文章目录
一、业务背景
1.网易游戏ETL服务概况
基础数据:主要日志方式采集
数据结构:非结构化或半结构化数据
流程:日志数据通过数据集成ETL才可以入库至实时或离线的数据仓库。
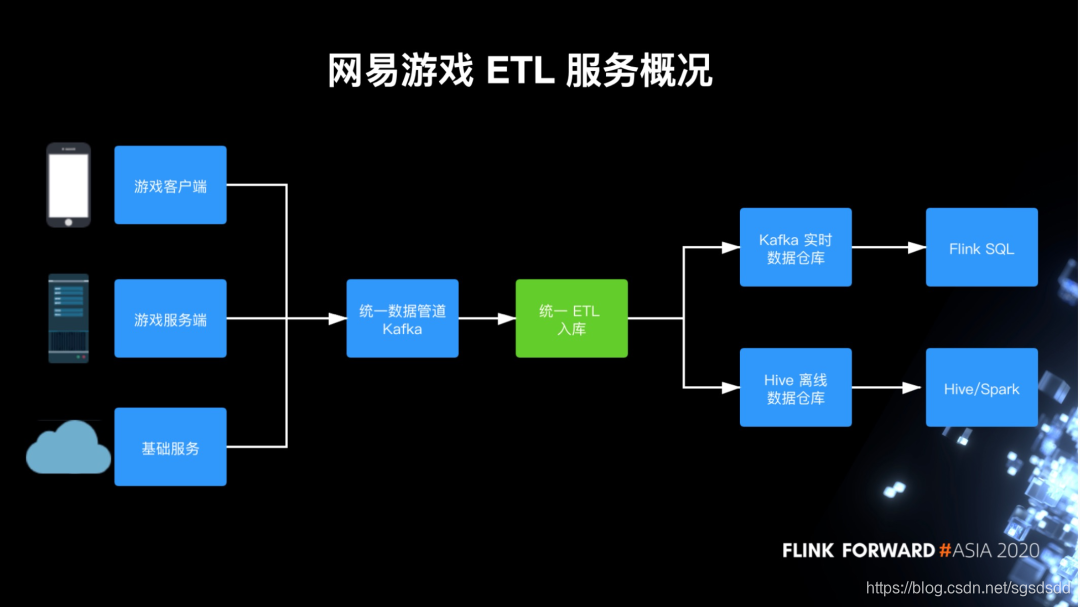
数据集成的数据流:主要有游戏客户端日志、游戏服务端日志和其他周边基础的日志,比如Nginx access log、数据库日志等等。
流程:这些日志会被采集到统一的Kafka数据管道,然后经由ETL入库服务写入到Hive离线数据仓库或者Kafka实时数据仓库。
2.网易游戏流式ETL需求特点
(1)数据库:
MongoDB(游戏行业常用)
(2)数据异构问题:
没有一个线上业务的准确的schema可以依赖,在实际数据处理中,多字段或少字段,甚至一个字段因为玩法迭代变为完全不同的格式。为ETL的数据清洗带来了较高的成本
(3)反范式设计:
会刻意以复杂内嵌的字段来避免表间的join。
好处:数据集成阶段,不需要去实时地去join多个数据流
坏处:数据结构可能非常复杂,多层嵌套十分常见
(4)实时数仓:
复用现有的ETL管道,提取转换一次,加载到实时离线两个数据仓库
(5)异常处理:
需要提供完善的异常处理,让业务可以及时得知数据异常和通过流程修复数据
3.日志分类及特点
(1)运营日志:
玩家行为事件,比如登录账号、领取礼包等等。
数据结构:有固定的格式,即特定的header+json的文本格式。
用途:主要用来做数据报表、数据分析和游戏内推荐,比如玩家的匹配组队推荐。
(2)业务日志:
玩家行为以为的业务事件,如Nginx access log、CDN下载日志等等
数据结构:无固定格式,可能是二进制也有可能是文本
用途:类似运营日志,但更加丰富
(3)程序日志记录:
程序的运行情况,即日志框架打的INFO、ERROR这类日志。通常写入ES,但数量过大或需要提取指标分析时,也会写入数据仓库
用途:检索定位运行问题
4.网易游戏ETL服务剖析
针对日志分类,提供3类ETL入库服务
(1)运营日志专用的ETL:
