目录
4.未指定字段条件查询:query_string,含AND与OR条件
5.指定字段条件查询:query_string,含AND与OR条件
八、手工控制搜索结果精准度:minimum_should_match
一、es基本操作
1.索引基本操作
(1)创建索引
PUT /索引名称(2)查询索引
GET /索引名称(3)删除索引
DELETE /索引名称2.文档基本操作
(1)添加文档
PUT /索引名称/类型/id(2)修改文档
PUT /索引名称/类型/id(3)查询文档
GET /索引名称/类型/id(4)删除文档
DELETE /索引名称/类型/id3.查询操作
(1)查询所有信息
GET /索引名称/类型/_search(2)精确匹配:age = 11
GET /索引名称/类型/_search?q=age:11(3)范围查询:age 在25到30之间
#这里的TO必须是大写,FROM A TO B的TO
GET /索引名称/类型/_search?q=age[25 TO 30](4)根据多个ID批量查询:in
GET /索引名称/类型/_mget
{
"ids":["1","2"]
}(5)>=和<=
GET /索引名称/类型/_search?q=age:>=11
GET /索引名称/类型/_search?q=age:<=11(6)分页查询
from=A&size=B类似于sql里的 limit A ,B
GET /索引名称/类型/_search?q=age[25 TO 30]&from=0&size=1(7)对查询结果只输出某些字段
类似于select A,B from table
GET /索引名称/类型/_search?_source=字段A,字段B(8)对查询结果排序
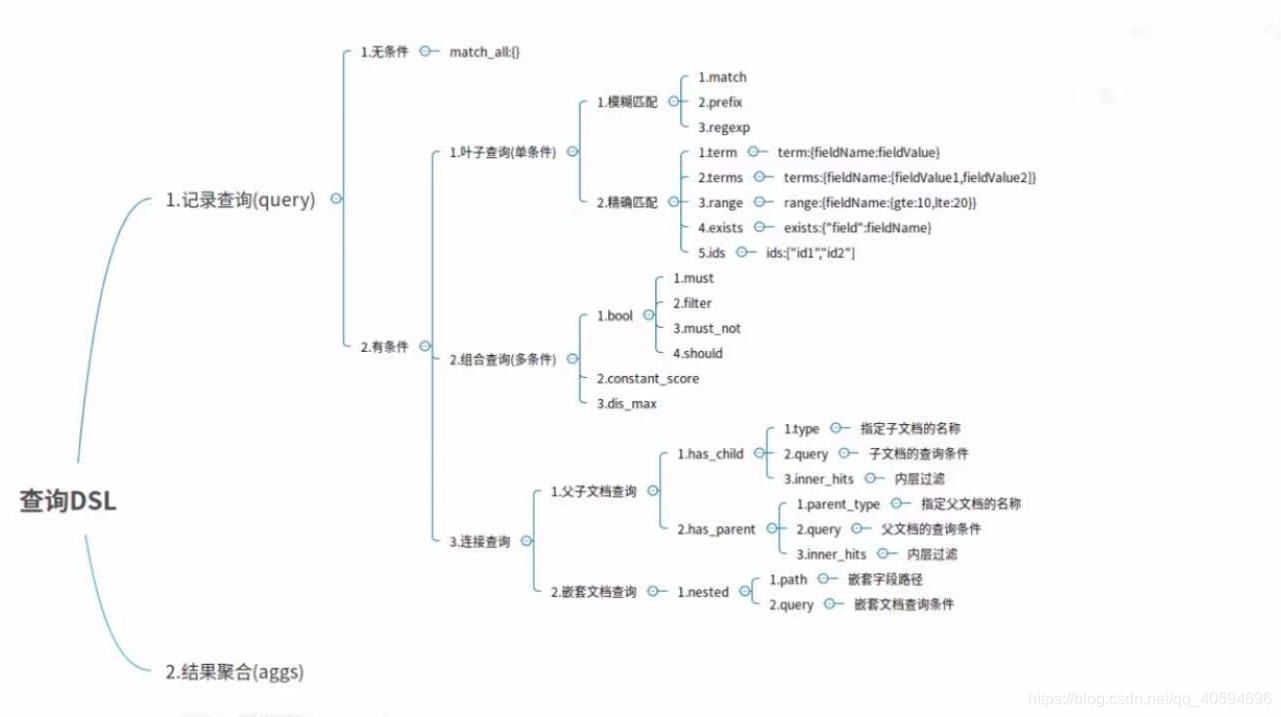
GET /索引名称/类型/_search?sort=字段:desc二、DSL语言高级查询基础
ES提供了强大的查询语言(DSL),允许我们基于JSON进行更加强大复杂的查询。DSL有叶子查询子句和复合查询子句两种。
DSL中有Query和Filter两种。
三、DSL之Query查询
Query查询会在es中索引的数据都会存储一个_score分值,分值越高就代表越匹配。另外关于某个搜索的分值计算是很复杂的,因此需要一定的时间
1.无条件查询:match_all: {}
我们刚打开kibana,其实就默认进行了一次无条件查询
2.有条件查询
(1)叶子条件查询(单字段查询条件)
*1)模糊匹配
模糊查询主要是针对文本类型的字段,文本类型的字段会对内容进行分词。查询时也会对搜索条件进行分词,然后通过倒排索引查找到匹配的数据,模糊匹配主要通过match等参数来实现。
- match:通过match关键词模糊匹配条件内容
- prefix:前缀匹配
- regexp:通过正则表达式来匹配数据
match的复杂用法:
match条件支持以下参数:
- query:指定匹配的值
- operator:匹配条件类型
- and:条件分词后都要匹配
- or:条件分词后有一个匹配即可(默认)
- minmum_should_match:指定最小匹配的数量
*2)精确匹配
- term:单个条件相等
- terms:单个字段属于某个值数组内的值
- range:字段属于某个范围内的值
- exists:某个字段的值是否存在
- ids:通过ID批量查询
(2)组合条件查询(多条件查询)
组合条件查询是将叶子条件查询语句进行组合而形成的一个完整的查询条件
- bool:各条件之间有and、or、not的关系
- must:各个条件都必须满足,即各条件是and的关系
- should:各个条件有一个满足即可,即各条件是or的关系
- must_not:不满足所有条件,即各条件是not关系
- filter:不计算相关度评分_score,效率更高
- constant_score:不计算相关度评分
must/should/must_not/filter的子条件是通过term/terms/range/exists/ids/match等叶子条件为参数的
注:以上参数,当只有一个搜索条件时,must等对应的是一个对象,当时多个条件时,对应的是一个数组
(3)连接查询(多文档合并查询)
- 父子文档查询:parent/child
- 嵌套文档查询:nested
四、DSL之Filter查询
过滤上下文是在使用filter参数时候的执行环境,比如在bool查询中使用must_not或者filter。
