Hadoop

Hadoop是由Doug Cutting开发,最早起源于Nutch,灵感来自于谷歌发表的两篇论文,随后成为Apache的顶级项目,同时迎来它的黄金时代。
Nutch:
Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。
Nutch的创始人是Doug Cutting,他同时也是Lucene、Hadoop和Avro开源项目的创始人。
Hadoop是较早流行的大数据处理工具之一,现在依然被广泛使用。
Hadoop经过十多年不断的迭代和优化,已逐步成为大数据领域数据存储和计算的标准。在此期间,它经历了两次大的版本升级,这两次升级分别被称为Hadoop 2.0时代和Hadoop 3.0时代。
Hadoop提供了底层分布式存储平台HDFS和分布式资源管理平台YARN,并开放了资源管理平台,使之不断地兼容各种应用,让各种应用在YARN上呈现“百花齐放”的景象。
1、Hadoop 1.0时代
在Hadoop 1.0时代(包括Hadoop 0.x 和Hadoop1.x),Hadoop由两部分组成。
- 一部分是:分布式文件系统—HDFS
- 另一部分:分布式计算引擎—MapReduce
1.1、HDFS
HDFS在Hadoop 1.0时代的架构和在后两个时代的基础架构没什么区别,都是采用主/从架构。
- NameNode为主节点
- DataNode为从节点
Hadoop的研发团队在研发初期就意识到了NameNode的重要性,故将其部分功能拆离出来作为SecondaryNameNode。
SecondaryNameNode作为NameNode的一个冷备节点,定期将NameNode的操作日志合并成集群的状态快照,这样在NameNode重启时可以加快启动速度。
HDFS的整体架构: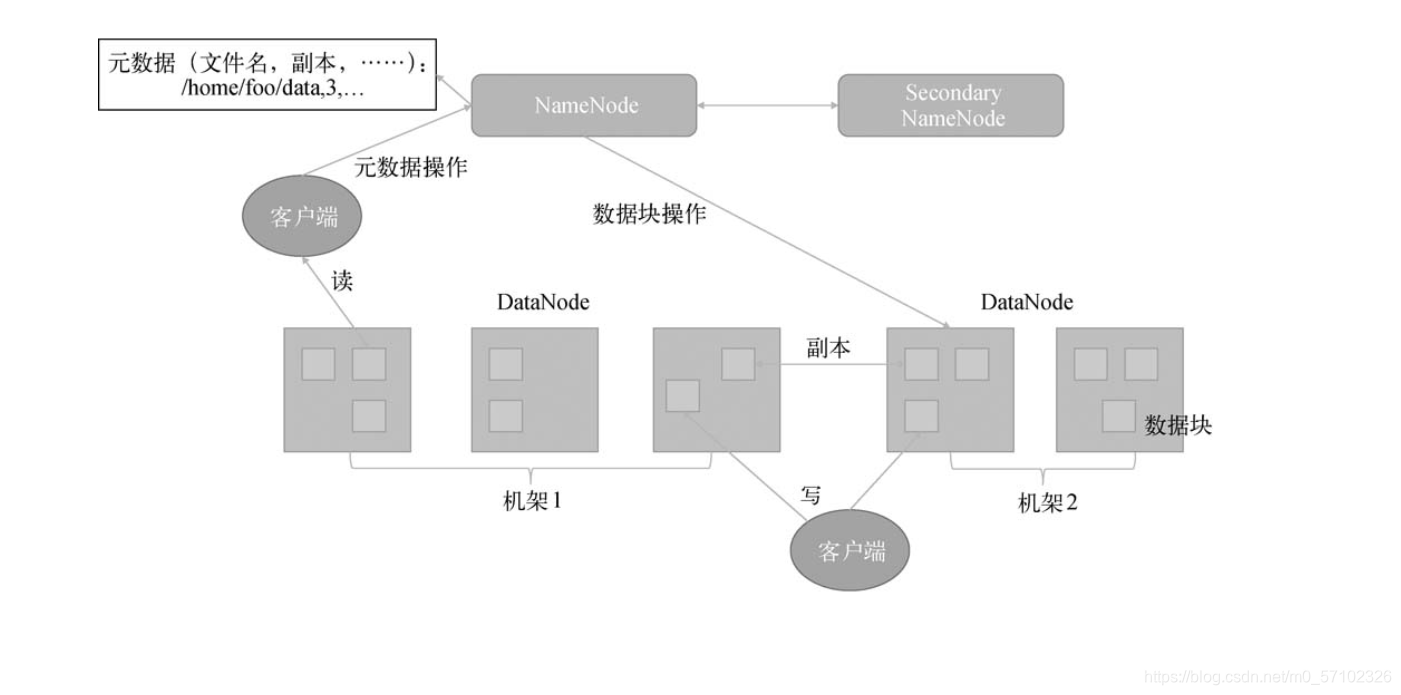
1.2、MapReduce
MapReduce在Hadoop 1.0时代的架构与在后两个时代的架构相比,变化有点大。