这会根据运营日志模式进行定制化
(2)通用的面向文本日志的EntryX ETL服务:
会服务于运营日志以外的所以日志
(3)Entry无法支持的特殊ETL需求:
比如有加密或者需要进行特殊转换的数据,这种情况下我们会针对性地开发ad-hoc作业来处理
二、运营日志专用ETL
1.运营日志ETL发展历程
2013年,基于Hadoop Streaming + python预处理/后处理的第一版离线ETL框架
2017年,基于Spark Streaming的第二个版本,相当于一个POC,但因为微批调优困难且小文件多等问题没有上线应用
2018年,基于Flink DataStream的第三版运营日志ETL服务。因为长时间的业务积累的很多python的ETL脚本,然后新版最重要的一点就是支持这些python UDF的无缝迁移
2.运营日志ETL架构
(1)早期的hadoop Streaming版本:
数据首先被dump到HDFS上,然后Hadoop Streaming启动Mapper来读取数据并通过标准输入的方式传递给python脚本,之后由python脚本执行模块
注:python脚本三个模块
《1》预处理UDF:这里通常进行基于字符串的替换,一般用作规范化数据
《2》解析/转换:根据运营日志的格式来解析数据,并进行通用转换,比如滤掉测试服数据
《3》针对字段的转换:比如常见的汇率转换,之后这些数据会通过标准输出返回给Mapper,然后Mapper再将数据批量写入Hive目录中
(2)Flink重构:
数据源由HDFS改为直接对接Kafka,而IO模块则用Flink的Source/Sink Operator来代替原本的Mapper,然后中间通用模块可以直接重写为Java,剩余的预处理和后处理是我们需要支持Python UDF的地方
3.Python UDF实现(针对Flink重构)
(1)架构:
在Flink ProcessFunction之上加入了Runner层,Runner层负责跨语言的执行
(2)技术选型:
Jython,没有选择Py4j,主要因为Jython可以直接在JVM里面去完成计算,不需要额外启动python进程,这样开发和运维管理成本都比较低,而Jython带来的限制,比如不支持pandas类基于c的库,这些对python UDF来说可接受
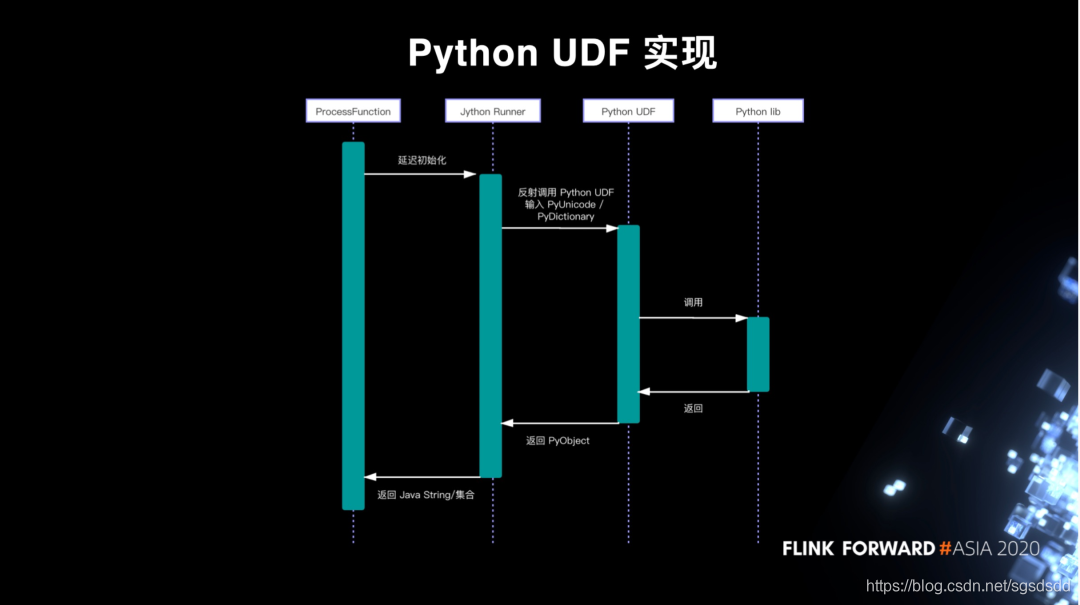
(3)调用链:
ProcessFunction在TaskManager被调用时会在open函数延迟初始化Runner,这是因为Jython是不可序列化的。Runner初始化时会负责资源准备,包括将依赖的模块假如pythonpath,然后根据配置反射调用UDF函数
(4)执行过程:
调用时,对于预处理UDF Runner会把字符串转换为Jython的PyUnicode类型,而对于后处理UDF则会把解析后的Map对象转为Jython的PyDcitionary,分别作为两者的输入。UDF可以调用其他模块进行计算,最终返回PyObject,然后Runner再将其转换成Java String或者Map,返回给ProcessFunction输出
4.运营日志ETL运行时
作业初始化:
首先提供了通用的Flink jar,当我们生成并提交ETL作业到作业平台时,调度器会执行通用的main函数构建Flink JobGraph。这是我们的配置中心,也就是ConfigServer,拉去ETL配置。ETL配置中包含使用到的python模块,后端服务会扫描其中引用到的其他模块,把他们统一作为资源文件通过YARN分发功能上传到HDFS上。在Flink JobManager和TaskManager启动时,这些python资源都会被YARN自动同步到工作目录上备用。
对于一些不影响Flink JobGraph的轻量级变更支持热更新。实现的方法是每个TaskManager启动一个热更新线程,定时轮询配置中心同步配置
三、EntryX通用ETL
通用可以分为两层意义,首先是数据格式上的通用,支持非结构化到结构化的各种文本数据,其次是用户群体的通用,目标童虎覆盖数据分析、数据开发等传统用户,和业务程序、策划这些数据背景较弱的用户

