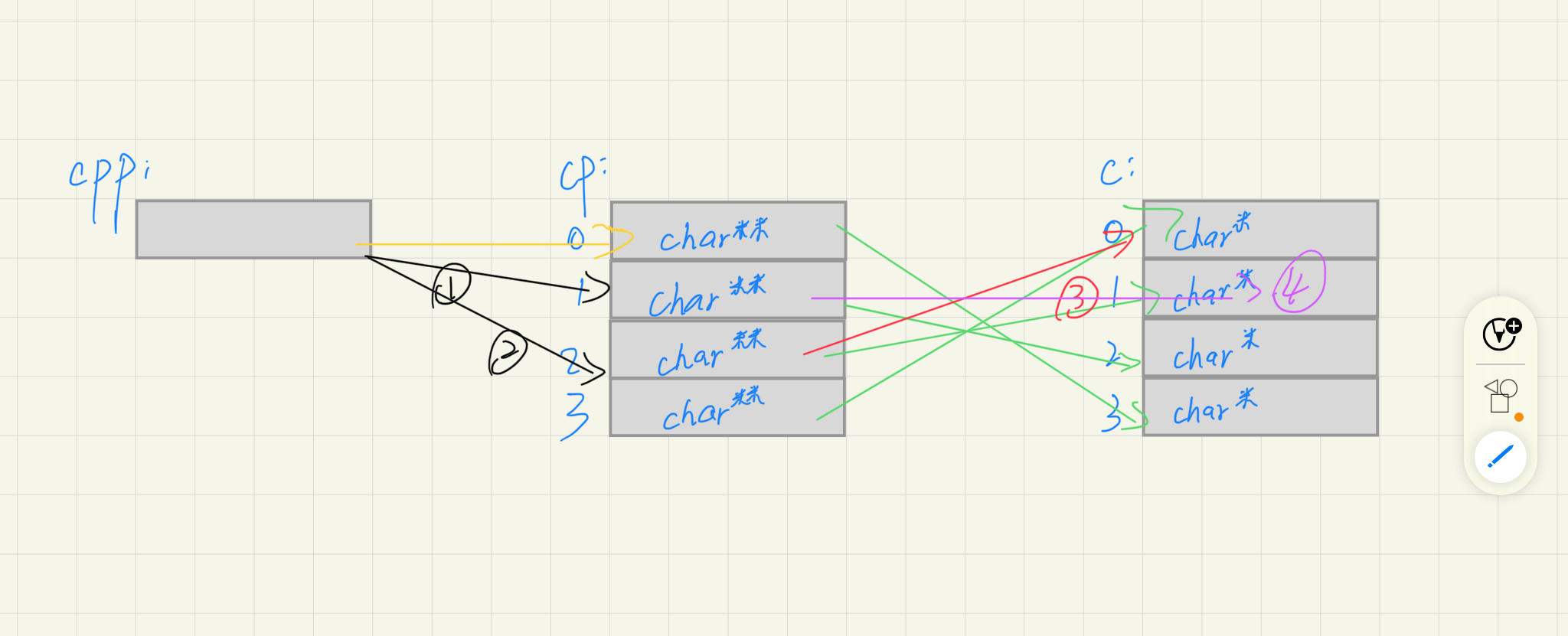
C/C++指针整理(C部分)
文章目录
1.什么是指针
指针就是一个变量,存放内存单元的地址。
1.1指针的大小
既然是内存单元的地址,那么指针变量的大小就和地址的大小有关。
在32位平台下指针是4个字节大小,64位平台下指针是8个字节大小。
32位机器就有32根地址线,就有 2 32 2^{32} 232个地址,如果按照一个字节进行编址, 2 32 / 1024 / 1024 / 1024 = 4 G B 2^{32}/1024/1024/1024=4GB 232/1024/1024/1024=4GB 如此大的空间不现实。
因此改成了32位机子4字节,64位机子8字节比较合适
1.2指针的声明和类型及解引用
C语言中有不少内置类型,比如说int,char,short等。而指针有没有类型,指针又如何标识?
我们来看这样的情景:
int num=10;
p=#
这里的p要怎么声明呢?
char *pc = NULL;
int *pi = NULL;
short *ps = NULL;
long *pl = NULL;
float *pf = NULL;
double *pd = NULL;
如此声明有两种理解:
- *表明pc是指针,其存放的地址应该以char类型来解释
- char* 表明pc是char*的指针。
看起来区别不大,但是时间久了之后个人感觉第一种理解更贴切。
比如这种情况:
char* pc,pd;
请问pc和pd分别是什么?pc是指针,存放char的地址。而pd是char。在第二种理解的方式下就会产生误解,理解成pc和pd都是指针。
那么已经说到*代表指针类型,前面的类型放具体是为了什么,指针又为什么能强转呢?
指针的类型指明了该指针应该如何翻译指向的地址的内容。
#include <stdio.h>
int main()
{
int n = 10;
char *pc = (char*)&n;
int *pi = &n;
printf("%p\n", &n);
printf("%p\n", pc);
printf("%p\n", pc+1);
printf("%p\n", pi);
printf("%p\n", pi+1);
return 0;
}
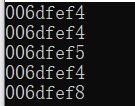
可以看到,指针指向了n变量的地址,在不同类型下解释的时候,开始都是指向相同的首地址,而char是一字节的,int是4字节的,因此指针的+1是按照指针类型来计算的。
既然指针的类型是指明了指针+1的大小,那么如下代码又作何输出
#include <stdio.h>
int main()
{
int n = 0x11223344;
char *pc = (char *)&n;
int *pi = &n;
*pc = 0;
*pi = 0;
return 0;
}
大小端:大小端指的的是高位字节的存储位置。
如0x11223344,11是高位字节,在小端法的模式下,高位字节存在高地址的位置;而在大端法的模式下,高位字节存在低地址的位置。
本机环境为小端。
关于判断机器大小端,有两种方式:一种是用指针,一种是用联合(Union)
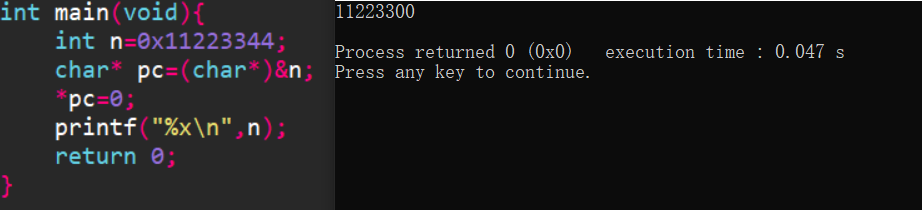
#include <stdio.h>
int main()
{
int n = 0x11223344;
char *pc = (char *)&n;
*pc = 0;
printf("%x\n",n);
return 0;
}
不难发现,在小端下,n的内存应该以 44 33 22 11形式分布,对于pc修改,是按照char来解释,改成了00 33 22 11.因此输出应该是0x11223300
#include <stdio.h>
int main()
{
int n = 0x11223344;
int *pc = &n;
*pc = 0;
printf("%x\n",n);
return 0;
}
而对于pi,是int来解释,因此四个字节全部赋成0.
