简介
这是HRNet+TRansformer在语义分割方面的应用;
最近的研究中,把TRansformer用在语义分割中的很多,因为不同位置不同实例的语义是有相关联性的,比如说飞机不可能在厕所里面等等;
这是OCRNet官方的解读:
https://zhuanlan.zhihu.com/p/43902175
网络结构
直接上网络结构:
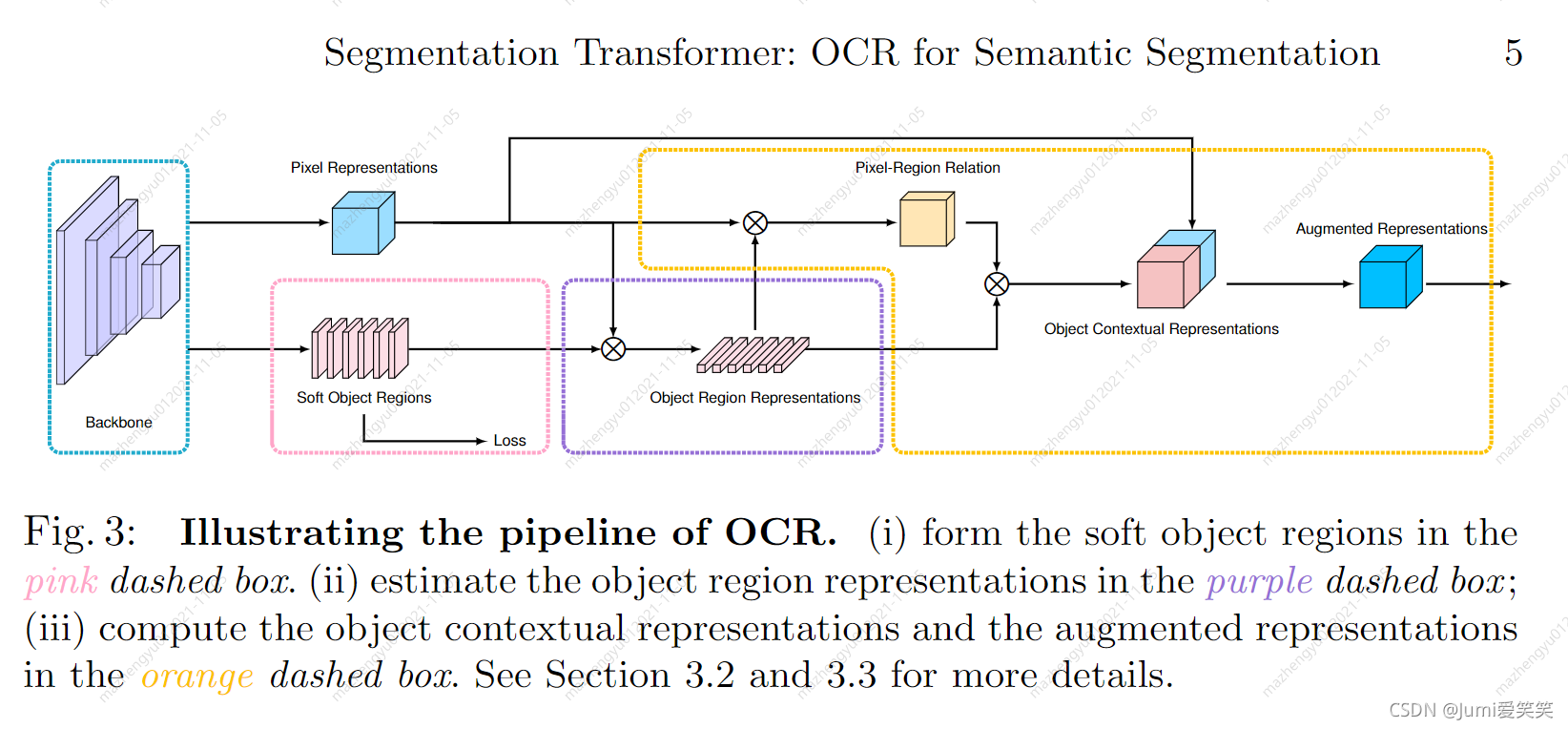
OCR 方法的实现主要包括3个阶段:(1) 根据网络中间层的特征表示估测一个粗略的语义分割结果作为 OCR 方法的一个输入 ,即软物体区域(Soft Object Regions),(2) 根据粗略的语义分割结果和网络最深层的特征表示计算出 K 组向量,即物体区域表示(Object Region Representations),其中每一个向量对应一个语义类别的特征表示,(3) 计算网络最深层输出的像素特征表示(Pixel Representations)与计算得到的物体区域特征表示(Object Region Representation)之间的关系矩阵,然后根据每个像素和物体区域特征表示在关系矩阵中的数值把物体区域特征加权求和,得到最后的物体上下文特征表示 OCR (Object Contextual Representation) 。当把物体上下文特征表示 OCR 与网络最深层输入的特征表示拼接之后作为上下文信息增强的特征表示(Augmented Representation),可以基于增强后的特征表示预测每个像素的语义类别,具体算法框架可以参考图6。综上,OCR 可计算一组物体区域的特征表达,然后根据物体区域特征表示与像素特征表示之间的相似度将这些物体区域特征表示传播给每一个像素。
详细网络结构图

局限性分析
1.并未像传统的TRansformer加入位置信息的编码;
2.整个流程相当于是基于全局像素对分类进行了编码,基于这个分类的编码又生成了注意力mask叠加在全局像素上;并未真正实现远距离像素之间信息的有效融合;
源码解读
# ------------------------------------------------------------------------------
# Copyright (c) Microsoft
# Licensed under the MIT License.
# Written by Ke Sun ([email protected]), Jingyi Xie ([email protected])
# ------------------------------------------------------------------------------
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import logging
import functools
import numpy as np
import torch
import torch.nn as nn
import torch._utils
import torch.nn.functional as F
from .bn_helper import BatchNorm2d, BatchNorm2d_class, relu_inplace
ALIGN_CORNERS = True
BN_MOMENTUM = 0.1
logger = logging.getLogger(__name__)
class ModuleHelper:
#BN+relu
@staticmethod
def BNReLU(num_features, bn_type=None, **kwargs):
return nn.Sequential(
BatchNorm2d(num_features, **kwargs),
nn.ReLU()
)
#BN
@staticmethod
def BatchNorm2d(*args, **kwargs):
return BatchNorm2d
#普通的kernel=3*3的卷积
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
#上下文结合模块
class SpatialGather_Module(nn.Module):
"""
Aggregate the context features according to the initial
predicted probability distribution.
Employ the soft-weighted method to aggregate the context.
根据初始聚合上下文特征
预测的概率分布。
使用软加权方法来聚合上下文。
"""
def __init__(self, cls_num=0, scale=1):
super(SpatialGather_Module, self).__init__()
