改为:
select
device,
deviceType,
signal,
timestr
from device_json lateral view json_tuple(json,'device','deviceType','signal','time') t1 as device,deviceType,signal,timestr;
- 方案三: 可以在建表的时候, 直接让hive对json数据自动解析即可
- 适合于 整个文件数据都是json
create table device_json_1(
device string,
deviceType string ,
signal string,
timestr string
)
row format SERDE 'org.apache.hive.hcatalog.data.JsonSerDe';
加载数据:
load data local inpath '/root/hivedata/device.json' into table device_json_1;
+-----------------------+---------------------------+-----------------------+------------------------+
| device_json_1.device | device_json_1.devicetype | device_json_1.signal | device_json_1.timestr |
+-----------------------+---------------------------+-----------------------+------------------------+
| device_30 | kafka | 98.0 | NULL |
| device_40 | route | 99.0 | NULL |
| device_21 | bigdata | 77.0 | NULL |
| device_31 | kafka | 98.0 | NULL |
| device_20 | bigdata | 12.0 | NULL |
| device_54 | bigdata | 14.0 | NULL |
| device_10 | db | 39.0 | NULL |
| device_94 | bigdata | 59.0 | NULL |
发现最后一列为null? 为什么呢?
原因: org.apache.hive.hcatalog.data.JsonSerDe 在查询数据的时候,
通过这个类对json进行解析, 解析的时候, 会按照表的字段名称当做key 寻找json中value数据,
所以要求key必须和json中key保持一致, 否则会映射失败
create table device_json_2(
device string,
deviceType string ,
signal string,
`time` string
)
row format SERDE 'org.apache.hive.hcatalog.data.JsonSerDe';
加载数据:
load data local inpath '/root/hivedata/device.json' into table device_json_2;
4、窗口函数
格式: 分析函数 over(partition by xxx order by xxx [desc|asc])
说明:
partition by: 相当于group by 对数据进行分组操作
order by : 用于排序, 如果有partition by,相当于给每组内数据进行排序,
如果没有partition by相当于认为将表中所有的数据作为一组进行排序操作
4.1 窗口函数 和 row_number,rank,dense_rank,ntile结合使用
- row_number,rank,dense_rank,ntile 主要的作用是什么
主要的作用是用于'对每组内的数据打标记的', 一般都是从 1开始
- 在打标记的时候, 各有什么不同点
是否考虑重复问题, 以及标记序号的间隔问题
1) row_number: 在进行打标记的时候, '不会考虑数据重复问题', 从1开始往下打即可
2) rank: 在进行打标记的时候, '会考虑数据重复的问题', 从1开始打标记, '当遇到重复的数据(以排序字段), 会打上相同的序号', 此操作会占用后续的序号位 比如 1 2 2 4
3) dense_rank: 在进行打标记的时候, '会考虑数据重复的问题', 从1开始打标记, '当遇到重复的数据(以排序字段), 会打上相同的序号, 不会占用后续的序号位': 比如 1 2 2 3
4) ntile(N) : 主要是用于'对一组内数据划分为N份, 每一份都是平均分开, 两份之间相差不会超过1'
- 以上这几个分析函数, 有什么应用场景呢?