1.EntryX的三个基本概念
(1)Source
Source是ETL作业的输入源,通常是从业务端采集而来的原始日志topic,或者是经过分发过滤后的topic。这些topic可能只包含一种日志,但更多情况下会包含多种异构日志。
(2)StreamTable(流表)
流表定义了ETL管道的主要元数据,包括如何转换数据,还有根据转换好的数据定义的流表schema,将数据schema化。
流表schema是最为关键的概念,相当于table ddl,主要包括字段名、字段数据类型、字段约束和表属性等。为了更方便对接上下游,流表schema使用的是自研的SQL-Like的类型系统,里面会支持我们一些拓展的数据类型,比如json类型
(3)Sink:
负责流表到目标存储的物理表的映射,比如映射到目标Hive表,这里主要需要schema的映射关系来提取字段,并将数据转换为目标表的存储格式,加载到目标表
2.EntryX管道
蓝色部分是外部存储系统,绿色部分是EntryX的内部模块
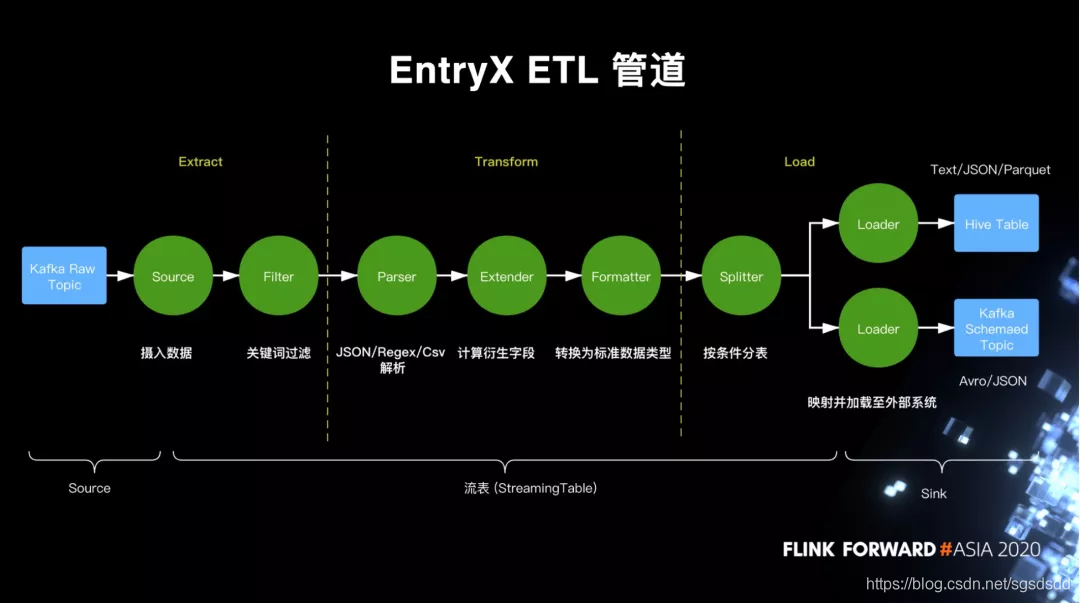
(1)数据首先从对接采集的原始数据Topic流入,经过Source摄入到Filter。
(2)Filter负责根据关键词过滤数据,
通常来说我们要求过滤完的数据是有相同schema的。经过这两步数据完成Extract,到transform阶段
(3)transform第一步:
解析数据Parser:Parser支持JSON/Regex/csv三种解析,基本可以覆盖所有案例
(4)transform第二步:
对数据进行转换,这是由Extender负责的。Extender通过内置函数或UDF计算衍生字段,最常见的是将 JSON 对象拉平展开,提取出内嵌字段
(5)transform第三步:
Formatter:根据之前用户定义的字段逻辑类型,将字段的指转为对应的物理类型。比如一个逻辑类型为BIGINT的字段,统一转为Java long的物理类型
(6)load阶段第一步:
Splitter:决定数据应该加载到哪个表。Splitter模块会根据每个表的入库条件来分流数据
(7)load阶段第二步:
loader:负责将数据写到具体的外部存储系统。目前支持Hive/Kafka两种存储,Hive支持Text/Parquet/JSON 三种格式,而 Kafka 支持 JSON 和 Avro 两种格式。
3.实时离线统一Schema
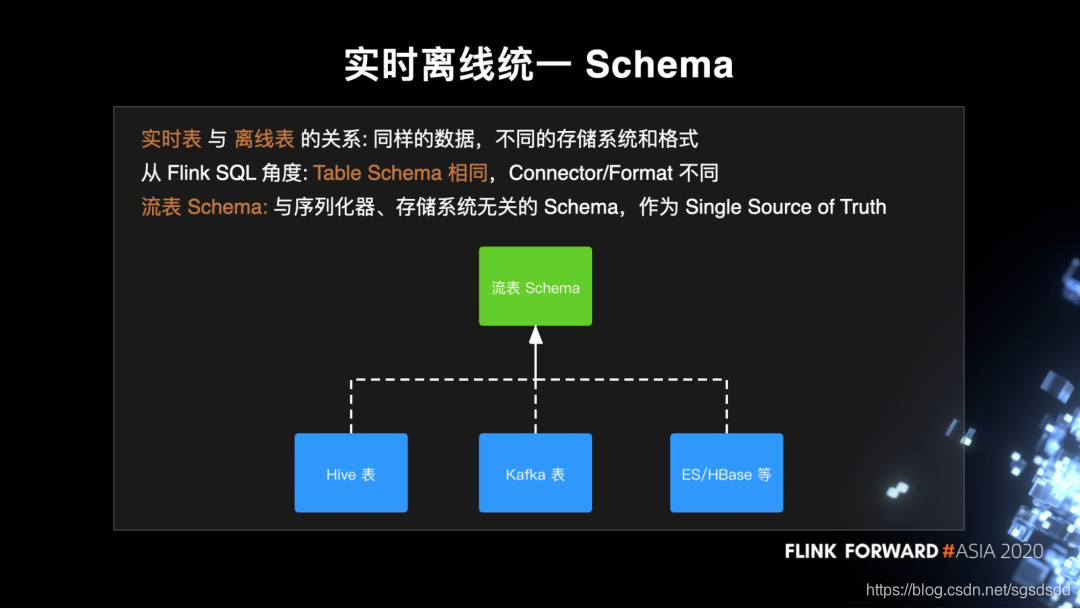
在Entry的设计里数据可以被写入实时和离线两个数据仓库,即同一份数据,但在不同的存储系统中以不同格式表示。从Flink SQL的角度来说schema部分相同,但conneor和format不同的两个表。但connector和format(即存储系统和存储格式)是相对稳定的,而schema部分经常随业务变更。
4.实时数据仓库集成
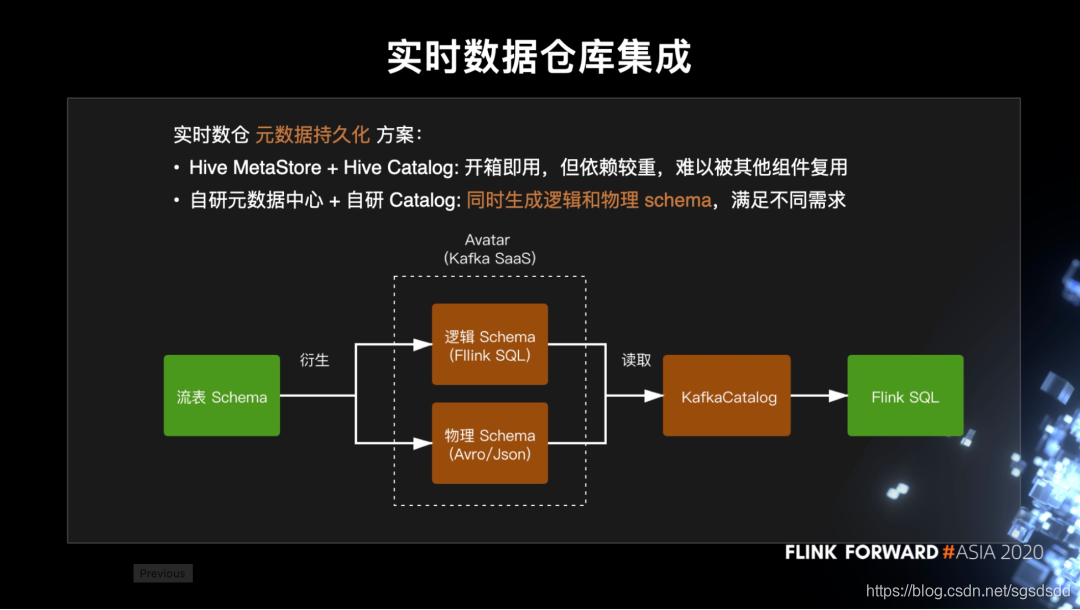
EntryX作为实时仓库的统一入口
(1)实时数仓的常见问题是:
Kafka并没有原生支持schema元数据的持久化。
(2)目前主流解决方案:
基于hive MetaStore来保存Kafka表的元数据,并复用hiveCatalog来直接对接到Flink SQL
(3)Hive MetaStore几个问题:
《1》实时作业里引入Hive依赖并与Hive耦合,导致定义的表很难被其他组件复用,包括 Flink DataStream 用户
《2》已经有 Kafka SaaS 平台 Avatar 来管理物理 schema,比如 Avro schema,如果再引入 Hive MetaStore 会导致元数据的割裂.因此,我们是拓展了 Avatar 平台的 schema 注册中心,同时支持逻辑 schema 和物理 schema。
(4)实时数仓和EntryX的集成关系:
首先我们有 EntryX 的流表 schema,在新建 Sink 的时候调用 Avatar 的 schema 接口,根据映射关系生成逻辑 schema,而 Avatar 再根据 Flink SQL 类型与物理类型的映射关系生成 topic 的物理 schema。
