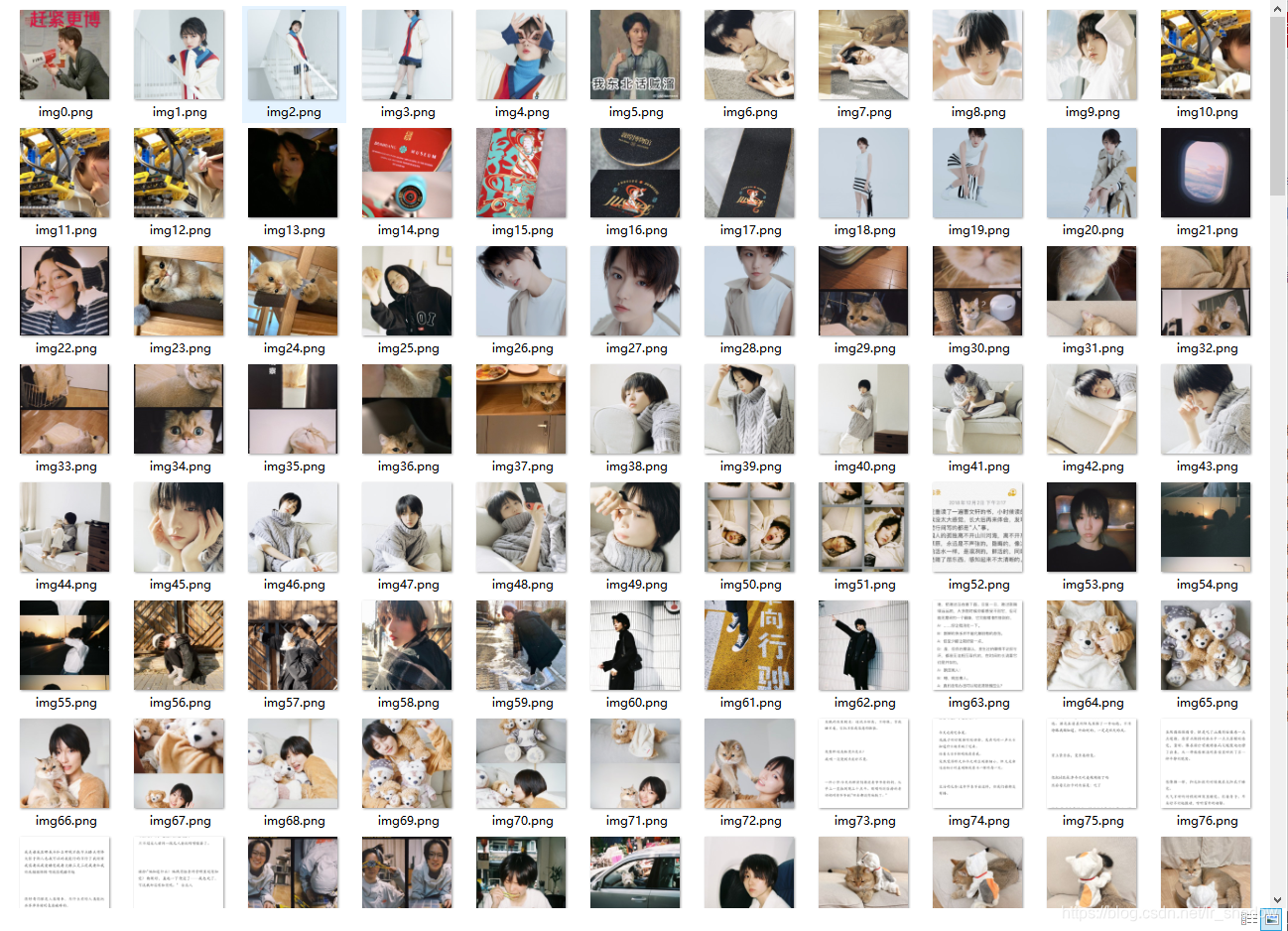
爬取成果微博相册图片
采用了显示等待以及selenium模仿模拟器登陆微博
狗哥男粉飘过~~
本文采用的是模仿谷歌浏览器,使用ConfigParser读取自己的账号密码,通过找网页的xpath路径找到节点并点击登陆,想爬取哪个明星直接在get中覆盖
有时有额外验证码验证或滑块验证码的bug出现,这个后续补上自动验证
import requests
from selenium import webdriver # 自动化工具
from configparser import ConfigParser
import time
import re
# 模仿浏览器 打开网址
driver = webdriver.Chrome()
driver.get("https://weibo.com/p/1005051927305954/photos?type=photo#_loginLayer_1579152333459")
driver.set_window_size(1200, 1000)
# 等待
driver.implicitly_wait(10)
time.sleep(3)
driver.find_element_by_link_text('登录').click()
target = ConfigParser()
target.read('password.ini', encoding='utf-8')
password = target.get('weibo', 'password')
driver.find_element_by_xpath("//div[@class = 'item username input_wrap']/input").send_keys()
driver.find_element_by_xpath("//div[@class = 'item password input_wrap']/input").send_keys(password)
driver.find_element_by_xpath("//div[@class = 'item verify']/../div[7]/a").click()
for i in range(25):
js = "var q = document.documentElement.scrollTop=" + str(i * 3000)
driver.execute_script(js) # 执行
time.sleep(3)
def get_picture_url():
page = driver.page_source
print(page)
pictures_url = re.findall(r'class="photo_pict" src="//(.*?)"', page, re.S)
num = 0
# 下载图片
for i in pictures_url:
picture_url = 'http://' + i
r = requests.get(picture_url)
with open('ChengGuo/img%d.png' % num, 'wb') as f:
f.write(r.content)
num += 1
get_picture_url()
# 解析数据
password.ini
[weibo]
username = "XXX"
password = XXX