'row_number,rank,dense_rank' : 主要的应用场景是为了计算求分组TOPN(求组内的前多少个)问题,
以及取每组的某一个操作
需求: 求以下电影中, 每组分类中最热门的的前三部电影
ntile(N) : 主要的应用场景是求几分之几的问题
需求: 求出在我们班级中男生 女生各身高的前3分之1的数据
给个案例:
数据文件:website_pv_info.txt
cookie1,2018-04-10,1
cookie1,2018-04-11,5
cookie1,2018-04-12,7
cookie1,2018-04-13,3
cookie1,2018-04-14,2
cookie1,2018-04-15,4
cookie1,2018-04-16,4
cookie2,2018-04-10,2
cookie2,2018-04-11,3
cookie2,2018-04-12,5
cookie2,2018-04-13,6
cookie2,2018-04-14,3
cookie2,2018-04-15,9
cookie2,2018-04-16,7
1) 将提供的website_pv_info.txt文件上传到node1的/root/hivedata目录下
2)在hive中建表
create table web_pv(
cookie string,
datestr string,
pv int
)row format delimited fields terminated by ',';
3) 加载数据
load data local inpath '/root/hivedata/website_pv_info.txt' into table web_pv;
4) 校验数据
select * from web_pv;
+----------------+-----------------+------------+
| web_pv.cookie | web_pv.datestr | web_pv.pv |
+----------------+-----------------+------------+
| cookie1 | 2018-04-10 | 1 |
| cookie1 | 2018-04-11 | 5 |
| cookie1 | 2018-04-12 | 7 |
| cookie1 | 2018-04-13 | 3 |
| cookie1 | 2018-04-14 | 2 |
| cookie1 | 2018-04-15 | 4 |
| cookie1 | 2018-04-16 | 4 |
| cookie2 | 2018-04-10 | 2 |
| cookie2 | 2018-04-11 | 3 |
| cookie2 | 2018-04-12 | 5 |
| cookie2 | 2018-04-13 | 6 |
| cookie2 | 2018-04-14 | 3 |
| cookie2 | 2018-04-15 | 9 |
| cookie2 | 2018-04-16 | 7 |
+----------------+-----------------+------------+
相关操作:
1) 演示各个分析函数的相关的操作
select
cookie,
datestr,
pv,
row_number() over(partition by cookie order by pv desc) as rn1,
rank() over(partition by cookie order by pv desc) as rn2,
dense_rank() over(partition by cookie order by pv desc) as rn3,
ntile(3) over(partition by cookie order by pv desc) as rn4
from web_pv;
+----------+-------------+-----+------+------+------+------+
| cookie | datestr | pv | rn1 | rn2 | rn3 | rn4 |
+----------+-------------+-----+------+------+------+------+
| cookie1 | 2018-04-12 | 7 | 1 | 1 | 1 | 1 |
| cookie1 | 2018-04-11 | 5 | 2 | 2 | 2 | 1 |
| cookie1 | 2018-04-16 | 4 | 3 | 3 | 3 | 1 |
| cookie1 | 2018-04-15 | 4 | 4 | 3 | 3 | 2 |
| cookie1 | 2018-04-13 | 3 | 5 | 5 | 4 | 2 |
| cookie1 | 2018-04-14 | 2 | 6 | 6 | 5 | 3 |
| cookie1 | 2018-04-10 | 1 | 7 | 7 | 6 | 3 |
| cookie2 | 2018-04-15 | 9 | 1 | 1 | 1 | 1 |
| cookie2 | 2018-04-16 | 7 | 2 | 2 | 2 | 1 |
| cookie2 | 2018-04-13 | 6 | 3 | 3 | 3 | 1 |
| cookie2 | 2018-04-12 | 5 | 4 | 4 | 4 | 2 |
| cookie2 | 2018-04-11 | 3 | 5 | 5 | 5 | 2 |
| cookie2 | 2018-04-14 | 3 | 6 | 5 | 5 | 3 |
| cookie2 | 2018-04-10 | 2 | 7 | 7 | 6 | 3 |
+----------+-------------+-----+------+------+------+------+
需求: 基于row_number 获取每组内前三个数据
with t1 as(select
cookie,
datestr,
pv,
row_number() over(partition by cookie order by pv desc) as rn1
from web_pv)
select * from t1 where rn1 <=3;
+------------+-------------+--------+---------+
| t1.cookie | t1.datestr | t1.pv | t1.rn1 |