self.cls_num = cls_num #类别数
self.scale = scale#尺度
#假设feats是上文,probs是下文,二者融合的方式就是两者大小相同,[hw,c]居正乘以[c,hw]得到[c*c]
def forward(self, feats, probs):
batch_size, c, h, w = probs.size(0), probs.size(1), probs.size(2), probs.size(3)
probs = probs.view(batch_size, c, -1)#将probs的h*w打成一维
feats = feats.view(batch_size, feats.size(1), -1)#feats的h*w打成一维
feats = feats.permute(0, 2, 1) # batch x hw x c
probs = F.softmax(self.scale * probs, dim=2)# batch x k x hw??这里为什么是k维,不是c维
ocr_context = torch.matmul(probs, feats)\
.permute(0, 2, 1).unsqueeze(3)# batch x k x c
return ocr_context
#目标注意力模块
class _ObjectAttentionBlock(nn.Module):
'''
The basic implementation for object context block
Input:
N X C X H X W
Parameters:
in_channels : the dimension of the input feature map
key_channels : the dimension after the key/query transform
scale : choose the scale to downsample the input feature maps (save memory cost)
bn_type : specify the bn type
Return:
N X C X H X W
文字检测的基本模块
输入:
N X C X H X W
参数:
in_channels : 特征图的输入通道数
key_channels : 经过键值变换后的通道数
scale : 选择scale对输入特征图进行降采样 (为了节省内存)
bn_type : 指定BN方式
返回:
N X C X H X W
'''
def __init__(self,
in_channels,
key_channels,
scale=1,
bn_type=None):
super(_ObjectAttentionBlock, self).__init__()
self.scale = scale
self.in_channels = in_channels
self.key_channels = key_channels
self.pool = nn.MaxPool2d(kernel_size=(scale, scale))
self.f_pixel = nn.Sequential(
nn.Conv2d(in_channels=self.in_channels, out_channels=self.key_channels,
kernel_size=1, stride=1, padding=0, bias=False),
ModuleHelper.BNReLU(self.key_channels, bn_type=bn_type),
nn.Conv2d(in_channels=self.key_channels, out_channels=self.key_channels,
kernel_size=1, stride=1, padding=0, bias=False),
ModuleHelper.BNReLU(self.key_channels, bn_type=bn_type),
)
self.f_object = nn.Sequential(
nn.Conv2d(in_channels=self.in_channels, out_channels=self.key_channels,
kernel_size=1, stride=1, padding=0, bias=False),
ModuleHelper.BNReLU(self.key_channels, bn_type=bn_type),
nn.Conv2d(in_channels=self.key_channels, out_channels=self.key_channels,
kernel_size=1, stride=1, padding=0, bias=False),
ModuleHelper.BNReLU(self.key_channels, bn_type=bn_type),
)
