Python—Tornado框架(四)异步非阻塞框架
部分博文参考:https://www.cnblogs.com/wupeiqi/articles/5702910.html
一、异步非阻塞框架介绍
1、初步介绍
a、同步

测试:一个等待十秒,另一个不用等待,先访问需要等待的,再访问不用等待的,可以发现两个都要等待。先来先处理,后来的等待处理,这是同步。
b、异步非阻塞
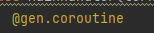
导入tornado的gen,Future模块

接着需要加入一个装饰器:
还没完:
 这时,即便在等待期间,也不会阻塞其他任务,其他任务依然能执行。
这时,即便在等待期间,也不会阻塞其他任务,其他任务依然能执行。
看上述代码,似乎没有用到future,但是这个future才是最关键的。
2、Future
Future里面有个 result,done。
框架里,会监听返回去的这个future,result如果没有值,这个请求就不断开,还没处理完。5秒之后处理完了,result里写了个值(True),future感觉到有值,Tornado就会断开。断开是通过执行回调函数断开。
Future两大功能:
1、发来请求,yield Future,挂起当前请求,当前线程处理请他请求。
2、某个时刻给Future设置了值,当前挂起的请求返回。
a、Tornado支持远程发送异步IO模块
 红色框框内这一块,就是执行http相关任务时,还能执行其他任务
红色框框内这一块,就是执行http相关任务时,还能执行其他任务
这里依然使用的是future。
3、

请求来了一直挂起,当另外一个请求来了后会终止第一个请求。
4、总结三个案例
1、阻塞期间能够处理其他请求。
2、请求来了之后,向远程发起另外一个请求。这个远程请求什么时候返回,就什么时候终止。
3、请求来了永远挂起,等待某一时刻主动给这个future设置,中断请求。
二、自定义Web框架
1、自定义Web(同步)框架
先简单的写一点:

这一部分封装起来,命名函数 run,
接着(模仿路由匹配):

然后,开始处理url:

写一个类,来处理url相关信息:
class HttpRequest(object): # 处理路由相关信息
"""
用户封装用户请求信息
"""
def __init__(self, content):
"""
:param content:用户发送的请求数据:请求头和请求体
"""
self.content = content
self.header_bytes = bytes()
self.header_dict = {}
self.body_bytes = bytes()
self.method = ""
self.url = ""
self.protocol = ""
self.initialize()
self.initialize_headers()
def initialize(self): # 处理请求头和请求体
temp = self.content.split(b'\r\n\r\n', 1)
if len(temp) == 1:
self.header_bytes += temp
else:
h, b = temp
self.header_bytes += h
self.body_bytes += b
@property
def header_str(self):
return str(self.header_bytes, encoding='utf-8')
def initialize_headers(self):
headers = self.header_str.split('\r\n')
first_line = headers[0].split(' ')
if len(first_line) == 3:
self.method, self.url, self.protocol = headers[0].split(' ')
for line in headers:
kv = line.split(':')
if len(kv) == 2:
k, v = kv
self.header_dict[k] = v
接着我们可以查看下:


既然都能取到,那么我们就能取到URL,处理URL相关:

接着测试错误跟正确的时候:
错误的时候(路由错误):
这时候加了sleep测试,是能发现不能异步处理,只能同步。