原理回归
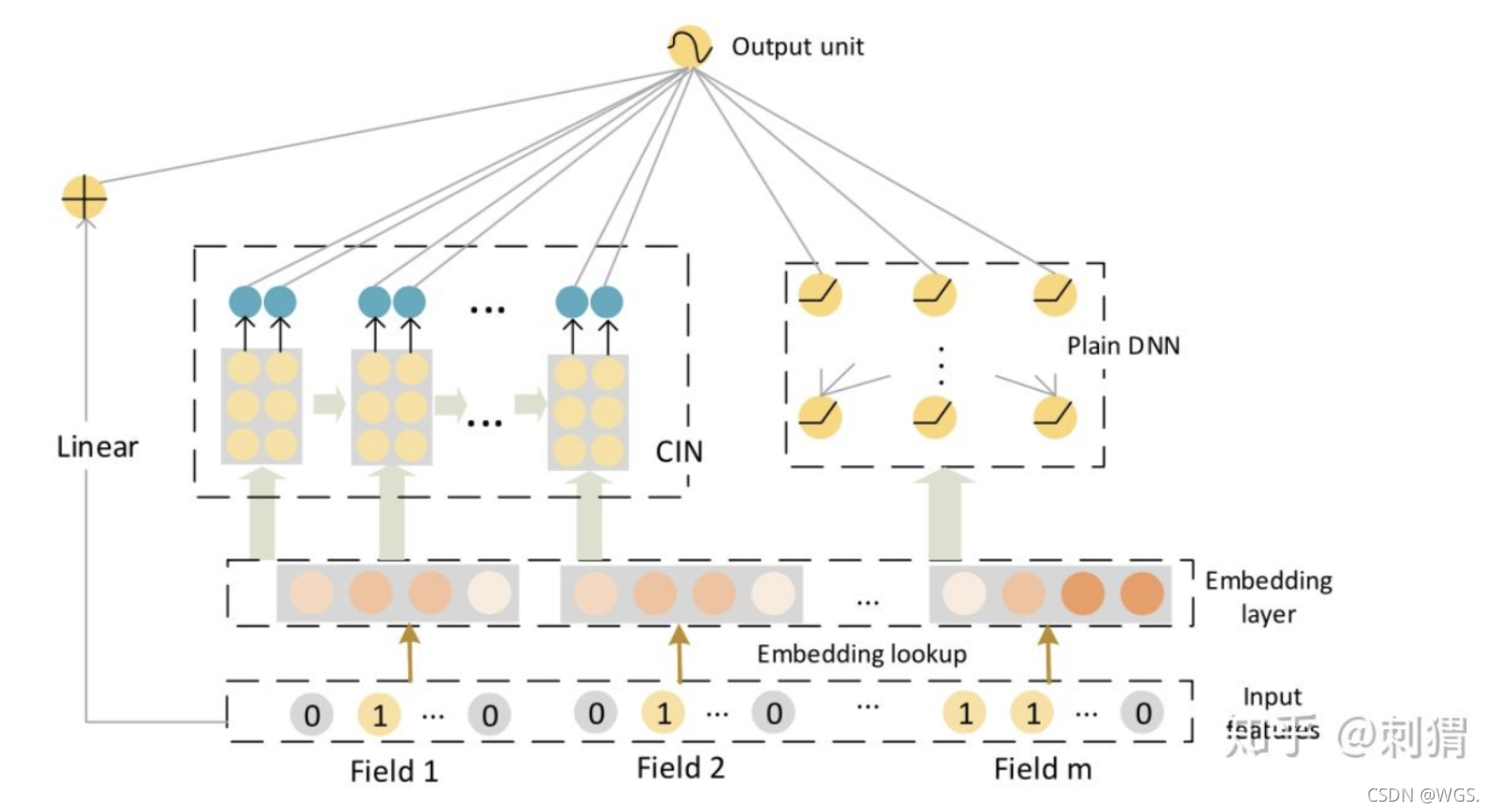
xDeepFM的架构从大致的体系来看, 包括五大部分(可参照deepFM):
-
对原始 特征的Field形式包装,把 特征one-hot形式 包装进同一field来克服 稀疏性, 这里就对应包括构建特征字典 和 特征索引矩阵、特征值矩阵分解的问题。
-
在embeding层对 样本做embeding转换,embeding其实相当于是 全连接层,进行embedding 按照 deepFM相似的形式 来获取每个样本长度为 field_size的 embedding表示,这样embedding后的样本矩阵应该为(field_size,embedding_size)。
-
linear:
- 简单的一阶计算部分,这部分并没有使用到 特征embedding的结果,而是w*x那种类似LR的一阶计算
-
CIN:
- CIN模型(压缩交互网络)架构进行可控的 自动学习显式的高阶特征交互,这里说显式是因为其 传递了 deep & cross 思想 可以通过层数控制 进行学习的最高阶数,这种可控的能表示成 wij * (xi * xj)形式的就成为显式。 同时也是可以特征向量级的交互,对于 向量级 和 显式的理解可参看 注1. 关于CIN的结构接下来会详细的介绍,其是一种非常巧妙的结合 CNN+RNN思想的架构。
-
DNN:
- 最后是很常见的 DNN部分的结构,会对经过embedding转换后的 样本特征进行 隐式的高阶 特征交互,这算是经常用到的模型结构,类同于deepFM、wide&deep中的使用。
-
集成的CIN和DNN两个模块能够帮助模型同时以显式和隐式的方式学习高阶的特征交互,而集成的线性模块和深度神经模块也让模型兼具记忆与泛化的学习能力。
deepctr实现xDeepFM
import os, warnings, time, sys
import pickle
import matplotlib.pyplot as plt
import pandas as pd, numpy as np
from sklearn.utils import shuffle
from sklearn.metrics import f1_score, accuracy_score, roc_curve, precision_score, recall_score, roc_auc_score
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, MinMaxScaler, OneHotEncoder
from deepctr.models import DeepFM, xDeepFM, MLR, DeepFEFM, DIN, AFM
from deepctr.feature_column import SparseFeat, DenseFeat, get_feature_names
from deepctr.layers import custom_objects
from tensorflow.python.keras.models import save_model, load_model
from tensorflow.keras.models import model_from_yaml
import tensorflow as tf
from tensorflow.python.ops import array_ops
import tensorflow.keras.backend as K
from sklearn import datasets
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import to_categorical
from keras.models import model_from_json
from tensorflow.keras.callbacks import *
from tensorflow.keras.models import *
from tensorflow.keras.layers import *
from tensorflow.keras.optimizers import *
from keras.preprocessing.sequence import pad_sequences
from keras.preprocessing.text import one_hot
from keras.layers.embeddings import Embedding
from toolsnn import *
def train_xDeepFM():
print('xDeepFM 模型训练开始 ', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())))
start_time_start = time.time()
pdtrain = pd.read_csv(train_path)
pdtest = pd.read_csv(test_path)
data = pd.concat([pdtrain, pdtest[pdtest['y'] == 0]], axis=0, ignore_index=True)
data = data.drop(['suuid', 'WilsonClickRate_all', 'WilsonClickRate_yesterday', 'WilsonAd_clickRate_all',
'WilsonAd_clickRate_yesterday'], axis=1)
data = shuffle(data)
