目录
Linux版本4.14 :。
kernel的整个启动过程涉及的内容很多,不可能每一个细节都描述清楚,因此我打算针对部分和ARM64相关的启动步骤进行学习、整理,并方便后续查阅。本文实际上描述在系统启动最开始的时候,bootloader和kernel的交互以及kernel如何保存bootloader传递的参数并进行校验,此外,还有一些最基础的硬件初始化的内容。
一、vmlinux.lds.S
文件arch\arm64\kernel\vmlinux.lds.S文件是kernel链接文件。
/* SPDX-License-Identifier: GPL-2.0 */
/*
* ld script to make ARM Linux kernel
* taken from the i386 version by Russell King
* Written by Martin Mares <[email protected]>
*/
....................
SECTIONS
{
/*
* XXX: The linker does not define how output sections are
* assigned to input sections when there are multiple statements
* matching the same input section name. There is no documented
* order of matching.
*/
/DISCARD/ : {
ARM_EXIT_DISCARD(EXIT_TEXT)
ARM_EXIT_DISCARD(EXIT_DATA)
EXIT_CALL
*(.discard)
*(.discard.*)
*(.interp .dynamic)
*(.dynsym .dynstr .hash .gnu.hash)
*(.eh_frame)
}
. = KIMAGE_VADDR + TEXT_OFFSET;
.head.text : {
_text = .;
HEAD_TEXT
}
.text : { /* Real text segment */
_stext = .; /* Text and read-only data */
__exception_text_start = .;
*(.exception.text)
__exception_text_end = .;
IRQENTRY_TEXT
SOFTIRQENTRY_TEXT
ENTRY_TEXT
TEXT_TEXT
SCHED_TEXT
CPUIDLE_TEXT
LOCK_TEXT
KPROBES_TEXT
HYPERVISOR_TEXT
IDMAP_TEXT
HIBERNATE_TEXT
TRAMP_TEXT
*(.fixup)
*(.gnu.warning)
. = ALIGN(16);
*(.got) /* Global offset table */
}
.................根据vmlinux.lds.S文件的描述,内核执行的第一行代码是sections .text 中的_stext,改函数在arch\arm64\kernel\head.S文件中。
二、head.S(进入kernel之前)
文件 arch\arm64\kernel\head.S文件是kernel 启动文件。
2.1 kernel之前bootloder的工作
我们知道,在进入内核之前,有一个bootloader的过程,其最大的作用莫过于准备好各方面的CPU外围芯片,尤其是RAM,其外,也要将我们的内核镜像解压至(可选)内存中使之运行。更具体地,bootloader所要完成的事情,至少要包含以下几点:
1、初始化系统中的RAM,并将RAM的相关信息传递给kernel,比如RAM的大小和分布。
2、准备好device tree blob,完成某些节点的解析,并将DTB首地址传递给内核。
3、解压内核。
4、移交控制权给内核。
2.1 bootloader和kernel的交互的时候需求
对于ARM64 Linux来说,依据ARM64 boot protocol,在内核运行前,bootloader需要保证以下的几个条件:
/*
* Kernel startup entry point.
* ---------------------------
*
* The requirements are:
* MMU = off, D-cache = off, I-cache = on or off,
* x0 = physical address to the FDT blob.
*
* This code is mostly position independent so you call this at
* __pa(PAGE_OFFSET + TEXT_OFFSET).
*
* Note that the callee-saved registers are used for storing variables
* that are useful before the MMU is enabled. The allocations are described
* in the entry routines.
*/也就是说,在刚进入kernel的时候,MMU,D-cache是关闭的,这也能很好的解释在实际项目中所遇到的,在bootloader完成某些数据读写/加载功能时,其速度远远不如在BSP中执行的时候。而对于PC处理器,bootloader执行相关功能实现的速度,明显比ARM中快,其MMU在CPU上电启动时默认开启了,大概是PC的bootloader不需要在开启MMU之后,又将其关闭吧?
