MySQL 可以说是每个 Java 程序员必会的技能之一,作为 Java 的高级进阶必备技能点,MySQL 的调优和底层原理必然是需要知道的。
但是大家似乎形成了一种思维定势,那就是提到 MySQL 好像就一股脑的往 MySQL 的索引啊、优化啊、之类的上面去钻。本文我们抛开“热门”的话题,来和大家一起来聊一聊比较冷门但比较重要的技术点:MySQL 事务的底层原理
这事情还得从头说起
首先大家需要知道的是 MySQL 是支持事务并发执行的,这又回到了最原始的问题了,「并发安全性问题」。在数据库事务中并发问题是这样子的:A 事务来写某条记录的数据,B 事务也在写该条记录的数据。那如果啥也不做,势必会造成数据的错乱,MySQL 在设计之初就考虑到了这个问题。
那么 MySQL 到底是如何解决这样的问题的呢?其实是使用了 MVCC 多版本控制机制、事务隔离机制、锁机制等办法来解决事务并发问题。那说到这里不知道各位有没有想过这样一个问题:在数据库中如果并发事务不做控制和处理,会有什么样的危害呢?
带着这样的疑问,请继续往下看。
脏数据
什么是脏数据,它有哪些类型
脏数据的具体概念有以下四种,分别是:脏写、脏读、不可重复读、幻读。我们来看看这几个概念的意思
1、脏写
脏写是指一个事务修改且已经提交的数据被另外一个事务给回滚了
首先来分析一下概念:假设有两个事务 A、B。事务 A 先开启事务,并且修改了一条 id 为 1 的记录,将 name 改成 A(假设原来为 null),但是此时 事务 A 还没有提交。这个时候事务 B 开启了。事务 B 将 id 为 1 的记录中 name 改成了 B,并且将事务提交 了。但是这个时候事务 A 不想修改了,就像之前自己修改的数据回滚了。也就是说此时导致的结果就是 id 为 1 的这条记录的 name 还是为 null。
然后事务 B 去查询这条记录。结果蒙了。name 居然为 null。这就是脏写。事务 B 已经写入的记录被事务 A 给回滚了。

看不懂没有关系,我们先来看一张图

对着图再来看一下上面的分析过程。
那 MySQL 是如何来解决脏写这种问题的?没错,就是锁。MySQL 在开启一个事务的时候,他会将某条记录和事务做一个绑定。这个其实和 JVM 锁是类似的。因为此时事务 A 先开启了,并关联绑定了这条记录。所以事务 B 此时如果想操作同样的记录,只能等待。当事务 A 执行完成了,就会通知正在等在事务。然后下一个事务继续操作执行。
啥?说好的并发,这说到底不还是串行吗?这样数据库岂不是慢的要死。实际上这些操作都是在内存中执行的。具体一点是在 Buffer Pool 中执行的。所以速度是非常快的。
2、脏读
脏读是指一个事务读取到了另外一个事务没有提交的记录
其实脏读是最好理解的。我们还是假设有两个事务 A、B。事务 A 先开启了,将 id 为 1 的记录中的 name 改成了 A,但是还没有提交。此时事务 B 开启了。事务 B 查询到当前 name 的值为 A,然后就会按照 A 逻辑去执行处理。结果事务 A 回滚了事务,事务 B 再次查询的时候发现记录值不是 A。这就是脏读。
事务 B 读取到的 name 值是事务 A 修改但是没有提交的记录。
来张图来直观的理解下:

3、不可重复读
不可重复读是指前后读取到的某条记录的结果不一样
废话少说,直接进分析:假设有三个事务 A、B、C ,事务 A 先开启了,但是还没有执行任何的操作,事务 B 开启了,事务 B 将 id 为 1 的记录的 name 改为 B 并提交了事务,此时事务 A 开始活动了,查询到的这条记录的 name 值为 B,还是还未执行任何操作。此时事务 C 开启了,事务 C 将 id 为 1 的记录的 name 改为 C 并提交了事务。此时事务 A 又开始活动了,结果查询到的 id 为 1 的 name 值又变成了 C。这就是不可重复读
其实理解起来还是很简单的。看起来高大上名字,实际上就这么几句话就能描述结束了。下面还是来一张图来更直观认识下:

