tf.keras.layers.Conv2D
tf.keras.layers.Conv2D(
filters, kernel_size, strides=(1, 1), padding='valid', data_format=None,
dilation_rate=(1, 1), groups=1, activation=None, use_bias=True,
kernel_initializer='glorot_uniform', bias_initializer='zeros',
kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None,
kernel_constraint=None, bias_constraint=None, **kwargs
)
说明:
当作为网络第一层的时候,input_shape=(128, 128, 3)表示128x128的图片,RGB共3个通道,通道数在最后一个。
案例:
# The inputs are 28x28 RGB images with `channels_last` and the batch
# size is 4.
input_shape = (4, 28, 28, 3)
x = tf.random.normal(input_shape)
y = tf.keras.layers.Conv2D(
2, 3, activation='relu', input_shape=input_shape[1:])(x)
print(y.shape)
输出:(4,26, 26 ,2)
# With `padding` as "same".
input_shape = (4, 28, 28, 3)
x = tf.random.normal(input_shape)
y = tf.keras.layers.Conv2D(
2, 3, activation='relu', padding="same", input_shape=input_shape[1:])(x)
print(y.shape)
输出:(4,28, 28 ,2)
# With extended batch shape [4, 7]:
input_shape = (4, 7, 28, 28, 3)
x = tf.random.normal(input_shape)
y = tf.keras.layers.Conv2D(
2, 3, activation='relu', input_shape=input_shape[2:])(x)
print(y.shape)
输出:(4,7,26, 26 ,2)
# With `dilation_rate` as 2.
input_shape = (4, 28, 28, 3)
x = tf.random.normal(input_shape)
y = tf.keras.layers.Conv2D(
2, 3, activation='relu', dilation_rate=2, input_shape=input_shape[1:])(x)
print(y.shape)
输出:(4,24, 24 ,2)
如何理解 dilation_rate?参见这个链接,感谢原博主分享。
dilation rate 指的是kernel的间隔数量(e.g. 正常的 convolution 是 dilatation rate 1)。
dilatation rate = 1
