前言
学习大数据框架,hadoop是许多其他框架的基础,因此需要掌握如何快速搭建hadoop的应用环境
通常来说,hadoop本地模式,伪分布模式和完全分布式,本篇以伪分布式单节点为例,快速在win10电脑上搭建出单节点的hadoop的运行环境,linux环境下可类似的操作
环境准备
1、前置准备
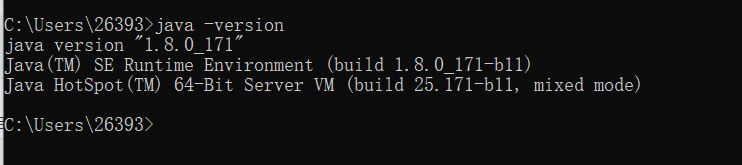
JDK环境,至少JDK1.8,相信JDK的环境安装就不再多说了吧,安装之后,确认下是否安装成功
2、下载合适版本的hadoop安装包
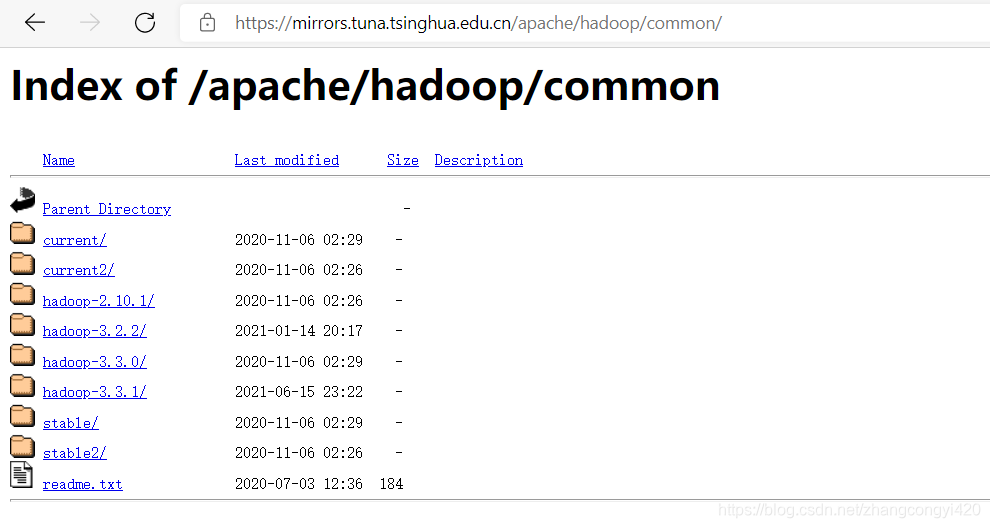
前往如下链接,https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/,本篇用的是2.10.1版本
3、配置环境变量
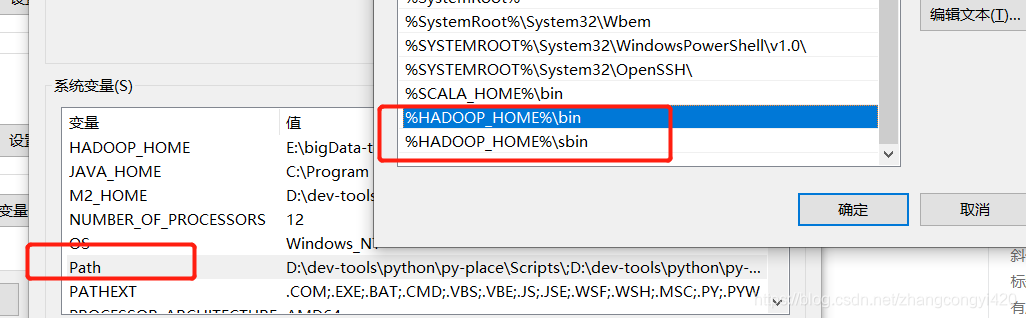
下载本地本地的某个目录之后,开始配置hadoop的环境变量
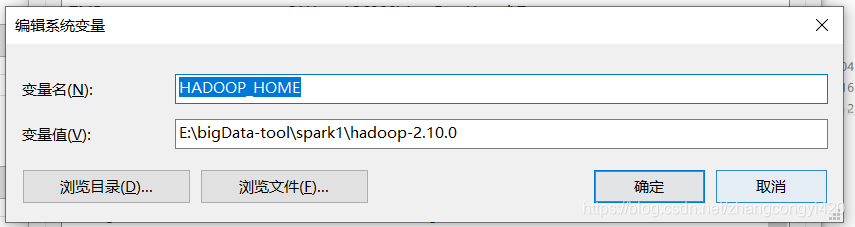
主要是将bin和sbin目录配置到环境变量中,新建环境变量:HADOOP_HOME,值为bin的全路径
然后配置到path路径中,这里需要配置2个,bin和sbin,2个都一起配置到环境变量中
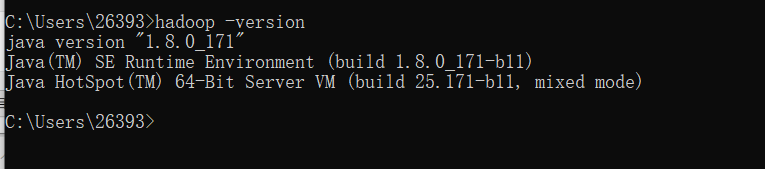
以上配置完毕后,可进入cmd窗口,通过:hadoop -version查看是否配置成功(出现如下提示,表示配置完成)
4、修改核心配置文件
