引言
我们知道,如果将全连接的神经网络应用到图像上是非常困难的,因为如果是 1000x1000 像素的图片,参数量可能就上亿了。
我们能否能设计一种网络,可以减少我们的参数量。
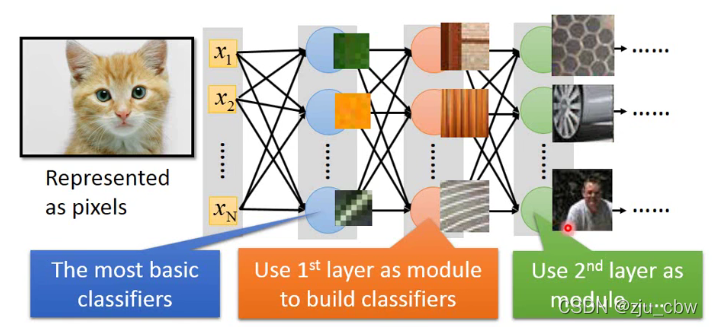
实际上,我们的眼睛是先找出图像的特征,再根据特征分辨图像到底是什么的,我们也可以设计网络去识别特征,再根据特征识别图像。如果可以这样,就能大大减少参数量,因为特征比整个图像小得多。
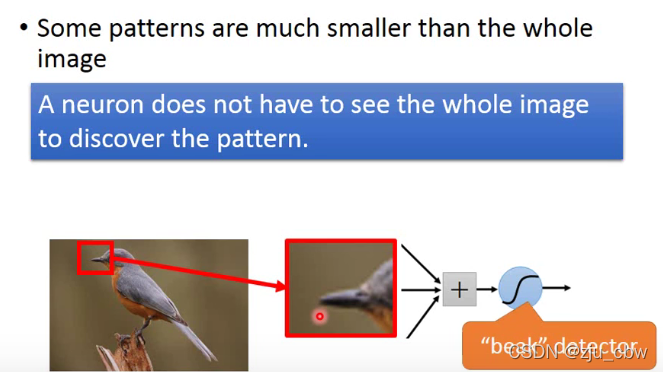
并且,无论这个特征出现在什么地方,我们都可以使用一个神经元来完成这个工作,这样就可以减少参数量。

图像还有个特点就是,假如我们把奇数像素点提取出来,而删去偶数像素点,其实对我们识别图像是没有什么太大的影响的。