(5)自研的 KafkaCatalog:
与 Avatar schema 注册中心配套的还有我们自研的 KafkaCatalog,它负责读取 topic 的逻辑和物理 schema 来生成 Flink SQL 的 TableSource 或 TableSink。
(6)Flink SQL以外的用户:
而对于一些 Flink SQL 以外的用户,比如 Flink DataStream API 的用户,他们也可以直接读取物理 schema 来享受到数据仓库的便利。
5.EntryX运行时
和运营日志 ETL 类似,在 EntryX 运行时,系统会基于通用的 jar 和配置生成 Flink 作业,但这里有两种情况需要特别处理。
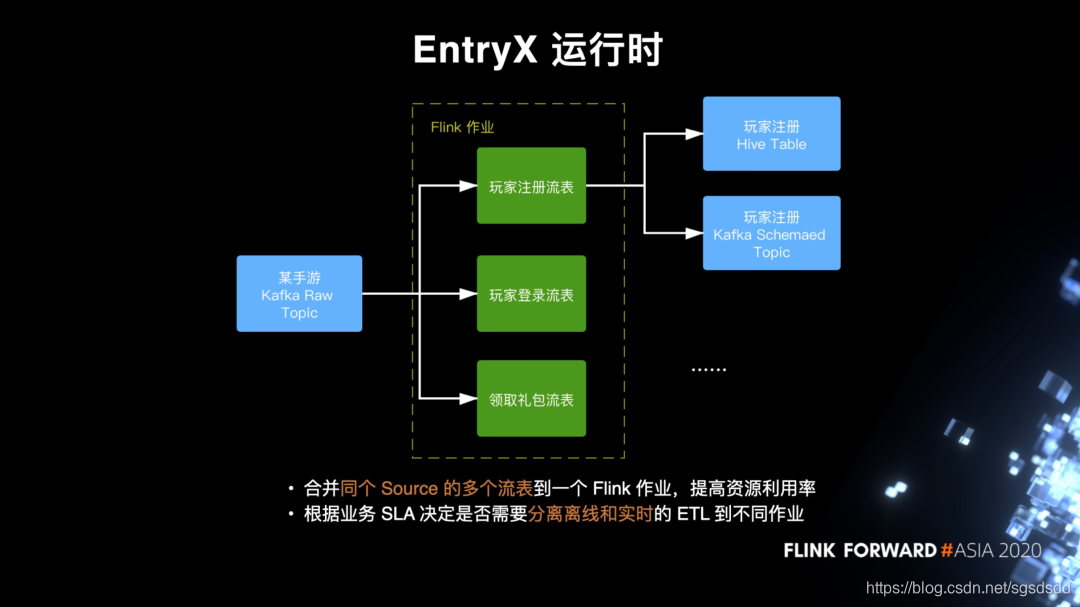
(1)第一种情况
一个 Kafka topic 往往有几十甚至上千种日志,那么对应其实有也几十甚至上千的流表,如果每个流表都单独运行在一个作业里,那么一个 topic 会可能会被读上千遍,这是非常大的浪费。因此,在作业运行时提供一个优化策略,可以将同个 source 的不同流表合并到一个作业里跑。比如图中,某个手游上传了 3 种日志到 Kafka,用户分别配置了玩家注册、玩家登录、领取礼包三个流表,那么我们可以这三个流表合并起来到一个作业,共享同一个 Kafka Source。
(2)第二种情况
一般情况下我们可以按照之前“提取转换一次,加载一次”的思路来将数据同时写到 Hive 和 Kafka,但是由于 Hive 或者说 HDFS 毕竟是离线系统,实时性比较差,写入在一些负载比较高的 HDFS 老集群经常会出现反压,同时阻塞上游,导致 Kafka 的写入也受到影响。在这种情况下,我们通常要分离加载到实时和离线的 ETL 管道,具体会取决于业务的 SLA 还有 HDFS 的性能。
四.调优实践
1.HDFS写入调优

(1)问题
