How SKBs work![]() http://vger.kernel.org/~davem/skb_data.html
http://vger.kernel.org/~davem/skb_data.html
How SKBs work![]() http://vger.kernel.org/~davem/skb.html
http://vger.kernel.org/~davem/skb.html
The socket buffer, or "SKB", is the most fundamental data structure in the Linux networking code. Every packet sent or received is handled using this data structure.
The most fundamental parts of the SKB structure are as follows:
struct sk_buff {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
struct sk_buff_head *list;
...
The first two members implement list handling. Packets can exist on several kinds of lists and queues. For example, a TCP socket send queue. The third member says which list the packet is on. Learn more about SKB list handling here.
struct sock *sk;
This is where we record the socket assosciated with this SKB. When a packet is sent or received for a socket, the memory assosciated with the packet must be charged to the socket for proper memory accounting. Read more about socket packet buffer memory accounting here.
struct timeval stamp;
Here we record the timestamp for the packet, either when it arrived or when it was sent. Calculating this is somewhat expensive, so this value is only recorded if necessary. When something happens that requires that we start recording timestamps, net_enable_timestamp() is called. If that need goes away, net_disable_timestamp() is called.
Timestamps are mostly used to packet sniffers. But they are also used to implement certain socket options, and also some netfilter modules make use of this value as well.
struct net_device *dev; struct net_device *input_dev; struct net_device *real_dev;
These three members help keep track of the devices assosciated with a packet. The reason we have three different device pointers is that the main 'skb->dev' member can change as we encapsulate and decapsulate via a virtual device.
So if we are receiving a packet from a device which is part of a bonding device instance, initially 'skb->dev' will be set to point the real underlying bonding slave. When the packet enters the networking (via 'netif_receive_skb()') we save 'skb->dev' away in 'skb->real_dev' and update 'skb->dev' to point to the bonding device.
Likewise, the physical device receiving a packet always records itself in 'skb->input_dev'. In this way, no matter how many layers of virtual devices end up being decapsulated, 'skb->input_dev' can always be used to find the top-level device that actually received this packet from the network.
union {
struct tcphdr *th;
struct udphdr *uh;
struct icmphdr *icmph;
struct igmphdr *igmph;
struct iphdr *ipiph;
struct ipv6hdr *ipv6h;
unsigned char *raw;
} h;
union {
struct iphdr *iph;
struct ipv6hdr *ipv6h;
struct arphdr *arph;
unsigned char *raw;
} nh;
union {
unsigned char *raw;
} mac;
Here we store the location of the various protocol layer headers as we build outgoing packets, and parse incoming ones. For example, 'skb->mac.raw' is set by 'eth_type_trans()', when an eternet packet is received. Later, we can use this to find the location of the MAC header.
These members are potentially redundant, and could be removed. Read a discussion about that here.
struct dst_entry *dst;
This member is the generic route for the packet. It tells us how to get the packet to it's destination. Note that routes are used for both input and output. DST entries are about as complex as SKBs are, and thus probably deserve their own tutorial.
struct sec_path *sp;
Here we store the security path traversed by the packet, if any. For example, on input IPSEC records each transformation which has been applied to the packet by a decapsulator. The records are an array of 'struct sec_decap_state' which each record the security assosciation that matched and got applied. Later, when we are trying to validate the security policy against a packet, we make sure that the transformations applied match the ones allowed by the policy.
char cb[40];
This is the SKB control block. It is an opaque storage area usable by protocols, and even some drivers, to store private per-packet information. TCP uses this, for example, to store sequence numbers and retransmission state for the frame.
unsigned int len, data_len, mac_len, csum;
The three length members are pretty straight-forward. The total number of bytes in the packet is 'len'. SKBs are composed of a linear data buffer, and optionally a set of 1 or more page buffers. If there are page buffers, the total number of bytes in the page buffer area is 'data_len'. Therefore the number of bytes in the linear buffer is 'skb->len - skb->data_len'. There is a shorthand function for this in 'skb_headlen()'.
static inline unsigned int skb_headlen(const struct sk_buff *skb)
{
return skb->len - skb->data_len;
}
The 'mac_len' holds the length of the MAC header. Normally, this isn't really necessary to maintain, except to implement IPSEC decapsulation of IP tunnels properly. This field is initialized once inside of 'netif_receive_skb()' to the formula 'skb->nh.raw - skb->mac.raw'.