CNN就是利用图像的这些特定来简化参数量的。
网络结构
CNN整个网络结构如下

Convolution 卷积层

卷积层简单来说就是通过多个卷积核(过滤器)来提取特征。
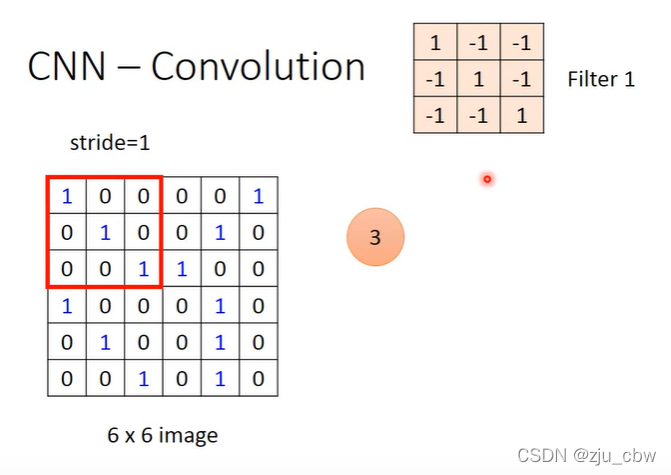
卷积过程就是设定一个 stride(步长),然后每次和过滤器内积完之后,移动 stride。
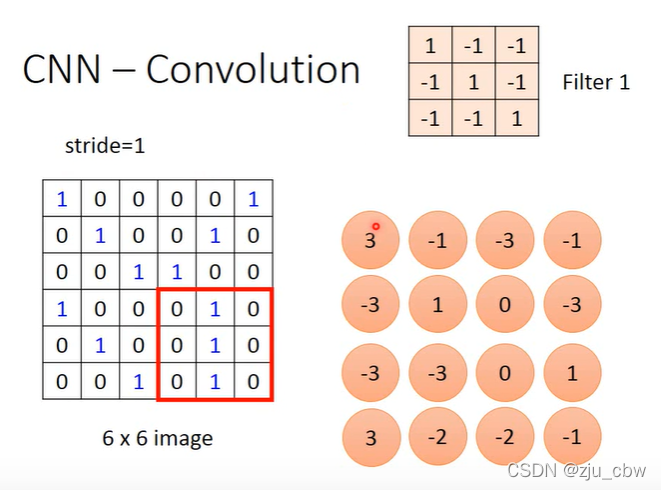
从下图可以看出,无论特征在哪,都可以通过一个过滤器提取出来。

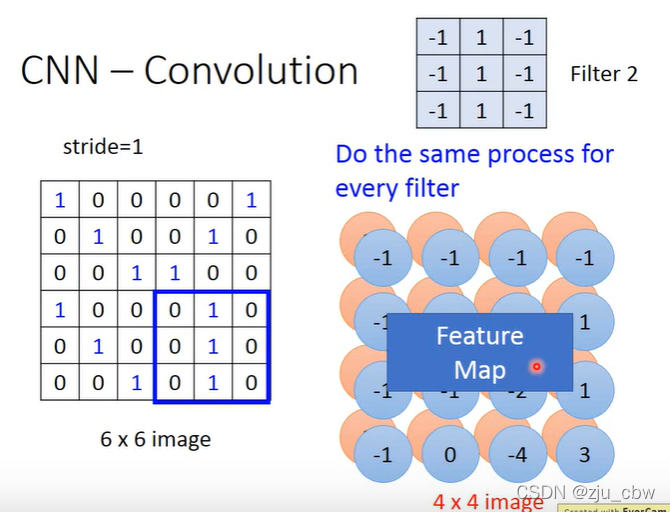
之后,每个过滤器重复上面的操作即可。