+------------+-------------+--------+---------+
| cookie1 | 2018-04-12 | 7 | 1 |
| cookie1 | 2018-04-11 | 5 | 2 |
| cookie1 | 2018-04-16 | 4 | 3 |
| cookie2 | 2018-04-15 | 9 | 1 |
| cookie2 | 2018-04-16 | 7 | 2 |
| cookie2 | 2018-04-13 | 6 | 3 |
+------------+-------------+--------+---------+
需求: 基于ntile节点, 求第二份数据
with t2 as (select
cookie,
datestr,
pv,
ntile(3) over(partition by cookie order by pv desc) as rn4
from web_pv)
select * from t2 where rn4 =2;
+------------+-------------+--------+---------+
| t2.cookie | t2.datestr | t2.pv | t2.rn4 |
+------------+-------------+--------+---------+
| cookie1 | 2018-04-15 | 4 | 2 |
| cookie1 | 2018-04-13 | 3 | 2 |
| cookie2 | 2018-04-12 | 5 | 2 |
| cookie2 | 2018-04-11 | 3 | 2 |
+------------+-------------+--------+---------+
需求: 请将表中每一组内数据拿出其中一条即可 : 分组top1问题
with t1 as(select
cookie,
datestr,
pv,
row_number() over(partition by cookie order by pv desc) as rn1
from web_pv)
select * from t1 where rn1 =1;
+------------+-------------+--------+---------+
| t1.cookie | t1.datestr | t1.pv | t1.rn1 |
+------------+-------------+--------+---------+
| cookie1 | 2018-04-12 | 7 | 1 |
| cookie2 | 2018-04-15 | 9 | 1 |
+------------+-------------+--------+---------+
4.2窗口函数和聚合函数结合
聚合函数: sum() count() avg() max() min()
相关的聚合函数和窗口函数演示: sum()
select
cookie,
datestr,
pv,
sum(pv) over(partition by cookie order by datestr desc) as rn1
from web_pv;
+----------+-------------+-----+------+
| cookie | datestr | pv | rn1 |
+----------+-------------+-----+------+
| cookie1 | 2018-04-16 | 4 | 4 |
| cookie1 | 2018-04-15 | 4 | 8 |
| cookie1 | 2018-04-14 | 2 | 10 |
| cookie1 | 2018-04-13 | 3 | 13 |
| cookie1 | 2018-04-12 | 7 | 20 |
| cookie1 | 2018-04-11 | 5 | 25 |
| cookie1 | 2018-04-10 | 1 | 26 |
| cookie2 | 2018-04-16 | 7 | 7 |
| cookie2 | 2018-04-15 | 9 | 16 |
| cookie2 | 2018-04-14 | 3 | 19 |
| cookie2 | 2018-04-13 | 6 | 25 |
| cookie2 | 2018-04-12 | 5 | 30 |
| cookie2 | 2018-04-11 | 3 | 33 |
| cookie2 | 2018-04-10 | 2 | 35 |
+----------+-------------+-----+------+
默认情况下: 当前行和之前的所有行进行级联求各种值(比如 sum 级联求和 count 级联求个数...)
思考: 如果我将order by 去掉, 会有什么效果呢?
select
cookie,
datestr,
pv,
sum(pv) over(partition by cookie ) as rn1
from web_pv;
+----------+-------------+-----+------+
| cookie | datestr | pv | rn1 |
+----------+-------------+-----+------+
| cookie1 | 2018-04-10 | 1 | 26 |
| cookie1 | 2018-04-16 | 4 | 26 |
| cookie1 | 2018-04-15 | 4 | 26 |
| cookie1 | 2018-04-14 | 2 | 26 |
| cookie1 | 2018-04-13 | 3 | 26 |
| cookie1 | 2018-04-12 | 7 | 26 |
| cookie1 | 2018-04-11 | 5 | 26 |
| cookie2 | 2018-04-16 | 7 | 35 |
| cookie2 | 2018-04-15 | 9 | 35 |
| cookie2 | 2018-04-14 | 3 | 35 |
| cookie2 | 2018-04-13 | 6 | 35 |
| cookie2 | 2018-04-12 | 5 | 35 |
| cookie2 | 2018-04-11 | 3 | 35 |
| cookie2 | 2018-04-10 | 2 | 35 |