另外,经常使用过滤器,es会自动的缓存过滤器的内容,这对于查询来说会提高很多性能。
五、基本查询实例
用作真正开发时候的参考。
先新增几条数据:
PUT /es_db/_doc/user1
{
"name":"xupeng",
"age":18,
"profession":"程序员"
}
1.term精确查询
类似于sql里的name=aaa
如果name是英文可以精确查询,但是如果是中文就不行了,没弄明白(无语子)
#根据名称精确查询姓名:term。term查询不会对字段进行分词查询,会采用精确匹配
#注意:采用term精确查询,查询字段映射类型属于keyword
POST /es_db/_doc/_search
{
"query":{
"term":{
"name":"xupeng02"
}
}
}2.match模糊查询
类似于sql里的city like '%aaa%',其中from,size类似于limit m,n
#模糊查询,match会根据该字段的分词器,进行分词查询
POST /es_db/_doc/_search
{
"from":0,
"size":2,
"query":{
"match":{
"city":"上"
}
}
}3.多字段模糊匹配查询:multi_match
name like '%xupeng%' or city like '%xupeng%'
POST /es_db/_doc/_search
{
"query":{
"multi_match":{
"query":"xupeng",
"fields":["city","name"]
}
}
}4.未指定字段条件查询:query_string,含AND与OR条件
一般来说默认是OR,即写不写OR查到的都一样,但是设置了AND查到的就不一样了
POST /es_db/_doc/_search
{
"query":{
"query_string":{
"query":"医生 OR 上海"
}
}
}5.指定字段条件查询:query_string,含AND与OR条件
POST /es_db/_doc/_search
{
"query":{
"query_string":{
"query":"医生 AND 上海",
"fields":["city","profession"]
}
}
}6.范围查询
注:json请求字符串中部分字段的含义
range:范围关键字
gte:大于等于
lte:小于等于
gt:大于
lt:小于
now:当前时间
POST /es_db/_doc/_search
{
"query":{
"range":{
"age":{
"gte":15,
"lte":28
}
}
}
}7.总结
1.match:模糊匹配,需要指定字段名,但是输入会进行分词。只要包含了分词的一部分就会都查出来
2.term:不会进行分词的去匹配。而es在很多时候会将数据分词保存,因此term查询时很多时候是去查询分词器识别的词汇
3.match_phase:会对输入做分词,但是需要结果中也包含所有分词,且顺序一致
4.query_string:和match基本一致,但是match需要指定字段名,query_string可以在所有字段中查询
六、文档映射
1.动态映射和静态映射
动态映射:在写入es时,跟你局文档字段自动识别类型
静态映射:事先定义好映射,包含文档的各个字段类型,分词器等
2.动态映射
动态映射不是非常严谨,毕竟自动识别类型。
#获取文档映射关系
GET /es_db/_mapping3.静态映射
PUT /es_db2
{
"mappings": {
"properties": {
"name": {
"type": "keyword",
"index": true,
"store": true
},
"sex": {
"type": "integer",
"index": true,
"store": true
},
"age": {
"type": "integer",
"index": true,
"store": true
},
"book": {
"type": "text",
"index": true,
"store": true
},
#自定义分词器
"address": {
"type": "text",
"index": true,
"store": true,
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
}
}
}(1)text和keyword有什么区别
这两个都代表字符串类型,keyword不会被分词器拆分(name),text会被拆分(address).