这里需要对data cache和instruction cache多说几句。我们知道,具体实现中的ARMv8处理器的cache是形成若干个level,一般而言,可能L1是分成了data cache和instruction cache,而其他level的cache都是unified cache。上面定义的D-cache off并不是说仅仅disable L1的data cache,实际上是disable了各个level的data cache和unified cache。同理,对于instruction cache亦然。
此外,在on/off控制上,MMU和data cache是有一定关联的。在ARM64中,SCTLR, System Control Register用来控制MMU icache和dcache,虽然这几个控制bit是分开的,但是并不意味着MMU、data cache、instruction cache的on/off控制是彼此独立的。一般而言,这里MMU和data cache是绑定的,即如果MMU 是off的,那么data cache也必须要off。因为如果打开data cache,那么要设定memory type、sharebility attribute、cachebility attribute等,而这些信息是保存在页表(Translation table)的描述符中,因此,如果不打开MMU,如果没有页表翻译过程,那么根本不知道怎么来应用data cache。当然,是不是说HW根本不允许这样设定呢?也不是了,在MMU OFF而data cache是ON的时候,这时候,所有的memory type和attribute是固定的,即memory type都是normal Non-shareable的,对于inner cache和outer cache,其策略都是Write-Back,Read-Write Allocate的。
更详细的ARM64 boot protocol请参考Documentation/arm64/booting.txt文档。
2.3 内核执行的第一行代码(_stext)
根据vmlinux.lds.S文件的描述,内核执行的第一行代码是_stext,在问文件 arch\arm64\kernel\head.S中,即:
/*
* The following callee saved general purpose registers are used on the
* primary lowlevel boot path:
*
* Register Scope Purpose
* x21 stext() .. start_kernel() FDT pointer passed at boot in x0
* x23 stext() .. start_kernel() physical misalignment/KASLR offset
* x28 __create_page_tables() callee preserved temp register
* x19/x20 __primary_switch() callee preserved temp registers
*/
ENTRY(stext)
bl preserve_boot_args
bl el2_setup // Drop to EL1, w0=cpu_boot_mode
adrp x23, __PHYS_OFFSET
and x23, x23, MIN_KIMG_ALIGN - 1 // KASLR offset, defaults to 0
bl set_cpu_boot_mode_flag
bl __create_page_tables
/*
* The following calls CPU setup code, see arch/arm64/mm/proc.S for
* details.
* On return, the CPU will be ready for the MMU to be turned on and
* the TCR will have been set.
*/
bl __cpu_setup // initialise processor
b __primary_switch
ENDPROC(stext)这几个函数即为head.s的主要函数,依次执行,最后通过__primary_switch进入start_kernel函数开始C语言代码的执行。
在细致分析之前,首先要明确,整个以上函数的主要目的,或者说任务是什么?由前面可以得知,此时MMU和D-cache均是关闭状态的,I-cache的状态则是依据具体的bootloader而定,那么,答案就比较明确了,即开启MMU和cache。如何开启MMU?很简单,不过是往CPU的某个寄存器写1罢了。但是,在这之前,我们需要做好充分的准备工作,让内核代码,能够顺畅地、欢快地在MMU on/off切换前后执行,也就是我们需要建立-----内核内存映射表,或者说页表。当然,该页表应该不是完整意义上我们在内核启动后所使用的那个页表,事实上,在我们进入c语言代码,也就是start_kernel函数之后,我们会再次进行页表项的建立,那个时候所使用的才是真正完整的。