+----------+-------------+-----+------+
说明: 去除排序后 , 没有了级联效果, 每一次都是对组内所有数据求各种值
思考: 如果我想求当前行和上一行的累加操作呢
此时需要介绍一些关键词:
关键字是rows between,包括下面这几个选项
- preceding:往前
- following:往后
- current row:当前行
- unbounded:边界
- unbounded preceding 表示从前面的起点
- unbounded following:表示到后面的终点
select
cookie,
datestr,
pv,
sum(pv) over(partition by cookie order by datestr desc rows between 1 preceding and current row) as rn1
from web_pv;
+----------+-------------+-----+------+
| cookie | datestr | pv | rn1 |
+----------+-------------+-----+------+
| cookie1 | 2018-04-16 | 4 | 4 |
| cookie1 | 2018-04-15 | 4 | 8 |
| cookie1 | 2018-04-14 | 2 | 6 |
| cookie1 | 2018-04-13 | 3 | 5 |
| cookie1 | 2018-04-12 | 7 | 10 |
| cookie1 | 2018-04-11 | 5 | 12 |
| cookie1 | 2018-04-10 | 1 | 6 |
| cookie2 | 2018-04-16 | 7 | 7 |
| cookie2 | 2018-04-15 | 9 | 16 |
| cookie2 | 2018-04-14 | 3 | 12 |
| cookie2 | 2018-04-13 | 6 | 9 |
| cookie2 | 2018-04-12 | 5 | 11 |
| cookie2 | 2018-04-11 | 3 | 8 |
| cookie2 | 2018-04-10 | 2 | 5 |
+----------+-------------+-----+------+
比如: 前三行和后二行之间求和操作
select
cookie,
datestr,
pv,
sum(pv) over(partition by cookie order by datestr desc rows between 3 preceding and 2 following) as rn1
from web_pv;
+----------+-------------+-----+------+
| cookie | datestr | pv | rn1 |
+----------+-------------+-----+------+
| cookie1 | 2018-04-16 | 4 | 10 |
| cookie1 | 2018-04-15 | 4 | 13 |
| cookie1 | 2018-04-14 | 2 | 20 |
| cookie1 | 2018-04-13 | 3 | 25 |
| cookie1 | 2018-04-12 | 7 | 22 |
| cookie1 | 2018-04-11 | 5 | 18 |
| cookie1 | 2018-04-10 | 1 | 16 |
| cookie2 | 2018-04-16 | 7 | 19 |
| cookie2 | 2018-04-15 | 9 | 25 |
| cookie2 | 2018-04-14 | 3 | 30 |
| cookie2 | 2018-04-13 | 6 | 33 |
| cookie2 | 2018-04-12 | 5 | 28 |
| cookie2 | 2018-04-11 | 3 | 19 |
| cookie2 | 2018-04-10 | 2 | 16 |
+----------+-------------+-----+------+
默认: 当前行和之前的所有行
select
cookie,
datestr,
pv,
sum(pv) over(partition by cookie order by datestr desc rows between unbounded preceding and current row) as rn1
from web_pv;
+----------+-------------+-----+------+
| cookie | datestr | pv | rn1 |
+----------+-------------+-----+------+
| cookie1 | 2018-04-16 | 4 | 4 |
| cookie1 | 2018-04-15 | 4 | 8 |
| cookie1 | 2018-04-14 | 2 | 10 |
| cookie1 | 2018-04-13 | 3 | 13 |
| cookie1 | 2018-04-12 | 7 | 20 |
| cookie1 | 2018-04-11 | 5 | 25 |
| cookie1 | 2018-04-10 | 1 | 26 |
| cookie2 | 2018-04-16 | 7 | 7 |
| cookie2 | 2018-04-15 | 9 | 16 |
| cookie2 | 2018-04-14 | 3 | 19 |
| cookie2 | 2018-04-13 | 6 | 25 |
| cookie2 | 2018-04-12 | 5 | 30 |
| cookie2 | 2018-04-11 | 3 | 33 |
| cookie2 | 2018-04-10 | 2 | 35 |
+----------+-------------+-----+------+
结论: 请问, 这种操作有什么应用场景:
主要是用于进行级联求值业务操作, 比如需要查看各个阶段运行结果
4.3 窗口函数和lag,lead,first_value,last_value
-
语法: LAG(col,n,DEFAULT)
第一个参数为列名, 第二个参数为往上第n行(可选,默认为1), 第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL) -