搭建hadoop最关键的一步,就是几个配置文件的参数修改,主要包括4个核心配置文件,
core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml,初学者可参考本篇提供的配置样例,在后续的深入学习中,了解各个配置文件和参数的深入含义
进入:E:\bigData-tool\spark1\hadoop-2.10.0\etc\hadoop目录,找到上面的几个配置文件,依次修改,在修改之前,需要创建几个文件目录,用于保存hadoop运行过程中产生的数据文件
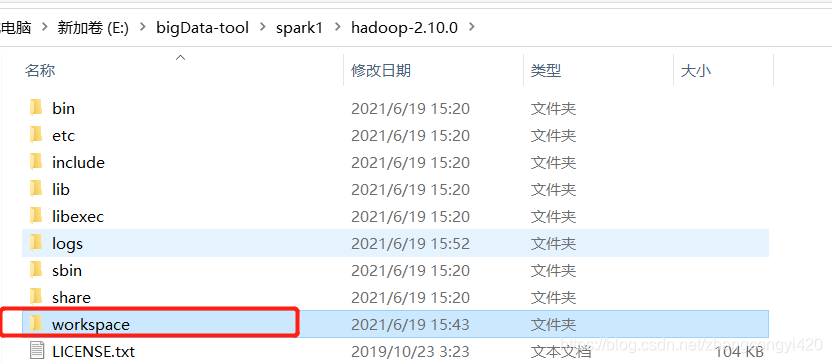
我这里在主目录下创建一个workspace目录,在workspace内部分别创建如下几个文件夹

core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/E:/bigData-tool/spark1/hadoop-2.10.0/workspace/tmp</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/E:/bigData-tool/spark1/hadoop-2.10.0/workspace/name</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/E:/bigData-tool/spark1/hadoop-2.10.0/workspace/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/E:/bigData-tool/spark1/hadoop-