# double -> float
data = transformDF(data, ['reserve_price', 'reserve_price_cpc', 'clickRate_all', 'clickRate_yesterday',
'ad_clickRate_yesterday'], float)
''' 特征处理 '''
global sparsecols, densecols
# 稀疏-onehot
sparsecols = ['hour', 'advert_place', 'province_id', 'port_type', 'user_osID', 'is_holidays', 'is_being',
'is_outflow',
'advertiser', 'ad_from', 'payment']
# 稠密-归一化
densecols = ['W', 'H', 'reserve_price', 'reserve_price_cpc', 'is_rest_click', 'clickPerHour_yesterday',
'display_nums_all', 'click_nums_all', 'display_nums_yesterday', 'click_nums_yesterday',
'ad_display_all', 'ad_click_all', 'ad_display_yesterday', 'ad_click_yesterday']
# 稠密-word2vec的embedding
idEmbeddingcols = ['userVector', 'adVector', 'modelVector', 'positionVector']
# 稠密-点击率
ratecols = ['WHrate', 'clickRate_all', 'clickRate_yesterday', 'ad_clickRate_yesterday']
global namesoh
namesoh = {
}
for sparse in sparsecols:
onehot = OneHotEncoder()
arrays = onehot.fit_transform(np.array(data[sparse]).reshape(-1, 1))
# 将onehot后的稀疏矩阵拼回原来的df
arrays = arrays.toarray()
names = [sparse + '_' + str(n) for n in range(len(arrays[0]))]
namesoh[sparse] = names
data = pd.concat([data, pd.DataFrame(arrays, columns=names)], axis=1)
data = data.drop([sparse], axis=1)
# 保存编码规则
with open(feature_encode_path.format(sparse) + '.pkl', 'wb') as f:
pickle.dump(onehot, f)
print(' onehot完成', time.strftime("%H:%M:%S", time.localtime(time.time())))
for dense in densecols:
mms = MinMaxScaler(feature_range=(0, 1))
data[dense] = mms.fit_transform(np.array(data[dense]).reshape(-1, 1))
with open(feature_encode_path.format(dense) + '.pkl', 'wb') as f:
pickle.dump(mms, f)
print(' 归一化完成', time.strftime("%H:%M:%S", time.localtime(time.time())))
print(' columns: ', len(list(data.columns)))
''' 验证集划分 '''
# 正负样本各抽10%作为验证集
test_data = val_split(data, frac=0.1)
val_data = val_split(data, frac=0.01)
negBpow(data, '训练集')
negBpow(test_data, '训练集')
negBpow(val_data, '验证集')
print(' data shape: ', data.shape)
print(' test_data shape: ', test_data.shape)
print(' val_data shape: ', val_data.shape)
''' 一阶特征 '''
# sparse_features = sparsecols
sparse_features = []
for value in namesoh.values():
for v in value:
sparse_features.append(v)
dense_features = densecols + idEmbeddingcols + ratecols
''' 二阶特征 '''
sparse_feature_columns = [SparseFeat(feat, vocabulary_size=int(data[feat].max() + 1), embedding_dim=4)
for i, feat in enumerate(sparse_features)]
dense_feature_columns = [DenseFeat(feat, 1)
for feat in dense_features]
