以下命令windows 10 cmd下测试
以下命令装个git ,然后添加环境变量,例如echo命令目录
C:\G\Program Files\Git\usr\bin\echo.exe
grep
搜索显示文件数据
主要用于搜索
grep -x 整行匹配 force PATTERN to match only whole lines
grep -w 匹配一个单词 force PATTERN to match only whole words
grep -E 扩展正则
grep -P perl正则
grep -o 只输出匹配内容
grep -e patten多个选项
grep -F 将样式视为固定字符串的列表,忽略正则
grep -l 列出文件名
grep -v 取反
grep -i 忽略大小写
grep -z 忽略换行符,整个文件文本一体 a data line ends in 0 byte, not newline
显示匹配行的附近
-B, --before-context=NUM
-A, --after-context=NUM
-C, --context=NUM
-NUM same as --context=NUM
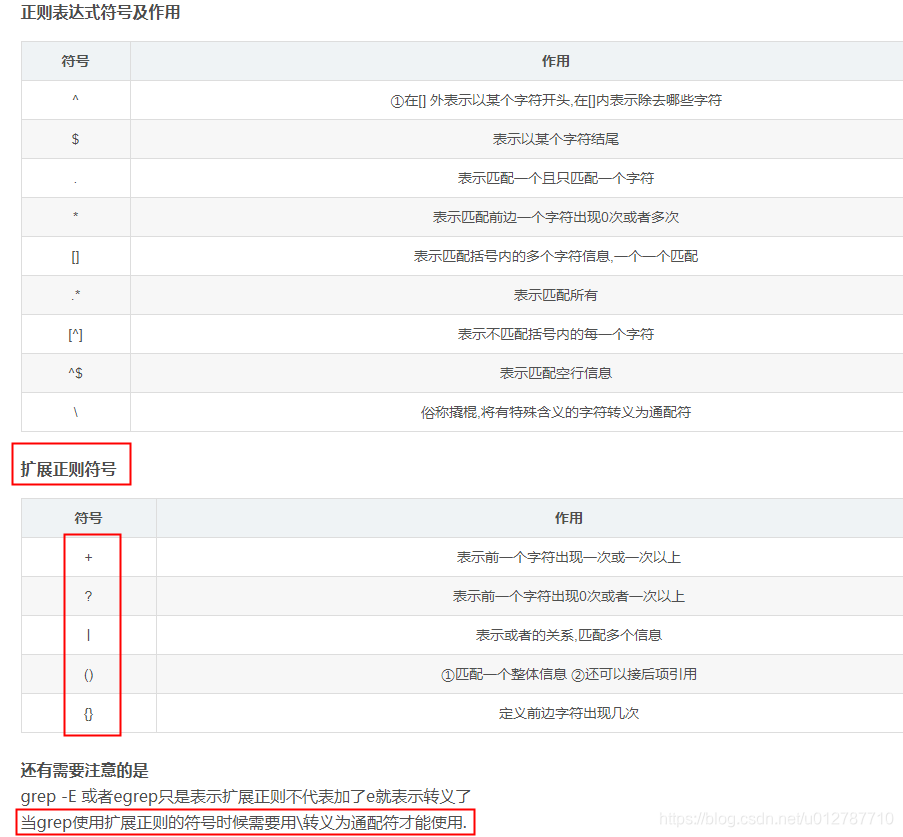
如图,上面的是基本正则和扩展正则,比如 \d这些就没有,要使用-P perl正则
\d 匹配任何十进制数,相当于[0-9]
\D 匹配任何非数字字符,相当于[^0-9]
grep Example
test.txt
defg
456
456methodqwe789lmn
abc+.?
cmd
cat test.txt |grep -Po "(?<=method)\D+(?=\d)" //qwe 匹配method后数字前的非数字
cat test.txt| grep -Po '(?^<=method)\D+(?=\d)' //单引号和双引号区别,尤其重定向符号,管道符号
cat test.txt |grep a.+ //无任何匹配
cat test.txt |grep a.\+ //abc+.? 基本正则加转义
cat test.txt |grep -E a.+ //abc+.? 扩展正则不转义
cat test.txt |grep -A1 456m //输出匹配行和后面一行,-B -C类似
//456methodqwe789lmn
//abc+.?