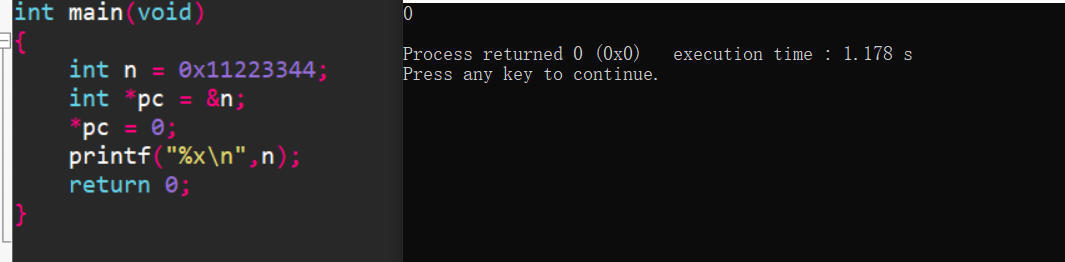
总结:
指针的类型决定了,对指针解引用的时候有多大的权限(能操作几个字节)。 比如: char* 的指针解引用就只能访问一个字节,而 int* 的指针的解引用就能访问四个字节。
1.3指针的运算
1.3.1指针±整数
在上一节已经看到了指针±1的一个场景。我们来看一个更加常用的例子——数组
数组的本质就是指针
在这里要记住的第一个点就是:单纯的数组名=首元素地址
*p++=i < − − − > <---> <−−−> *p=i,p++;
#include<cstdio>
int main(void){
int arr[10]={
0};
int* p=arr;//数组名=首元素地址
for(int i=0;i<10;i++){
arr[i]=1;
}
for(int i=0;i<10;i++){
printf("%d ",arr[i]);
}printf("\n");
for(int i=0;i<10;i++){
*(p+i)=1;
}
for(int i=0;i<10;i++){
printf("%d ",arr[i]);
}printf("\n");
for(int i=0;i<10;i++){
*p++=i; // *p=i;p++;--->*p++ =i;
}
for(int i=0;i<10;i++){
printf("%d ",arr[i]);
}printf("\n");
}
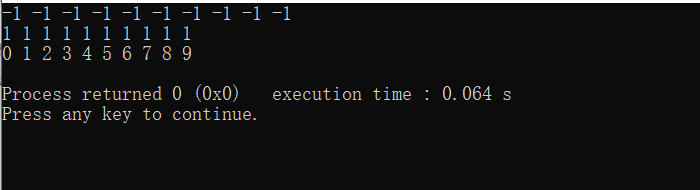
所以你观察的话,平时直接使用arr[i],背后的原理其实是*(arr+i),本质上是一个指针的加减。这里的例子是用指针来表示arr,是来做指针的加减。所以我如果没有指针来指向这个数组,我是不是直接使用arr+i,仍能保持这个性质呢?——3.3数组名VS&数组名
1.3.2指针±指针
同样以数组为例,指针-指针等于下标之差,注意要指向同一块空间的两个指针。
#include<cstdio>
int main(void){
int arr[10]={
1,2,3,4,5,6,7,8,9,10};
printf("%d\n",&arr[9]-&arr[0]);
}
在这里初步提及到了数组和指针的关系,到了后面还会重新进一步提及
2.什么是野指针
概念: 野指针就是指针指向的位置是不可知的(随机的、不正确的、没有明确限制的)
而且野指针的原因是面试常考内容
2.1野指针的成因
2.1.1指针未初始化
#include <stdio.h>
int main(void)
{
int *p;//局部变量指针未初始化,默认为随机值
return 0;
}
2.1.2指针越界访问
这里提一句,越界访问在有些时候提交是存在tle的。因为循环变量i可能是存在数组后面的空间,越界后访问会把循环变量给修改了导致死循环。
#include <stdio.h>
int main(void)
{
int arr[10]={
0};
int* p=arr;
int i=0;
for(int i=0;i<=11;i+++){
*(p+i)=1; //内存越界访问,p就是野指针
}
return 0;
}
2.1.3指针指向的内存释放了
注意这里的内存分为两种情形,一种是函数栈帧中的在栈上的内存,一种是手动malloc在堆上的内存
2.1.3.1函数栈帧中在栈上的内存
这种情况是释放了但是没有重新分配,假如程序中间插入了其他语句就可能导致那块内存被再分配最后导致内容改变。
test函数是在栈上开的空间。——关于函数栈帧,参考链接
此种情况下,原来的空间只是回收,随时可能被重新利用
因此将临时对象的地址作为参数返回并且对其解引用进行修改,是一种未知行为。临时对象的地址空间已经归还操作系统。
int* test(){
int a=10; //函数结束时空间释放了
return &a;
}
int main(){
int* p=test();
*p=20;
return 0;
}
2.1.3.2堆上的内存释放
由于在函数栈帧中以临时变量指向在堆上开辟的空间,并且在函数结束后没法拿到指向堆上空间的地址,造成了内存泄漏
void test()
{
int* p=(int*)malloc(100);
if(p==NULL)
{
return;
}
//使用
}
int main()
{
test();
//...
return 0;
}
2.2规避野指针的方法
-
指针初始化
- 初始化NULL
-
小心指针越界
-
当指针指向的空间释放,把指针指向NULL
- 不用了置NULL
-
指针使用之前检查有效性
- 用NULL来判断
3.指针和数组的关系
3.1结论
先说结论:
*(arr+i)=arr[i] − − − − − − − > -------> −−−−−−−>地址的+1同样看类型
&arr是取的是整个数组的首地址
单纯 sizeof(arr) 是整个数组的首地址
arr(单纯数组名)是数组首元素的地址——数组名=数组首元素的地址。
3.2数组名和数组首元素的地址
数组是什么就不必解释了。
我们现在来看数组名和数组首元素的地址是什么关系
include <stdio.h>
int main()
{
int arr[10] = {
1,2,3,4,5,6,7,8,9,0};
printf("%p\n", arr);
printf("%p\n", &arr[0]);
return 0;
}

可见数组名和数组首元素的地址是一样的。
结论:数组名表示的是数组首元素的地址
因此以下遍历数组的代码都是可行的。
这里的sizeof(数组名)——整个数组的大小,即10个int。
sizeof(arr[0])——即数组中首元素的大小。
在C语言中,这种方式是求数组size的一个常用方法。
#include <stdio.h>
int main()
{
int arr[] = {
1,2,3,4,5,6,7,8,9,0};
int *p = arr; //指针存放数组首元素的地址
int sz = sizeof(arr)/sizeof(arr[0]);
for(i=0; i<sz; i++)
{
printf("&arr[%d] = %p <====> p+%d = %p\n", i, &arr[i], i, p+i);
}
return 0;
}
3.3 数组名VS&数组名
前言:
在指针的运算中我们已经提到:数组的本质就是指针
在这里要记住的第一个点就是:单纯的数组名=首元素地址——1.3.1指针的运算
对于下面这段程序,其含义应当是如何?
#include <stdio.h>
int main()
{
int arr[10] = {
0 };
printf("arr = %p\n", arr);
printf("&arr= %p\n", &arr);
printf("arr+1 = %p\n", arr+1);
printf("&arr+1= %p\n", &arr+1);
return 0;
}
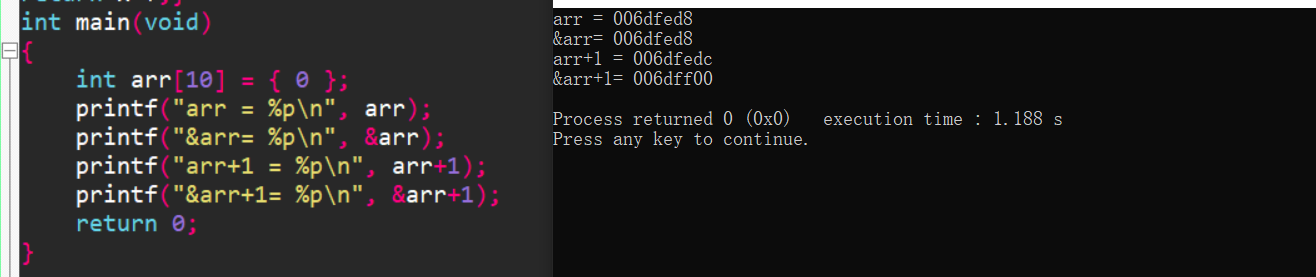
可以看到,数组名和&数组名在不进行加减的情况下是一样的,但是在进行加减的时候,就会产生差异。
arr既然是数组首元素的地址,那么该地址加1对应的应当是按照一个数组元素大小进行+1。
即可以理解为int* point=arr。而指针是根据类型来进行加减的大小。
因此arr+1实际上就是point+1。即按照int大小(一个字节)进行加减。此时指向数组的第二个元素。
而&arr是数组的地址,也就是指向一个数组的10个int的大小。实际上后面在数组指针的部分讲解中就会知道也是可以以 int( ∗ * ∗p)[10] 的形式表示
可能会突然觉得很怪异,怎么这个地址就直接按照指针的形式来算了呢?