self.f_down = nn.Sequential(
nn.Conv2d(in_channels=self.in_channels, out_channels=self.key_channels,
kernel_size=1, stride=1, padding=0, bias=False),
ModuleHelper.BNReLU(self.key_channels, bn_type=bn_type),
)
self.f_up = nn.Sequential(
nn.Conv2d(in_channels=self.key_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0, bias=False),
ModuleHelper.BNReLU(self.in_channels, bn_type=bn_type),
)
def forward(self, x, proxy):
batch_size, h, w = x.size(0), x.size(2), x.size(3)
if self.scale > 1:#scale>1就进行下采样
x = self.pool(x)
#f_pixel两层(1*1卷积+BNRElu),通道数变为key_channels ==》(B,key_channels,h*w)
query = self.f_pixel(x).view(batch_size, self.key_channels, -1)
query = query.permute(0, 2, 1)#==>(B,h*w,key_channels)
# f_object两层(1*1卷积+BNRElu),通道数变为key_channels ==》(B,key_channels,h*w)
key = self.f_object(proxy).view(batch_size, self.key_channels, -1)
# f_down一层(1*1卷积+BNRElu),通道数变为key_channels ==》(B,key_channels,h*w)
value = self.f_down(proxy).view(batch_size, self.key_channels, -1)
value = value.permute(0, 2, 1)#==>(B,h*w,key_channels)
sim_map = torch.matmul(query, key)#=》(B,h*w,h*w)
sim_map = (self.key_channels**-.5) * sim_map#乘以通道数开根号
#0表示张量的最高为度,1表示次高,以此类推,-1表示最低的维度,在这里,dim=-1相当于dim=2
sim_map = F.softmax(sim_map, dim=-1)
# add bg context ...
context = torch.matmul(sim_map, value)#(B,h*w,h*w)X(B,h*w,key_channels)==>(B,h*w,key_channels)
context = context.permute(0, 2, 1).contiguous()#==>(B,key_channels,h*w)
context = context.view(batch_size, self.key_channels, *x.size()[2:])#==>(B,key_channels,h*w)
# f_down一层(1*1卷积+BNRElu),通道数变为key_channels ==》(B,key_channels,h*w)
context = self.f_up(context)
if self.scale > 1:#如果scale>1,进行上采样
context = F.interpolate(input=context, size=(h, w), mode='bilinear', align_corners=ALIGN_CORNERS)
return context
#对于_ObjectAttentionBlock再进行了一道封装
class ObjectAttentionBlock2D(_ObjectAttentionBlock):
def __init__(self,
in_channels,
key_channels,
scale=1,
bn_type=None):
super(ObjectAttentionBlock2D, self).__init__(in_channels,
key_channels,
scale,
bn_type=bn_type)
class SpatialOCR_Module(nn.Module):
"""
Implementation of the OCR module:
We aggregate the global object representation to update the representation for each pixel.