text不能排序和聚合
term和keyword匹配;match和text匹配
(2)index和store的含义
我们知道es采用倒排索引,每个单词对应一个索引,如果index设置成true,那么我们会给这个单词设置倒排索引以作保存。(对于需要检索的信息我们需要设置index)
倒排索引中我们只是保存了索引,其实每个索引在正排索引中都有一个对应的中文,那么这个正排索引的中文是否需要保存维护,就由store确定。(对于需要显示原文的信息我们需要设置store)
4.核心类型
字符串:text和keyword
数值型:long,integer,short,byte,double,float
日期型:date
布尔型:boolean
5.对已存在的mapping映射进行修改
思路:
新建一个静态索引,将之前索引里的数据导入到新索引,删除原来的索引,为新索引起别名改成原索引名
平滑过渡,0停机操作如下:
PUT /es_db2/_doc/user1
{
"name":"aa",
"sex":1,
"age":11,
"book":"bb",
"address":"cc"
}
POST _reindex
{
"source": {
"index": "es_db2"
},
"dest": {
"index": "es_db3"
}
}
DELETE /es_db2
PUT /es_db3/_alias/es_db2
GET /es_db2七、高亮
PUT /news_website
{
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word"
},
"content":{
"type": "text",
"analyzer": "ik_max_word"
}
}
},
"settings": {
"index":{
"analysis.analyzer.default.type":"ik_max_word"
}
}
}
PUT /news_website/_doc/1
{
"title":"这是第一篇文章",
"content":"大家好,这是我的第一篇文章"
}
#如果高亮啥都不设置,会默认在查询的分词两边加上<em></em>标签
GET /news_website/_doc/_search
{
"query":{
"match":{
"title":"文章"
}
},
"highlight":{
"fields":{
"title":{}
}
}
}
#如果高亮啥都不设置,会默认在查询的分词两边加上<em></em>标签
GET /news_website/_doc/_search
{
"query":{
"bool":{
"should":[
{
"match":{
"title":"文章"
}
},
{
"match":{
"content":"文章"
}
}
]
}
},
"highlight":{
"fields":{
"title":{},
"content":{}
}
}
}
八、手工控制搜索结果精准度:minimum_should_match
先来创建 一些数据:
PUT /es_db/_doc/1
{
"name":"张三",
"sex":1,
"age":25,
"address":"陆家嘴",
"remark":"java developer"
}
PUT /es_db/_doc/2
{
"name":"李四",
"sex":1,
"age":28,
"address":"东方明珠",
"remark":"python developer worker"
}
PUT /es_db/_doc/3
{
"name":"王五",
"sex":0,
"age":38,
"address":"城隍庙",
"remark":"php developer"
}
PUT /es_db/_doc/4
{
"name":"王二",
"sex":0,
"age":76,
"address":"soho",
"remark":"linux worker"
}
PUT /es_db/_doc/5
{
"name":"赵六",
"sex":0,
"age":88,
"address":"迪士尼",
"remark":".net developer worker"
}自定义设置查询结果精确值:
#以单词做分词,只要有一个命中就会查询出来,相当于or
GET /es_db/_search
{
"query": {
"match": {
"remark": "java python"
}
}