4、幻读
幻读是指前后读取到的记录的数量不一样
幻读和不可重复读有点类似,不可重复读强调的是数据的值不一样,重点是修改修改,而幻读强调的是记录的数量不一样,重点是新增或删除。就好像是看花眼产生重影一样。
先来分析一下幻读。还是假设有两个事务 A、B。事务 A 先开启了,并执行了这样的 SQL:select * from user,假设现在结果是 5 条,此时事务 B 开启了,并往 user 表中插入了一条记录,并提交了事务,此时事务 A 又执行了 select * from user结果发现是 6 条记录。懵逼了。还以为自己饿昏了眼花了。这就是所谓的幻读。

以上的四个问题是现代数据库典型的问题,这些问题会在不同的数据库的事务隔离级别下产生。所以下面要分析的就是事务的隔离级别。
事务的隔离级别
事务的隔离级别有以下四种
-
Read Uncommitted:读取未提交【生产估计没人这么设置的】
意思就是一个事务能够读取到另一个事务未提交的修改 -
Read Committed[简称 RC]:读取已提交
意思就是一个事务能读取到另一个事务已经提交了的修改 -
Repeatable read[简称 RR]:可重复读
【MySQL 的默认隔离级别】,即事务之间只要是在进行中,彼此之间不会有任何的干扰 -
serializable:串行化
这个就有点狠了,就好比 Java 中的 synchroinzed 关键字,所有的请求只能一个一个来还行,很显然效率最低,基本也不会使用这种隔离剂呗
| 隔离级别 | 脏读 | 脏写 | 不可重复读 | 幻读 |
|---|---|---|---|---|
| Read Uncommitted:读取未提交 | √ | × | √ | √ |
| Read Committed:读取已提交 | × | × | √ | √ |
| Repeatable read:可重复读 | × | × | × | √ |
| Serializable:串行化(也有称序列化的) | × | × | × | × |
MVCC 机制
MVCC(全称 Multi-Version Concurrency Control),即多版本并发控制。MVCC 是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问;
我们本文的重点是事务的隔离级别的底层原理,但是似乎说到现在也并没有发现关于事务原理的影子(想发水文?)。

实际上要了解事务的底层原理,根本没法上来就开鲁,我相信那样的文章写出来不仅没人看,更是看不懂。所以为了让大家由浅入深的慢慢掌握。我必须要做很多铺垫,将相关的知识点进行抛砖引玉,然后一层一层剖析到原理。这里还请大家明白。
说到这里,我们又要提到一个新的概念了。就是数据在磁盘存储的时候,每一条存储的记录都会有事务 ID 和回滚指针(其他的是什么本文不需要关注,学习抓住脉路即可,否则必定走火入魔)。

这两个到底是干嘛的?我们还是先从概念说起
事务 ID:就是每个事务的唯一标识
回滚指针:该事务之前的记录的引用(指针)。换句话说就是相对现在时间节点的老数据
假设你需要操作某条记录,首先该条记录一定是先被加载到 Buffer Pool 中的,并且有这样的一条 undo log 记录。
画外音:undo log 就是修改前的记录。用于回滚的。

假设现在事务 A 开启了事务,将值改为 A

事务 A 还在活跃中,这个时候事务 B 开启了,将值改为 B
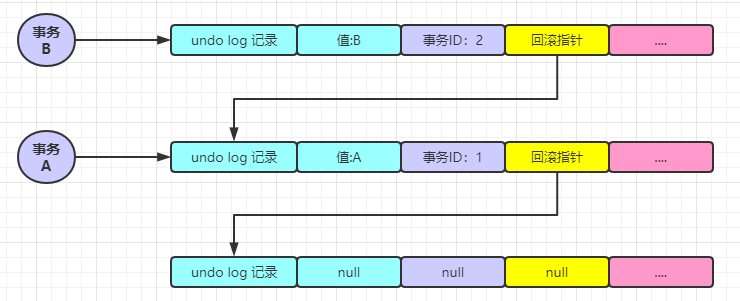
此时事务 A 和事务 B 都还在活跃中,这个时候事务 C 开启了,并将值改为 C