sed
修改或者显示文件数据
主要行
即时修改文件数据 sed -i
不修改文件数据,只显示修改后的数据
部分行操作
sed '3,5d' log.txt d删除,a增加,i插入,c修改
下面 1,$ 可以省略,默认整个文件
sed '1,$ s/1/a/g' log.txt 替换所有行中的1为a,没有g只替换每行第1个a
sed '1,$ s/1/a/2' log.txt 替换第2个a
所有行操作
sed '/root/p' log.txt 搜索与显示 p显示,d删除,a增加,i插入,c修改
-n 只显示匹配的
wc -l 统计行数
高级用法
sed命令:
g 将hold space中的内容拷贝到pattern space中,原来pattern space里的内容清除
G 将hold space中的内容append到pattern space后
h 将pattern space中的内容拷贝到hold space中,原来的hold space里的内容被清除
H 将pattern space中的内容append到hold space后
d 删除pattern中的所有行,并读入下一新行到pattern中
D 删除multiline pattern中的第一行,不读入下一行
例子
echo 1234 |sed 'H;g' |grep 1234
//1234
echo 1234 |sed 'H;G' |grep 1234
//1234
//1234
awk
处理格式化数据有有优势,并能进行一些运算
主要分为列
$n 当前记录的第n个字段,字段间由FS分隔
$0 完整的输入记录
ARGC 命令行参数的数目
ARGIND 命令行中当前文件的位置(从0开始算)
ARGV 包含命令行参数的数组
CONVFMT 数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组
ERRNO 最后一个系统错误的描述
FIELDWIDTHS 字段宽度列表(用空格键分隔)
FILENAME 当前文件名
FNR 各文件分别计数的行号
FS 字段分隔符(默认是任何空格)
IGNORECASE 如果为真,则进行忽略大小写的匹配
NF 一条记录的字段的数目
NR 已经读出的记录数,就是行号,从1开始
OFMT 数字的输出格式(默认值是%.6g)
OFS 输出记录分隔符(输出换行符),输出时用指定的符号代替换行符
ORS 输出记录分隔符(默认值是一个换行符)
RLENGTH 由match函数所匹配的字符串的长度
RS 记录分隔符(默认是一个换行符)
RSTART 由match函数所匹配的字符串的第一个位置
SUBSEP 数组下标分隔符(默认值是/034)
输出第一列的数据和第二列.
awk -va=1 '{print $1,$(1+a)}' log.txt
awk -F[ ] 'print $1,$2' filename
tasklist |awk "$1 ~ /^ch/" ^符号能匹配首
tasklist |awk '$1 ~ /^ch/' ^ 符号无用
原因未知,单引号下 ^ 无用,可能单引号中使 ^解析无效
对后面字符的变量还需要解析用双引号,否则 单引号
估计是 ^需要解析
过滤第一列大于2并且第二列等于’Are’的行
awk '$1>2 && $2=="Are" {print $1,$2,$3}' log.txt
BEGIN{ 这里面放的是执行前的语句 }
END {这里面放的是处理完所有的行后要执行的语句 }
{这里面放的是处理每一行时要执行的语句}
awk "length>12" log.txt 正常
awk 'length>12' log.txt无法执行,显示语法错误,网络例子
得到chome的最大进程id
tasklist |grep chrome.exe |awk "BEGIN {max = 0} {if ($2>max) max=$2 } END {print \"MaxPid=\", max}"
字符串转数字
awk 'BEGIN{a="100";b="10test10";print (a+b+0);}'
字符串拼接
awk 'BEGIN{a="a";b="b";c=(a""b);print c}'
修改同一个文件
awk '$4 ^<= 20 { printf "%s\t%s\n", $0,"*" ; } $4 ^> 20 { print $0 ;} ' log.txt |awk '{print $0 ^> "log.txt"}'
附录高级例子
多个文件
#cat account
张三|000001
李四|000002
#cat cdr
000001|10
000001|20
000002|30
000002|15
想要得到的结果是将用户名,帐号和金额在同一行打印出来,如下:
张三|000001|10
张三|000001|20
李四|000002|30
李四|000002|15
执行如下代码
awk -F \| 'NR==FNR{a[$2]=$0;next}{print a[$1]"|"$2}' account cdr 官方例子错误,可能环境不同
awk -F"|" "BEGIN{OFS=FS};NR==FNR{a[$2]=$0;next}{print a[$1],$2}" account cdr
或者
awk -F "|" 'NR==FNR{a[$2]=$0;next}{print a[$1]"|"$2}' account cdr
注释:
由NR=FNR为真时,判断当前读入的是第一个文件account,然后使用{a[$2]=$0;next}循环将account文件的每行记录都存入数组a,并使用$2第2个字段作为下标引用.
