文章目录
进程创建
fork函数
fork函数,可以从已存在的进程中创建一个新进程。
pid_t fork(void); //包含于<unistd.h>
· fork函数的返回值
给子进程返回0;
给父进程返回子进程的pid;
fork调用数百返回-1;
· fork函数创建子进程的过程
- OS为子进程开辟空间并创建task_struct结构体
- OS为子进程创建进程地址空间mm_struct和页表
- OS将父进程的部分数据拷入到子进程当中,并修改页表当中的映射关系
- OS将子进程添加到系统中的进程列表中
- fork函数进行返回
int main()
{
pid_t id;
id = fork();
if(id == 0) //fork返回值为0的就是子进程
{
//Child
printf("Child Process!!!\n");
sleep(3);
exit(1); //子进程强制退出,后面我会说
}
else //fork返回值不为0的就是父进程
{
//Father
printf("Father Process\n");
}
wait(NULL); //等待子进程(我后面会说)
return 0;
}
小细节:
问题:fork函数为什么会有2个返回值呢?
我刚才讲述了fork函数创建子进程的过程,在第5步的时候,fork函数其实还没有结束调用,此时子进程已经被创建出来了,因此在返回的时候,会进行2次返回值的返回。
进程创建与写时拷贝
我们先来看一下下面的这段代码!
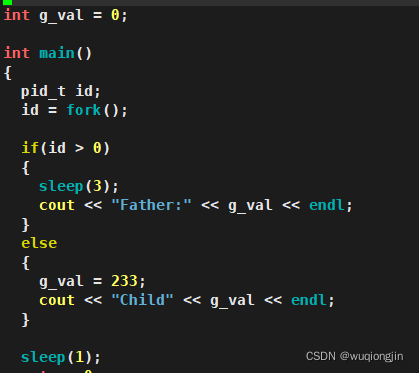
我们在里面定义了一个全局变量g_val,在创建子进程后,父子进程分别对g_val进行打印,但是子进程打印之前先对g_val进行了修改。为了确保子进程先运行,我们让父进程先sleep(3),大家可以猜一下运行的结果!

这个运行的结果是不是很奇怪?子进程先修改了g_val,父进程再打印g_val的时候竟然是没修改之前的。那么这个g_val可不可能其实是2个变量?我们可以打印一下它们的地址看看。

?很奇怪吧,为什么地址都是一样的,值不一样呢?
解释:
这里就不卖关子了,直接给出解释。首先,我们要知道进程运行时是具有独立性的!所以子进程修改g_val是不可能会影响父进程的。
其次,这里实际上采用了写时拷贝的方法,子进程在对g_val进行修改的同时,OS为其重新开辟了一块空间,让修改的值放到了新的空间当中,并且修改页表的映射关系,让进程地址空间中的地址指向到新的空间当中!这样就导致了子进程和父进程打印的地址虽然是一样的,但是其实对应到物理内存当中的地址是不同的!我现在描述的这个过程就是写时拷贝的过程!
写时拷贝
问题:什么是写时拷贝?
写时拷贝(copy-on-write)就是"写的时候才分配内存空间",这是对程序性能的优化的一种方案,可以延迟甚至是避免内存拷贝。
问题:为什么要进行写时拷贝?
①:进程具有独立性!对于父子进程也是如此。
②:子进程不一定会修改父进程的数据,它只有在需要的时候才会进行写入。
这是一种 按需分配、延迟分配 的思路。可以更高效的使用内存空间。
进程终止
· 进程终止的三种情况
1. 代码运行完毕,结果正确
2. 代码运行完毕,结果不正确
3. 代码异常终止
注意:
前两种是属于正常终止,最后一种是异常终止。
问题:main函数的返回值给了谁?
操作系统
问题:为什么main函数要有返回值?
因为要给用户看到这个进程运行完后完成的结果。(检查作业完成情况?hh)
进程的退出码
main函数的返回值实际上就是:进程的退出码
进程的退出码: 在task_struct中有一个变量叫exit_code就是用来存储退出码的值的。
进程的退出码分为:
0:正常退出
!0:运行结果不正确的退出
退出码相关的指令
echo $? #在命令行中打印最近一次的进程退出码
strerror() #打印退出码对应的相信信息描述
#关于子进程退出时退出码的获取我会在后面(进程等待处说)
进程正常终止的3种方式
| 退出方式 | 是否刷新缓冲区 | 结束进程的函数作用域 |
|---|---|---|
| return (在main中的) | 刷新 | 只有在main函数中的return才会结束进程, 在其它函数中只会结束当前函数 |
| exit | 刷新 | 任何函数中 |
| _exit | 不刷新 | 任何函数中 |
exit与_exit
void exit(int status); //这里的status参数就是进程的退出码
void _exit(int status);
exit函数会先去调用_exit函数,但是在调用_exit函数之前,它还会去做:
- 执行用户通过atexit或on_exit所定义的清理函数
- 关闭所有打开的流,所有的缓存数据均被写入
- 最终调用_exit
进程的异常终止
进程异常终止,那么退出码就没有任何意义了!