OCR模块的部署:
用全局的信息去更新单个像素的信息
"""
def __init__(self,
in_channels,
key_channels,
out_channels,
scale=1,
dropout=0.1,
bn_type=None):
super(SpatialOCR_Module, self).__init__()
self.object_context_block = ObjectAttentionBlock2D(in_channels,
key_channels,
scale,
bn_type)
_in_channels = 2 * in_channels
self.conv_bn_dropout = nn.Sequential(
nn.Conv2d(_in_channels, out_channels, kernel_size=1, padding=0, bias=False),
ModuleHelper.BNReLU(out_channels, bn_type=bn_type),
nn.Dropout2d(dropout)
)
def forward(self, feats, proxy_feats):
context = self.object_context_block(feats, proxy_feats)
output = self.conv_bn_dropout(torch.cat([context, feats], 1))
return output
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=relu_inplace)
self.conv2 = conv3x3(planes, planes)
self.bn2 = BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out = out + residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1,
bias=False)
self.bn3 = BatchNorm2d(planes * self.expansion,
momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=relu_inplace)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out = out + residual
out = self.relu(out)
return out
class HighResolutionModule(nn.Module):
def __init__(self, num_branches, blocks, num_blocks, num_inchannels,
num_channels, fuse_method, multi_scale_output=True):
super(HighResolutionModule, self).__init__()
self._check_branches(
num_branches, blocks, num_blocks, num_inchannels, num_channels)
self.num_inchannels = num_inchannels
self.fuse_method = fuse_method
self.num_branches = num_branches
self.multi_scale_output = multi_scale_output
self.branches = self._make_branches(
num_branches, blocks, num_blocks, num_channels)
self.fuse_layers = self._make_fuse_layers()
self.relu = nn.ReLU(inplace=relu_inplace)
def _check_branches(self, num_branches, blocks, num_blocks,
num_inchannels, num_channels):
if num_branches != len(num_blocks):
error_msg = 'NUM_BRANCHES({}) <> NUM_BLOCKS({})'.format(
num_branches, len(num_blocks))
logger.error(error_msg)
raise ValueError(error_msg)
if num_branches != len(num_channels):
error_msg = 'NUM_BRANCHES({}) <> NUM_CHANNELS({})'.format(
num_branches, len(num_channels))
logger.error(error_msg)
raise ValueError(error_msg)
if num_branches != len(num_inchannels):
error_msg = 'NUM_BRANCHES({}) <> NUM_INCHANNELS({})'.format(
num_branches, len(num_inchannels))
logger.error(error_msg)
raise ValueError(error_msg)
def _make_one_branch(self, branch_index, block, num_blocks, num_channels,
stride=1):
downsample = None
if stride != 1 or \
self.num_inchannels[branch_index] != num_channels[branch_index] * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.num_inchannels[branch_index],
num_channels[branch_index] * block.expansion,
kernel_size=1, stride=stride, bias=False),
BatchNorm2d(num_channels[branch_index] * block.expansion,
momentum=BN_MOMENTUM),
)
layers = []
layers.append(block(self.num_inchannels[branch_index],
num_channels[branch_index], stride, downsample))
self.num_inchannels[branch_index] = \
num_channels[branch_index] * block.expansion
for i in range(1, num_blocks[branch_index]):
layers.append(block(self.num_inchannels[branch_index],
num_channels[branch_index]))
return nn.Sequential(*layers)
def _make_branches(self, num_branches, block, num_blocks, num_channels):
branches = []
for i in range(num_branches):
branches.append(
self._make_one_branch(i, block, num_blocks, num_channels))
return nn.ModuleList(branches)