后两个时代的架构主要对之前架构的功能进行解耦,并且对一些功能进行提炼,使其更加通用。
在Hadoop1.0时代,MapReduce也是采用主/从架构:
- 主节点是JobTracker:负责集群资源的管理、任务调度以及跟踪任务的状态。
- 从节点是TaskTracker:负责任务的执行与周期性地汇报本节点的资源使用情况和任务进度。
MapReduce的整体架构:
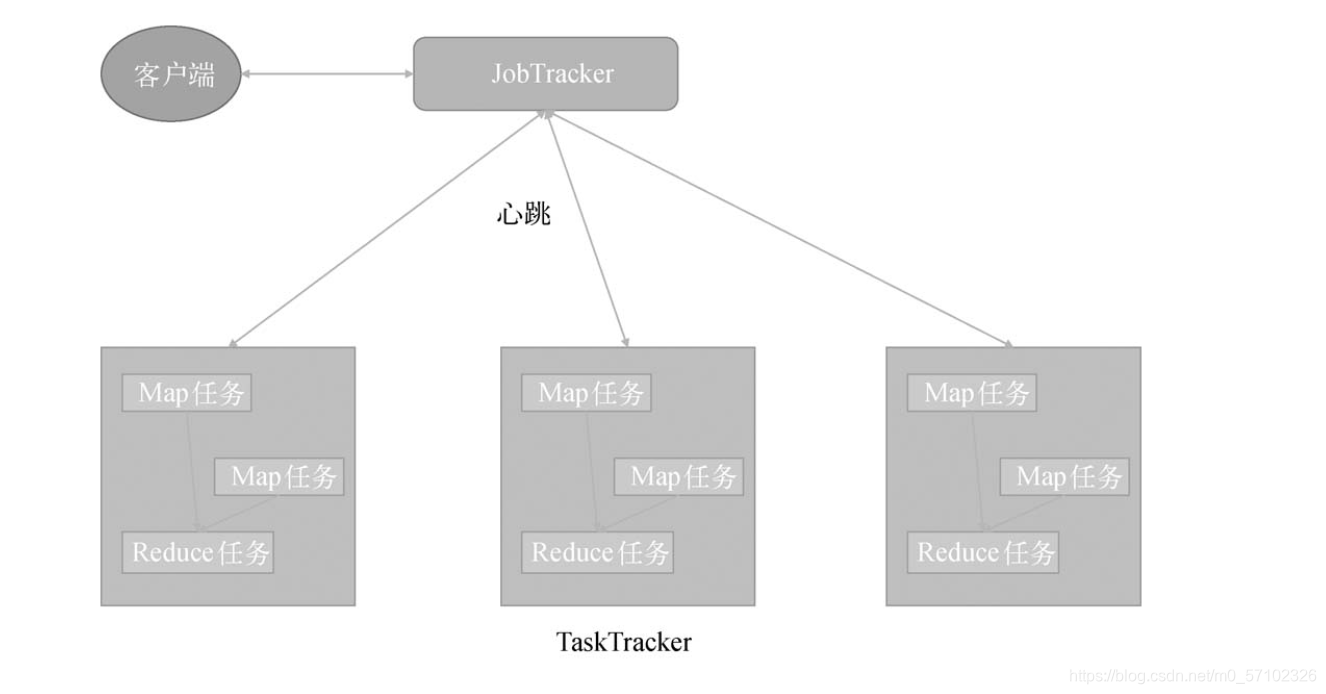
MapReduce在Hadoop 1.0中除了是一个计算引擎,还是一个资源管理平台。
它可管理的资源包括内存和CPU,这些资源被抽象为一个slot。而slot又被细分为map slot和reduce slot,它们分别为Map任务和Reduce任务提供计算资源。
2、Hadoop 2.0时代
随着Hadoop的影响力逐步扩大,其集群规模得到了迅猛增长,一些弊端就随之暴露出来了,此时Hadoop 2.0应运而生。
Hadoop 2.0使Hadoop迎来了第一次质的飞跃,它不仅在稳定性上有了较好的支持,在扩展性上也有了较大的改善,能够轻松应对上千节点的规模。
Hadoop 2.0对Hadoop 1.0中的每个组件都进行了升级扩展。
2.1、HDFS
HDFS,它的整体架构并没有太大的改变,其新增的特性为HA(高可用)和Federation(联邦模式),这两个特性主要集中在NameNode中。
1. HA功能—高可用
在Hadoop 2.0中,支持用两个NameNode提供HA功能:
- Active NameNode (Active NN): 负责对外提供服务,负责所有的客户端的操作。
- Standby NameNode(Standby NN):作为Active NameNode的热备节点,提供快速的故障恢复能力。
Active NameNode 和 Standby NameNode 通过一个共享的存储结构——通常是QJM(Quorum Journal Manager)实现数据同步.