回来看之前的1.3.1的例子:
前言:
所以你看,平时直接使用arr[i],背后的原理其实是*(arr+i),本质上是一个指针的加减。这里的例子是用指针来表示arr,是来做指针的加减。所以我如果没有指针来指向这个数组,我是不是直接使用arr+i,仍能保持这个性质呢?
#include<cstdio>
int main(void){
int arr[10]={
0};
int* p=arr;//数组名=首元素地址
for(int i=0;i<10;i++){
arr[i]=1;
}
for(int i=0;i<10;i++){
printf("%d ",arr[i]);
}printf("\n");
for(int i=0;i<10;i++){
*(p+i)=1;
}
for(int i=0;i<10;i++){
printf("%d ",arr[i]);
}printf("\n");
}
答案:
在这里我们就应该看到,这个性质理应并且合理。
既然 i n t ∗ p = a r r , ∗ ( p + i ) = a r r [ i ] − − − − > ∗ ( a r r + i ) = a r r [ i ] int *p=arr,*(p+i)=arr[i] ---->*(arr+i)=arr[i] int∗p=arr,∗(p+i)=arr[i]−−−−>∗(arr+i)=arr[i]
由此可以看到,就算没有指针来指向数组,我们平时直接使用的int arr[i],比如arr[1],我们是直接获取了第二个int类型的数组元素。
arr[1]=*(arr+1),我们在这里也没有直接的用指针来进行加减,结果仍然是按照元素类型的大小去加减。
因为数组本就是一段连续相同数据类型的集合,因此其首元素地址的加减理应按照数据类型大小去加减。
因此我们可以推出:*(arr+i)=arr[i]
并且从这个角度来说,它和指针的性质是吻合的。甚至可以将[]看成是数组的一个解引用的语法糖。
因此根据上面的代码我们发现,其实&arr和arr,虽然值是一样的,但是意义应该不一样的。 实际上: &arr 表示的是数组的地址,而不是数组首元素的地址。
数组的地址+1,跳过整个数组的大小,所以 &arr+1 相对于 &arr 的差值是40.
4.二(多)级指针
指针变量也是变量,是变量就有地址,那指针变量的地址存放在哪里? 这就是 二级指针 。
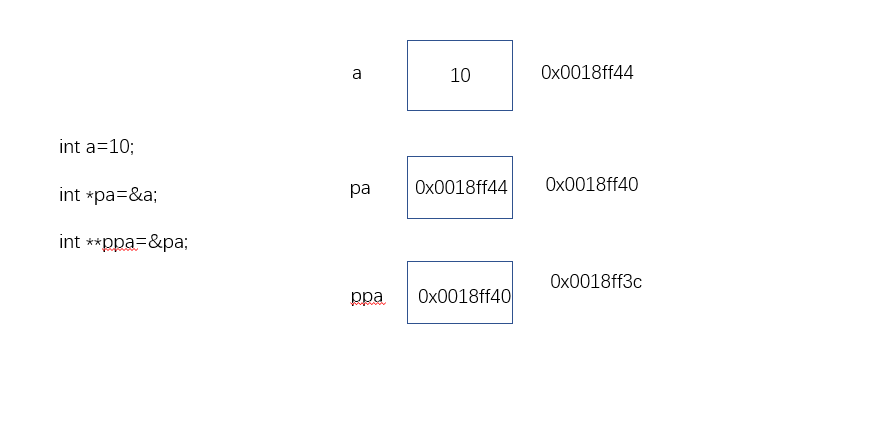
int a=10;
int* pa=&a;
int** ppa=&pa;///二级指针
int*** pppa=&ppa;
printf("%d\n",**ppa);
在C中写数据结构比如链表的销毁中可以用到,直接修改main中的头结点指针为NULL
void ListDestroy(ListNode* phead){
assert(phead);
ListNode* cur=phead->next;
while(cur!=phead){
ListNode* next=cur->next;///提前保存
free(cur);
cur=next;
}
free(phead);
phead=NULL;//一级指针没用,这是临时变量
//1.传二级指针
//2.用完自己赋值NULL;保持接口的一致性
}
int main(){
ListNode* plist = list_create();
list_destory(&plist);
plist=NULL;
if (plist == NULL) {
printf("空指针\n");
}
else {
printf("不是空指针\n");
}
}
//要将main中的plist置为空
void list_destory(ListNode** p) {
assert(p);
ListNode* phead = *p;
ListNode* cur = phead->next;
while (cur != phead) {
ListNode* next = cur->next;
free(cur);
cur = next;
}
free(phead);
*p = NULL;//将main中的指针赋值为NULL。
}
int main(){
ListNode* plist = list_create();
list_destory(&plist);
if (plist == NULL) {
printf("空指针\n");
}
else {
printf("不是空指针\n");
}
}
5.指针数组
首先明确:指针数组是数组,存的元素都是指针
#include<stdio.h>
int main(void)
{
int a=10;int b=20;int c=30;
int* pa=&a;int *pb=&b;int *pc=&c;
int* arr[]={
pa,pb,pc};
int sz=sizeof(arr)/sizeof(arr[0]);
for(int i=0;i<sz;i++){
printf("%x %d\n",arr[i],*arr[i]);
}
return 0;
}
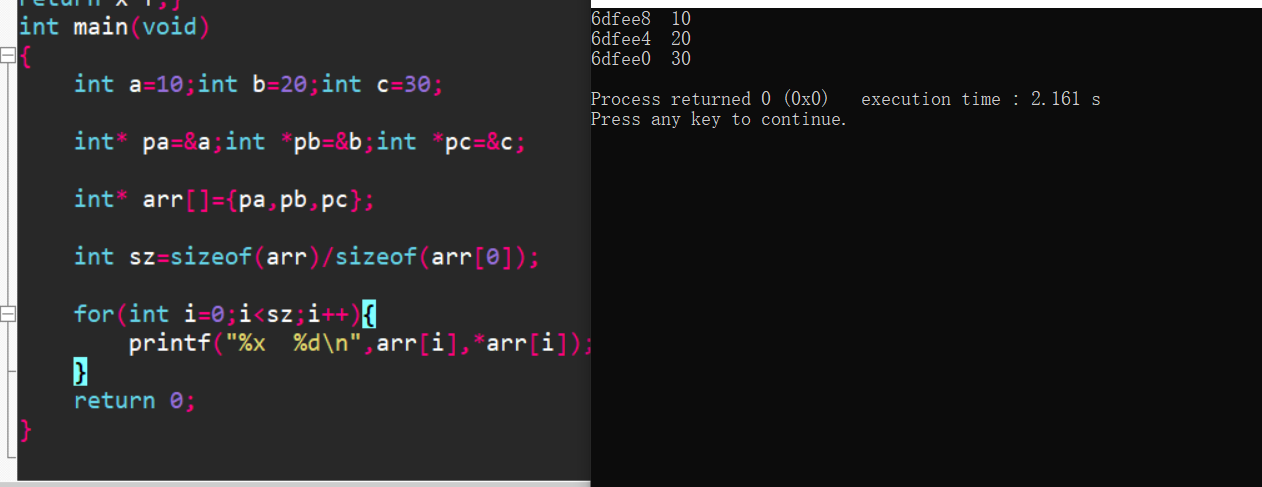
#include<stdio.h>
int main(void)
{
int arr1[]={
1,2,3,4,5};
int arr2[]={
6,7,8,9,10};
int arr3[]={
11,12,13,14,15};
int* pointarr[]={
arr1,arr2,arr3};
for(int i=0;i<3;i++){
for(int j=0;j<5;j++){
printf("%d ", * ( (pointarr[i])+j ) );
}printf("\n");
}
return 0;
}

6.数组指针
6.1一维数组
首先明确:数组指针,指向的是数组。
在这里要注意[]的运算符优先级的关系
