-
reference
阮一峰:字符编码笔记:ASCII,Unicode 和 UTF-8
python2报错:UnicodeEncodeError: ‘ascii’ codec can’t encode character -
ASCII码和非ASCII码
一开始计算机制造于国外,ASCII只能编码英文,对应的别的语言只能各自为政,非ASCII中最为典型的就是GB2312,专门用来编码简体中文的。 -
为了统一语言,出现了Unicode,这是个所有语言的编码的标准。但是标准归标准,具体存储的时候,实现在计算机里面的方式就五花八门,比如UTF-8就是一种。
- 所以 UTF-8 是隶属于Unicode的一种实现方式。
-
一些常见概念解析
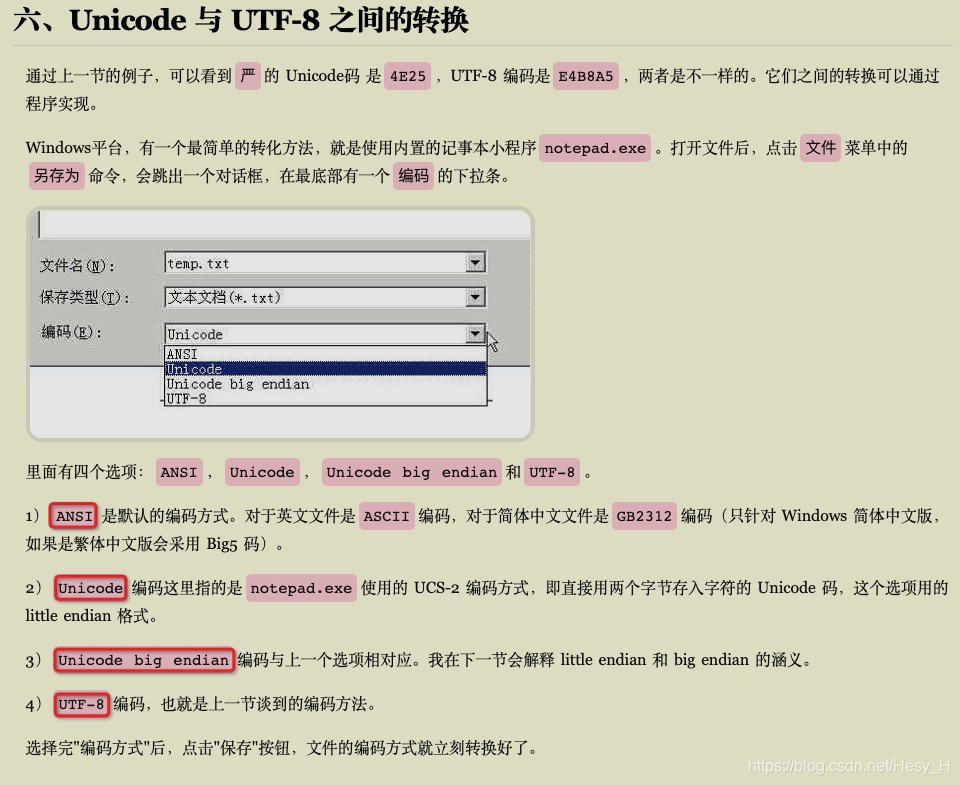
-
Python 认为 16 位的 unicode 才是字符的唯一内码,而大家常用的字符集如 gb2312,gb18030/gbk,utf-8,以及 ascii 都是字符的二进制(字节)编码形式。把字符从 unicode 转换成二进制编码,当然是要 encode。
hh,毕竟刚刚也说了,只有unicode才是集所有语言的大成者。
编码:ASCII,Unicode 和 UTF-8
猜你喜欢
转载自blog.csdn.net/Hesy_H/article/details/119486414
今日推荐
周排行