目录
一、DMA基本概念
DMA英文全称是Direct Memory Access,意思是直接存储器访问。他的作用就是不需要经过CPU进行数据传输,也就是替CPU分担点事情做,什么事情?数据传输方面的事情。也就是说,你只要使能并配置好了DMA,DMA就可以将一批数据从源地址搬运到目的地址去而不经过CPU的干预,这样可以为CPU节省好多精力去干更重要的事情很人性化。就像我们人一样,我们平常习惯性的动作是不用经过大脑思考的,比如说眨眼睛,呼吸等。DMA就是负责这些工作的,但它没人这么智能,需要将它设置好了它才会正常工作。
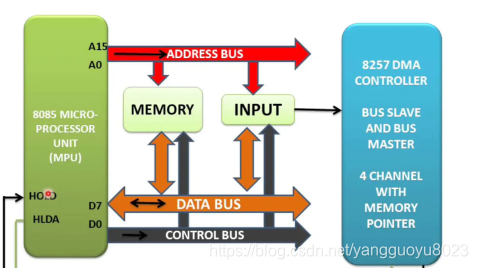
要进行数据传输就必须有两个条件:数据从哪传(源地址),数据传到哪里去(目的地址)。是的,DMA的确有这两项设置,通过软件设置,设置好源地址和目的地址。还有一个重要的条件就是触发源是什么,就是说什么时候进行DMA数据传输呢?这叫触发信号。也可以通过软件编程设置具体时间,具体条件来触发DMA数据传输。
二、DMA burst 基本概念
DMA和burst不是一个概念。
DMA传送不经过CPU的控制,假如硬盘的数据不能经过DMA控制器读到内存,那么每完成一次将硬盘的数据读出来,再存放到内存的操作,都要通过CPU运行几条读写指令来完成,这时CPU就做不了别的事了,如果有DMA控制器,则这个过程不需要CPU的参与,只需要占用总线就可以了。CPU还可以去完成别的运算。
Burst操作还是要通过CPU的参与的,与单独的一次读写操作相比,burst只需要提供一个其实地址就行了,以后的地址依次加1,而非burst操作每次都要给出地址,以及需要中间的一些应答、等待状态等等。如果是对地址连续的读取,burst效率高得多,但如果地址是跳跃的,则无法采用burst操作。
一般芯片的dma有基本功能:
1、普通的内存、外设间互传数据,一次性的。
2、支持链表的,美其名曰“scatter”,内核有struct scatter可以参考。
dma有burst、burst size、transfer的概念:
burst:
dma实际上是一次一次的申请总线,把要传的数据总量分成一个一个小的数据块。比如要传64个字节,那么dma内部可能分为2次,一次传64/2=32个字节,这个2(a)次呢,就叫做burst。这个burst是可以设置的。这32个字节又可以分为32位 *8或者16位*16来传输。
transfer size:
就是数据宽度,比如8位、32位,一般跟外设的FIFO相同。
burst size:
就是一次传几个 transfer size.
配置数据宽度为32位。一次传8个32位=32个字节。那么如果总长度为128字节,那么实际dma设置的长度为 128/32 = 4.
三、DMA缓存cache一致性原则
3.1 先理解cache的作用
CPU在访问内存时,首先判断所要访问的内容是否在Cache中,如果在,就称为“命中(hit)”,此时CPU直接从Cache中调用该内容;否则,就 称为“ 不命中”,CPU只好去内存中调用所需的子程序或指令了。CPU不但可以直接从Cache中读出内容,也可以直接往其中写入内容。由于Cache的存取速 率相当快,使得CPU的利用率大大提高,进而使整个系统的性能得以提升。
3.2 Cache的一致性
Cache的一致性就是Cache中的数据,与对应的内存中的数据是一致的。
DMA是直接操作总线地址的,这里先当作物理地址来看待吧(系统总线地址和物理地址只是观察内存的角度不同)。如果cache缓存的内存区域不包括DMA分配到的区域,那么就没有一致性的问题。但是如果cache缓存包括了DMA目的地址的话,会出现什么什么问题呢?
问题出在,经过DMA操作,cache缓存对应的内存数据已经被修改了,而CPU本身不知道(DMA传输是不通过CPU的),它仍然认为cache中的数 据就是内存中的数据,以后访问Cache映射的内存时,它仍然使用旧的Cache数据。这样就发生Cache与内存的数据“不一致性”错误。
题外话:好像2.6.29内核中,6410的总线地址和物理地址是一样的,因为我在查看vir_to_bus函数的时候,发现在/arch/arm/linux/asm/memory.h中这样定义:
#ifndef __virt_to_bus
#define __virt_to_bus __virt_to_phys
#define __bus_to_virt __phys_to_virt
#endif 而且用source Insight搜索了一遍,没有发现6410相关的代码中,重新定义__vit_to_bus,因此擅自认为2.6内核中,6410的总线地址就是物理地址。希望高手指点。
顺便提一下,总线地址是从设备角度上看到的内存,物理地址是CPU的角度看到的未经过转换的内存(经过转换的是虚拟地址)
由上面可以看出,DMA如果使用cache,那么一定要考虑cache的一致性。解决DMA导致的一致性的方法最简单的就是禁止DMA目标地址范围内的cache功能。但是这样就会牺牲性能。
因此在DMA是否使用cache的问题上,可以根据DMA缓冲区期望保留的的时间长短来决策。DAM的映射就分为:一致性DMA映射和流式DMA映射。
3.3 一致性DMA映射和流式DMA映射
一致性DMA映射申请的缓存区能够使用cache,并且保持cache一致性。一致性映射具有很长的生命周期,在这段时间内占用的映射寄存器,即使不使用也不会释放。生命周期为该驱动的生命周期
流式DMA映射实现比较复杂,因为没具体了解,就不说明了。只知道种方式的生命周期比较短,而且禁用cache。一些硬件对流式映射有优化。建立流式DMA映射,需要告诉内核数据的流动方向。
四、链表传输
一种Scatter-GatherDMA的数据传输缓冲区设计方法与流程
五、参考文章
DMA设备驱动(二)————dma和cache一致性(dma_malloc_writecombine)
DMA设备驱动(三)————基于Linux3.4.2的dma设备驱动的简单实现