int main(){
int* p=NULL;//p是整形指针 -- 指向整型的指针 --可以存放整形的地址
char* pc=NULL; // pc是字符指针 -- 指向字符的指针 --可以存放字符的地址
//数组指针 -- 指向数组的指针 -- 存放数组的地址
//arr- 首元素地址
//&arr[0] -首元素地址
//&arr - 数组的地址 (yes)
int arr[10]={
1,2,3,4,5,6,7,8,9,10};
int (*pa)[10]=&arr; //数组的地址要存起来 ,p是数组指针,指向一个数组(有10个元素[10]),里面每个元素都是int
//*pa是先解引用成数组了。因为数组的地址解引用自然是数组
for(int i=0;i<10;i++){
printf("%d ",(*pa)[i]);
}
printf("\n");
for(int i=0;i<10;i++){
printf("%d ",*(*pa+i) );
}
}
由于[]的优先级比*高,所以为了不变成指针数组的形式需要提前加括号。
int (*pa)[10]=&arr 表明 , *pa是一个指针,指向的是一个[10]个元素的数组,数组的类型是int。因此需要指向数组的地址,即&arr。
而同时与之对应的,pa+1和pa是差距了一个数组的大小。
而对pa解引用是什么意思,解引用后就是数组名,而数组名是什么,即数组首元素的地址。因此根据3.指针和数组关系即可得,获得了首元素的地址+1仍然是按照int类型。
6.2二维数组
一般来说数组指针用到二维数组的时候才算方便。同时也产生了一个问题,二维数组实际上的内存分配是如何的?同时二维数组的数组名也是代表数组首元素的地址吗?二维数组的数组首元素地址是什么?
#include<stdio.h>
/*参数是数组的形式*/
void print1(int arr[3][5],int x,int y){
int i=0;int j=0;
for(i=0;i<x;i++){
for(j=0;j<y;j++){
printf("%d ",arr[i][j]);
}
printf("\n");
}
}
void print2(int (*p)[5], int x,int y){
for(int i=0;i<x;i++){
for(int j=0;j<y;j++){
printf("%d " ,p[i][j]);
}
}printf("\n");
for(int i=0;i<x;i++){
for(int j=0;j<y;j++){
printf("%d ",*(p[i]+j));
}
}printf("\n");
for(int i=0;i<x;i++){
for(int j=0;j<y;j++){
printf("%d ",*(*(p+i)+j) );
}
}printf("\n");
for(int i=0;i<x;i++){
for(int j=0;j<y;j++){
printf("%d ", (*(p+i))[j] );
}
}
}
int main(){
int arr[3][5]={
{
1,2,3,4,5},{
6,7,8,9,10},{
11,12,13,14,15}};
print1(arr,3,5); //arr -数组名 --首元素地址(sizeof和&特殊)
//首元素不是这个1
//讨论首元素的时候,若是二维数组,把二维数组想象成一维数组,所以此时arr是一维数组的地址
//把每行看成一个元素
// 1 2 3 4 5 (1) int [5]
// 6 7 8 9 10 (2)
// 11 12 13 14 15 (3)
// 首元素就是第一行,第二个元素是第二行
print2(arr,3,5);
}
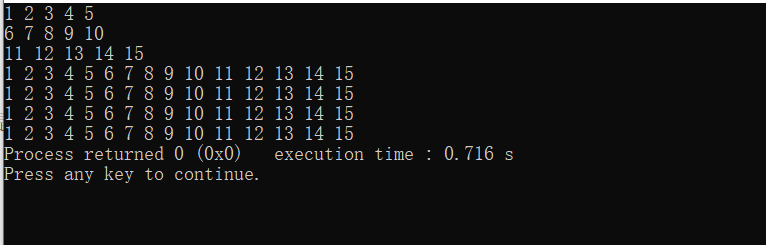
- 第一份输出以二维数组的形式传参
- 第二份输出以一维数组指针的形式传参
上述两份输出是完全一样的也就是等价的。
可以看出,虽然在编译器的调试窗口下二维数组是分割成一行一行的,但是实际上是一串一维的连续的数组,按照一维数组固定的大小来拼凑成二维数组。
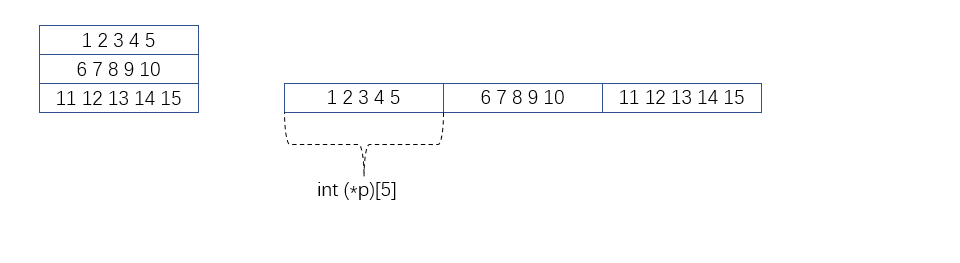
针对这个输出的含义:
内部循环里面的p[i]+j,前面已经提及 p [ i ] = ∗ ( p + i ) p[i]=*(p+i) p[i]=∗(p+i),p是数组指针,所以+i实际上一次跳i个5个int大小的数组,当p[i]完成的时候,即为一维数组的数组名(也即数组首元素的地址)。因此再次+j按照一维数组内置类型元素的大小来加减【即类似3.3的arr+1】,即访问该一维数组内对应的元素。
for(int i=0;i<x;i++){
for(int j=0;j<y;j++){
printf("%d ",*(p[i]+j));
}
}printf("\n");
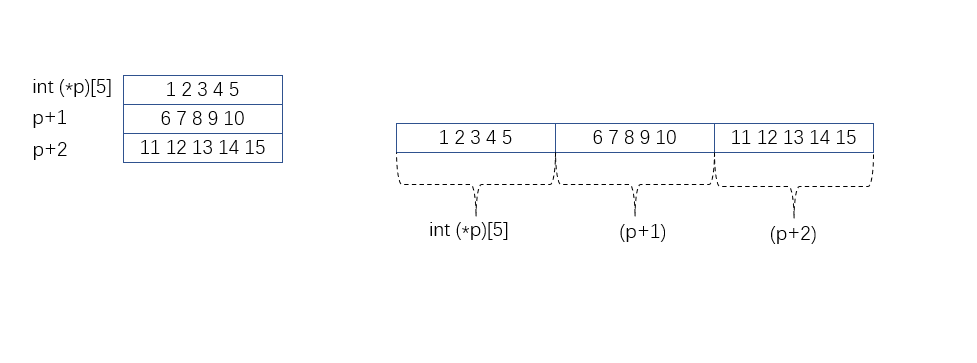
对于第三份输出即是将p[i]具体展开。
for(int i=0;i<x;i++){
for(int j=0;j<y;j++){
printf("%d ",*(*(p+i)+j) );
}
}printf("\n");
对于第四份输出, ∗ ( p + i ) *(p+i) ∗(p+i)将一维数组指针解引用到对应的一维数组,即是一维数组的数组名,对于[j]也就是取一维数组的第j个元素。
for(int i=0;i<x;i++){
for(int j=0;j<y;j++){
printf("%d ", (*(p+i))[j] );
}
}printf("\n");
而此时再来看调用输入的参数print2(arr,3,5)。我们传的arr,对应接收的一维的数组指针。
综上可以看出来,对于二维数组,一维数组的性质依然都是满足的。并且特别的,对于二维数组来说,数组首元素的地址是首行数组的地址。
6.3回顾
以下分别是什么意思?