Since we only use this for one purpose, with some clever ideas we may be able to eliminate this member in the future. For example, perhaps we can store the value in the 'struct sec_path'.
Finally, 'csum' holds the checksum of the packet. When building send packets, we copy the data in from userspace and calculate the 16-bit two's complement sum in parallel for performance. This sum is accumulated in 'skb->csum'. This helps us compute the final checksum stored in the protocol packet header checksum field. This field can end up being ignored if, for example, the device will checksum the packet for us.
On input, the 'csum' field can be used to store a checksum calculated by the device. If the device indicates 'CHECKSUM_HW' in the SKB 'ip_summed' field, this means that 'csum' is the two's complement checksum of the entire packet data area starting at 'skb->data'. This is generic enough such that both IPV4 and IPV6 checksum offloading can be supported.
unsigned char local_df, cloned:1, nohdr:1, pkt_type, ip_summed;
The 'local_df' field is used by the IPV4 protocol, and when set allows us to locally fragment frames which have already been fragmented. This situation can arise, for example, with IPSEC.
In order to make quick references to SKB data, Linux has the concept of SKB clones. When a clone of an SKB is made, all of the 'struct sk_buff' structure members of the clone are private to the clone. The data, however, is shared between the primary SKB and it's clone. When an SKB is cloned, the 'cloned' field will be set in both the primary and clone SKB. Otherwise is will be zero.
The 'nohdr' field is used in the support of TCP Segmentation Offload ('TSO' for short). Most devices supporting this feature need to make some minor modifications to the TCP and IP headers of an outgoing packet to get it in the right form for the hardware to process. We do not want these modifications to be seen by packet sniffers and the like. So we use this 'nohdr' field and a special bit in the data area reference count to keep track of whether the device needs to replace the data area before making the packet header modifications.
The type of the packet (basically, who is it for), is stored in the 'pkt_type' field. It takes on one of the 'PACKET_*' values defined in the 'linux/if_packet.h' header file. For example, when an incoming ethernet frame is to a destination MAC address matching the MAC address of the ethernet device it arrived on, this field will be set to 'PACKET_HOST'. When a broadcast frame is received, it will be set to 'PACKET_BROADCAST'. And likewise when a multicast packet is received it will be set to 'PACKET_MULTICAST'.
The 'ip_summed' field describes what kind of checksumming assistence the card has provided for a receive packet. It takes on one of three values: 'CHECKSUM_NONE' if the card provided no checksum assistence, 'CHECKSUM_HW' if the two's complement checksum over the entire packet has been provides in 'skb->csum', and 'CHECKSUM_UNNECESSARY' if it is not necessary to verify the checksum of this packet. The latter usually occurs when the packet is received over the loopback device. 'CHECKSUM_UNNECESSARY' can also be used when the device only provides a 'checksum OK' indication for receive packet checksum offload.
__u32 priority;
The 'priority' field is used in the implement of QoS. The packet's value of this field can be determined by, for example, the TOS field setting in the IPV4 header. Then, the packet scheduler and classifier layer can key off of this SKB priority value to schedule or classify the packet, as configured by the administrator.
unsigned short protocol, security;
The 'protocol' field is initialized by routines such as 'eth_type_trans()'. It takes on one of the 'ETH_P_*' values defined in the 'linux/if_ether.h' header file. Even non-ethernet devices use these ethernet protocol type values to indicate what protocol should receive the packet. As long as we always have some ethernet protocol value for each and every protocol, this should not be a problem.
