各种字符编码的转换是个非常容易混淆的问题,这篇文章旨在梳理字符编码、常见字符集的基本概念,下一篇整理C++、python在不同应用中的代码实现。
字符编码
数字计算机中的存储器唯一可以存储的是比特(bit),因此如果要想在计算机上处理信息,就必须把它们按位存储。为了将文本表示为数字形式,我们需要构建一种系统来为每一个字母赋予一个唯一的编码。数字和标点符号也算做文本的一种形式,所以它们也必须拥有自己的编码。
所有由符号所表示的字母和数字(Alphanumeric)都需要编码。具有这种功能的系统被称为字符编码集(Coded Character Set),系统内的每个独立编码称为字符编码(Character Codes)。1
ASCII
所有人都遵循并使用统一化的字符编码,不同计算机之间就可以互相交流文本信息。
ASCII码就是一种被广泛使用的字符编码标准,它被称为美国信息交换标准码(American Standard Code for Information Interchange),简称为ASCII码,发音很像ASS-key。从1967年正式公布至今,它一直是计算机产业中最重要的标准。
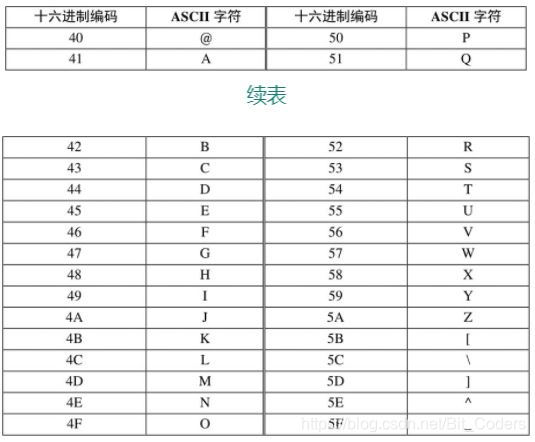
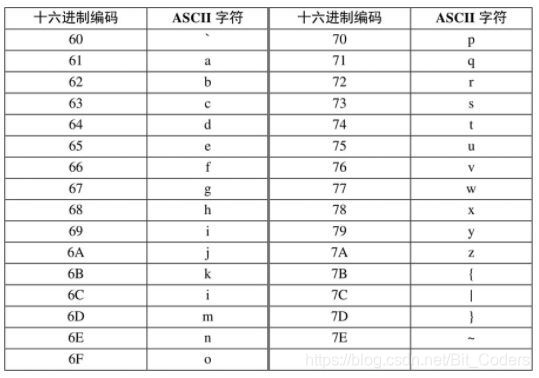
ASCII码是7位编码,它的二进制取值范围为0000000~1111111,对应于十六进制就是00h~7Fh,最多可以表示128个编码。下面具体展示一些常用字符及相应的十六进制编码。
数字和标点符号

大写字母+标点符号
小写字母+标点符号
像这样一段字符串:
Hello, you!
