简介
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、 分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将 对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
应用场景
功能
特点
安装部署
一般在linux系统安装,推荐使用docker安装(参考《Docker入门及技术指南》https://blog.csdn.net/yan_dk/article/details/89427641),
1.首先,取得Elasticsearch镜像
# docker pull elasticsearch:7.12.1
cluster.name: my-application #集群名称
node.name: node-1 #节点名称 #数据和日志的存储目录
path.data: /usr/share/elasticsearch/data
path.logs: /usr/share/elasticsearch/logs
##设置绑定的ip,设置为0.0.0.0以后就可以让任何计算机节点访问到了
network.host: 0.0.0.0
http.port: 9200 #端口
##设置在集群中的所有节点名称,这个节点名称就是之前所修改的,当然你也可以采用默认的也 行,目前 是单机,放入一个节点即可
cluster.initial_master_nodes: ["node-1"]docker run -p 9200:9200 -d --name es -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -v /docker/es/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /docker/es/data:/usr/share/elasticsearch/data -v /docker/es/plugins:/usr/share/elasticsearch/plugins --privileged=true elasticsearch:7.12.14.查看运行状态、日志
# docker ps

# docker logs es

上述发现报错
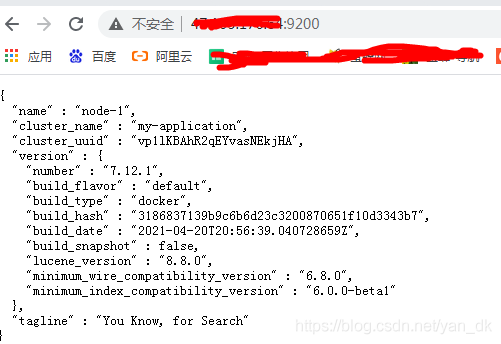
安装kibana
Kibana 是一个免费且开放的用户界面,能够让您对 Elasticsearch 数据进行可视化,并让您在 Elastic Stack 中进行导航。您可以进行各种操作,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成。
我理解,如果把ES比作mysql数据库,那kibana就相当于Navigate之类的数据库客户端工具。
1.获取kibana镜像
server.name: kibana
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://你的es地址:9200"]
xpack.monitoring.ui.container.elasticsearch.enabled: true查看docker的es的ip地址
# docker inspect es
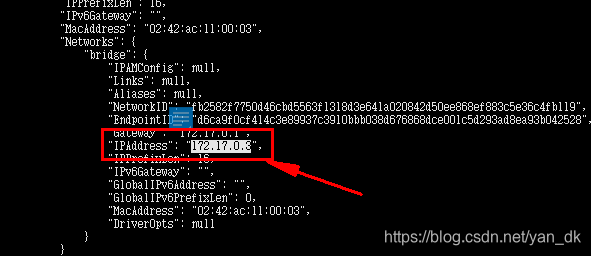
修改上述ip地址为图示的172.17.0.3
3.构建kibana的容器
docker run -p 5601:5601 -d --name kibana -v /docker/kibana/conf/kibana.yml:/usr/share/kibana/config/kibana.yml --privileged=true kibana:7.12.1查看docker容器状态
# docker ps