Active NameNode会将操作日志实时写入QJM中,Standby NameNode则会从 QJM 中实时拉取操作日志进行操作回放,并定期生成集群的状态快照,然后同步给Active NameNode。
因为Active NameNode和Standby NameNode的数据是实时同步的,所以当Active NameNode发生故障无法提供服务时,Standby NameNode就能快速进行状态转换,变为ActiveNameNode对外提供服务,从而实现故障转移,增强NameNode的可用性。
补充:
为了保证Active NN与Standby NN节点状态同步,即元数据保持一致。除了DataNode需要向两个NN发送block位置信息外,还构建了一组独立的守护进程”JournalNodes”,用来FsEdits信息。当Active NN执行任何有关命名空间的修改,它需要持久化到一半以上的JournalNodes上。而Standby NN负责观察JournalNodes的变化,读取从Active NN发送过来的FsEdits信息,并更新其内部的命名空间。一旦ActiveNN遇到错误,Standby NN需要保证从JNs中读出了全部的FsEdits,然后切换成Active状态。预防脑裂现象”Brain Split”:HA需要保证在任何一个时间点,最多只有一个NameNode处于Active状态。否则的话,在两个NN的NameSpace下的状态会出现分歧,从而引起数据丢失、或者其它不可预见的错误。为了预防该问题的发送,在任何时间点内JournalNodes仅允许一个NN向其写FsEdits信息,保证故障迁移的正常执行,通过互斥机制来保证。
虽然NameNode的稳定性通过HA得到了增强,但是随着集群规模的扩大,NameNode的内存逐渐成为影响其扩容的主要因素,而Federation为其提供了横向扩展的能力。
2. Federation (联邦模式)
在Federation中,一个大HDFS集群会被分为N个小HDFS集群,这些小集群既可以共享DataNode的存储空间,也可以对其进行物理隔离。
Federation的整体架构:
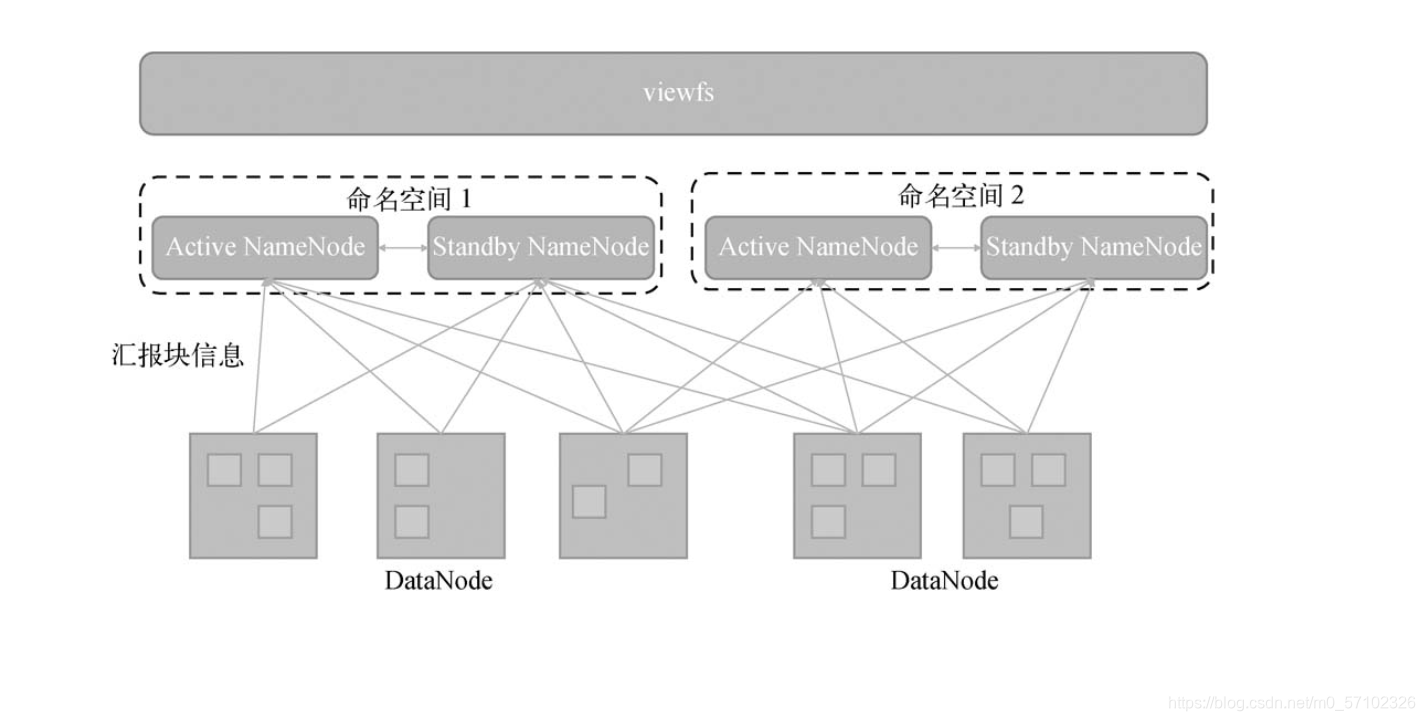
其中,viewfs负责提供N个小集群的整体视图,对普通用户屏蔽内部架构细节,这样也方便集群管理员管理集群。
2.2、MapReduce
Hadoop 2.0的另一个亮点是将Hadoop 1.0中的MapReduce拆分为两个组件:
- 一个组件专注于分布式计算,依然以MapReduce命名
- 另一个组件专注于资源管理,命名为YARN
任何系统都处在不断迭代的过程中,并且在迭代中会解决一些瓶颈问题,而随着使用场景的不断扩大,又会出现新的瓶颈。
Hadoop 2.0解决了很多问题,使其性能得以提升、集群规模得以扩大,但是在扩大的过程中,精益求精的工程师们又发现了新的瓶颈:
- HDFS虽然在Federation下能够横向扩展,但是其使用方式并不利于维护,而且数据冗余存储的方式在大规模集群中暴露出了存储资源利用不足的问题。
- HDFS的横向扩展导致在集群达到一定规模时,ResourceManager对资源的调度成了新的瓶颈。
为了解决这些问题,Hadoop 3.0问世了。
3、Hadoop 3.0时代
Hadoop 3.0没有在架构上对Hadoop2.0进行大的改动。而是将精力放在了如何提高系统的可扩展性和资源利用率上。
Hadoop 3.0提供了更高的性能、更强的容错能力以及更高效的数据处理能力。
1. 提高可扩展性
- Hadoop 3.0为YARN提供了Federation,使其集群规模可以达到上万台。
- 还为NameNode提供了多个Standby NameNode,这使得NameNode又多了一份保障。
2、在提高资源利用率
在提高资源利用率方面,Hadoop 3.0对HDFS和YARN都做了调整。
-
HDFS : HDFS增加了纠删码副本策略,与原先的副本策略相比,该策略可以提高存储资源的利用率,用户可以针对具体场景选择不同的存储策略
-
YARN : 为了更好地区分集群中各机器的特性,新增了NodeAttribute功能。由于越来越多的框架运行在YARN上,为了更好地进行资源隔离,YARN丰富了原先的container放置策略等。
同时,Hadoop 3.0中还新增了两个成员,分别是Hadoop Ozone和Hadoop Submarine。
- Hadoop Ozone是一个对象存储方案,在一定程度上可以缓解HDFS集群中小文件的问题。
- Hadoop Submarine是一个机器学习引擎,可使TensorFlow或者PyTorch运行在YARN中。
Hadoop 3.0时代整个工程包含6个模块:
- Hadoop Common
- HDFS(Hadoop Distributed FileSystem
- Hadoop YARN
- Hadoop MapReduce
- Hadoop Ozone
- Hadoop Submarine
Hadoop Common
这是将其他模块中的公共部分抽象出来并整理成的一个模块,它为Hadoop提供一些常用工具,主要包括配置工具包Configuration、抽象文件系统包FileSystem、远程调用包RPC以及用于指标检测的jmx和metrics2包,还有一些其他公共工具包。
HDFS(Hadoop Distributed FileSystem,Hadoop分布式文件系统)
Hadoop有一个综合性的、抽象的文件系统概念,提供了很多文件系统的接口,一般使用URI方案来选取其中合适的文件系统实例进行交互。Java抽象类org.apache.hadoop.fs.FileSystem展示了其中的一个文件系统,该系统有几个具体的实现,而HDFS只是这些实现中的一个。
HDFS是Hadoop的旗舰级文件系统,以流式数据访问模式存储超大文件,是一个高吞吐量的分布式文件。