进程异常终止一般都是通过发送信号给该进程,从而让该进程异常终止。
信号的发送者有很多:可以是自己发送给自己,也可以是别人发送信号给当前进程,或者是OS系统发送信号终止该进程。
我这里举几个信号相关的例子,关于信号更详细的讲解我将放在后面的博客当中。
SIGINT #使用组合键ctrl + c就可以发送,作用是让当前进程终止
SIGQUIT #使用组合键ctrl + \就可以发送,作用是让当前进程退出
SIGSTP #使用组合键ctrl + z就可以发送,作用是暂停当前进程
操作系统在进程终止时都做了哪些操作?
- 释放进程加载到内存当中的代码和数据
- 释放曾经向内存申请的数据结构, 如task_struct、mm_struct和页表
- 从各种队列当中移除该进程
进程等待
问题:为什么需要进程等待?
如果不进行进程等待,那么可能会导致子进程变成僵尸进程,僵尸进程的危害可以看(这里)
父进程可以通过进程等待的方式,去回收子进程的资源以及获取子进程的退出信息。
进程等待的方法
wait方法
pit_t wait (int* status); // 包含于#include <sys/types.h> #include <sys/wait.h>
返回值:
成功wait,返回被等待进程的pid
失败,返回 -1
参数:
输出型参数,获取进程退出状态,不关心可以设置成NULL
waitpid方法
pit_t waitpid (pit_t pid, int* status, int options);
返回值:
①:成功wait,返回被等待进程的pid
②:失败(调用出错),返回-1。//这时候errno会被设置成相应的值,去指示错误所在
③:WNOHANG被设置,在调用时没有等到子进程时,返回0。等待到子进程返回子进程pid
参数:
pid:
pid = -1;代表等待任何一个进程。此时与pid等效
pid > 0;等待子进程的pid与这里参数的id相同的子进程 //等相同pid的子进程
status:
传的参数依然是 int status = 0; //和pid的参数status使用方法相同
options:#控制进程是否 阻塞等待 还是非阻塞等待
0:代表使用 阻塞等待的方式,挨个挨个 子进程去等待,等待期间不会做任何事情。
WNOHANG:进行非阻塞等待。若未等到子进程,继续执行下面的代码,此时waitpid的返回值为0。 若等到子进程,则waitpid的返回值为子进程的pid
· status参数详解 //wait和waitpid中的status是一样的
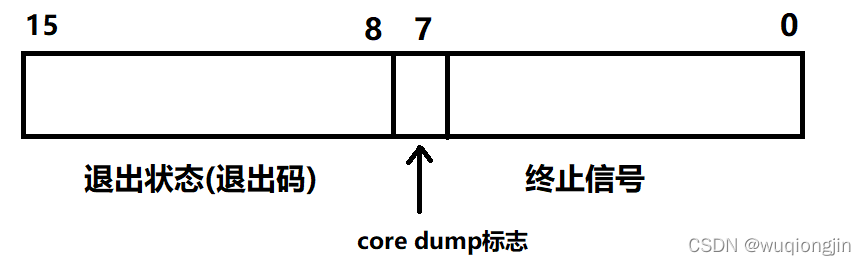
status是个输出型参数,由操作系统填充。
操作系统将整形int的status分为3个部分取使用:
#低7位、第8位、次低8位
#下面的是数字按照距离第最低位的距离进行表示的
0 ~ 6 比特位:存放信号
7:core dump (核心转储)
8 ~ 15 比特位:存放退出码
更简单的判断方法(宏):(用的多)
WIFEXITED (status): #判断进程是否正常/异常终止
判断子进程是否正常/异常终止。正常返回:返回值true。异常返回:返回值false
WEXITSTATUS (status): #返回子进程的退出码(在进程正常退出的情况下), 否则这个值无意义
当WIFEXITED返回值为true,它可以返回子进程的退出码。
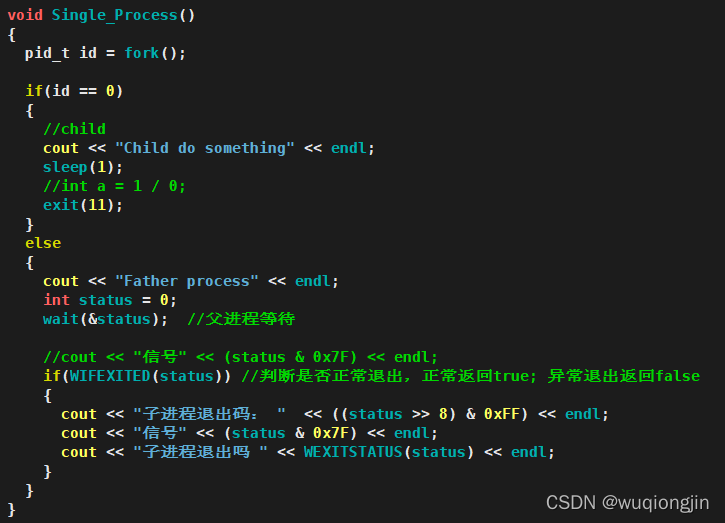
· 进程等待的代码演示
进程替换
替换原理