The 'security' field was meant to be used in the implementation of IP Security, but that never materialized. It can probably be safely removed. Since the next field is a pointer, and thus needs to be aligned properly, eliminating the 'security' field would unfortunately not buy us any space savings.
void (*destructor)(struct sk_buff *skb); ... unsigned int truesize;
The SKB 'destructor' and 'truesize' fields are used for socket buffer accounting. See the SKB socket accounting page for details.
atomic_t users;
We reference count SKB objects using the 'users' field. Extra references can be obtained by invoking 'skb_get()'. An implicit single reference is present in the SKB (that is, 'users' has a value of '1') when it is first allocated. References are dropped by invoking 'kfree_skb()'.
unsigned char *head, *data, *tail, *end;
These four pointers provide the core management of the linear packet data area of an SKB. SKB data area handling is involved enough to deserve it's very own tutorial. Check it out here.
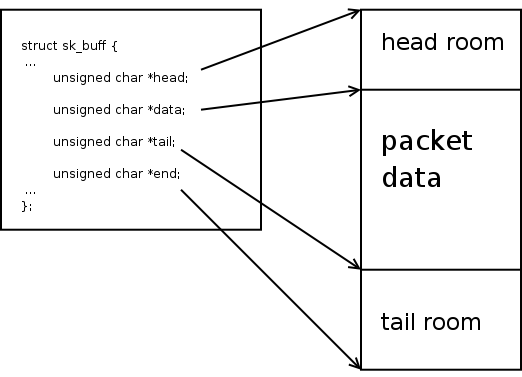
This first diagram illustrates the layout of the SKB data area and where in that area the various pointers in 'struct sk_buff' point.
The rest of this page will walk through what the SKB data area looks like in a newly allocated SKB. How to modify those pointers to add headers, add user data, and pop headers.
Also, we will discuss how page non-linear data areas are implemented. We will also discuss how to work with them.
skb = alloc_skb(len, GFP_KERNEL);
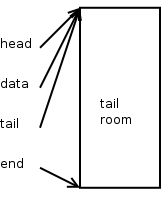
This is what a new SKB looks like right after you allocate it using alloc_skb()
As you can see, the head, data, and tail pointers all point to the beginning of the data buffer. And the end pointer points to the end of it. Note that all of the data area is considered tail room.
The length of this SKB is zero, it isn't very interesting since it doesn't contain any packet data at all. Let's reserve some space for protocol headers using skb_reserve()
skb_reserve(skb, header_len);
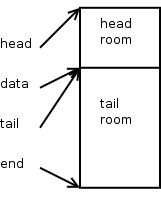
This is what a new SKB looks like right after the skb_reserve() call.
Typically, when building output packets, we reserve enough bytes for the maximum amount of header space we think we'll need. Most IPV4 protocols can do this by using the socket value sk->sk_prot->max_header.
When setting up receive packets that an ethernet device will DMA into, we typically call skb_reserve(skb, NET_IP_ALIGN). By default NET_IP_ALIGN is defined to '2'. This makes it so that, after the ethernet header, the protocol header will be aligned on at least a 4-byte boundary. Nearly all of the IPV4 and IPV6 protocol processing assumes that the headers are properly aligned.
Let's now add some user data to the packet.
unsigned char *data = skb_put(skb, user_data_len); int err = 0; skb->csum = csum_and_copy_from_user(user_pointer, data, user_data_len, 0, &err); if (err) goto user_fault;
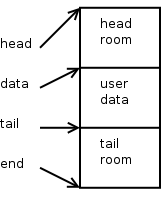
This is what a new SKB looks like right after the user data is added.
skb_put() advances 'skb->tail' by the specified number of bytes, it also increments 'skb->len' by that number of bytes as well. This routine must not be called on a SKB that has any paged data. You must also be sure that there is enough tail room in the SKB for the amount of bytes you are trying to put. Both of these conditions are checked for by skb_put() and an assertion failure will trigger if either rule is violated.