2.3.1 preserve_boot_args()
/*
* Preserve the arguments passed by the bootloader in x0 .. x3
*/
preserve_boot_args:
mov x21, x0 // x21=FDT(物理地址),将dtb的地址暂存在x21寄存器中,释放出x0以便后续做临时变量使用
adr_l x0, boot_args // record the contents of, x0保存了boot_args变量的地址
stp x21, x1, [x0] // x0 .. x3 at kernel entry,保存x0和x1的值到boot_args[0]和boot_args[1]
stp x2, x3, [x0, #16] // 保存x2和x3的值到boot_args[2]和boot_args[3]
dmb sy // needed before dc ivac with
// MMU off
mov x1, #0x20 // 4 x 8 bytes //x0和x1是传递给__inval_cache_range的参数
b __inval_dcache_area // tail call
ENDPROC(preserve_boot_args)
该函数很简单,凭注释也很容易读懂,由于bootloader把设备树的首地址赋值给了通用寄存器x0,因此,x21现在保存着FDT(物理地址),用于后面的调用,同时也将x0寄存器腾了出来,以便后面的代码可以将x0作为通用寄存器使用。随后,分别将x21,x1,x2,x3的值保存到boot_args标签所代表的地址空间中,并使用dmb sy设置指令屏障。随后,调用__inval_dcache_area将该片内存中的cache使无效。为什么这么做?在bootloader中,很有可能已经对该片内存执行过一些操作了,而bootloader是会开启cache的,因此,在各层级的cache中可能会包含无效的数据,因此,很有必要将其invalue掉。此时x0保存着boot_args的首地址,x1保存着boot_args的大小,作为__inval_dcache_area的参数使用。
此处直接黏贴大神的原话:为何要保存x0~x3这四个寄存器呢?因为ARM64 boot protocol对启动时候的x0~x3这四个寄存器有严格的限制:x0是dtb的物理地址,x1~x3必须是0(非零值是保留将来使用)。在后续setup_arch函数执行的时候会访问boot_args并进行校验。
对于invalidate cache的操作而言,我们可以追问几个问题:如果boot_args所在区域的首地址和尾部地址没有对齐到cache line怎么办?具体invalidate cache需要操作到那些level的的cache?这些问题可以通过阅读__inval_cache_range的代码获得答案,这里就不描述了。
还有一个小细节是如何访问boot_args这个符号的,这个符号是一个虚拟地址,但是,现在没有建立好页表,也没有打开MMU,如何访问它呢?这是通过adr_l这个宏来完成的。这个宏实际上是通过adrp这个汇编指令完成,通过该指令可以将符号地址变成运行时地址(通过PC relative offset形式),因此,当运行的MMU OFF mode下,通过adrp指令可以获取符号的物理地址。不过adrp是page对齐的(adrp中的p就是page的意思),boot_args这个符号当然不会是page size对齐的,因此不能直接使用adrp,而是使用adr_l这个宏进行处理,如果读者有兴趣可以自己看source code。
/*
* The recorded values of x0 .. x3 upon kernel entry.
*/
u64 __cacheline_aligned boot_args[4];解释一下adr_l这个宏,该宏的含义是将boot_args标签的物理地址赋值给了x0,即x0 = __pa(boot_args);adr_l宏最终会调用adrp指令,该指令的作用就是将符号地址变为运行时地址,由于此时MMU和cache都是关闭的,而boot_args的标签是虚拟地址(为什么是虚拟地址?事实上vmlinux.lds.S所定义的标签地址都是虚拟地址,因此这个时候,head.s里面的变量/标签所代表的均是虚拟地址),运行时地址,在目前的情况下也就是物理地址,因为MMU还没有打开。