def _make_fuse_layers(self):
if self.num_branches == 1:
return None
num_branches = self.num_branches
num_inchannels = self.num_inchannels
fuse_layers = []
for i in range(num_branches if self.multi_scale_output else 1):
fuse_layer = []
for j in range(num_branches):
if j > i:
fuse_layer.append(nn.Sequential(
nn.Conv2d(num_inchannels[j],
num_inchannels[i],
1,
1,
0,
bias=False),
BatchNorm2d(num_inchannels[i], momentum=BN_MOMENTUM)))
elif j == i:
fuse_layer.append(None)
else:
conv3x3s = []
for k in range(i-j):
if k == i - j - 1:
num_outchannels_conv3x3 = num_inchannels[i]
conv3x3s.append(nn.Sequential(
nn.Conv2d(num_inchannels[j],
num_outchannels_conv3x3,
3, 2, 1, bias=False),
BatchNorm2d(num_outchannels_conv3x3,
momentum=BN_MOMENTUM)))
else:
num_outchannels_conv3x3 = num_inchannels[j]
conv3x3s.append(nn.Sequential(
nn.Conv2d(num_inchannels[j],
num_outchannels_conv3x3,
3, 2, 1, bias=False),
BatchNorm2d(num_outchannels_conv3x3,
momentum=BN_MOMENTUM),
nn.ReLU(inplace=relu_inplace)))
fuse_layer.append(nn.Sequential(*conv3x3s))
fuse_layers.append(nn.ModuleList(fuse_layer))
return nn.ModuleList(fuse_layers)
def get_num_inchannels(self):
return self.num_inchannels
def forward(self, x):
if self.num_branches == 1:
return [self.branches[0](x[0])]
for i in range(self.num_branches):
x[i] = self.branches[i](x[i])
x_fuse = []
for i in range(len(self.fuse_layers)):
y = x[0] if i == 0 else self.fuse_layers[i][0](x[0])
for j in range(1, self.num_branches):
if i == j:
y = y + x[j]
elif j > i:
width_output = x[i].shape[-1]
height_output = x[i].shape[-2]
y = y + F.interpolate(
self.fuse_layers[i][j](x[j]),
size=[height_output, width_output],
mode='bilinear', align_corners=ALIGN_CORNERS)
else:
y = y + self.fuse_layers[i][j](x[j])
x_fuse.append(self.relu(y))
return x_fuse
blocks_dict = {
'BASIC': BasicBlock,
'BOTTLENECK': Bottleneck
}
class HighResolutionNet(nn.Module):
def __init__(self, config, **kwargs):
global ALIGN_CORNERS
extra = config['MODEL']['EXTRA']
super(HighResolutionNet, self).__init__()
ALIGN_CORNERS = False#config['MODEL']['ALIGN_CORNERS']
# stem net
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1,
bias=False)
self.bn1 = BatchNorm2d(64, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1,
bias=False)
self.bn2 = BatchNorm2d(64, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=relu_inplace)
#self.stage1_cfg = extra['STAGE1']
num_channels = 64#self.stage1_cfg['NUM_CHANNELS'][0]
#block = blocks_dict[self.stage1_cfg['BLOCK']]
num_blocks = 4#self.stage1_cfg['NUM_BLOCKS'][0]
#modified by mzy
#self.layer1 = self._make_layer(block, 64, num_channels, num_blocks)
self.layer1 = self._make_layer(Bottleneck, 64, 64, 4)
stage1_out_channel = block.expansion*num_channels
self.stage2_cfg = extra['STAGE2']
num_channels = self.stage2_cfg['NUM_CHANNELS']
block = blocks_dict[self.stage2_cfg['BLOCK']]
num_channels = [
num_channels[i] * block.expansion for i in range(len(num_channels))]
self.transition1 = self._make_transition_layer(
[stage1_out_channel], num_channels)
self.stage2, pre_stage_channels = self._make_stage(
self.stage2_cfg, num_channels)
self.stage3_cfg = extra['STAGE3']
num_channels = self.stage3_cfg['NUM_CHANNELS']
block = blocks_dict[self.stage3_cfg['BLOCK']]
num_channels = [
num_channels[i] * block.expansion for i in range(len(num_channels))]
self.transition2 = self._make_transition_layer(
pre_stage_channels, num_channels)
self.stage3, pre_stage_channels = self._make_stage(