看到这里是不是稍微有一点感觉了。这上面的图有一个专有名词:MVCC 版本控制链。同时这里又涉及到一个新的名词:ReadView。就是每个事务在开启的时候都会创建一个 ReadView 视图。那具体什么叫 ReadView ,我们这里还不能一带而过,相反需要我们来详细的讨论分析下。
ReadView
ReadView 可能是你理解事务底层原理的核心部分,那么什么是 ReadView 呢
在每个事务开启的时候都会创建一个 ReadView 视图,作用就是用来记录每个事务中的操作的一些 Undo Log 记录。
他里面涉及到几个字段。分别是:m_ids、min_trx_id、max_trx_id、creator_trx_id。他们的具体含义如下:
-
m_ids:用于记录活跃中的事务的 ID;
-
min_trx_id:当前活跃的事务中的最小的事务 ID;
-
max_trx_id:下一个即将要生成的事务 ID。注意这里并不是指的最大的事务 ID,这个事务一定是当前的 m_ids 中不存在的。(事务 ID 的生成是递增的);
-
creator_trx_id:当前活跃事务的 ID;
不要慌,光说概念一定是在耍流氓。下面我会通过图文并茂的形式来一一说明解释。假设有一个记录现在是这样存放的

看到这里大家应该知道的是,这条记录一定是原来的某一个事务修改后的结果。也就是说这是一条原本的已经存在的记录。
现在假设有 A、B、C 三个事务,他们分别先后开启,假设他们的事务 ID 依次为:4、5、6。
先来看事务 A,此时的m_ids 为:[4、5、6],min_trx_id 为:4,max_trx_id 为 7,creator_trx_id 为 4。

事务 A 首先执行了一次查询操作,他此时是这么执行的:
首先他会顺着 MVCC 的版本控制链往下找。找啥?找该条记录的以前操作它的事务 ID,他发现找到的这个 undolog 日志的对应的事务 ID 为 3,比自己的 4 要小,所以可以肯定这条记录不是自己修改的,而又因为 m_ids 中的事务 ID 为 4、5、6,3 是比他们都要小的,所以可推断出查找到的这条记录是在本次事务开启之前就已经存在的。所以事务 A 查询到的值为 C。
此时事务 B 同样开始查询这条记录了。以此类推事务 B 此时的执行流程大概是这样子的,首先事务 B 会以同样的方式查询数据(PS:这些操作都是在内存中的)同样查询到的结果是 C,经过上面的的对于事务 A 的分析,相信这里已经不是问题了。但是假如现在事务 B 将该值改成了 B,也就是下面的这张图的样子。

此时事务 A 又开始活跃了,还是执行查询操作,这个时候结果该是多少呢?
首先事务 A 发现同样会顺着该条记录的 MVCC 版本控制链往下找,发现事务 ID 为 5 ,比 m_ids 中的最小的事务 ID 4 要大,那么可以且是存在于该集合中的,此时就可以断定事务 ID 为 5 的事务是正在进行中的事务,所以事务 A 是不会取该条 undo log 的值的。
然后继续往下找,找到了事务 ID 为 3 的 undo log 记录,对比后发现 3 不在 m_ids 中,且比 m_ids 中的最小的事务 ID 都要小。下面的判断就和刚开始的查询判断一样了。
假设此时事务 A 将该条记录的值改成 A ,然后事务 A 再查询这条记录,那么请问这个时候事务 A 查询是怎么样子的(这一步非常重要)?现在这些事务以及数据在我们的脑袋中应该是这样子的:

那么事务 A 到底是怎么查询的?查出来的结果到底是 A 还是 B?先来看下这张图,然后根据图一步一步来分析

事务 A 开始查询,返现此时的 undo log 日志针对于该条记录的 undo log 链(MVCC 版本链的另一种叫法)的第一条记录的事务 ID 为 4 ,一对比发现不就是自己修改的值吗?那么查询的结果就是 A。
那么此时如果是事务 B 来执行查询呢?结果你能否分析一下?那就是首先 B 发现最新的事务 ID 为 4 ,且在 m_ids 中,可以断定这是一条正在执行中的事务,且不和自己的一样,所以是不会取该值的。
然后继续顺着 undo log 日志链往下找,找到了事务 ID 为 5 的记录,发现和自己的一样,那这个不就是需要查找的结果吗?也就是说 事务 B 查找到的结果是 B。
以上是关于 ReadView 的相关的介绍,总体内容不算难,但是是需要认真思考的,这里先来一个小总结
-
ReadView 其实使用版本链机制
-
他里面的核心属性为:
-
m_ids: 一个列表, 存储当前系统活跃的事务 id (重点)
-
min_trx_id: 当前 m_ids 活动事务中的最小的事务 ID
-
max_trx_id: 下一个即将被分配出来的事务 ID
-
creator_trx_id: 当前的事务的 ID
- ReadView 记录的是:每个事务中的 Undo log 日志
说到这里,下面继续来分析本文的主题知识点:事务的底层原理(其实上面多多少少都说到了)。其实事务的底层就是基于 ReadView 来设计的。关于事务的底层原理,我们以 RC(Read Commit)和 RR(Repeatable read)来分析
1. Read commit
Read Commit 是事务隔离级别的其中一种,含义是:读取已经提交的记录。举个例子来说,假设有事务 A 和事务 B 都在活动中,事务 B 提交的记录是能够被事务 A 读取到的。
具体我们开始一步一步来分析。首先需要大家知道的是在 RC 隔离级别下,一个事务的每次查询操作,数据库都会为其创建一个新的 ReadView,这就是 RC 的核心思想。
假设有事务 A 和事务 B ,事务 ID 分别为 10 和 11,事务 A 还没开始活跃,事务 B 就将某条记录的值改为 B(假设原来的值为 X),但是还未提交,现在你可以想象一下下面这张图:

此时事务 A 开始活跃了,他首先执行了一次查询操作。按照上面的核心思想,此时数据库会重新创建一个 ReadView 里面的几个属性的值分别为:
-
m_ids:[10,11]
-
min_trx_id:10
-
max_trx_id: 12
-
creator_trx_id:10
接着就是就是和上面说过的一样的查询过程了,首先 A 查询到的最近的一个事务 ID 为 11,发现在 m_ids 中,但是又和自己的事务 ID 不相等,所以就会顺着 undo log 链继续查找,然后找到了事务 ID 为 3 的记录,发现不在 m_ids 中且,比最小的事务 ID 10 还要小,所以可以断定出事务 ID 为 3 的这个记录是原本就存在的记录,所以查询到的结果就是 X。
接着事务 B 又开始活跃了,事务 B 直接提交了事务,然后事务 A 又发起了一起查询操作。现在这个时候就是 RC 的核心了:这个时候数据库会再次为事务 A 创建一个新的 ReadView 里面的四个属性分别为:
-
m_ids:[10]
-
min_trx_id:10
-
max_trx_id: 12
-
creator_trx_id:10
然后 A 按照正常的流程去查询,首先查询到的是事务 ID 为 11 的记录,结果发现不在 m_ids 中,那这个时候就可以断定的是:这个是最近已经提交的记录,所以是能够查询到 B 这个值的,也就是说这次查询得到的结果就是 B 。
这就是 RC,是不是如果看懂了 ReadView 原理,这些再看起来就非常简单了?
2. Repeatable read
Repeatable read 是 MySQL 默认的隔离级别,既然是默认的,那一定是很厉害咯?其实你看完会发现 just so so ?

RR 的核心思想是:ReadView 创建以后直到事务提交,都不会再次重新生成。
首先还是有事务 A 和事务 B,事务 ID 分别为 10 和 11 ,事务 B 首先将值改为 B (假设原来值为 X),然后 事务 A 发起了一次查询的操作:

查询过程和前面的一模一样。我就不再赘述了。
接着事务 B 又开始活跃了,直接提交了事务,然后事务 A 又发起了一次查询。这个时候奇迹就出现了。因为我们刚刚说了:ReadView 创建以后直到事务提交,都不会再次重新生成。因为事务 A 在创建 ReadView 的时候 m_ids 是 10 和 11,所以现在查询的时候里面仍然是这个值,现在的查询是这样子的:事务 A 首先查询到的事务 ID 为 11 ,结果发现在 m_ids 中,也就不会取该值,会继续查找,当查找到事务 ID 为 3 的时候,发现不在 m_ids 中,所以查询到的就是 X。
现在你知道为什么这个隔离级别下的事务不会互相干扰了吧?这就是原理
本文小结
本文为了说明事务的底层原理,做了大量的铺垫,相信大家看完不光对不同隔离级别下事务的实现会有更深刻地理解,也同时明白了 undo log 记录的作用,所以多探索一下底层你会发现各种知识点是如何串在一起工作的,这种通透的感觉确实很奇妙