在MMU没有打开的情况下,我们不能直接访问虚拟地址,需要adrp这个指令来获取标签的物理地址。而adrp指令是page对齐的,显然boot_args无法保证这一条件(事实上,它应当是cache_line对齐的),因此ard_l的作用就体现出来了,它并不需要page对齐。
至于dmb sy, ARM文档中,有关于数据访问指令和 data cache指令之间操作顺序的约定,原文如下:
/* All data cache instructions, other than DC ZVA, that specify an address can execute in any order relative to loads or stores that access any address with the Device memory attribute,or with Normal memory with Inner Non-cacheable attribute unless a DMB or DSB is executed between the instructions. */即,在Inner Non-cacheable 的情况下,所有的data cache instructions执行之前, 除了DC ZVA(cache zeros by Virtual Address. This zeros a block of memory within the cache)之外,都要先执行DMB或者DSB,来保证stp等数据加载指令已经执行完毕。因此,在Non-cacheable的情况下,必须要使用DMB来保证stp指令在dc ivac指令之前执行完成。
2.3.2 el2_setup
ARMv8中有exception level的概念,即EL0~EL3一共4个level。这个概念代替了以往的普通模式、特权模式的定义,也大致延续了ARMv7中的PL0、PL1、PL2的概念,各个level所代表的具体意义可以参见下图(盗图):
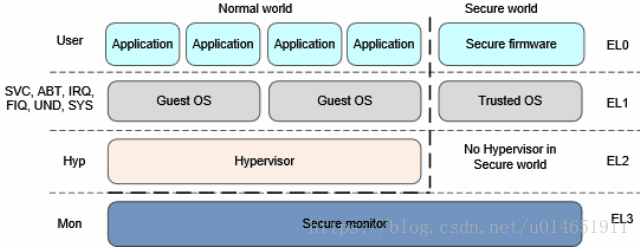
即用户态所使用的Application处于特权的最低等级EL0,内核OS的运行则处于EL1层级,EL2则被用于虚拟化的应用,提供Security支持的Seurity Monitor位于EL3。显然,当内核运行到当前时候时,处于EL1层级或者以上,该函数很长,由于还未接触到虚拟化相关的内容,就不全部分析了,留待以后需要的时候再研习。
/*
* If we're fortunate enough to boot at EL2, ensure that the world is
* sane before dropping to EL1.
*
* Returns either BOOT_CPU_MODE_EL1 or BOOT_CPU_MODE_EL2 in w0 if
* booted in EL1 or EL2 respectively.
*/
ENTRY(el2_setup)
msr SPsel, #1 // We want to use SP_EL{1,2}
mrs x0, CurrentEL
cmp x0, #CurrentEL_EL2
b.eq 1f
mov_q x0, (SCTLR_EL1_RES1 | ENDIAN_SET_EL1)
msr sctlr_el1, x0
mov w0, #BOOT_CPU_MODE_EL1 // This cpu booted in EL1
isb
ret
1: mov_q x0, (SCTLR_EL2_RES1 | ENDIAN_SET_EL2)
msr sctlr_el2, x0SPsel(,Stack Pointer Select)寄存器是aarch64 Special-purpose register中的一个,其作用的官方描述为Allow the Stack Pointer to be selected between SP_EL0 and SP_ELX.
currentEL,也是aarch64 Special-purpose register中的一个,可以通过它获取当前所处的exception level。

代码在这里判断当前是否是处于EL2,如果是,还需要进行一系列的寄存器配置,然后退回EL1,这里就不再研究了。如果当前处于EL1,则继续读取寄存器sctlr_el1的值,CPU_BE和CPU_LE只会执行其中的一句,为的是设置是大端模式还是小端模式,然后将值回写至sctlr_el1。最后,将当前的level保存到w0寄存器备用。
2.3.3 set_cpu_boot_mode_flag
/*
* Sets the __boot_cpu_mode flag depending on the CPU boot mode passed
* in w0. See arch/arm64/include/asm/virt.h for more info.