self.stage3_cfg, num_channels)
self.stage4_cfg = extra['STAGE4']
num_channels = self.stage4_cfg['NUM_CHANNELS']
block = blocks_dict[self.stage4_cfg['BLOCK']]
num_channels = [
num_channels[i] * block.expansion for i in range(len(num_channels))]
self.transition3 = self._make_transition_layer(
pre_stage_channels, num_channels)
self.stage4, pre_stage_channels = self._make_stage(
self.stage4_cfg, num_channels, multi_scale_output=True)
last_inp_channels = np.int(np.sum(pre_stage_channels))
ocr_mid_channels = config['MODEL']['OCR']['MID_CHANNELS']
ocr_key_channels = config['MODEL']['OCR']['KEY_CHANNELS']
self.conv3x3_ocr = nn.Sequential(
nn.Conv2d(last_inp_channels, ocr_mid_channels,
kernel_size=3, stride=1, padding=1),
BatchNorm2d(ocr_mid_channels),
nn.ReLU(inplace=relu_inplace),
)
self.ocr_gather_head = SpatialGather_Module(config['DATASET']['NUM_CLASSES'])
self.ocr_distri_head = SpatialOCR_Module(in_channels=ocr_mid_channels,
key_channels=ocr_key_channels,
out_channels=ocr_mid_channels,
scale=1,
dropout=0.05,
)
self.cls_head = nn.Conv2d(
ocr_mid_channels, config['DATASET']['NUM_CLASSES'], kernel_size=1, stride=1, padding=0, bias=True)
self.aux_head = nn.Sequential(
nn.Conv2d(last_inp_channels, last_inp_channels,
kernel_size=1, stride=1, padding=0),
BatchNorm2d(last_inp_channels),
nn.ReLU(inplace=relu_inplace),
nn.Conv2d(last_inp_channels, config['DATASET']['NUM_CLASSES'],
kernel_size=1, stride=1, padding=0, bias=True)
)
def _make_transition_layer(
self, num_channels_pre_layer, num_channels_cur_layer):
num_branches_cur = len(num_channels_cur_layer)
num_branches_pre = len(num_channels_pre_layer)
transition_layers = []
for i in range(num_branches_cur):
if i < num_branches_pre:
if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
transition_layers.append(nn.Sequential(
nn.Conv2d(num_channels_pre_layer[i],
num_channels_cur_layer[i],
3,
1,
1,
bias=False),
BatchNorm2d(
num_channels_cur_layer[i], momentum=BN_MOMENTUM),
nn.ReLU(inplace=relu_inplace)))
else:
transition_layers.append(None)
else:
conv3x3s = []
for j in range(i+1-num_branches_pre):
inchannels = num_channels_pre_layer[-1]
outchannels = num_channels_cur_layer[i] \
if j == i-num_branches_pre else inchannels
conv3x3s.append(nn.Sequential(
nn.Conv2d(
inchannels, outchannels, 3, 2, 1, bias=False),
BatchNorm2d(outchannels, momentum=BN_MOMENTUM),
nn.ReLU(inplace=relu_inplace)))
transition_layers.append(nn.Sequential(*conv3x3s))
return nn.ModuleList(transition_layers)
def _make_layer(self, block, inplanes, planes, blocks, stride=1):
downsample = None
if stride != 1 or inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
BatchNorm2d(planes * block.expansion, momentum=BN_MOMENTUM),
)
layers = []
layers.append(block(inplanes, planes, stride, downsample))
inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(inplanes, planes))
return nn.Sequential(*layers)
def _make_stage(self, layer_config, num_inchannels,
multi_scale_output=True):
num_modules = layer_config['NUM_MODULES']
num_branches = layer_config['NUM_BRANCHES']
num_blocks = layer_config['NUM_BLOCKS']
num_channels = layer_config['NUM_CHANNELS']
block = blocks_dict[layer_config['BLOCK']]
fuse_method = layer_config['FUSE_METHOD']
modules = []
for i in range(num_modules):
# multi_scale_output is only used last module
if not multi_scale_output and i == num_modules - 1:
reset_multi_scale_output = False
else:
reset_multi_scale_output = True