The computed checksum is remembered in 'skb->csum'. Now, it's time to build the protocol headers. We'll build a UDP header, then one for IPV4.
struct inet_sock *inet = inet_sk(sk); struct flowi *fl = &inet->cork.fl; struct udphdr *uh; skb->h.raw = skb_push(skb, sizeof(struct udphdr)); uh = skb->h.uh uh->source = fl->fl_ip_sport; uh->dest = fl->fl_ip_dport; uh->len = htons(user_data_len); uh->check = 0; skb->csum = csum_partial((char *)uh, sizeof(struct udphdr), skb->csum); uh->check = csum_tcpudp_magic(fl->fl4_src, fl->fl4_dst, user_data_len, IPPROTO_UDP, skb->csum); if (uh->check == 0) uh->check = -1;
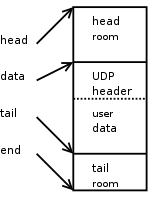
This is what a new SKB looks like after we push the UDP header to the front of the SKB.
skb_push() will decrement the 'skb->data' pointer by the specified number of bytes. It will also increment 'skb->len' by that number of bytes as well. The caller must make sure there is enough head room for the push being performed. This condition is checked for by skb_push() and an assertion failure will trigger if this rule is violated.
Now, it's time to tack on an IPV4 header.
struct rtable *rt = inet->cork.rt; struct iphdr *iph; skb->nh.raw = skb_push(skb, sizeof(struct iphdr)); iph = skb->nh.iph; iph->version = 4; iph->ihl = 5; iph->tos = inet->tos; iph->tot_len = htons(skb->len); iph->frag_off = 0; iph->id = htons(inet->id++); iph->ttl = ip_select_ttl(inet, &rt->u.dst); iph->protocol = sk->sk_protocol; /* IPPROTO_UDP in this case */ iph->saddr = rt->rt_src; iph->daddr = rt->rt_dst; ip_send_check(iph); skb->priority = sk->sk_priority; skb->dst = dst_clone(&rt->u.dst);
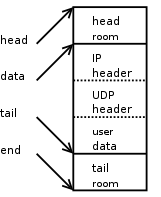
This is what a new SKB looks like after we push the IPv4 header to the front of the SKB.
Just as above for UDP, skb_push() decrements 'skb->data' and increments 'skb->len'. We update the 'skb->nh.raw' pointer to the beginning of the new space, and build the IPv4 header.
This packet is basically ready to be pushed out to the device once we have the necessary information to build the ethernet header (from the generic neighbour layer and ARP).
Things start to get a little bit more complicated once paged data begins to be used. For the most part the ability to use [page, offset, len] tuples for SKB data came about so that file system file contents could be directly sent over a socket. But, as it turns out, it is sometimes beneficial to use this for nomal buffering of process sendmsg() data.
It must be understood that once paged data starts to be used on an SKB, this puts a specific restriction on all future SKB data area operations. In particular, it is no longer possible to do skb_put() operations.
We will now mention that there are actually two length variables assosciated with an SKB, len and data_len. The latter only comes into play when there is paged data in the SKB. skb->data_len tells how many bytes of paged data there are in the SKB. From this we can derive a few more things:
- The existence of paged data in an SKB is indicated by skb->data_len being non-zero. This is codified in the helper routine skb_is_nonlinear() so that it the function you should use to test this.
- The amount of non-paged data at skb->data can be calculated as skb->len - skb->data_len. Again, there is a helper routine already defined for this called skb_headlen() so please use that.
The main abstraction is that, when there is paged data, the packet begins at skb->data for skb_headlen(skb) bytes, then continues on into the paged data area for skb->data_len bytes. That is why it is illogical to try and do an skb_put(skb) when there is paged data. You have to add data onto the end of the paged data area instead.
Each chunk of paged data in an SKB is described by the following structure:
struct skb_frag_struct {
struct page *page;
__u16 page_offset;
__u16 size;
};
There is a pointer to the page (which you must hold a proper reference to), the offset within the page where this chunk of paged data starts, and how many bytes are there.