*/
set_cpu_boot_mode_flag:
adr_l x1, __boot_cpu_mode
cmp w0, #BOOT_CPU_MODE_EL2
b.ne 1f
add x1, x1, #4
1: str w0, [x1] // This CPU has booted in EL1
dmb sy
dc ivac, x1 // Invalidate potentially stale cache line
ret
ENDPROC(set_cpu_boot_mode_flag)在进入这个函数的时候,有一个前提条件:w20寄存器保存了cpu启动时候的Eexception level。
由于系统启动之后仍然需要了解cpu启动时候的Eexception level(例如判断是否启用hyp mode),因此,有一个全局变量__boot_cpu_mode用来保存启动时候的CPU mode。代码很简单,大家自行体会就OK了,我这里补充几点描述:
(1)本质上我们希望系统中所有的cpu在初始化的时候处于同样的mode,要么都是EL2,要么都是EL1,有些EL2,有些EL1是不被允许的(也许只有那些精神分裂的bootloader才会这么搞)。
(2)所有的cpu core在启动的时候都处于EL2 mode表示系统支持虚拟化,只有在这种情况下,kvm模块可以顺利启动。
(3)set_cpu_boot_mode_flag和el2_setup这两个函数会在各个cpu上执行。
(4)变量__boot_cpu_mode定义如下:
/*
* We need to find out the CPU boot mode long after boot, so we need to
* store it in a writable variable.
*
* This is not in .bss, because we set it sufficiently early that the boot-time
* zeroing of .bss would clobber it.
*/
ENTRY(__boot_cpu_mode)
.long BOOT_CPU_MODE_EL2 --------A
.long BOOT_CPU_MODE_EL1 --------B在前面的el2_setup函数中,我们已经把level的值保存在w0中了。
借用大神的描述:由于系统启动之后仍然需要了解cpu启动时候的Exception level(例如判断是否启用hyp mode),因此,有一个全局变量__boot_cpu_mode用来保存启动时候的CPU mode。
如果cpu启动的时候是EL1 mode,会修改变量__boot_cpu_mode A域,将其修改为BOOT_CPU_MODE_EL1。
如果cpu启动的时候是EL2 mode,会修改变量__boot_cpu_mode B域,将其修改为BOOT_CPU_MODE_EL2。
2.3.4 __create_page_tables
/*
* Setup the initial page tables. We only setup the barest amount which is
* required to get the kernel running. The following sections are required:
* - identity mapping to enable the MMU (low address, TTBR0)
* - first few MB of the kernel linear mapping to jump to once the MMU has
* been enabled
*/
__create_page_tables:
mov x28, lr
/*
* Invalidate the idmap and swapper page tables to avoid potential
* dirty cache lines being evicted.
*/
adrp x0, idmap_pg_dir
ldr x1, =(IDMAP_DIR_SIZE + SWAPPER_DIR_SIZE + RESERVED_TTBR0_SIZE)
bl __inval_dcache_area
/*
* Clear the idmap and swapper page tables.
*/
adrp x0, idmap_pg_dir
ldr x1, =(IDMAP_DIR_SIZE + SWAPPER_DIR_SIZE + RESERVED_TTBR0_SIZE)
1: stp xzr, xzr, [x0], #16
stp xzr, xzr, [x0], #16
stp xzr, xzr, [x0], #16
stp xzr, xzr, [x0], #16
subs x1, x1, #64
b.ne 1b
mov x7, SWAPPER_MM_MMUFLAGS
/*
* Create the identity mapping.
*/
adrp x0, idmap_pg_dir
adrp x3, __idmap_text_start // __pa(__idmap_text_start)
#ifndef CONFIG_ARM64_VA_BITS_48
#define EXTRA_SHIFT (PGDIR_SHIFT + PAGE_SHIFT - 3)
#define EXTRA_PTRS (1 << (48 - EXTRA_SHIFT))
/*
* If VA_BITS < 48, it may be too small to allow for an ID mapping to be
* created that covers system RAM if that is located sufficiently high
* in the physical address space. So for the ID map, use an extended
* virtual range in that case, by configuring an additional translation
* level.
* First, we have to verify our assumption that the current value of
* VA_BITS was chosen such that all translation levels are fully
* utilised, and that lowering T0SZ will always result in an additional
* translation level to be configured.