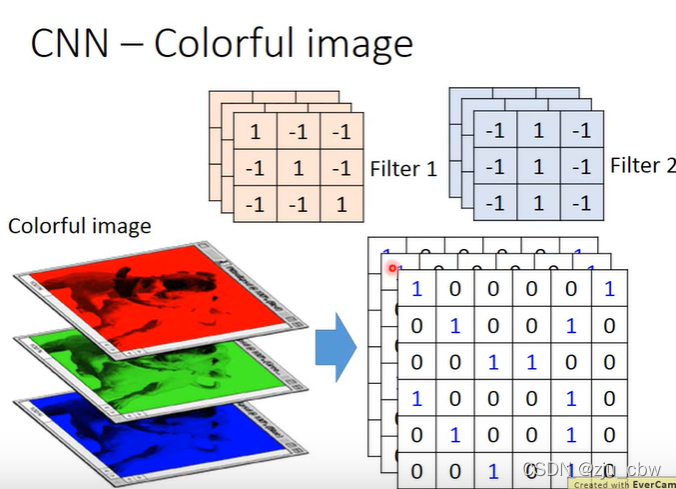
对于RGB图像,我们设计三层的过滤器即可。
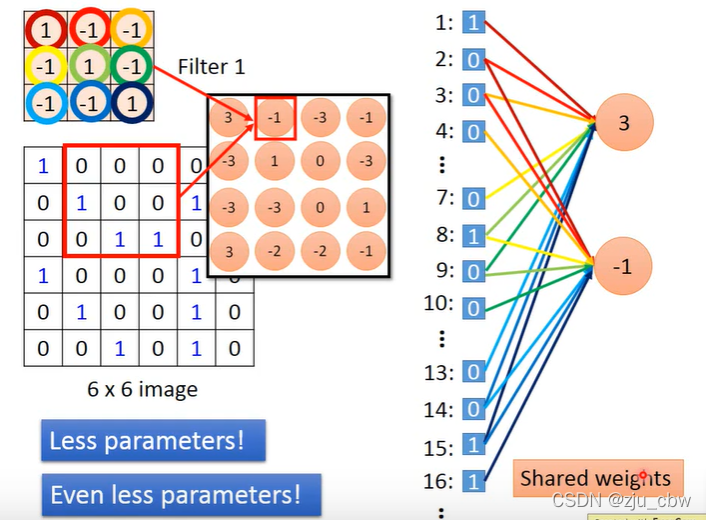
有人可能会有疑问,滤波器和神经元有什么关系,看着一点都不像啊?其实过滤器就是神经元。
如果我们将图像展平,是不是就和神经元的连接差不多了。
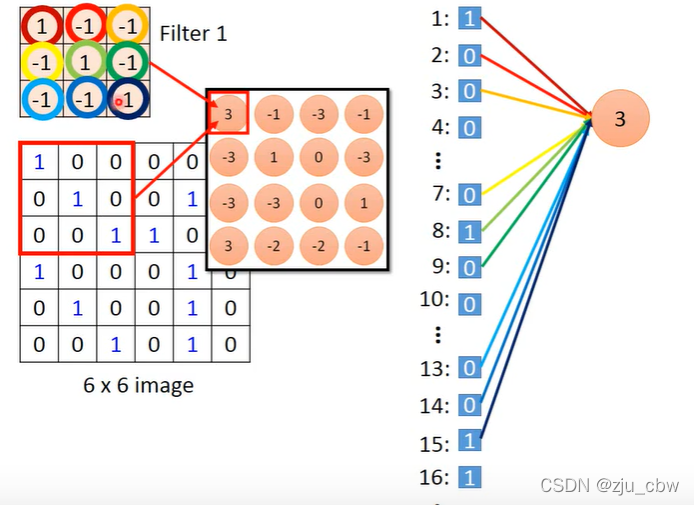
而且神经元和神经元之间还是权值共享的,这样做既可以省好多参数,还可以避免过拟合。
池化层
我们以最大池化为例。
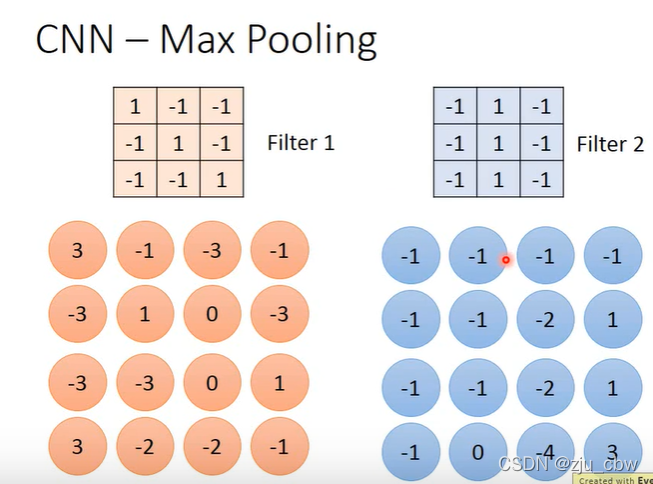
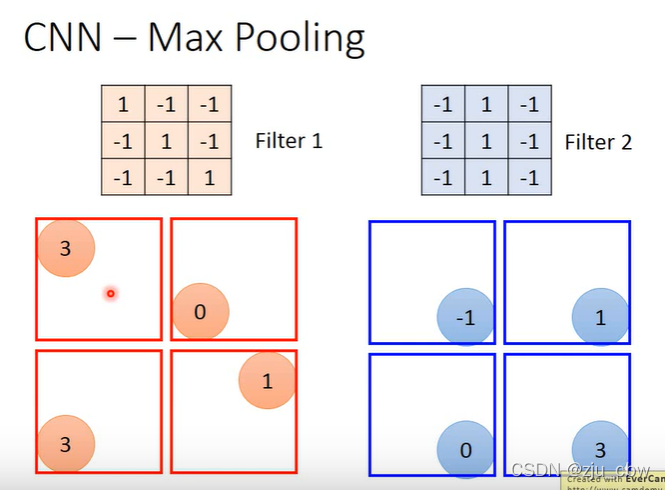