转换成ASCII码,用十六进制数表示如下:
48 65 6C 6F 2C 20 79 6F 75 21
在ASCII码中,一个大写字母与其对应的小写字母的ASCII码值相差20h。这种规律大大简化了程序代码的编写,例如一段将特定的字符串变成大写的程序。
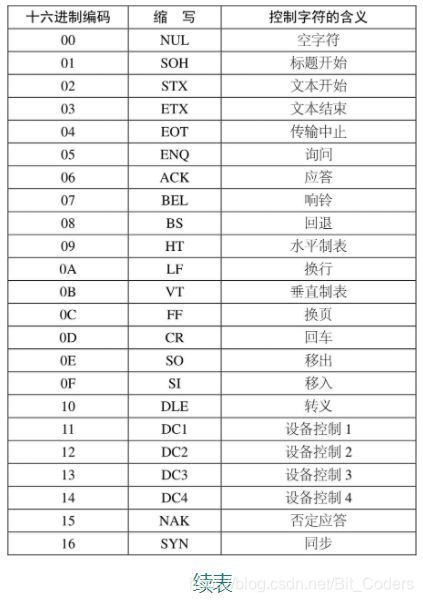
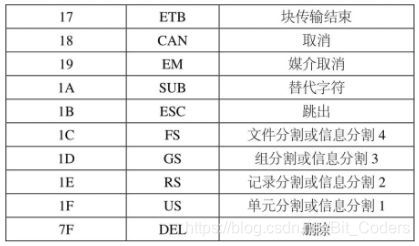
前面讲到的95个编码也被称为图形文字(graphic characters),因为它们可以被显示出来。其实ASCII码还包含33个控制字符(control characters),它们用来执行某一特定功能,因而不用显示出来。比如:
ASCII的局限性

简单的7位编码只适用于以英语为主的国家,在面对数以万计的中国、日本、韩国的象形文字,以及奇怪的朝鲜文音节等各国语言面前就不够用了。
为了应对各种语言的编码需求,近几十年来出现了许多不同版本的扩展的ASCII码,多个不同的版本严重影响了编码的一致性,导致了混淆和不兼容。其中通用的ASCII码字符,是用单个字节编码表示的,相比而言,成千上万的象形文字则是双字节编码,这在无形之中增加了使用这种字符集的难度。
Unicode
Unicode,统一码,也叫万国码,学名是"Universal Multiple-Octet Coded Character Set",简称为UCS。现在用的是UCS-2,即2个字节编码,而UCS-4是为了防止将来2个字节不够用才开发的。
相对于ASCII的7位编码,目前Unicode采用了16位编码,每一个字符需要2个字节。也就是说Unicode的字符编码范围为0000h~FFFFh,总共可以表示65,536个不同字符。全世界所有的人类语言,尤其是经常出现在计算机通信过程中的语言,都可以使用同一个编码系统,而且这种系统还具备很高的扩展性。
例如,采用ASCII编码方式存储的著作《怒火之花》,其所占据的存储空间约为1 MB。而如果采用Unicode编码,约占2 MB。为了使编码系统兼容,Unicode在存储空间上付出了相应的代价。
UTF-8
虽然Unicode字符集中的码位唯一,但由于计算机存储数据通常是以字节为单位的,而且出于兼容之前的ASCII、大数小段数段、节省存储空间等诸多原因,通常情况下,我们需要一种具体的编码方式来对字符码位进行存储。
比较常见的基于Unicode字符集的编码方式有UTF-8、UTF-16及UTF-32。2
以UTF-8为例,其采用了1~6字节的变长编码方式编码Unicode,英文通常使用1字节表示,且与ASCII是兼容的,而中文常用3字节进行表示。UTF-8编码由于较为节约存储空间,因此使用得比较广泛。下图所示就是UTF-8的编码方式。

现行桌面系统中,Windows内部采用了UTF-16的编码方式,而Mac OS、Linux等则采用了UTF-8编码方式。
GB2312
除了基于Unicode字符集的UTF-8、UTF-16等编码外,在中文语言地区,我们还有一些常见的字符集及其编码方式,GB2312、Big5就是其中影响最大、使用最广泛的两种。
GB2312的出现先于Unicode。早在20世纪80年代,GB2312作为简体中文的国家标准被颁布使用。GB2312字符集收入6763个汉字和682个非汉字图形字符,而在编码上,是采用了基于区位码的一种编码方式,采用2字节表示一个中文字符。GB2312在中国大陆地区及新加坡都有广泛的使用。
而BIG5则常见于繁体中文,俗称“大五码”。BIG5是长期以来的繁体中文的业界标准,共收录了13060个中文字,也采用了2字节的方式来表示繁体中文。BIG5在中国台湾、香港、澳门等地区有着广泛的使用。2
不同的编码方式对于相同的二进制字符串的解释是不同的。常见的,如果一个UTF-8编码的网页中的字符串按照GB2312编码进行显示,就会出现乱码。
而BIG5和GB2312之间的乱码则在中文地区软件中有着“悠久”的历史。不过随着Unicode的使用和发展,以及软件系统对多种编码的支持,程序发生乱码的现象也越来越少。