*/
#if VA_BITS != EXTRA_SHIFT
#error "Mismatch between VA_BITS and page size/number of translation levels"
#endif
/*
* Calculate the maximum allowed value for TCR_EL1.T0SZ so that the
* entire ID map region can be mapped. As T0SZ == (64 - #bits used),
* this number conveniently equals the number of leading zeroes in
* the physical address of __idmap_text_end.
*/
adrp x5, __idmap_text_end
clz x5, x5
cmp x5, TCR_T0SZ(VA_BITS) // default T0SZ small enough?
b.ge 1f // .. then skip additional level
adr_l x6, idmap_t0sz
str x5, [x6]
dmb sy
dc ivac, x6 // Invalidate potentially stale cache line
create_table_entry x0, x3, EXTRA_SHIFT, EXTRA_PTRS, x5, x6
1:
#endif
create_pgd_entry x0, x3, x5, x6
mov x5, x3 // __pa(__idmap_text_start)
adr_l x6, __idmap_text_end // __pa(__idmap_text_end)
create_block_map x0, x7, x3, x5, x6
/*
* Map the kernel image (starting with PHYS_OFFSET).
*/
adrp x0, swapper_pg_dir
mov_q x5, KIMAGE_VADDR + TEXT_OFFSET // compile time __va(_text)
add x5, x5, x23 // add KASLR displacement
create_pgd_entry x0, x5, x3, x6
adrp x6, _end // runtime __pa(_end)
adrp x3, _text // runtime __pa(_text)
sub x6, x6, x3 // _end - _text
add x6, x6, x5 // runtime __va(_end)
create_block_map x0, x7, x3, x5, x6
/*
* Since the page tables have been populated with non-cacheable
* accesses (MMU disabled), invalidate the idmap and swapper page
* tables again to remove any speculatively loaded cache lines.
*/
adrp x0, idmap_pg_dir
ldr x1, =(IDMAP_DIR_SIZE + SWAPPER_DIR_SIZE + RESERVED_TTBR0_SIZE)
dmb sy
bl __inval_dcache_area
ret x28
ENDPROC(__create_page_tables)2.3.5 __cpu_setup
arch\arm64\mm\proc.S
ARM64的启动过程之(三):为打开MMU而进行的CPU初始化
2.3.6 __primary_switch
__primary_switch:
#ifdef CONFIG_RANDOMIZE_BASE
mov x19, x0 // preserve new SCTLR_EL1 value
mrs x20, sctlr_el1 // preserve old SCTLR_EL1 value
#endif
bl __enable_mmu
#ifdef CONFIG_RELOCATABLE
bl __relocate_kernel
#ifdef CONFIG_RANDOMIZE_BASE
ldr x8, =__primary_switched
adrp x0, __PHYS_OFFSET
blr x8
/*
* If we return here, we have a KASLR displacement in x23 which we need
* to take into account by discarding the current kernel mapping and
* creating a new one.
*/
pre_disable_mmu_workaround
msr sctlr_el1, x20 // disable the MMU
isb
bl __create_page_tables // recreate kernel mapping
tlbi vmalle1 // Remove any stale TLB entries
dsb nsh
isb
msr sctlr_el1, x19 // re-enable the MMU
isb
ic iallu // flush instructions fetched
dsb nsh // via old mapping
isb
bl __relocate_kernel
#endif
#endif
ldr x8, =__primary_switched
adrp x0, __PHYS_OFFSET
br x8
ENDPROC(__primary_switch)2.3.6.1 __enable_mmu
/*
* Enable the MMU.
*
* x0 = SCTLR_EL1 value for turning on the MMU.
*
* Returns to the caller via x30/lr. This requires the caller to be covered
* by the .idmap.text section.
*
* Checks if the selected granule size is supported by the CPU.