最大池化就是在卷积之后,从每个块中提取出最大的,这就和提取奇数像素点一样,即使少了这些像素也对我们识别图像产生不了太大影响,这既可以减少参数,也可以防止过拟合。
全连接层
我们在经过多次卷积池化这样操作后,需要将提取到的特征展平,放入全连接层。
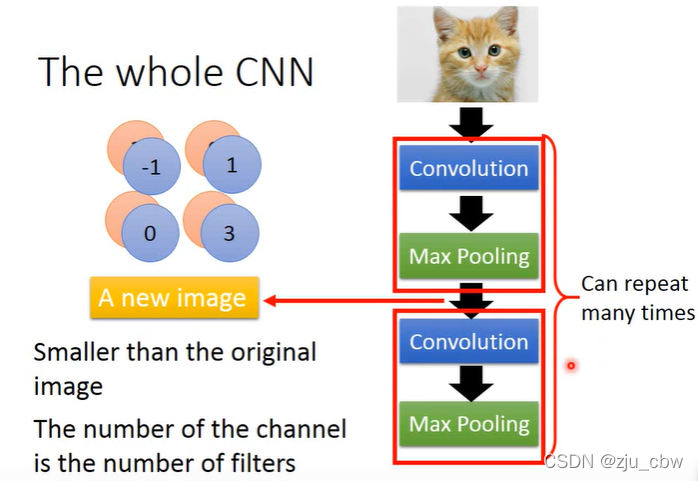
Flatten操作可以根据下面的图,很方便地理解。
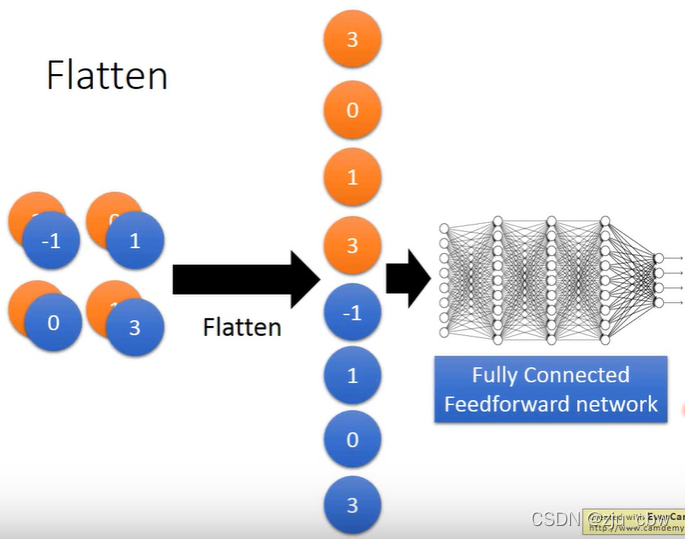
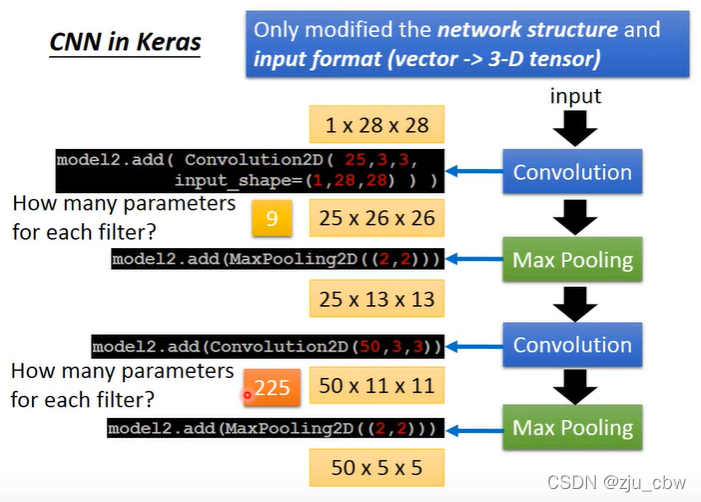
使用Keras设计CNN
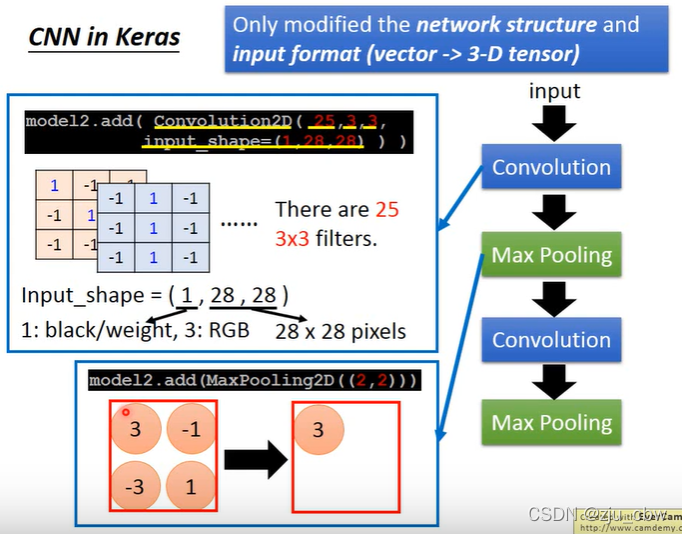
需要注意的是,从第二卷积层开始,每一个过滤器的深度都是上一层过滤器的个数。