AI音箱的原理
简单的说,音箱工作的时,麦列始终处于拾音状态(对声音进行采样,量化)。进过基本的信号处理(静音检测、降噪等),唤醒模块会判断是否出现唤醒词,是的话就进行更复杂的语音信号处理,开始真正的语音交互流程。
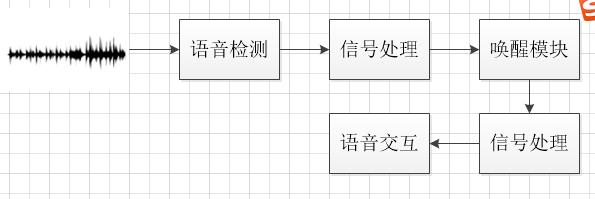
1.前端信号的处理
1.1语音检测(VAD voice activity detection)
准确的检测音频信号的语音段起始位置,从而分离出语音段和非语音段
1.2降噪
现实环境中存在噪声,通过降低噪声的干扰,降低语音识别难度。
常用的有LMS和维纳滤波。
1.3声学回声消除(AEC)
麦克风收集声音的时候,去除自身播放的声音。否则在播放音乐的时候,人的声音可能被掩盖。
1.4去混响处理
避免声音的反射对音箱的干扰。
1.5声源定位
确定人的位置。
1.6波束形成
降噪去混响的作用
2唤醒
经过语音检测后的信息,只能音箱会在检测到唤醒词之后才开始复杂的信号处理(声源定位等)和后续的交互。
3语音交互
语音输入-语音识别-自然语言的理解-对话管理控制借口-对话管理-自然语言生出-语音合成-语音输出。

3.1语音识别(ASR)
将语音信号转化成文本。
3.2自然语言理解(NLU)
要结合特定的使用场景和现有技术。
领域分类:根据识别命令所属领域,领域是封闭的集合。
意图分类:在相应的领域,识别用户的意图。
实体抽取:确定意图的参数。比如歌手名字和歌曲名称。
3.3对话管理:
对一些追加性的问题的优化。比如明天上海天气怎么样?北京呢?
3.4自然语音的生成(NLG)
采用预先设计的文本模块生成文本输出。
即将为您播放的歌曲是谁的什么歌。
3.5语音合成
TTS使机器能够像人一样朗读给定的文本。