* If it isn't, park the CPU
*/
ENTRY(__enable_mmu)
mrs x1, ID_AA64MMFR0_EL1
ubfx x2, x1, #ID_AA64MMFR0_TGRAN_SHIFT, 4
cmp x2, #ID_AA64MMFR0_TGRAN_SUPPORTED
b.ne __no_granule_support
update_early_cpu_boot_status 0, x1, x2
adrp x1, idmap_pg_dir
adrp x2, swapper_pg_dir
msr ttbr0_el1, x1 // load TTBR0
msr ttbr1_el1, x2 // load TTBR1
isb
msr sctlr_el1, x0
isb
/*
* Invalidate the local I-cache so that any instructions fetched
* speculatively from the PoC are discarded, since they may have
* been dynamically patched at the PoU.
*/
ic iallu
dsb nsh
isb
ret
ENDPROC(__enable_mmu)2.3.6.2 __primary_switched
/*
* The following fragment of code is executed with the MMU enabled.
*
* x0 = __PHYS_OFFSET
*/
__primary_switched:
adrp x4, init_thread_union
add sp, x4, #THREAD_SIZE
adr_l x5, init_task
msr sp_el0, x5 // Save thread_info
adr_l x8, vectors // load VBAR_EL1 with virtual
msr vbar_el1, x8 // vector table address
isb
stp xzr, x30, [sp, #-16]!
mov x29, sp
str_l x21, __fdt_pointer, x5 // Save FDT pointer
ldr_l x4, kimage_vaddr // Save the offset between
sub x4, x4, x0 // the kernel virtual and
str_l x4, kimage_voffset, x5 // physical mappings
// Clear BSS
adr_l x0, __bss_start
mov x1, xzr
adr_l x2, __bss_stop
sub x2, x2, x0
bl __pi_memset
dsb ishst // Make zero page visible to PTW
#ifdef CONFIG_KASAN
bl kasan_early_init
#endif
#ifdef CONFIG_RANDOMIZE_BASE
tst x23, ~(MIN_KIMG_ALIGN - 1) // already running randomized?
b.ne 0f
mov x0, x21 // pass FDT address in x0
bl kaslr_early_init // parse FDT for KASLR options
cbz x0, 0f // KASLR disabled? just proceed
orr x23, x23, x0 // record KASLR offset
ldp x29, x30, [sp], #16 // we must enable KASLR, return
ret // to __primary_switch()
0:
#endif
add sp, sp, #16
mov x29, #0
mov x30, #0
b start_kernel
ENDPROC(__primary_switched)三、main.c(start_kernel)
文件 init\main.c
asmlinkage __visible void __init start_kernel(void)
{
char *command_line;
char *after_dashes;
set_task_stack_end_magic(&init_task);
smp_setup_processor_id();
debug_objects_early_init();
cgroup_init_early();
local_irq_disable();
early_boot_irqs_disabled = true;
/*
* Interrupts are still disabled. Do necessary setups, then
* enable them.
*/
boot_cpu_init();
page_address_init();
pr_notice("%s", linux_banner);
setup_arch(&command_line);
/*
* Set up the the initial canary and entropy after arch
* and after adding latent and command line entropy.
*/
add_latent_entropy();
add_device_randomness(command_line, strlen(command_line));
boot_init_stack_canary();
mm_init_cpumask(&init_mm);
setup_command_line(command_line);
setup_nr_cpu_ids();
setup_per_cpu_areas();
smp_prepare_boot_cpu(); /* arch-specific boot-cpu hooks */
boot_cpu_hotplug_init();
build_all_zonelists(NULL);
page_alloc_init();
pr_notice("Kernel command line: %s\n", boot_command_line);
/* parameters may set static keys */
jump_label_init();
parse_early_param();
after_dashes = parse_args("Booting kernel",
static_command_line, __start___param,
__stop___param - __start___param,
-1, -1, NULL, &unknown_bootoption);
if (!IS_ERR_OR_NULL(after_dashes))
parse_args("Setting init args", after_dashes, NULL, 0, -1, -1,
NULL, set_init_arg);
/*
* These use large bootmem allocations and must precede
* kmem_cache_init()
*/
setup_log_buf(0);
pidhash_init();
vfs_caches_init_early();
sort_main_extable();
trap_init();
mm_init();
ftrace_init();
/* trace_printk can be enabled here */
early_trace_init();
/*
* Set up the scheduler prior starting any interrupts (such as the
* timer interrupt). Full topology setup happens at smp_init()
* time - but meanwhile we still have a functioning scheduler.