2.10.0/workspace/data</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9001</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hahoop.mapred.ShuffleHandler</value>
</property>
</configuration>
hadoop-env.cmd
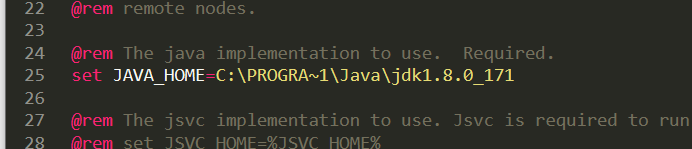
这一步非常重要,通常很多开发的小伙伴安装JDK时候会默认安装在C盘目录下,这里直接将JDK的路径拷贝过来,会报错,导致后续的操作无法进行,本人已经踩过坑了,正确的配置如下:
set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_171
5、初始化格式化namenode
进入smd窗口,输入:hdfs namenode -format,出现如下效果,说明初始化成功
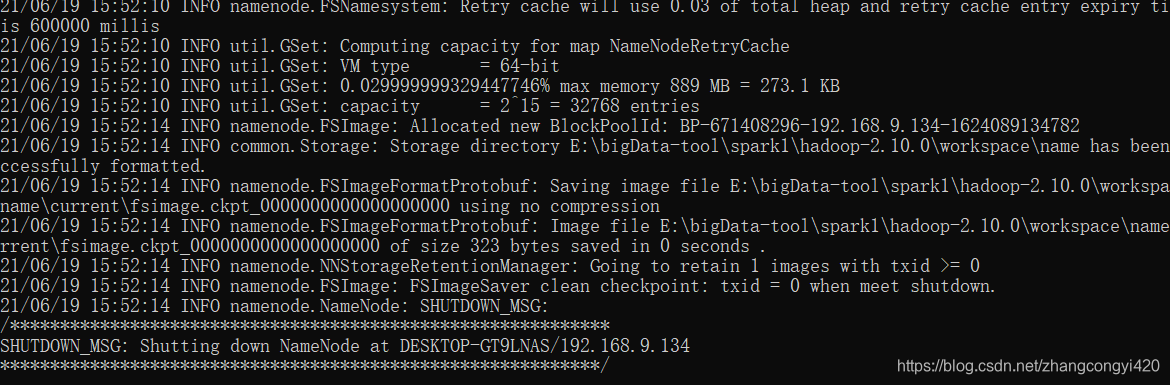
6、启动(停止)hadoop
完成上面的操作之后,cmd黑窗口进入hadoop的sbin目录,直接:start-all.cmd开启服务

输入stop-all.cmd关闭服务

开启服务之后,会快速弹出4个黑窗口,然后浏览器访问:
http://localhost:8088/cluster ,出现如下界面表示环境搭建成功
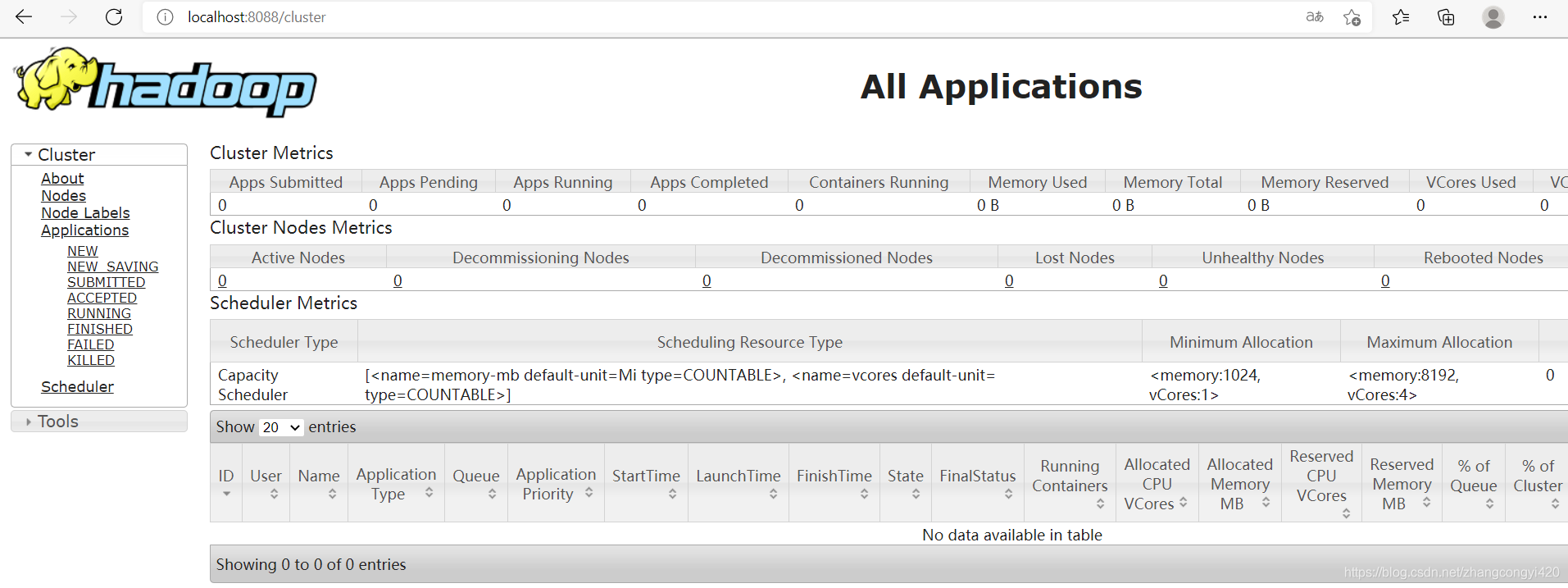
本篇到此结束,最后感谢观看!