4.上述正常后,访问浏览器http://ip:5601,如下图
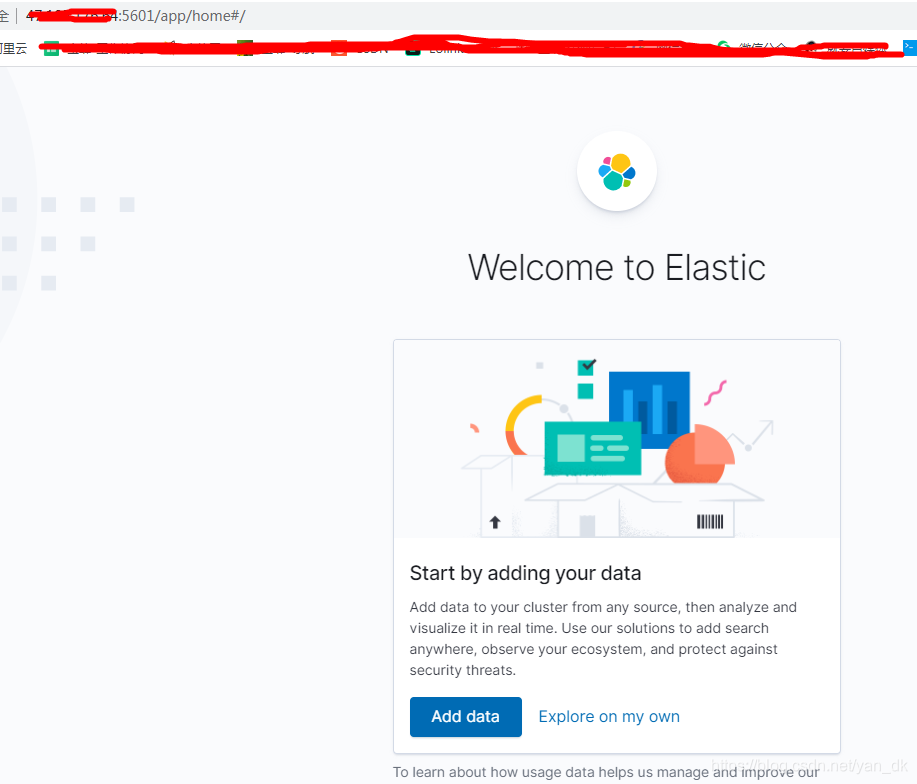
说明正常安装了kibana 。
安装IK分词器插件
Ik 分词器:比较适合中文的一个分词器
分词器:把一段文字划分成一个个关键字,我们在搜索的时候会把自己的搜索信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行匹配操作。elasticsearch默认分词器是把每个字分成一个词,这显然不行,所以想使用中文,建议用IK分词器
IK软件包下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v5.6.16
1、解压 elasticsearch-analysis-ik-5.6.16.zipunzip elasticsearch-analysis-ik-5.6.16.zip
将解压文件放在 /docker/es/plugins/ik 目录下。
2. 重启es
# docker restart es
查看状态及日志,看看是否启动成功。
#docker ps
#docker logs es
ES的花式查询
浏览器http://{你的es的ip}:5601

创建一个索引
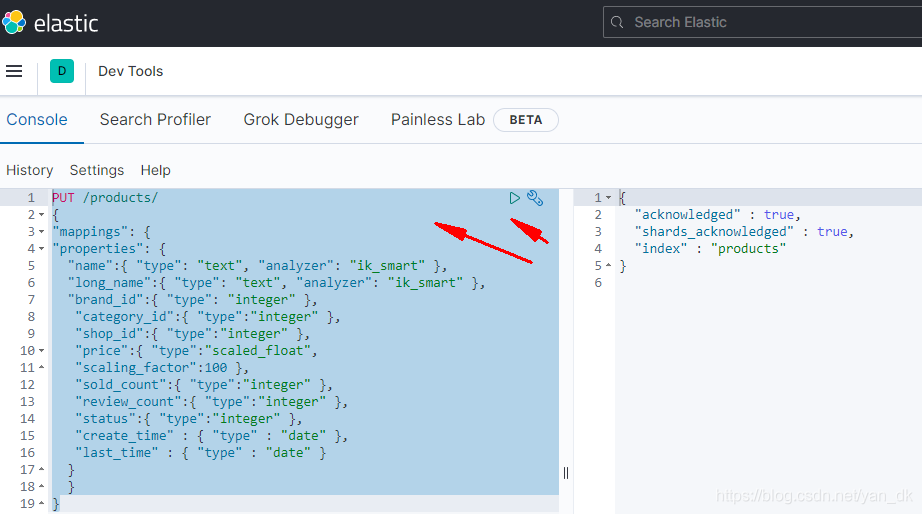
PUT /products/
{
"mappings": {
"properties": {
"name":{ "type": "text", "analyzer": "ik_smart" },
"long_name":{ "type": "text", "analyzer": "ik_smart" },
"brand_id":{ "type": "integer" },
"category_id":{ "type":"integer" },
"shop_id":{ "type":"integer" },
"price":{ "type":"scaled_float",
"scaling_factor":100 },
"sold_count":{ "type":"integer" },
"review_count":{ "type":"integer" },
"status":{ "type":"integer" },
"create_time" : { "type" : "date" },
"last_time" : { "type" : "date" }
}
}
}
GET /products/_searchkibana的dev tools工具右侧得到相应的结果,类似指令GET POST、PUT等可以一一类似执行查看,这里不再罗列。记住以下语法关键词:
精确查询term,模糊查询match
返回字段source
排序sort
分页from、size
过滤器条件filter、范围条件range
高亮选择highlight