语法: lead(col,n,DEFAULT)
第一个参数为列名, 第二个参数为往下第n行(可选,默认为1), 第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL) -
语法: first_value()
取每组的第一个 -
语法: last_value()
取每组的最后一个
上个案例:
数据:
cookie1,2018-04-10 10:00:02,url2
cookie1,2018-04-10 10:00:00,url1
cookie1,2018-04-10 10:03:04,1url3
cookie1,2018-04-10 10:50:05,url6
cookie1,2018-04-10 11:00:00,url7
cookie1,2018-04-10 10:10:00,url4
cookie1,2018-04-10 10:50:01,url5
cookie2,2018-04-10 10:00:02,url22
cookie2,2018-04-10 10:00:00,url11
cookie2,2018-04-10 10:03:04,1url33
cookie2,2018-04-10 10:50:05,url66
cookie2,2018-04-10 11:00:00,url77
cookie2,2018-04-10 10:10:00,url44
cookie2,2018-04-10 10:50:01,url55
创建文件:website_url_info.txt
1) 将website_url_info.txt文件上传到node1的/root/hivedata目录下
2) 在hive中建表
create table web_url(
cookie string,
datestr string,
url string
)row format delimited fields terminated by ',';
3) 加载数据
load data local inpath '/root/hivedata/website_url_info.txt' into table web_url;
4) 校验数据
select * from web_url;
+-----------------+----------------------+--------------+
| web_url.cookie | web_url.datestr | web_url.url |
+-----------------+----------------------+--------------+
| cookie1 | 2018-04-10 10:00:02 | url2 |
| cookie1 | 2018-04-10 10:00:00 | url1 |
| cookie1 | 2018-04-10 10:03:04 | 1url3 |
| cookie1 | 2018-04-10 10:50:05 | url6 |
| cookie1 | 2018-04-10 11:00:00 | url7 |
| cookie1 | 2018-04-10 10:10:00 | url4 |
| cookie1 | 2018-04-10 10:50:01 | url5 |
| cookie2 | 2018-04-10 10:00:02 | url22 |
| cookie2 | 2018-04-10 10:00:00 | url11 |
| cookie2 | 2018-04-10 10:03:04 | 1url33 |
| cookie2 | 2018-04-10 10:50:05 | url66 |
| cookie2 | 2018-04-10 11:00:00 | url77 |
| cookie2 | 2018-04-10 10:10:00 | url44 |
| cookie2 | 2018-04-10 10:50:01 | url55 |
+-----------------+----------------------+--------------+
看我操作:
演示 lad
select
cookie,
datestr,
url,
lag(datestr,2) over(partition by cookie order by datestr desc) as rn1
from web_url;
+----------+----------------------+---------+----------------------+
| cookie | datestr | url | rn1 |
+----------+----------------------+---------+----------------------+
| cookie1 | 2018-04-10 11:00:00 | url7 | NULL |
| cookie1 | 2018-04-10 10:50:05 | url6 | NULL |
| cookie1 | 2018-04-10 10:50:01 | url5 | 2018-04-10 11:00:00 |
| cookie1 | 2018-04-10 10:10:00 | url4 | 2018-04-10 10:50:05 |
| cookie1 | 2018-04-10 10:03:04 | 1url3 | 2018-04-10 10:50:01 |
| cookie1 | 2018-04-10 10:00:02 | url2 | 2018-04-10 10:10:00 |
| cookie1 | 2018-04-10 10:00:00 | url1 | 2018-04-10 10:03:04 |
| cookie2 | 2018-04-10 11:00:00 | url77 | NULL |
| cookie2 | 2018-04-10 10:50:05 | url66 | NULL |
| cookie2 | 2018-04-10 10:50:01 | url55 | 2018-04-10 11:00:00 |
| cookie2 | 2018-04-10 10:10:00 | url44 | 2018-04-10 10:50:05 |
| cookie2 | 2018-04-10 10:03:04 | 1url33 | 2018-04-10 10:50:01 |
