我也不知道什么类型 只当是自己的笔记吧
1 introduction
As CNNs become increasinglydeep,a new research problem emerges : as information about theinput or gradientpasses through many layers, it can vanish and“wash out” by the time it reaches the end (or beginning) of the network.(出现问题 梯度消失)
Many recent publications address this or related problems.
1 ResNets [11] and Highway Networks [33] bypass signal from one layer to the next via identity connections.
2 Stochastic depth [13] shortens ResNets by randomly dropping layers during training to allow better information and gradient flow.
3 FractalNets [17] repeatedly combine several parallel layer sequences with different number of convolutional blocks to obtain a large nominal depth, while
maintaining many short paths in the network.
(过去提出的相应解决方案)
Although these different approaches vary in network topology and training procedure, they all share a key characteristic:they create short paths from early layers to later layers.(解决方案共同点)
In this paper, we connectall layers(with matching feature-map sizes) directly with each other.(我们的方案)
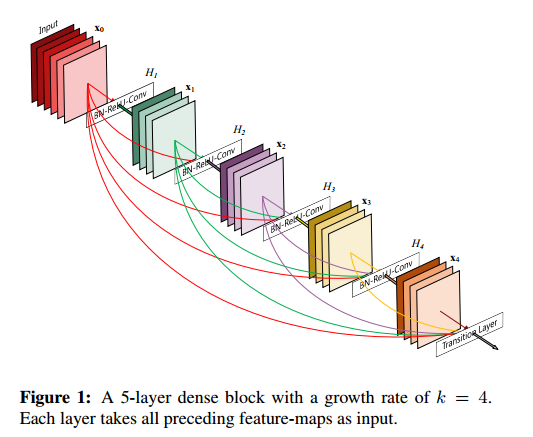
Crucially, in contrast to ResNets, we never combine features through summation before they are passed into a layer; instead, we combine features by concatenating them. (对比ResNet的summation,我们是concatenation)
A possibly counter-intuitive effect of this dense connectivity pattern is that it requires fewer parameters than traditional convolutional networks, as there is no need to relearn redundant feature-maps.
Besides better parameter efficiency, one big advantage of DenseNets is their improved flow of information and gradients throughout the network, which makes them easy to train.
Further, we also observe that denseconnections have a regularizing effect, which reduces overfitting on tasks with smaller training set sizes.(一些我们方案的优势)
2. Related Work
先吧拉一堆历史。先是说Highway Networks用到了bypassing paths方法。 The bypassing paths are presumed to be the key factor that eases the training of these very deep networks. This point is further supported by ResNets[11], in which pure identity mappings are used as bypassing paths. 并取得突破成绩
Recently,stochastic depth was proposed as a way to successfully train a 1202-layer ResNet [13]. Stochastic depth improves the training of deep residual networks by dropping layers randomly during training. This shows that not all layers may be needed and highlights that there is a great amount of redundancy in deep (residual) networks. Our paper was partly inspired by that observation. (ResNets with pre-activation also facilitate the training of state-of-the-art
networks with > 1000 layers [12].论文里提了一句不知道什么意思回去查查)(drop layers方法,也是本文方法的思想源泉)
An orthogonal approach to making networks deeper (e.g., with the help of skip connections) is to increase the network width. In fact, simply increasing the number of filters in each layer of ResNets can improve its performance provided the depth is sufficient [41]. (为下文过度的一个点)
Instead of drawing representational power from extremely deep or wide architectures,DenseNets exploit the potential of the networkthrough feature reuse, yielding condensed models that are easy to train and highly parameter-efficient. (DenseNet和其他更宽更深不一样的地方)
Concatenating feature-maps learned by different layers increases variation in the input of subsequent layers and improves efficiency. This constitutes a major difference between DenseNets and ResNets.
下边巴拉一堆其他的算法。
3. DenseNets
ResNet
ResNets [11] add as kip-connection that bypasses the non-linear transformations with an identity function:
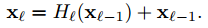
An advantage of ResNets is that the gradient can flow directly through the identity function from later layers to the earlier layers. However, the identity function and the output of H`are combined by summation, which may impede the information flow in the network.(ResNet的函数和优势,缺点)
Dense connectivity.
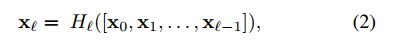
公式2当feature-maps的尺寸变化的时候就不能用了,we divide the network into multiple densely connecteddense blocks;
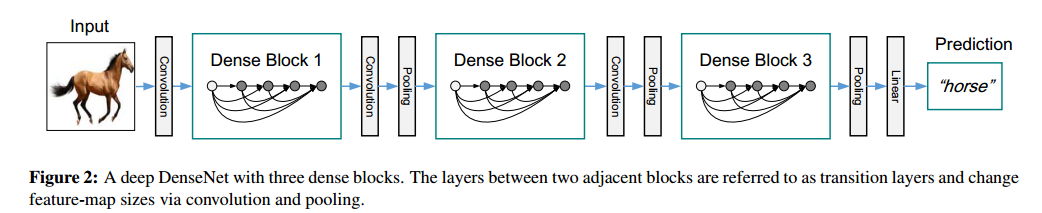
Growth rate.
An important difference between DenseNetandexisting network architectures is that DenseNet can have very narrow layers, e.g., k = 12. We refer to the hyperparameter k as the growth rate of the network.
One explanation for this is thateach layer has accessto all the preceding feature-maps in its blockand, therefore,to the network’s “collective knowledge”. One can view the
feature-maps as the global state of the network. Each layeraddsk feature-maps of its own to this state.
The global state, once written, can be accessed from everywhere within the network and,unlike in traditional network architectures, there is no needto replicate it from layer to layer.
Bottleneck layers.
It has been noted in [36, 11] that a 1×1 convolution can be introduced as bottleneck layer before each 3×3 convolution to reduce the number of input feature-maps, and thus to improve computational efficiency.-----DenseNet-B(后边儿还有别的模式)-----we let each 1×1 convolution produce 4k feature-maps.
(说白了这个地方就是为了减少feature-maps的东西)
Compression. (To further improve model compactness)
we can reduce the number of feature-maps at transition layers. If a dense block contains m feature-maps, we let the following transition layer generate
向下取整(θm)个 output feature-maps, where 0<θ≤1 is referred to as the compression factor. We refer the DenseNet with θ <1 as DenseNet-C,
and we setθ = 0.5 in our experiment. When both the bottleneck and transition layers withθ <1 are used, we refer to our model as DenseNet-BC.
4 Experiments
优秀链接:https://www.leiphone.com/news/201708/0MNOwwfvWiAu43WO.html