print(' sparse_features count: ', len(sparse_features))
print(' dense_features count: ', len(dense_features))
''' DNN '''
dnn_feature_columns = sparse_feature_columns + dense_feature_columns
''' FM '''
linear_feature_columns = sparse_feature_columns + dense_feature_columns
global feature_names
feature_names = get_feature_names(linear_feature_columns + dnn_feature_columns)
print(' feature_names: ', feature_names)
''' feed处理 '''
train_x = {
name: data[name].values for name in feature_names}
test_x = {
name: test_data[name].values for name in feature_names}
val_x = {
name: val_data[name].values for name in feature_names}
train_y = data[['y']].values
test_y = test_data[['y']].values
val_y = val_data[['y']].values
print(' 数据处理完成', time.strftime("%H:%M:%S", time.localtime(time.time())))
deep = xDeepFM(linear_feature_columns, dnn_feature_columns, dnn_hidden_units=(256, 128, 64, 32),
l2_reg_linear=0.001, l2_reg_embedding=0.001, dnn_dropout=0.1, dnn_activation='relu', dnn_use_bn=True,
task='binary')
mNadam = Adam(lr=1e-4, beta_1=0.98, beta_2=0.999)
deep.compile(optimizer=mNadam, loss='binary_crossentropy',
metrics=['AUC', 'Precision', 'Recall'])
print(' 组网完成', time.strftime("%H:%M:%S", time.localtime(time.time())))
print(' 训练开始 ', time.strftime("%H:%M:%S", time.localtime(time.time())))
start_time = time.time()
''' 训练 '''
batch_size = 20000
train_nums = len(data)
deep.fit_generator(
GeneratorRandomPatchs(train_x, train_y, batch_size, train_nums, feature_names),
validation_data=(val_x, val_y),
steps_per_epoch=train_nums // batch_size,
epochs=30,
verbose=1,
shuffle=True,
# callbacks=[earlystop_callback]
)
end_time = time.time()
print(' 训练完成', time.strftime("%H:%M:%S", time.localtime(time.time())))
print((' 训练运行时间: {:.0f}分 {:.0f}秒'.format((end_time - start_time) // 60, (end_time - start_time) % 60)))
# exit()
# 模型保存成yaml文件
save_model(deep, save_path)
print(' 模型保存完成', time.strftime("%H:%M:%S", time.localtime(time.time())))
# 测试集评估
scores = deep.evaluate(test_x, test_y, verbose=0)
print(' %s: %.4f' % (deep.metrics_names[0], scores[0]))
print(' %s: %.4f' % (deep.metrics_names[1], scores[1]))
print(' %s: %.4f' % (deep.metrics_names[2], scores[2]))
print(' %s: %.4f' % (deep.metrics_names[3], scores[3]))
print(' 验证集再评估完成', time.strftime("%H:%M:%S", time.localtime(time.time())))
# 全量评估
full_evaluate()
end_time_end = time.time()
print(('xDeepFM 模型训练运行时间: {:.0f}分 {:.0f}秒'.format((end_time_end - start_time_start) // 60, (end_time_end - start_time_start) % 60)))