会议:icassp 2021
作者:Kun Zhou,lihaizhou
文章目录
abstract
emotion vc是转换source中的情感韵律,不改变说话人和文本内容。之前的工作证明encoder-decoder结构可以在emotion label的标记下解耦情感信息;
本文提出一个 VAW-GAN: auto-encoding Wasserstein generative adversarial network,使用一个预先训练好的speech emotion recognition model提取emotion style,这样就可以进行seen和unseen的情感转换。
本文也发布了一个包含多语种,多说话人的情感数据库。
1. introduction
emotion-vc-id成功的尝试了VAW-GAN + emotion id(one-hot)进行风格控制,但是只用id表示情绪风格过于单一,因为情绪是由多种因素共同影响的。
2. Analysis of Deep Emotional Features
Emotional prosody 可以用离散的标签表示:比如Ekmans’s 六类基本情绪,也可以用连续的向量表示:Russell’s circumplex model;
本文用连续的空间表示情绪,可以完成one-to-many的情感控制;
- 挑了四个人(2男2女)相同内容、不同情绪的句子提取deep emotional features,画tsne图,可以看到各个情绪类之间有明显的区别;
3. ONE-TO-MANY Emotional style transfer
3.1. StageI : Emotion Descriptor Training
使用一个nn对输入的句子进行情感分类,提取出句子级的向量表示;
Φ = D ( X ) \Phi = D(X) Φ=D(X)
3.2. Stage II: Encoder-Decoder Training with VAW-GAN

-emotion style:是reference set的向量均值;
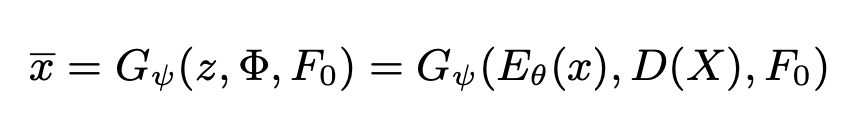
4. experiment & results
- demo效果听起来和baseline的区别不大,neural-to-angry的情绪更好一些;