进程的替换本质就是 当某个进程调用exec系列函数时,该进程的用户空间代码和数据将被新的程序的代码和数据进行替换,从新程序的启动例程开始执行 (从新程序的头开始执行)。
替换函数
//均包含于<unistd.h>
int execl (const char* path, const char* arg, ...); //...表示可变参数,意思是可以传多个参数,类似于printf你进行输出的时候,也是可以输出多个参数的
int execlp (const char* file, const char* arg, ...);
int execle (const char* path, const char* arg, ..., char* const envp[]);
int execv (const char* path, char* const argv[]);
int execvp (const char* file, char* const argv[]);
int execve (const char* path, char* const argv[], char* const envp[]);
大家可能看一眼这些函数就觉得头大,其实我最开始也是这样的。但是在掌握下面的几条函数的命名规则与含义后,就能够豁然开朗了!
----->这里先教大家一个方便记忆的诀窍!<-----
exec系列函数 :(搜索的指令名称, 命令函参数列表,//环境变量的导入)
我要执行谁?我要怎么执行?环境变量的导入。
替换函数的命名规则
· l (list):采用参数列表进行传参 (指使用 ... 可变参数列表)
· v (vector):使用数组去进行传参 (将所有的命令函参数存入数组中,然后使用数组传参)
· p (path):自动去环境变量PATH中进行搜索指令
· e (env):自己维护的环境变量数组
组合规律:l 和 v 是相对的 、 e 和 p 是相对的。相对的不能同时组合!也就是说采用参数列表进行传参就不能在采用数组传参了,使用p去自动在PATH中搜索指令的话就不能自己维护环境变量数组了。下面给出组合的方式。
l、lp、le v、vp、ve
(l和v确定参数的传参形式、e和p确定程序的搜索位置)
替换函数的示例与解释
execl("/usr/bin/ls", "ls", "-l", "-i", "-a", NULL);
//带 l 的都需要在命令行参数的最后一个参数后面 + NULL
execlp("ls", "ls", "-l", "-i", "-a", NULL);
execle("./mycmd", "mycmd", NULL , my_envp);
//my_envp是自己写的环境变量数组,会传到你所调用的程序的main函数中的envp数组中
//你所调用的程序中得到了你所传的环境变量数组后,就可以使用正常获取环境变量的方法去获取环境变量了
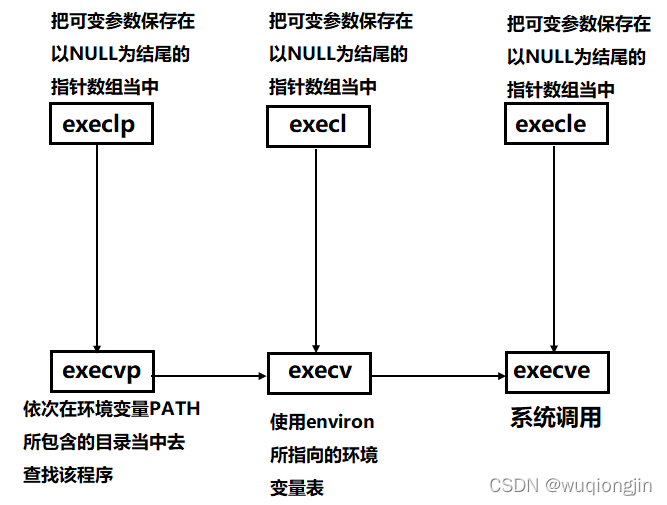
替换函数之间的调用关系
这些函数都比较相似,OS才不会挨个挨个实现每个函数的。事实上,只有execve是系统调用接口,其他的函数是对该接口进行的封装。
替换函数的注意事项与理解
- exec系列函数在成功调用后,会加载新的程序的代码和数据到现在的程序的位置上,并且会从头开始执行新程序的代码!
- 调用出错返回 -1
- exec系列函数只有出错时的返回值,没有成功的返回值。(因为成功了就不可能接收到返回值
这里再次分享一下进程管理章节的思维导图以便大家总结:思维导图获取链接
提取码: kfiq