}
#两个单词被分词后,必须两个都命中才会被查询出来,因为有and。
#如果是or,其实就和上面一样了
GET /es_db/_search
{
"query": {
"match": {
"remark": {
"query": "java developer",
"operator": "and"
}
}
}
}
#在真实查询中,我们不可能全都命中,也不可能只要有一个命中就查询
#我们希望至少命中一定比例,就给他查询出来
GET /es_db/_search
{
"query": {
"match": {
"remark": {
"query": "java developer",
"minimum_should_match": "60%"
}
}
}
}
#有时候按照比例并不靠谱,我们按照命中个数往往更准确
GET /es_db/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"remark": "java"
}},
{
"match": {
"remark": "developer"
}},
{
"match": {
"remark": "worker"
}}
],
"minimum_should_match": 2
}
}
}
九、boost权重控制:boost
#有时候按照比例并不靠谱,我们按照命中个数往往更准确
GET /es_db/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"remark": {
"query": "python",
"boost": 2
}
}},
{
"match": {
"remark": {
"query": ".net",
"boost": 3
}
}},
{
"match": {
"remark": "developer"
}},
{
"match": {
"remark": "worker"
}}
],
"minimum_should_match": 2
}
}
}十、短语搜索:match_phrase
1.搜索条件不分词
GET /es_db/_search
{
"query": {
"match_phrase": {
"remark": "developer worker"
}
}
}2.match_phrase的实现原理
我们先执行:
GET _analyze
{
"text": "developer worker",
"analyzer": "standard"
}可以得到对应结果:
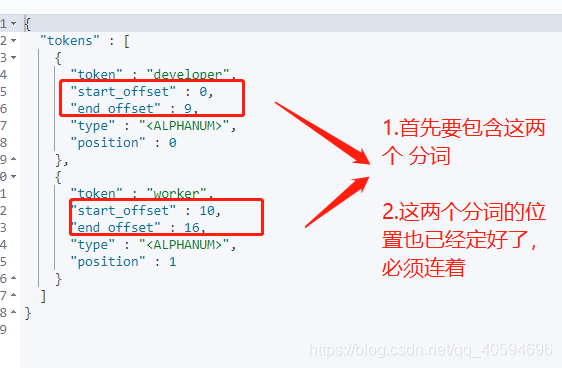
十一、近似匹配
先准备一下数据:
POST /test_a/_doc/3
{
"f":"hello,java is very good,python is also very good"
}
POST /test_a/_doc/4
{
"f":"java and python ,development language"
}
POST /test_a/_doc/5
{
"f":"java python is a fast and good language"
}
POST /test_a/_doc/6
{
"f":"java python and ,development language"
}1.前缀搜索
使用前缀匹配实现搜索能力,通常针对keyword类型字段,也就是不分词的字段
GET _search
{
"query": {
"prefix": {
"f.keyword": "ja"
}
}
}2.通配符搜索
?:一个任意字符
*:0-n个任意字符
效率很低,不建议.
GET _search
{
"query": {
"wildcard": {
"f.keyword": {
"value": "?av*"
}
}
}
}3.推荐搜索
以java开头,第二个以a开头的会推荐。
如果加了slop,a在偏移10个位置以为的都会被推荐
GET _search
{
"query": {
"match_phrase_prefix": {
"f": {
"query": "java a",
"slop": 10
}
}
}
}4.模糊查询
fuzziness:2,就算有2个字母写的不对也可以查出来
GET _search
{
"query": {
"fuzzy": {
"f": {
"value": "development",
"fuzziness": 2
}
}
}
}十二、打赏请求
如果本篇博客对您有所帮助,打赏一点呗,谢谢了呢~