C++中的字符类型
C++提供了几种字符类型,其中多数支持国际化。基本的字符类型是char,一个char的空间应确保可以存放机器基本字符集中任意字符对应的数字值。也就是说,一个char的大小和一个机器字节一样。其他字符类型用于扩展字符集,如wchar_t、char16_t、char32_t。
wchar_t类型用于确保可以存放机器最大扩展字符集中的任意一个字符,类型char16_t和char32_t则为Unicode字符集服务(Unicode是用于表示所有自然语言中字符的标准)。
在Visual C++中,宽字符字符串表示为一个 wchar_t[] 数组并由 wchar_t* 指针指向它。 可以通过用字母 L 作为字符的前缀将任何 ASCII 字符表示为宽字符形式。 例如,L’\0’ 是终止宽(16 位)NULL 字符。3
用L前缀标识宽字符常量和字符串,用%lc和%ls显示宽字符数据4:
#include <wchar.h>
wchar_t wch = L'I';
wchar_t w_arr[20] = L"am wide!";
printf("%lc %ls\n",wch,w_arr);
C++11引入以下两种新的内置数据类型来存储不同编码长度的Unicode数据。
- char16_t:用于存储UTF-16编码的Unicode数据。
- char32_t:用于存储UTF-32编码的Unicode数据。
至于UTF-8编码的Unicode数据,C++11还是使用8字节宽度的char类型的数组来保存。而char16_t和char32_t的长度则犹如其名称所显示的那样,长度分别为16字节和32字节,对任何编译器或者系统都是一样的。
此外,C++11还定义了一些常量字符串的前缀。在声明常量字符串的时候,这些前缀声明可以让编译器使字符串按照前缀类型产生数据。事实上,C++11一共定义了3种这样的前缀:
- u8表示为UTF-8编码。
- u表示为UTF-16编码。
- U表示为UTF-32编码。
3种前缀对应于3种不同的Unicode编码。一旦声明了这些前缀,编译器会在产生代码的时候按照相应的编码方式存储。
以上3种前缀加上基于宽字符wchar_t的前缀“L”,及不加前缀的普通字符串字面量,算来在C++11中,一共有了5种方式来声明字符串字面量,其中4种是前缀表达的。2
python中的字符编码
在现代Python中(此处指Python 3.0及以上), Unicode成为字符串类型的一等类,用于更好地兼容处理ASCII和非ASCII文本。
在Python中,数字、英文、小数点、下划线和空格占一个字节;一个汉字可能会占2~4个字节,占几个字节取决于采用的编码。汉字在GBK/GB2312编码中占2个字节,在UTF-8/unicode中一般占用3个字节(或4个字节)。5
我们可以使用enocde方法将一个Unicode字符串转换为UTF-8字节6:
a = "hello"
b = "你好"
a_uft8 = a.encode('utf-8')
b_uft8 = b.encode('utf-8')
a_uft8输出:
b'hello'
b_uft8输出:
b'\xe4\xbd\xa0\xe5\xa5\xbd'
假设你知道一个字节对象的Unicode编码,你可以再使用decode方法进行解码:
a_uft8.decode('utf-8') #输出:'hello'
b_uft8.decode('utf-8') #输出:'你好'
小结
- ASCII简单的7位编码适用于以英语为主的国家。
- Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。
- UTF-8是一种常见的基于Unicode字符集的编码方式。
- GB2312是面向简体中文,BIG5是面向繁体中文。
- Unicode还在其发展期,Unicode、GB2312以及BIG5等多种编码共存的状况可能在以后较长的时间内都会持续下去。