*/
sched_init();
/*
* Disable preemption - early bootup scheduling is extremely
* fragile until we cpu_idle() for the first time.
*/
preempt_disable();
if (WARN(!irqs_disabled(),
"Interrupts were enabled *very* early, fixing it\n"))
local_irq_disable();
radix_tree_init();
/*
* Allow workqueue creation and work item queueing/cancelling
* early. Work item execution depends on kthreads and starts after
* workqueue_init().
*/
workqueue_init_early();
rcu_init();
/* Trace events are available after this */
trace_init();
context_tracking_init();
/* init some links before init_ISA_irqs() */
early_irq_init();
init_IRQ();
tick_init();
rcu_init_nohz();
init_timers();
hrtimers_init();
softirq_init();
timekeeping_init();
time_init();
sched_clock_postinit();
printk_safe_init();
perf_event_init();
profile_init();
call_function_init();
WARN(!irqs_disabled(), "Interrupts were enabled early\n");
early_boot_irqs_disabled = false;
local_irq_enable();
kmem_cache_init_late();
/*
* HACK ALERT! This is early. We're enabling the console before
* we've done PCI setups etc, and console_init() must be aware of
* this. But we do want output early, in case something goes wrong.
*/
console_init();
if (panic_later)
panic("Too many boot %s vars at `%s'", panic_later,
panic_param);
lockdep_info();
/*
* Need to run this when irqs are enabled, because it wants
* to self-test [hard/soft]-irqs on/off lock inversion bugs
* too:
*/
locking_selftest();
/*
* This needs to be called before any devices perform DMA
* operations that might use the SWIOTLB bounce buffers. It will
* mark the bounce buffers as decrypted so that their usage will
* not cause "plain-text" data to be decrypted when accessed.
*/
mem_encrypt_init();
#ifdef CONFIG_BLK_DEV_INITRD
if (initrd_start && !initrd_below_start_ok &&
page_to_pfn(virt_to_page((void *)initrd_start)) < min_low_pfn) {
pr_crit("initrd overwritten (0x%08lx < 0x%08lx) - disabling it.\n",
page_to_pfn(virt_to_page((void *)initrd_start)),
min_low_pfn);
initrd_start = 0;
}
#endif
kmemleak_init();
debug_objects_mem_init();
setup_per_cpu_pageset();
numa_policy_init();
if (late_time_init)
late_time_init();
calibrate_delay();
pidmap_init();
anon_vma_init();
acpi_early_init();
#ifdef CONFIG_X86
if (efi_enabled(EFI_RUNTIME_SERVICES))
efi_enter_virtual_mode();
#endif
thread_stack_cache_init();
cred_init();
fork_init();
proc_caches_init();
buffer_init();
key_init();
security_init();
dbg_late_init();
vfs_caches_init();
pagecache_init();
signals_init();
proc_root_init();
nsfs_init();
cpuset_init();
cgroup_init();
taskstats_init_early();
delayacct_init();
check_bugs();
acpi_subsystem_init();
arch_post_acpi_subsys_init();
sfi_init_late();
if (efi_enabled(EFI_RUNTIME_SERVICES)) {
efi_free_boot_services();
}
/* Do the rest non-__init'ed, we're now alive */
rest_init();
prevent_tail_call_optimization();
}
Linux内核4.14版本:ARM64的内核启动过程——start_kernel_yangguoyu8023的博客-CSDN博客