int arr[5];
int *parr1[10];
int (*parr2)[10];
int (*parr3[10])[5];
- 代表一个5个int类型的数组
- 代表一个10个int*类型的数组
- parr2和*结合,表示指针,指向[10]个元素都是int类型的数组,是数组指针
- parr3[10]先结合,表示是一个10个元素的数组,*表示10个元素都是指针,而指针指向的都是int [5],即数组指针,每个指针指向的数组有5个元素且都是int。即是一个数组指针的数组。
7.字符指针
该指针指向的类型是字符。
对于const修饰的问题在13节
#include<stdio.h>
int main(){
char ch='w';
char* pc=&ch;
char arr[]="abcdef";
char* pc=arr;
printf("%s\n",arr);
printf("%s\n",pc);
const char* p="abcdef"; /* abcdef是一个常量字符串 */
printf("%c\n",p);/*存的是a的地址*/
printf("%s\n",p);/*从a开始打印一串*/
}
char arr1[]={
"abcdef"};
char arr2[]={
'a','b','c','d','e','f'};
两者的区别在于上面末尾有’\0’,而下面的没有。
8.数组参数,指针参数
8.1数组传参
一维时候可以写大小也不可以不写,写错也没事。
void test(int arr[]){
//ok
}
void test(int arr[10]){
//ok
}
void test(int *arr){
//ok ,传的arr是首元素地址,这个数组的每个元素都是int; *表明*arr指向首元素地址,指向的内容是int
}
void test2(int *arr[20]){
//ok 对应参数形式
}
void test2( int** arr2 ){
//ok *arr2表示arr2是一个指针,指向的内容是int*。其中传进来的arr2是数组首元素地址,*arr2指向该地址,int*表明数组首元素是int*,指针解引用也就是int*。
}
int main(){
int arr[10] ={
0};
int *arr2[20]={
0};//优先与[20]结合,这是个指针数组
test(arr);
test2(arr2);
}
二维传参,行可以省略掉,但是列不能。
二维数组传参,函数参数的设计只能省略第一个[]的数字
- 因为对一个二维数组,可以不知道有多少行,但是必须知道一行有多少元素,这样才方便计算
void test(int arr[3][5]){
}
void test1(int arr[][5]){
}
void test2(int arr[3][]){
//error
}
void test3(int arr[][]){
//error
}
void test4(int (*arr)[5]){
//以一维数组指针来传。
}
int main(){
int arr[3][5]={
0};
test(arr);///二维数组传参
test1(arr);
test2(arr);
return 0;
}
8.2指针参数
8.2.1一级指针传参
void print(int *p,int sz){
int i=0;
for(i=0;i<sz;i++){
printf("%d\n",*(p+i));
}
}
int main(){
int arr[10]={
1,2,3,4,5,6,7,8,9};
int *p=arr;
int sz=sizeof(arr)/sizeof(arr[0]);
//一级指针,传给函数
print(p,sz);
}
思考:当一个函数的参数部分为一级指针的时候,函数能接收什么参数?
如:
/*test1能接收什么参数*/
/* 指针,int数组首元素的地址,&(int) */
void test1(int *p){
}
void test2(char* p){
}
可以传指针,也可以传int类型的数组,也可以传&(int)
8.2.2二级指针传参
void test(int** ptr){
}
int main(){
int n=10;
int* p=&n;
int **pp=&p;
test(pp);
test(&p);
int* arr[10];///指针数组也可以
test(arr);
}
如链表的销毁将原指针置为空指针。
//要将main中的plist置为空
void list_destory(ListNode** p) {
assert(p);
ListNode* phead = *p;
ListNode* cur = phead->next;
while (cur != phead) {
ListNode* next = cur->next;
free(cur);
cur = next;
}
free(phead);
*p = NULL;//将main中的指针赋值为NULL。
}
int main(){
ListNode* plist = list_create();
list_destory(&plist);
if (plist == NULL) {
printf("空指针\n");
}
else {
printf("不是空指针\n");
}
}
9.函数指针
数组指针—指向数组的指针
函数指针—指向函数的指针 —存放函数地址的一个指针
函数里面&函数名和函数名是一样的,都是函数的地址
如果打开汇编,就可以看到,函数的调用其实就是call到该函数首行代码的地址。因此函数理应也有指针,指向的是函数的首代码的地址。
9.1函数指针写法
来看下面一个例子:
int Add(int x,int y){
int z=0;
z=x+y;
return z;
}
int main(){
int a=10;
int b=20;
int arr[10]={
0};
//&arr; 整个数组的地址
//arr;数组首元素的地址
//printf("%d\n",Add(a,b));
printf("%p\n",&Add);
printf("%p\n",Add);
int (*pa)(int,int) =Add; /* ( , )意味着指向函数,参数可写可不写 */
pritnf("%d\n",(*pa)(2,3) );
return 0;
}
在普通的调用中,函数的调用写不写&都不影响。
这里注意下函数指针的写法:
*pa表示是一个指针,int( ) (int,int)表示函数的返回类型是int,参数是两个int。其中调用的时候就和直接使用函数一样p(xxx,xxx)即可。
再来看个例子。
void print(char* str){
printf("%s\n",str);
}
int main(){
void (*p)(char* ) = print;
(*p)("hello world");
return 0;
}
9.2函数指针的例子
例子一:
(* (void (*) () )0 )();
初看会很懵,但是一步步拆开来看。
首先,我们看到0前面有一个大的括号,来分析这个括号。
(void (*) () )
void (*) () , 其中*表明是一个指针,再看前面的void和后面的(),这是函数指针的语法,所以这里一个指向void ()的函数指针
此时再来看这个0,0是int类型的,那就是说这里其实是将这个0强转成一个指向void ()的函数指针。
再来看剩下的部分
(* 函数指针 ) ();
前面的*就是对函数指针的解引用,外面的()就是函数的参数列表,也就是说此时调用了这个函数