| cookie2 | 2018-04-10 10:00:02 | url22 | 2018-04-10 10:10:00 |
| cookie2 | 2018-04-10 10:00:00 | url11 | 2018-04-10 10:03:04 |
+----------+----------------------+---------+----------------------+
说明: 可以实现让当前行的数据和之前或者之后的某一行数据并列放置在一行
-- 默认值
select
cookie,
datestr,
url,
lead(datestr,2,'1970-01-01 00:00:00') over(partition by cookie order by datestr desc) as rn1
from web_url;
+----------+----------------------+---------+----------------------+
| cookie | datestr | url | rn1 |
+----------+----------------------+---------+----------------------+
| cookie1 | 2018-04-10 11:00:00 | url7 | 2018-04-10 10:50:01 |
| cookie1 | 2018-04-10 10:50:05 | url6 | 2018-04-10 10:10:00 |
| cookie1 | 2018-04-10 10:50:01 | url5 | 2018-04-10 10:03:04 |
| cookie1 | 2018-04-10 10:10:00 | url4 | 2018-04-10 10:00:02 |
| cookie1 | 2018-04-10 10:03:04 | 1url3 | 2018-04-10 10:00:00 |
| cookie1 | 2018-04-10 10:00:02 | url2 | 1970-01-01 00:00:00 |
| cookie1 | 2018-04-10 10:00:00 | url1 | 1970-01-01 00:00:00 |
| cookie2 | 2018-04-10 11:00:00 | url77 | 2018-04-10 10:50:01 |
| cookie2 | 2018-04-10 10:50:05 | url66 | 2018-04-10 10:10:00 |
| cookie2 | 2018-04-10 10:50:01 | url55 | 2018-04-10 10:03:04 |
| cookie2 | 2018-04-10 10:10:00 | url44 | 2018-04-10 10:00:02 |
| cookie2 | 2018-04-10 10:03:04 | 1url33 | 2018-04-10 10:00:00 |
| cookie2 | 2018-04-10 10:00:02 | url22 | 1970-01-01 00:00:00 |
| cookie2 | 2018-04-10 10:00:00 | url11 | 1970-01-01 00:00:00 |
+----------+----------------------+---------+----------------------+
-- first_value
select
cookie,
datestr,
url,
first_value(datestr) over(partition by cookie order by datestr desc) as rn1
from web_url;
+----------+----------------------+---------+----------------------+
| cookie | datestr | 数量 | rn1 |
+----------+----------------------+---------+----------------------+
| cookie1 | 2018-04-10 11:00:00 | url7 | 2018-04-10 11:00:00 |
| cookie1 | 2018-04-10 10:50:05 | url6 | 2018-04-10 11:00:00 |
| cookie1 | 2018-04-10 10:50:01 | url5 | 2018-04-10 11:00:00 |
| cookie1 | 2018-04-10 10:10:00 | url4 | 2018-04-10 11:00:00 |
| cookie1 | 2018-04-10 10:03:04 | 1url3 | 2018-04-10 11:00:00 |
| cookie1 | 2018-04-10 10:00:02 | url2 | 2018-04-10 11:00:00 |
| cookie1 | 2018-04-10 10:00:00 | url1 | 2018-04-10 11:00:00 |
| cookie2 | 2018-04-10 11:00:00 | url77 | 2018-04-10 11:00:00 |
| cookie2 | 2018-04-10 10:50:05 | url66 | 2018-04-10 11:00:00 |
| cookie2 | 2018-04-10 10:50:01 | url55 | 2018-04-10 11:00:00 |
| cookie2 | 2018-04-10 10:10:00 | url44 | 2018-04-10 11:00:00 |
| cookie2 | 2018-04-10 10:03:04 | 1url33 | 2018-04-10 11:00:00 |
| cookie2 | 2018-04-10 10:00:02 | url22 | 2018-04-10 11:00:00 |
| cookie2 | 2018-04-10 10:00:00 | url11 | 2018-04-10 11:00:00 |
+----------+----------------------+---------+----------------------+
应用场景
需要将当前行和之前或者之后的任意一行进行比对统计计算操作的时候, 都可以使用 这些函数来解决
比如: 计算流失率