由NR=FNR为假时,判断当前读入了第二个文件cdr,然后跳过{a[$2]=$0;next},对第二个文件cdr的每一行都无条件执行{print a[$1]"|"$2},此时变量$1为第二个文件的第一个字段,与读入第一个文件时,采用第一个文件第二个字段$2为数组下标相同.因此可以在此使用a[$1]引用数组。
next为跳过当前行
九九乘法表
seq 9 | sed 'H;g' | awk -v RS='' '{for(i=1;i^<=NF;i++)printf("%dx%d=%d%s", i, NR, i*NR, i==NR?"\n":"\t")}'
seq 9 | awk '{for(i=1;i^<=NR;i++)printf("%dx%d=%d%s", i, NR, i*NR, i==NR?"\n":"\t")}
echo "1 1 1 1 1 1 1 1 1" |awk -v RS=' ' '{for(i=1;i^<=NR;i++)printf("%dx%d=%d%s", i, NR, i*NR, i==NR?"\n":"\t")}
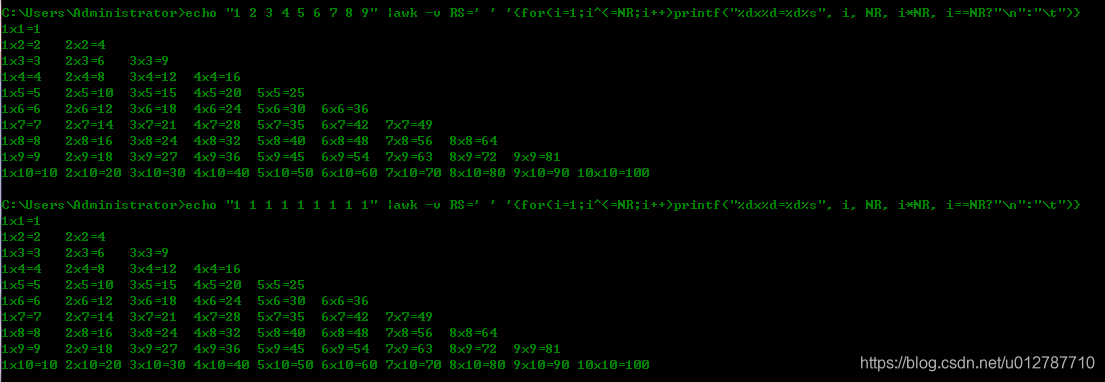
seq 产生一个序列 1-9
后续 原来错误的命令行
需要转义字符 ^ 居然是这个转义 还以为是 \
究其原因,原来是windows 下cmd和 linux下转义字符的区别
上面"错误"的官方例子,在windows cmd下应该修改为
awk -F ^| 'NR==FNR{a[$2]=$0;next}{print a[$1]"|"$2}' account cdr
awk 'length^>12' log.txt
tasklist |awk '$1 ~ /^^ch/'
或者用双引号就不需要转义
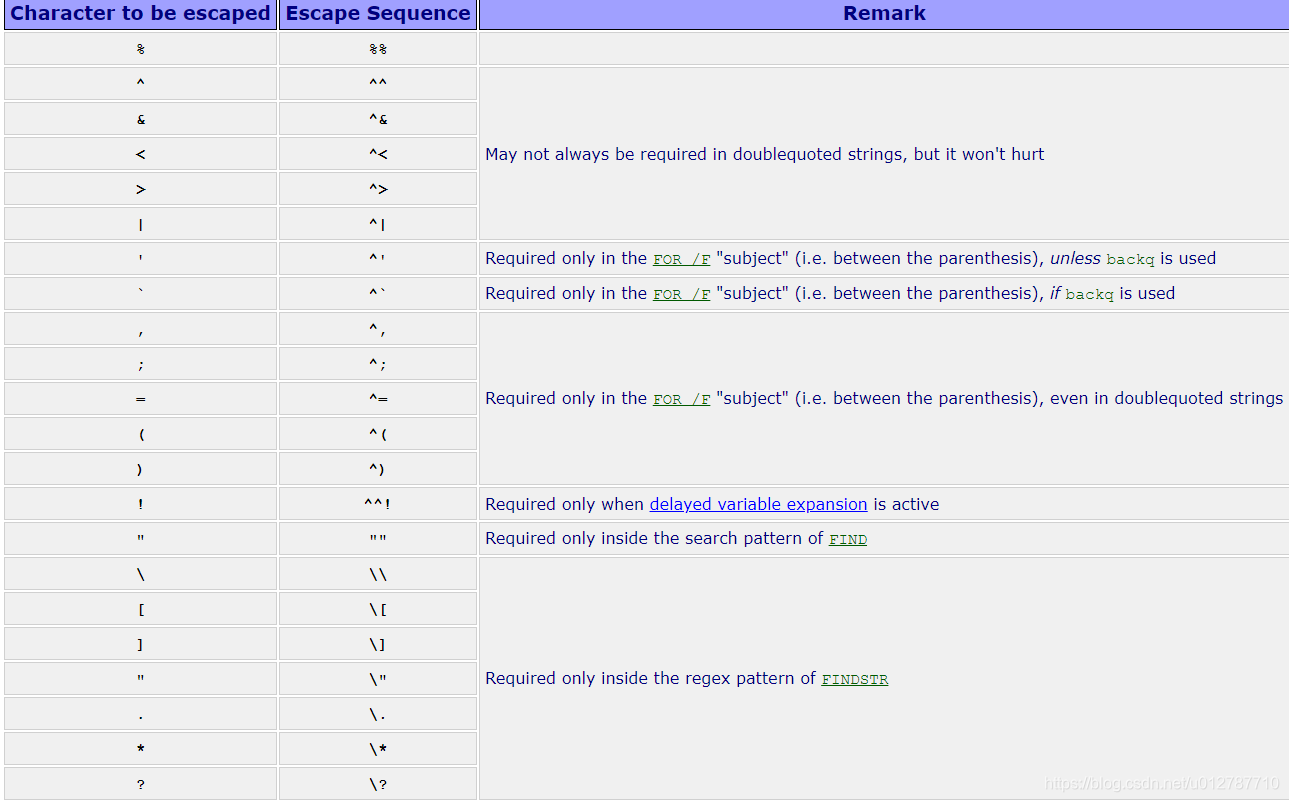
完整转义字符表查看
https://www.robvanderwoude.com/escapechars.php
完整grep
Usage: grep [OPTION]... PATTERN [FILE]...
Search for PATTERN in each FILE or standard input.
PATTERN is, by default, a basic regular expression (BRE).
Example: grep -i 'hello world' menu.h main.c
Regexp selection and interpretation:
-E, --extended-regexp PATTERN is an extended regular expression (ERE)
-F, --fixed-strings PATTERN is a set of newline-separated strings
-G, --basic-regexp PATTERN is a basic regular expression (BRE)
-P, --perl-regexp PATTERN is a Perl regular expression
-e, --regexp=PATTERN use PATTERN for matching
-f, --file=FILE obtain PATTERN from FILE
-i, --ignore-case ignore case distinctions
-w, --word-regexp force PATTERN to match only whole words