综上:这段代码就是把0强制转换成一个函数指针并且调用它。
例子二:
void ( *signal(int , void(*)(int) ) ) )(int);
首先还是一步步拆开来看,
void(*)(int),就是一个函数指针,表明指针指向一个返回类型为void,并且参数为int的函数
再来看
signal(int , void(*)(int) )
是一个函数调用的形式,signal函数的参数类型分别是int和函数指针。
那么接下来再看外面
void ( *signal(int , void(*)(int) ) ) )(int);
signal函数已经拆开来,有了参数和函数函数名,剩下的部分就是函数的返回类型。
即signal函数的返回类型是void (*) (int),返回的也是一个函数指针,其指向的函数参数是int,返回类型是void。
综上:
signal是一个函数声明
signal函数的参数有2个,第一个是int。第二个是函数指针,该函数指针指向的函数的参数是int,返回类型是void
signal函数的返回类型也是一个函数指针:该函数指针指向的函数的参数是int,返回类型是void
9.3函数指针的typedef
可以看到,上面将函数指针写到参数里面很复杂并且累赘,那么能否如C将struct进行typedef 一样对函数指针进行typedef呢?答案肯定是可以的。
比如拿上面的例子来
void ( *signal(int , void(*)(int) ) ) )(int);
我们可以先把signal的参数的函数指针给定义了。
typedef void(*)(int) p_fun_t ;///不能这么定义
虽然说像其他地方类型都是放最后的,但是函数指针不一样。
像前面的例子
int (*pa)(int,int) =Add;
这个pa是拿来调用的,也就是说pa才是变量名。所以我们应该定义的时候变量名也写在这里
typedef void(* p_fun_t)(int)
然后上面的就变成了
p_fun_t signal(int p_fun_t){
};
瞬间就清楚很多了。
9.4函数指针的用途
9.2.1比较函数(仿函数)
这里我直接拿堆的C实现来举例子
在堆的结构体中定义一个比较函数的指针,在进行堆的向下调整(这里只举了向上调整的例子)和向上调整中,就不用为了实现>,<的关系而重新再写一份几乎一样只有比较不一样的代码,提升了代码的复用性。
typedef int DateType;
typedef struct Heap {
DateType* a;
size_t size;
size_t capacity;
bool (*p)(DateType, DateType);//函数指针
}Heap;
//权当c++中的仿函数
bool Less(DateType A, DateType B) {
return A > B;
}
bool Greater(DateType A, DateType B) {
return A < B;
}
void swap(DateType* A, DateType* B) {
DateType tmp = *A;
*A = *B;
*B = tmp;
}
//注:c++中Greater为小堆,仿照c++
///向下调整算法(建默认的大堆)
void adjust_down(Heap* hp, size_t n, size_t parent, bool (*p)(DateType, DateType) ) {
size_t child = parent * 2 + 1;///左儿子
while (child < n) {
//找出大的儿子(大堆) 小堆找小的儿子
if (child+1<n && p(hp->a[child + 1],hp->a[child]) ) child++;
if ( p(hp->a[child],hp->a[parent] ) ) {
swap(&hp->a[child], &hp->a[parent]);
parent = child;
child = parent * 2 + 1;//左儿子
}
else break;
}
10.函数指针数组
10.1函数指针数组的用法
看下面的例子:
char* (*pf)(char*,const char*)=my_strcpy;
char* (*pfarr [4])(char* ,const char*)={
};
第一行pf是个指针,指向一个函数,该函数的返回类型是char*,参数是 ( c h a r ∗ , c o n s t c h a r ∗ ) (char * , const char * ) (char∗,constchar∗) 。
而第二行优先和数组结合,表明是一个4个元素大小的数组,元素的类型是指针,该指针指向的内容是函数。这就是函数指针数组。
10.2函数指针数组的用途
10.2.1转移表
比如在写计算器的途中,会使用很多函数,可以将这些函数存放在函数指针数组中使用。
int Add(int x,int y){
return x+y;
}
int Sub(int x,int y){
return x-y;
}
int Mul(int x,int y){
return x*y;
}
int Div(int x,int y){
return x/y;
}
int main(){
//指针数组
int* arr[5];
//需要一个数组。这个数组可以存放4个函数的地址 --函数指针数组
int (*pa)(int,int)=Add;
int (*pa)(int,int)=Add;///Sub/Mul/Div
int(*parr[4])(int,int)={
Add,Sub,Mul,Div};///老规矩,先和方块结合,而且函数指针的变量和*贴在一起。数组元素4个,每个元素是函数
int i=0;
for(i=0;i<4;i++){
printf("%d\n",parr[i](2,3) ) ; /* 前文已知可以不写* */
}
return 0;
}
但是发现,即使这样冗余的代码还是存在4份,只不过用了函数指针数组减少了switch的冗余性。如何变成只写一份呢?看回调函数
11.指向函数指针数组的指针
11.1用法
指向函数指针数组的指针是一个指针,指针指向一个数组,数组的元素都是函数指针。
int Add(int x,int y){
return x+y;
}
int main(){
int arr[10]={
0};
int (*p)[10]=&arr; //取出数组的地址
int (*pf)(int,int);//函数指针
int (*pfArr[4])(int ,int );///pfArr是一个数组--函数指针的数组
/// int (*ppfArr[4])(int ,int );
int(*( *ppfArr )[4] )(int,int)=(&pfArr);
///ppfArr是指针,指向一个4个元素的数组,每个元素是函数指针
///ppfArr是一个指向[函数指针数组]的指针
return 0;
}
11.2用途:虚函数表(多态)
举的还是c++的例子。这里为了完整性放了c++,具体的剖析在c++的指针分析中仍会提到。实际上是一个函数指针数组,而对象里存的是指向函数指针数组的指针。
#include<iostream>
using namespace std;
class Base {
public:
virtual void func1() {
cout << "Base:func1" << endl; }
virtual void func2() {