modules.append(
HighResolutionModule(num_branches,
block,
num_blocks,
num_inchannels,
num_channels,
fuse_method,
reset_multi_scale_output)
)
num_inchannels = modules[-1].get_num_inchannels()
return nn.Sequential(*modules), num_inchannels
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.layer1(x)
x_list = []
for i in range(self.stage2_cfg['NUM_BRANCHES']):
if self.transition1[i] is not None:
x_list.append(self.transition1[i](x))
else:
x_list.append(x)
y_list = self.stage2(x_list)
x_list = []
for i in range(self.stage3_cfg['NUM_BRANCHES']):
if self.transition2[i] is not None:
if i < self.stage2_cfg['NUM_BRANCHES']:
x_list.append(self.transition2[i](y_list[i]))
else:
x_list.append(self.transition2[i](y_list[-1]))
else:
x_list.append(y_list[i])
y_list = self.stage3(x_list)
x_list = []
for i in range(self.stage4_cfg['NUM_BRANCHES']):
if self.transition3[i] is not None:
if i < self.stage3_cfg['NUM_BRANCHES']:
x_list.append(self.transition3[i](y_list[i]))
else:
x_list.append(self.transition3[i](y_list[-1]))
else:
x_list.append(y_list[i])
x = self.stage4(x_list)
# Upsampling
x0_h, x0_w = x[0].size(2), x[0].size(3)
x1 = F.interpolate(x[1], size=(x0_h, x0_w),
mode='bilinear', align_corners=ALIGN_CORNERS)
x2 = F.interpolate(x[2], size=(x0_h, x0_w),
mode='bilinear', align_corners=ALIGN_CORNERS)
x3 = F.interpolate(x[3], size=(x0_h, x0_w),
mode='bilinear', align_corners=ALIGN_CORNERS)
#将最后四个分支的输出都上采样到统一的大小,然后cat
feats = torch.cat([x[0], x1, x2, x3], 1)
#以上都是HRNet的常规操作
out_aux_seg = []
# ocr
#2*(1*1卷积+BNRelu)=>输出通道数是num_classes
out_aux = self.aux_head(feats)#[B,num_classes,H,W]
# compute contrast feature 3*3卷积+BN+Relu=>通道数变为mid_channels
feats = self.conv3x3_ocr(feats)#[B,mid_channels,H,W]
#ocr_gather_head==>SpatialGather_Module
#这一步可以理解为基于全局的像素值获取通道和分类注意力
context = self.ocr_gather_head(feats, out_aux)#[B,mid_channels,num_classes,1]
#ocr_distri_head==>SpatialOCR_Module
feats = self.ocr_distri_head(feats, context)
#1*1卷积将通道数由mid_channels==>num_classes
out = self.cls_head(feats)
out_aux_seg.append(out_aux)#out_aux是不经过Transformer的结果
out_aux_seg.append(out)#out_aux是经过Transformer的结果
return out_aux_seg
def init_weights(self, pretrained='',):
logger.info('=> init weights from normal distribution')
for name, m in self.named_modules():
if any(part in name for part in {
'cls', 'aux', 'ocr'}):
# print('skipped', name)
continue
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight, std=0.001)
elif isinstance(m, BatchNorm2d_class):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
if os.path.isfile(pretrained):
pretrained_dict = torch.load(pretrained, map_location={
'cuda:0': 'cpu'})
logger.info('=> loading pretrained model {}'.format(pretrained))
model_dict = self.state_dict()
pretrained_dict = {
k.replace('last_layer', 'aux_head').replace('model.', ''): v for k, v in pretrained_dict.items()}
print(set(model_dict) - set(pretrained_dict))
print(set(pretrained_dict) - set(model_dict))
pretrained_dict = {
k: v for k, v in pretrained_dict.items()
if k in model_dict.keys()}
# for k, _ in pretrained_dict.items():
# logger.info(
# '=> loading {} pretrained model {}'.format(k, pretrained))
model_dict.update(pretrained_dict)
self.load_state_dict(model_dict)
elif pretrained:
raise RuntimeError('No such file {}'.format(pretrained))
def get_seg_model(cfg, **kwargs):
model = HighResolutionNet(cfg, **kwargs)
model.init_weights(cfg['MODEL']['PRETRAINED'])
return model