The paged frags are organized into an array in the shared SKB area, defined by this structure:
#define MAX_SKB_FRAGS (65536/PAGE_SIZE + 2)
struct skb_shared_info {
atomic_t dataref;
unsigned int nr_frags;
unsigned short tso_size;
unsigned short tso_segs;
struct sk_buff *frag_list;
skb_frag_t frags[MAX_SKB_FRAGS];
};
The nr_frags member states how many frags there are active in the frags[] array. The tso_size and tso_segs is used to convey information to the device driver for TCP segmentation offload. The frag_list is used to maintain a chain of SKBs organized for fragmentation purposes, it is _not_ used for maintaining paged data. And finally the frags[] holds the frag descriptors themselves.
A helper routine is available to help you fill in page descriptors.
void skb_fill_page_desc(struct sk_buff *skb, int i, struct page *page, int off, int size)
This fills the i'th page vector to point to page at offset off of size size. It also updates the nr_frags member to be one past i.
If you wish to simply extend an existing frag entry by some number of bytes, increment the size member by that amount.
With all of the complications imposed by non-linear SKBs, it may seem difficult to inspect areas of a packet in a straightforward way, or to copy data out from a packet into another buffer. This is not the case. There are two helper routines available which make this pretty easy.
First, we have:
void *skb_header_pointer(const struct sk_buff *skb, int offset, int len, void *buffer)
You give it the SKB, the offset (in bytes) to the piece of data you are interested in, the number of bytes you want, and a local buffer which is to be used _only_ if the data you are interested in resides in the non-linear data area.
You are returned a pointer to the data item, or NULL if you asked for an invalid offset and len parameter. This pointer could be one of two things. First, if what you asked for is directly in the skb->data linear data area, you are given a direct pointer into there. Else, you are given the buffer pointer you passed in.
Code inspecting packet headers on the output path, especially, should use this routine to read and interpret protocol headers. The netfilter layer uses this function heavily.
For larger pieces of data other than protocol headers, it may be more appropriate to use the following helper routine instead.
int skb_copy_bits(const struct sk_buff *skb, int offset, void *to, int len);
This will copy the specified number of bytes, and the specified offset, of the given SKB into the 'to'buffer. This is used for copies of SKB data into kernel buffers, and therefore it is not to be used for copying SKB data into userspace. There is another helper routine for that:
int skb_copy_datagram_iovec(const struct sk_buff *from, int offset, struct iovec *to, int size);
Here, the user's data area is described by the given IOVEC. The other parameters are nearly identical to those passed in to skb_copy_bits() above.
As we trim the SKB, this page will keep track of the size and layout of this structure. This is done for a 64-bit architecture, structure offsets are in the first column.
struct sk_buff {
0x00 struct sk_buff *next;
0x08 struct sk_buff *prev;
0x10 struct sock *sk;
0x18 struct timeval stamp;
0x28 struct net_device *dev;
0x30 struct net_device *input_dev;
union {
struct tcphdr *th;
struct udphdr *uh;
struct icmphdr *icmph;
struct igmphdr *igmph;
struct iphdr *ipiph;
struct ipv6hdr *ipv6h;
unsigned char *raw;
0x38 } h;
union {
struct iphdr *iph;
struct ipv6hdr *ipv6h;
struct arphdr *arph;
unsigned char *raw;
0x40 } nh;
union {
unsigned char *raw;
0x48 } mac;
0x50 struct dst_entry *dst;
0x58 struct sec_path *sp;
0x60 char cb[40];
0x88 unsigned int len,
0x8c data_len,
0x90 mac_len,
0x94 csum;
0x98 __u32 priority;
0x9c __u8 local_df:1,
cloned:1,
ip_summed:2,
nohdr:1,
nfctinfo:3;
0x9d __u8 pkt_type;
0x9e __u16 protocol;
0xa0 void (*destructor)(struct sk_buff *skb);
0xa8 __u32 nfmark;
0xb0 struct nf_conntrack *nfct;
0xb8 __u8 ipvs_property:1;
0xc0 struct nf_bridge_info *nf_bridge;
0xc8 __u16 tc_index;
0xca __u16 tc_verd;
0xcc unsigned int truesize;
0xd0 atomic_t users;
0xd8 unsigned char *head,
0xe0 *data,
0xe8 *tail,
0xf0 *end;
};