cout << "Base:func2" << endl; }
private:
int a;
};
class Derive :public Base {
virtual void func1() {
cout << "Derive::func1" << endl; }
virtual void func3() {
cout << "Derive::func3" << endl; }
virtual void func4() {
cout << "Derive::func4" << endl; }
private:
int b;
};
//打印虚表
///void (*p) () //定义一个函数指针变量
typedef void (*VF_PTR)();//函数指针类型typedef
void PrintVFTable(VF_PTR* ptable) {
for (size_t i = 0;ptable[i] != 0; i++) {
printf("vfTable[%d]:%p->", i, ptable[i]);
VF_PTR tmp=ptable[i];
tmp();
}printf("\n");
}
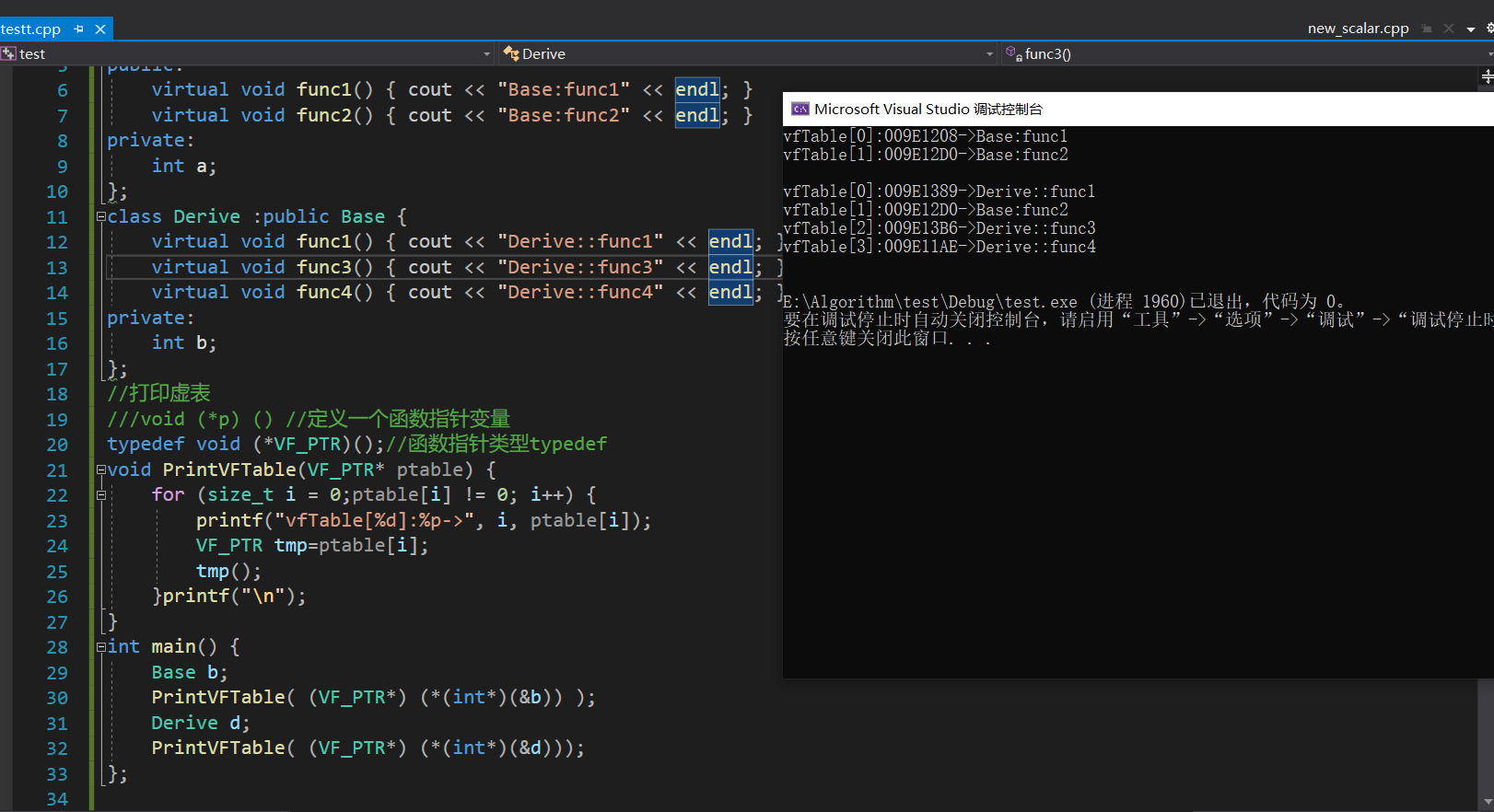
int main() {
Base b;
PrintVFTable( (VF_PTR*) (*(int*)(&b)) );
Derive d;
PrintVFTable( (VF_PTR*) (*(int*)(&d)));
};
对于实现了虚函数的对象,其内存第一个位置是指向其虚表的指针。
函数传参选择是指针传参,*ptable表明是个指针,指向虚表数组的首元素的地址。同时前面的参数表明指针指向的内容是虚函数。
而拿到了对象的地址,对其转换成int*并解引用拿到虚表首元素的地址。注意这里是对int类型的指针解引用,因此拿到的地址是int。以此作为数组首元素地址明显不符合,我们要类型匹配,对应的传一个表示指向虚函数的指针进去。
因此强转成(VF_PTR*)。
12.回调函数
回调函数就是一个通过函数指针调用的函数。
如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。
回调函数不是由该函数的实现方直接调用的,而是在特定的时间或条件发生时由另外的一方调用的,用于对该事件或条件的响应。
在转移表中提到还是需要写四个函数存在冗余,当使用回调函数的时候,就可以简洁很多。
int Add(int x,int y){
return x+y;
}
int Sub(int x,int y){
return x-y;
}
void Calc( int (*pf) (int ,int ) ){
int x=0;int y=0;
printf("输入两个操作数:>");
scanf("%d%d",&x,&y);
pritnf("%d\n",pf(x,y));
}
int main(void){
switch(input){
case 1:
Calc(Add);
break;
case 2:
Calc(Sub);
break;
default:
break;
}
return 0;
}
再举一个C语言中qsort的例子。由于单独地只能判一种类型排序,采用回调函数就能复用。
void Swap(char* buf1,char* buf2,int width){
int i=0;
for(int i=0;i<width;i++){
char tmp=*buf1;
*buf1=*buf2;
*buf2=tmp;
buf1++;
buf2++;
}
}
void bubble_sort(void* base,int sz,int width,int (*cmp) (const void* e1,const void* e2)){
int i=0;
//趟数
for(int i=0;i<sz-1;i++){
int j=0;
//每一趟的比较对数
for(int j=0;j<sz-1-i;j++){
//两个元素的比较
if( cmp( (char*)base+width*j,(char*)base+width*(j+1) ) >0 ){
///交换
swap ((char*)base+width*j,(char*)base+width*(j+1) ,width);
}
}
}
}
int cmp_int(const void* e1,const void* e2){
return *(int*)e1-*(int*)e2;
}
void test4(){
int arr[10]={
9,8,7,6,5,4,3,2,1,0};
int sz=sizeof(arr)/sizeof(arr[0]);
//使用bubble_sort的程序员一定知道自己排序的是什么数据
//就应该知道如何比较待排序数组中的元素
bubble_sort(arr,sz,sizeof(arr[0]),cmp_int );
}
int cmp_stu_byage(const void* e1,const void*e2){
return ((struct Stu*)e1)->age -( (struct Stu* )e2)->age;
}
void test5(){
struct Stu s[3]={
{
"zhuansan",20},{
"lisi",30},{
"wangshu",15}};
int sz=sizeof(arr)/sizeof(arr[0]);
bubble_sort(arr,sz,sizeof(arr[0]),cmp_stu_byage);
}
int main(){
test4();
test5();
}
13.C中指针的const修饰
const char *p — const 修饰 *p ,表示p指向的内容不能修改
char const *p --const 修饰 *p ,表示p指向的内容不能修改
char* const p—const修饰p本身,表示p的指向不能修改,p指向的空间中的内容可以修改。
const char * const p —第一个const表示p指向的内容不能修改,第二个const表示p不能指向其他变量
总结:也就是说const在 *左边表示能修饰指向的内容。在 * 右边表示修饰指针变量。
在C++中,尽量地对传引用,以及this指针指向内容不发生修改的情况下使用const。
比如
const char* p ="abcdef" //(如侯捷所说,万一别人用了发生段错误就很不好。因此直接const指针这样直接编译错误就好)
//而右值是字符串常量,IDE基本是编译阶段就要求直接加const了。
14.练习题
int main(){
char arr1[]="abcdef";
char arr2[]="acbdef";
char* p1="abcdef";
char* p2="abcdef";
if(arr1==arr2){
printf("hehe\n");
}
else{
printf("haha\n");
}
return 0;
}
/*输出的是haha*/
int main(){
char arr1[]="abcdef";
char arr2[]="acbdef";
char* p1="abcdef";
char* p2="abcdef";
if(p1==p2){
printf("hehe\n");
}
else{
printf("haha\n");
}
return 0;
}
/*输出是hehe*/
/*常量字符串不能被修改,两者又一样,节省空间内存中就一份*/
以下输出分别是什么?