HDFS的设计场景是一次写入,多次读取。因为它认为一个数据集的获取过程通常是先由数据源生成数据集,接着对该数据集进行各种各样的分析,每个分析至少会读取此数据集中的大部分数据,所以HDFS的流式数据访问模式可以提高吞吐量。此外,HDFS还具有高度容错性,能够自动检测和应对硬件故障。
Hadoop YARN
YARN是从JobTracker的资源管理功能中独立出来,形成的一个用于作业调度和资源管理的框架。作为一个通用的资源管理平台,YARN将container作为资源划分的最小单元,所划分的资源包括CPU和内存。
YARN能够支持各种计算引擎,例如支持离线处理的MapReduce、支持迭代计算和微批处理的Spark以及支持实时处理的Flink,它还提供了接口以便让用户实现自定义的分布式应用。
YARN作为Hadoop的一个模块,与HDFS有着天然的兼容性。它将应用都集成到统一的资源管理平台中。
- 一方面使得应用之间能够轻松地实现数据共享,避免了多个集群的冗余存储或者跨集群数据复制;
- 另一方面,多个计算引擎集中在一个集群中既能够减轻运维,也能更好地利用资源,避免在某一时刻某些集群的计算资源比较紧张而其他集群的资源比较空闲。
Hadoop MapReduce
MapReduce是一种基于YARN的大数据分布式并行计算模型。
它将整个计算过程分为Map和Reduce两个任务:
- Map任务从输入的数据集中读取数据,并对取出的数据进行指定的逻辑处理,然后生成键值对形式的中间结果,并将该结果写入本地磁盘。
- Reduce任务从Map任务输出的中间结果中读取相应的键值对,然后进行聚合处理,最后输出结果。
MapReduce主要用于对大规模数据进行离线计算。
一个完整的MapReduce作业由n个Map任务和m个Reduce任务组成,出于对性能优化的考虑,n>m。
对于某些特定的场景,可以对Map任务使用的combiner个数进行优化以减少它的输出数据。至于Reduce任务要读取哪些数据,这是由Map任务的分区策略决定的,默认是散列分区策略,也可根据需要自定义。
Hadoop Ozone
Hadoop Ozone是专门为Hadoop设计的、由HDDS(HadoopDistributed Data Store)构建成的可扩展的分布式对象存储系统.
后续会介绍
Hadoop Submarine
Hadoop Submarine是一个机器学习引擎,可以运行TensorFlow、PyTorch、MXNet等框架,可以运行在YARN、Kubernetes等资源管理平台之上。Hadoop Submarine随后的开发计划还包含算法开发、模型增量训练以及模型管理,这使得基础研发工程师和数据分析师都能运行深度学习算法。
其中最后两个模块是新增的,它们正处在开发中,之后会使Hadoop更加强大。
总结
本文首先分析了Hadoop各个版本的演变过程,然后梳理了Hadoop 3.0中的主要模块。