流式写入 HDFS 场景中老生常谈的一个问题便是小文件过多。通常来说小文件和实时性是鱼与熊掌不可兼得。如果要延迟低,那么我们需要频繁地滚动文件来提交数据,必然导致小文件过多。
注:小文件过多带来的问题:
<1>
HDFS 集群管理角度看,小文件会占用大量的文件数和 block 数,浪费 NameNode 内存
<2>
从用户角度看,读写效率都会降低,因为写的时候要更频繁地调用 RPC 和 flush 数据,造成更多的阻塞,有时甚至造成 checkpoint 超时,而读时则需要打开更多的文件才能读完数据。
(2)数据流预分区
优化小文件问题时做的一点调优是:对数据流先做一遍预分区,具体来说,便是在 Flink 作业内部先基于目标 Hive 表进行一次 keyby 分区,让同一个表的数据尽量集中在少数的几个 subtask 上。
2.基于 OperatorState 的 SLA 统计
(1)背景:
我们的用户经常会通过 Web UI 来进行调试和问题的排查,比如不同 subtask 的输入输出数目,但这些 metric 会因为作业重启或者 failover 而重置,因此我们开发了基于 OperatorState 的 SLA-Utils 工具来统计数据的输入和分类输出
(2)SLA-Utils
<1>标准的 metric:
recordsIn/recordsOut/recordsDropped/recordsErrored,分别对应输入记录数/正常输出记录数/被过滤掉的记录数/处理异常的记录数。通常来说 recordsIn 就等于后面三者的总和
<2>用户可以自定义的 metric:
通常可以用于记录更详细的原因,比如是 recordsEventTimeDropped 代表数据是因为 event time 被过滤的。
<3>在运行时动态注册的 TTL metric:
这种 metric 通常有动态生成的日期作为前缀,在经过 TTL 的时间之后被自动清理。TTL metric 主要可以用于做天级别时间窗口的统计
(3)暴露给用户:
通过 Accumulater 的方式来暴露,
<1>优点:
Web UI 有支持,开箱即用,同时 Flink 可以自动合并不同的 subtask 的 metric
<2>缺点:
没有办法利用 metric reporter 来 push 到监控系统,同时因为 Acuumulater 是不能在运行时动态注销的,所以使用 TTL metric 会有内存泄漏的风险
3.数据容错及恢复
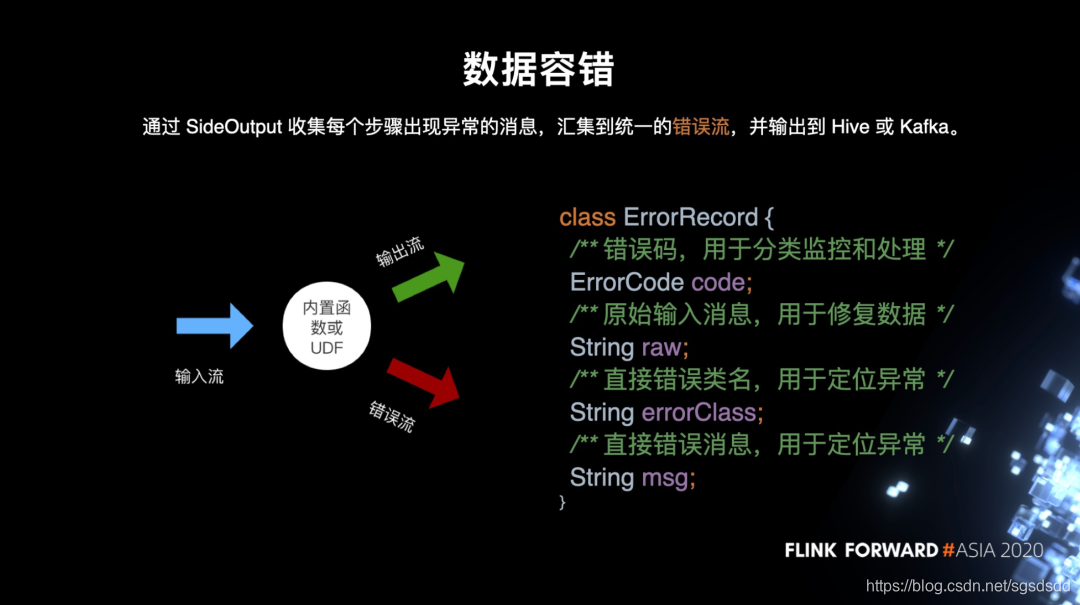
(1)存储异常数据:
用 SideOutput 来收集 ETL 各环节中出错的数据,汇总到一个统一的错误流。错误记录中包含我们预设的错误码、原始输入数据以及错误类和错误信息。一般情况下,错误数据会被分类写入 HDFS,用户通过监控 HDFS 目录可以得知数据是否正常。
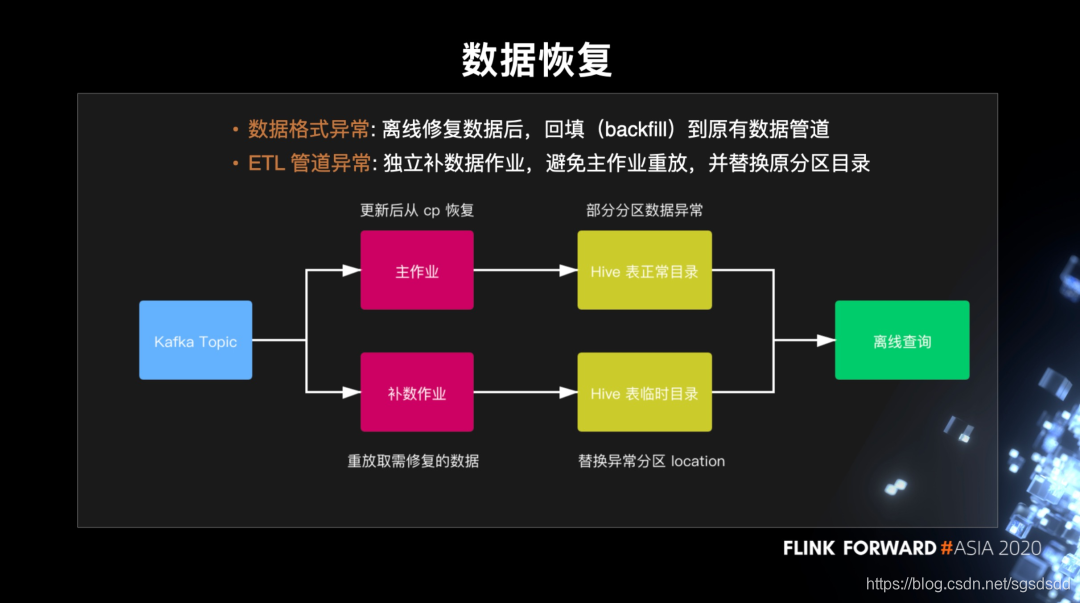
(2)恢复数据
<1>数据格式异常:
比如日志被截断导致不完整或者时间戳不符合约定格式,这种情况下我们一般通过离线批作业来修复数据,重新回填到原有的数据管道。
<2> ETL 管道异常:
首先更新线上的流表配置为最新,保证不再产生更多异常数据,这时 Hive 里面仍有部分分区是异常的。然后,我们发布一个独立的补数作业来专门修复异常的数据,输出的数据会写到一个临时的目录,并在 hive metastore 上切换 partition 分区的 location 来替换掉原来的异常目录。因此这样的一个补数流程对离线查询的用户来说是透明的。最后我们再在合适的时间替换掉异常分区的数据并恢复 location。
五.未来规划

1.数据湖的支持
目前我们的日志绝大多数都是 append 类型,不过随着 CDC 和 Flink SQL 业务的完善,我们可能会有更多的 update、delete 的需求,因此数据湖是一个很好的选择。
2.会提供更加丰富的附加功能
比如实时的数据去重和小文件的自动合并。这两个都是对业务方非常实用的功能。
3.支持 PyFlink
目前我们的 Python 支持只覆盖到数据集成阶段,后续数据仓库的 Python 支持我们是希望通过 PyFlink 来实现。