//一维数组
int a[] = {
1,2,3,4};
printf("%d\n",sizeof(a));
printf("%d\n",sizeof(a+0));
printf("%d\n",sizeof(*a));
printf("%d\n",sizeof(a+1));
printf("%d\n",sizeof(a[1]));
printf("%d\n",sizeof(&a));
printf("%d\n",sizeof(*&a));
printf("%d\n",sizeof(&a+1));
printf("%d\n",sizeof(&a[0]));
printf("%d\n",sizeof(&a[0]+1));
第一个答案:16 sizeof(数组名)--计算的是数组总大小
第二个答案:4/8 数组名是首元素地址,两个例外:1.sizeof(数组名) --表示整个数组 2.&数组名 --数组名表示整个数组。所以是地址的大小,32位平台是4
第三个答案:4 *a就是首元素
第四个答案: 4/8 第二个元素的地址
第五个答案: 4 第一个元素的大小
第六个答案: 4 &a取出的是数组的地址,但是数组的地址也是地址,地址的大小都是统一的。
第七个答案:16 计算出一个数组的大小 --&a是数组的地址,对数组的地址解引用访问的是数组
第八个答案:4 跳过一个数组,跳到数组末尾后面的地址,是地址。
第九个答案:4 /8 &a[0]--第一个元素的地址,地址加1也是看类型的。这里是int类型。
第九个答案:4/8 第二个元素的地址,地址加1也是看类型的。这里是int类型。
//字符数组
char arr[] = {
'a','b','c','d','e','f'};
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr+0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr+1));
printf("%d\n", sizeof(&arr[0]+1));
第一个答案:6 注意这种形式没有'\0'
第二个答案:4 指针的大小
第三个答案:1 首元素的大小
第四个答案:1 char元素的大小
第五个答案:4 数组的地址,指针大小
第六个答案:4 数组地址+1,到数组末尾后一个,仍然地址
第七个答案:4 &arr[0]-->arr(数组首元素),地址+1(char),仍然地址
//字符数组
char arr[] = {
'a','b','c','d','e','f'};
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr+0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr+1));
printf("%d\n", strlen(&arr[0]+1));
**strlen目的是找到'\0'。找到之前出现几个字符就是几个。**参数部分传的是地址
第一个答案:随机值 因为不知道后面放的是啥
第二个答案:随机值 arr是首元素地址+0,还是上一题
第三个答案:RE *arr是'a',是97,相当于给strlen传了97。非法访问内存
第四个答案:RE 传了98
第五个答案:随机值
第六个答案:随机值
第七个答案:随机值 b的地址传给strlen
二维数组也是数组。
- sizeof(数组名)–》整个数组
- &数组名 --》整个数组
- 除此之外,所有数组名都是数组首元素的地址
- 所以这种题就看数组名是不是单独放sizeof内部,再看数组名有没有&,不然就是首元素的地址。
- 二维数组中*(a+1)就是第二行的数组名。相当于 sizeof( *&arr)=sizeof(arr)
int main()
{
int a[3][4]={
0};
cout<<sizeof(a)<<endl;
cout<<sizeof(a[0][0])<<endl;
cout<<sizeof(a[0])<<endl;
cout<<sizeof(a[0]+1)<<endl;
cout<<sizeof(*(a[0]+1))<<endl;
cout<<sizeof(*(a+1))<<endl;
cout<<sizeof(&a[0]+1)<<endl;
cout<<sizeof(*(&a[0]+1))<<endl;
cout<<sizeof(*a)<<endl;
cout<<sizeof(a[3])<<endl;
}
int main()
{
int a[3][4]={
0};
cout<<sizeof(a)<<endl;//48
cout<<sizeof(a[0][0])<<endl;//4
cout<<sizeof(a[0])<<endl;//第一行的数组名是a[0],第二行的数组名是a[1]。既然是数组名,数组名单独放在sizeof内部,就是数组的整个大小--4x4=16
cout<<sizeof(a[0]+1)<<endl;//数组名没有单独放到sizeof内部,也没有取地址,所以这个地方数组名就是首元素地址,代表第一行第一个元素的地址。所以a[0]+1就是第一行,第二个元素的地址。4/8
cout<<sizeof(*(a[0]+1))<<endl;//4
cout<<sizeof(a+1)<<endl;//数组名没有单独放到sizeof内部,也没有取地址,所以这个地方数组名就是首元素地址。二维数组的数组名,表示[首元素](第一行)的地址。+1就是第二行的地址。int (*)[4]。4/8
cout<<sizeof(*(a+1))<<endl;//*(a+1)就是第二行数组名。--16字节---等价于a[1]
cout<<sizeof(&a[0]+1)<<endl;//a[0]是第一行的数组名。&a[0]获的是第一行的地址,&a[0]+1就是第二行的地址。4/8
cout<<sizeof(*(&a[0]+1))<<endl;//第二行的数组名 16
//*(&a[0]+1) -- 第二行 -- a[1]
cout<<sizeof(*a)<<endl;//第一行的地址,*a第一行的数组名,16
cout<<sizeof(a[3])<<endl;//虽然没有第四行的数组名,但是sizeof()里面的表达式是不参加运算的。值属性和类属性。类型推导ok。不会报错也是16。
}
struct Test
{
int num;
char* pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
int main()
{
p=(struct Test*) 0x100000;
printf("%p\n",p+0x1);
printf("%p\n",(unsigned long)p+0x1);
printf("%p\n",(unsigned int*)p+0x1);
}
struct Test
{
int num;
char* pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
//假设p的值为0x100000。如下表表达式的值分别是多少?
//已知,结构体Test类型的变量大小是20个字节
int main()
{
//struct Test* --int
p=(struct Test*) 0x100000;
printf("%p\n",p+0x1);//0x00100014
printf("%p\n",(unsigned long)p+0x1);//指针转成整数了,00100001,以%p(十六进制打印)打印这个数
printf("%p\n",(unsigned int*)p+0x1);
}
int main()
{
int a[4] = {
1, 2, 3, 4 };
int *ptr1 = (int *)(&a + 1);
int *ptr2 = (int *)((int)a + 1);
printf( "%x,%x", ptr1[-1], *ptr2);
return 0;
}
//取出的是数组的地址,类型不匹配要强制类型转换
//4 2000000
//第二个是把地址变成int然后+1,强转成int*。然后读取4个字节的内容00 00 00 02.由于是小端法,高位字节在高位。此时假设左边低地址,右边高地址。注意这里2前面的0给省略了
int main()
{
int a[3][2]={
(0,1),(2,3),(4,5) };
int* p;
p=a[0];
printf("%d\n",p[0]);
}
int main()
{
int a[3][2]={
(0,1),(2,3),(4,5) }; //()是逗号表达式
int* p;
p=a[0];
printf("%d\n",p[0]);//4
}
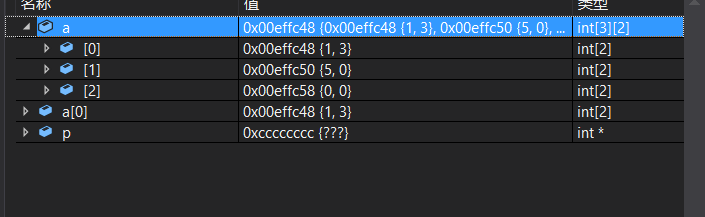
int main()
{
int a[5][5];
int(*p)[4];
p = (int (*)[4])a;
printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}
fffffffc,-4
由数组的内存模型可得-4,
负数在内存中以补码形式存储
int main()
{
int aa[2][5] = {
1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int *ptr1 = (int *)(&aa + 1);
int *ptr2 = (int *)(*(aa + 1));
printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}
&数组名 --》整个数组
10 5
前者int*指针指向10的位置。
后者int*指针指向5的位置。
#include <stdio.h>
int main()
{
char *a[] = {
"work","at","alibaba"};
char**pa = a;
pa++;
printf("%s\n", *pa);
return 0;
}
输出at。pa是指针,+1是4个字节,而a数组是存数组指针的,加了四个字节到第二个元素的地址。
int main()
{
char *c[] = {
"ENTER","NEW","POINT","FIRST"};
char**cp[] = {
c+3,c+2,c+1,c};
char***cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *--*++cpp+3);
printf("%s\n", *cpp[-2]+3);
printf("%s\n", cpp[-1][-1]+1);
return 0;
}
int main()
{
char* c[]={
"ENTER","NEW","POINT","FIRST"};
char** cp[]={
c+3,c+2,c+1,c};
char*** cpp=cp;
printf("%s\n",**++cpp); //POINT
printf("%s\n",*-- * ++cpp + 3); //ER
printf("%s\n",*cpp[-2] + 3); // ST
printf("%s\n",cpp[-1][-1] +1); //EW
}