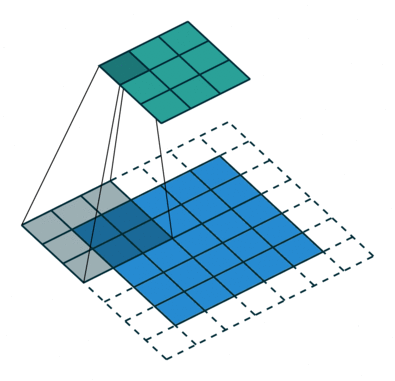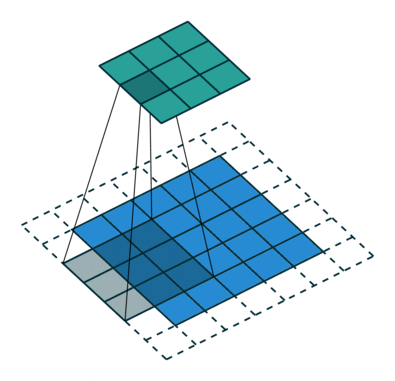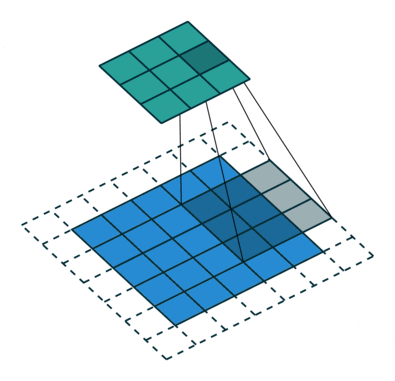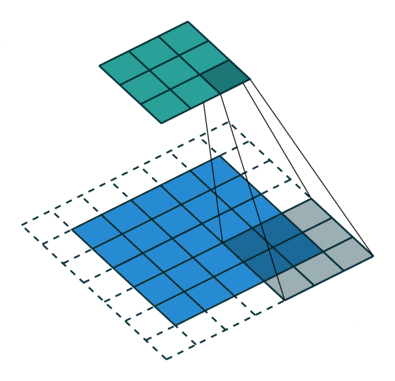
dilatation rate = 2
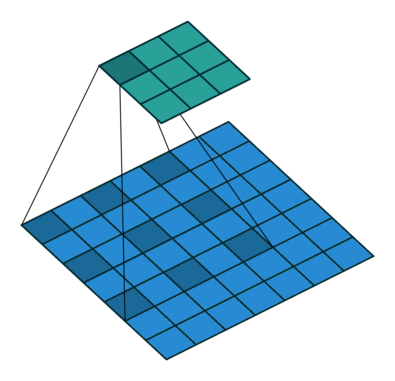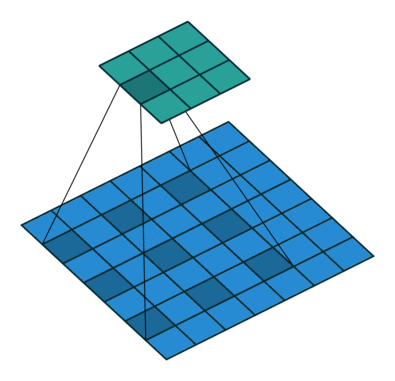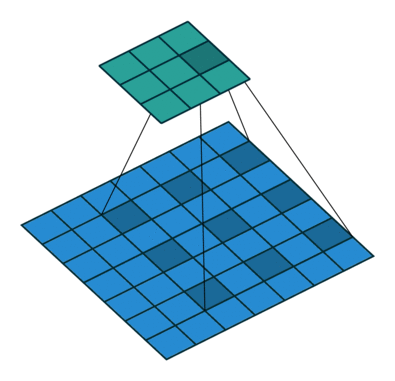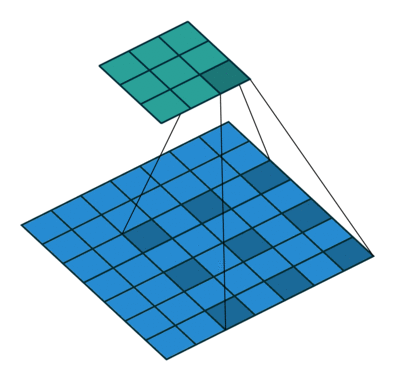
可见,dilatation rate的作用就是将kernel的大小膨胀为kernel_size + (dilatation rate -1)。
tf.keras.layers.Conv2DTranspose
是普通卷积的逆运算,所以参数和卷积运算相同。
函数原型:
tf.keras.layers.Conv2DTranspose(
filters, kernel_size, strides=(1, 1), padding='valid', output_padding=None,
data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True,
kernel_initializer='glorot_uniform', bias_initializer='zeros',
kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None,
kernel_constraint=None, bias_constraint=None, **kwargs
)
Input shape:
3D tensor with shape: (batch_size, steps, channels)
Output shape:
3D tensor with shape: (batch_size, new_steps, filters) If output_padding is specified:
复杂的在于计算输出tensor的维度。
(1)当没有设置output_padding时:
# 当padding="valid"时
new_rows = (rows - 1) * strides[0] + kernel_size[0]
new_cols = (cols - 1) * strides[1] + kernel_size[1]
# 当padding="same"时
new_rows = rows * strides[0]
new_cols = cols * strides[1]
(2)当设置output_padding时:
# padding="valid"时,padding=[0,0]
# padding="same"时,padding=[1,1]
# 注意output_padding的大小小于strides
new_rows = ((rows - 1) * strides[0] + kernel_size[0] - 2 * padding[0] +
output_padding[0])
new_cols = ((cols - 1) * strides[1] + kernel_size[1] - 2 * padding[1] +
output_padding[1])