-x, --line-regexp force PATTERN to match only whole lines
-z, --null-data a data line ends in 0 byte, not newline
Miscellaneous:
-s, --no-messages suppress error messages
-v, --invert-match select non-matching lines
-V, --version display version information and exit
--help display this help text and exit
Output control:
-m, --max-count=NUM stop after NUM matches
-b, --byte-offset print the byte offset with output lines
-n, --line-number print line number with output lines
--line-buffered flush output on every line
-H, --with-filename print the file name for each match
-h, --no-filename suppress the file name prefix on output
--label=LABEL use LABEL as the standard input file name prefix
-o, --only-matching show only the part of a line matching PATTERN
-q, --quiet, --silent suppress all normal output
--binary-files=TYPE assume that binary files are TYPE;
TYPE is 'binary', 'text', or 'without-match'
-a, --text equivalent to --binary-files=text
-I equivalent to --binary-files=without-match
-d, --directories=ACTION how to handle directories;
ACTION is 'read', 'recurse', or 'skip'
-D, --devices=ACTION how to handle devices, FIFOs and sockets;
ACTION is 'read' or 'skip'
-r, --recursive like --directories=recurse
-R, --dereference-recursive likewise, but follow all symlinks
--include=FILE_PATTERN search only files that match FILE_PATTERN
--exclude=FILE_PATTERN skip files and directories matching FILE_PATTERN
--exclude-from=FILE skip files matching any file pattern from FILE
--exclude-dir=PATTERN directories that match PATTERN will be skipped.
