因为Hive本身是Java开发的,所以我们可以使用Java定义函数供Hive SQL使用。
我们通过定义一个将输入字符串转换成反向输出的案例来探究UDF函数的自定义。
在Eclipse下以添加jar包形式开发:
需要:hadoop-common-3.2.0.jar (在hadoop安装文件中)、hive-exec-3.1.2.jar包(在hive安装文件中)
项目结构:
Java代码比较简单,实现一个字符串的反转输出:
package test1;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
@SuppressWarnings("deprecation")
public class RevertString extends UDF {
public Text evaluate(Text line) {
if (null != line && !line.toString().equals("")) {
String str = line.toString();
char[] rs = new char[str.length()];
for (int i = str.length() - 1; i >= 0; i--) {
rs[str.length() - 1 - i] = str.charAt(i);
}
line.set(new String(rs));
return line;
}
line.set("");
return line;
}
}
代码开发完毕后,只对该类打成jar包即可:
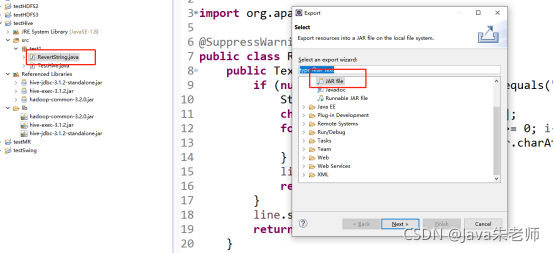
将jar包命名为testHive-e1.jar之后上传到linux虚拟机中:
在beeline中使用如下命令将jar添加到hive中:
add jar /apps/testHive-e1.jar;
定义函数,设置关联的Java类:
create temporary function my_revert_e1 as 'test1.RevertString';
测试:
select my_revert_e1('abc');
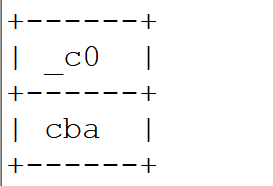
查看所有的已添加的jar:

查看所有的函数:
Show functions