数据转换:

框架,架构:

格式转换, 矩阵类型转换:
torch.sparse:
-
初始化一个tensor的稀疏矩阵, 用 coo稀疏矩阵
-
参数:
-
描述位置的矩阵
-
元素值
-
i = torch.LongTensor([[0, 1, 1],[2, 0, 2]]) #位置矩阵
v = torch.FloatTensor([3, 4, 5]) #元素值
torch.sparse.FloatTensor(i, v, torch.Size([2,3])).to_dense()
0 0 3
4 0 5
[torch.FloatTensor of size 2x3]torch.floor:
-
作用: 返回一个新张量,包含输入
input张量每个元素的floor,即不小于元素的最大整数。 -
出处: 看代码时, 在实现dropout_mask时使用
torch.view:
-
重点: -1的意思: 不想自己算, 先填成-1, 计算机会自动帮你补
-
作用: 类比reshape()
import torch
a = torch.arange(0,20) #此时a的shape是(1,20)
a.view(4,5).shape #输出为(4,5)
a.view(-1,5).shape #输出为(4,5)
a.view(4,-1).shape #输出为(4,5)torch.load:
-
从磁盘文件中读取一个通过
torch.save()保存的对象。
torch.load(f, map_location=None, pickle_module=<module 'pickle' from '/home/jenkins/miniconda/lib/python3.5/pickle.py'>)-
可通过参数
map_location动态地进行内存重映射,使其能从不动设备中读取文件。
>>> torch.load('tensors.pt')
# Load all tensors onto the CPU
>>> torch.load('tensors.pt', map_location=lambda storage, loc: storage)
# Map tensors from GPU 1 to GPU 0
>>> torch.load('tensors.pt', map_location={'cuda:1':'cuda:0'})
-
用户可以通过register_package进行扩展,使用自己定义的标记和反序列化方法。???
torch.manual_seed() 和 torch.cuda.manual_seed():
-
功能:设置固定生成随机数的种子,使得每次运行该 .py 文件时生成的随机数相同
-
CPU:torch.manual_seed(整数)
-
GPU:torch.cuda.manual_seed(整数)
torch.normal:
- 返回一个张量,包含从给定参数
means,std的离散正态分布中抽取随机数。
torch.normal(means, std, out=None)
torch.norm:
- 返回输入张量
input的p 范数。
torch.norm(input, p=2) → float
torch.rand:
torch.rand(2, 3)
0.0836 0.6151 0.6958
0.6998 0.2560 0.0139
[torch.FloatTensor of size 2x3]- 均匀分布:
- 返回一个张量,包含了从区间[0, 1)的均匀分布中抽取的一组随机数。
torch.randn:
- 标准正太分布:
- 返回一个张量,包含了从标准正态分布(均值为0,方差为1,即高斯白噪声)中抽取的一组随机数。
torch.randn(2, 3)
0.5419 0.1594 -0.0413
-2.7937 0.9534 0.4561
[torch.FloatTensor of size 2x3]torch.mul:
- 核心:普通标量相乘
- 张量和标量相乘:每个元素×数值
#输入张量和标量相乘
torch.mul(input, value, out=None)
例:
>>> a = torch.randn(3)
>>> a
-0.9374
-0.5254
-0.6069
[torch.FloatTensor of size 3]
>>> torch.mul(a, 100)
-93.7411
-52.5374
-60.6908
[torch.FloatTensor of size 3]- 张量和张量相乘:对应元素直接相乘
#两个张量相乘
torch.mul(input, other, out=None)
>>> a = torch.randn(4,4)
>>> a
-0.7280 0.0598 -1.4327 -0.5825
-0.1427 -0.0690 0.0821 -0.3270
-0.9241 0.5110 0.4070 -1.1188
-0.8308 0.7426 -0.6240 -1.1582
[torch.FloatTensor of size 4x4]
>>> b = torch.randn(2, 8)
>>> b
0.0430 -1.0775 0.6015 1.1647 -0.6549 0.0308 -0.1670 1.0742
-1.2593 0.0292 -0.0849 0.4530 1.2404 -0.4659 -0.1840 0.5974
[torch.FloatTensor of size 2x8]
>>> torch.mul(a, b)
-0.0313 -0.0645 -0.8618 -0.6784
0.0934 -0.0021 -0.0137 -0.3513
1.1638 0.0149 -0.0346 -0.5068
-1.0304 -0.3460 0.1148 -0.6919
[torch.FloatTensor of size 4x4]torch.cat():
import torch
A = torch.ones(2,3)
B = torch.ones(2,3)*2
print('A:',A)
print('A:',A.shape)
print('----------------------')
print('B:',B)
print('B:',B.shape)
print('-----------------------')
C = torch.cat((A, B)) #默认dim=0
print('C:',C)
print('C:',C.shape)
print('_______________________')
D = torch.cat((A, B), dim=1)
print('D:',D)
print('D:',D.shape)
参考博文:https://blog.csdn.net/qq_39938666/article/details/89356542
torch.cat()和torch.stack()的对比:
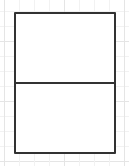
>>> import torch
>>> a = torch.rand((2, 3))
>>> b = torch.rand((2, 3))
>>> c = torch.cat((a, b))
>>> a.size(), b.size(), c.size()
(torch.Size([2, 3]), torch.Size([2, 3]), torch.Size([4, 3])) #看这里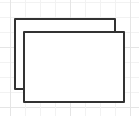
>>> import torch
>>> a = torch.rand((2, 3))
>>> b = torch.rand((2, 3))
>>> c = torch.stack((a, b))
>>> a.size(), b.size(), c.size()
(torch.Size([2, 3]), torch.Size([2, 3]), torch.Size([2, 2, 3])) #看这里torch.empty():
- 创建一个未被初始化值的tensor