-L, --files-without-match print only names of FILEs containing no match
-l, --files-with-matches print only names of FILEs containing matches
-c, --count print only a count of matching lines per FILE
-T, --initial-tab make tabs line up (if needed)
-Z, --null print 0 byte after FILE name
Context control:
-B, --before-context=NUM print NUM lines of leading context
-A, --after-context=NUM print NUM lines of trailing context
-C, --context=NUM print NUM lines of output context
-NUM same as --context=NUM
--color[=WHEN],
--colour[=WHEN] use markers to highlight the matching strings;
WHEN is 'always', 'never', or 'auto'
-U, --binary do not strip CR characters at EOL (MSDOS/Windows)
-u, --unix-byte-offsets report offsets as if CRs were not there
(MSDOS/Windows)
'egrep' means 'grep -E'. 'fgrep' means 'grep -F'.
Direct invocation as either 'egrep' or 'fgrep' is deprecated.
When FILE is -, read standard input. With no FILE, read . if a command-line
-r is given, - otherwise. If fewer than two FILEs are given, assume -h.
Exit status is 0 if any line is selected, 1 otherwise;
if any error occurs and -q is not given, the exit status is 2.
完整awk
Usage: awk [POSIX or GNU style options] -f progfile [--] file ...
Usage: awk [POSIX or GNU style options] [--] 'program' file ...
POSIX options: GNU long options: (standard)
-f progfile --file=progfile
-F fs --field-separator=fs
-v var=val --assign=var=val
Short options: GNU long options: (extensions)
-b --characters-as-bytes
-c --traditional
-C --copyright
-d[file] --dump-variables[=file]
-D[file] --debug[=file]
-e 'program-text' --source='program-text'
-E file --exec=file
-g --gen-pot
-h --help
-i includefile --include=includefile
-l library --load=library
-L[fatal|invalid] --lint[=fatal|invalid]
-M --bignum
-N --use-lc-numeric
-n --non-decimal-data
-o[file] --pretty-print[=file]
-O --optimize
-p[file] --profile[=file]
-P --posix
-r --re-interval
-S --sandbox
-t --lint-old
-V --version
To report bugs, see node `Bugs' in `gawk.info', which is
section `Reporting Problems and Bugs' in the printed version.
gawk is a pattern scanning and processing language.
By default it reads standard input and writes standard output.
Examples:
gawk '{ sum += $1 }; END { print sum }' file
gawk -F: '{ print $1 }' /etc/passwd
完整sed
Usage: sed [OPTION]... {
script-only-if-no-other-script} [input-file]...
-n, --quiet, --silent
suppress automatic printing of pattern space
-e script, --expression=script
add the script to the commands to be executed
-f script-file, --file=script-file
add the contents of script-file to the commands to be executed
--follow-symlinks
follow symlinks when processing in place
-i[SUFFIX], --in-place[=SUFFIX]
edit files in place (makes backup if SUFFIX supplied)
-b, --binary
open files in binary mode (CR+LFs are not processed specially)
-l N, --line-length=N
specify the desired line-wrap length for the `l' command
--posix
disable all GNU extensions.
-r, --regexp-extended
use extended regular expressions in the script.
-s, --separate
consider files as separate rather than as a single continuous
long stream.
-u, --unbuffered
load minimal amounts of data from the input files and flush
the output buffers more often
-z, --null-data
separate lines by NUL characters
--help display this help and exit
--version output version information and exit
If no -e, --expression, -f, or --file option is given, then the first
non-option argument is taken as the sed script to interpret. All
remaining arguments are names of input files; if no input files are
specified, then the standard input is read.