
导读
Jim哥2007年加入VMware中国,经历了整个企业级市场从服务器虚拟化、私有云、公有云、容器云、混合云到云原生蓬勃发展的过程,也见证了从软件定义的计算存储、网络到软件定义一切的概念延伸。2021年Jim哥加入趋动科技,投身到软件定义AI算力的这一波浪潮中。本文不打算说概念和逻辑,而是尝试通过五大实际客户场景来看看如何通过软件定义的方法来对AI算力做优化,解决痛点问题,供各位老板们参考。
GPU服务器相对CPU服务器来说是非常昂贵的,大约是美金和人民币汇率的差距(以8卡GPU服务器为例),而且在芯片紧缺的年代,GPU到货周期还比较长!面对资源昂贵、算力又是AI的发动机、AI业务又必须开展之间的矛盾,如何更好的利用和管理GPU资源就变得尤其关键。下面一起来看看这五大典型场景。
◆ ◆ ◆ ◆
场景一:AI开发测试
◆ ◆ ◆ ◆
大多数的客户采取的是为一个开发者分配一块或几块GPU卡的方式来满足开发调试的需求。这种情况下存在什么问题?卡和人绑定,卡分配之后,存在着较大的闲置,开发人员70%以上的时间都在读论文、写代码,只有不到30%的时间在利用GPU资源进行运算调试。利用软件定义GPU的技术,把卡和人解绑,当有任务调用GPU资源的时候才真正被占用,任务结束,资源释放,回到资源池。
下图是一个JupyterLab的开发场景,VSCode server/PyCharm的模式与这个类似,在实际的客户案例里,使用软件定义的GPU之后,资源能缩减至25%左右!50个人的开发团队,16张卡搞定。
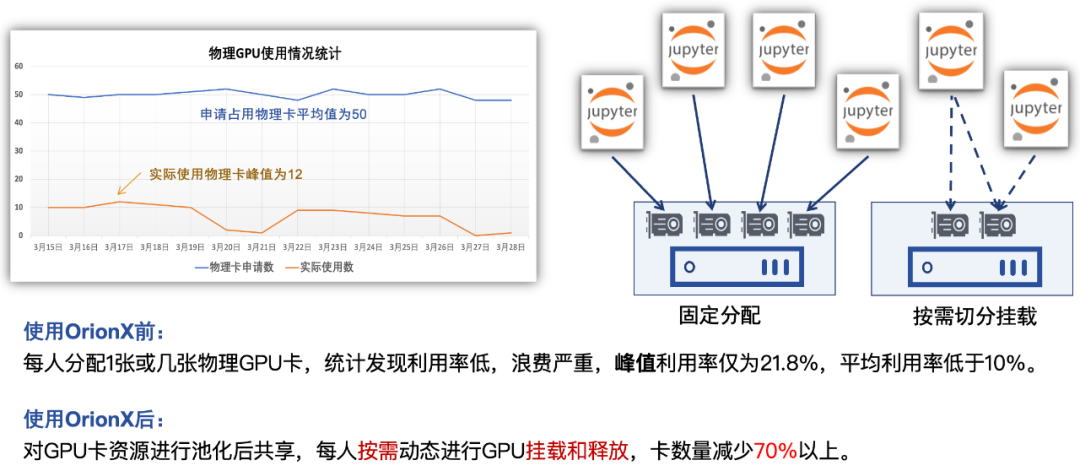
图1: OrionX在AI开发中动态调用卡资源示例
◆ ◆ ◆ ◆
场景二:生产环境的AI推理业务
◆ ◆ ◆ ◆
通过调查,绝大多数的用户业务为了保证业务的隔离性,不受其它AI业务的干扰,保障服务的SLA,都是运行在独立的GPU卡上。在这种情况下,GPU卡的算力和显存使用往往不到20%,这样造成了大量的资源浪费——近80%的算力和显存其实是被白白消耗,而且还有与之相关的电费,运维费用。通过软件定义的方式,提供细颗粒度的GPU资源复用单卡,保障业务运行的隔离性,可靠性和性能。大部分采取趋动科技池化方案上线生产业务的客户,可获得3倍以上的提升收益。
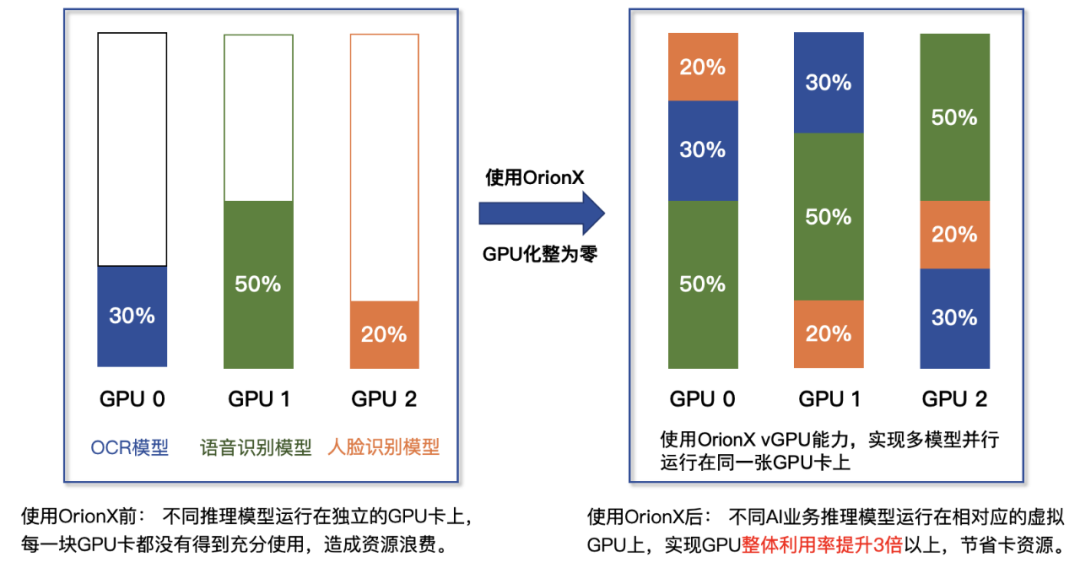
图2: OrionX在生产环境中的单卡多业务复用示例
◆ ◆ ◆ ◆
场景三:昼夜复用
◆ ◆ ◆ ◆
在前两种场景中,不管是AI开发,还是AI线上推理,基本上都是白天比较繁忙,卡利用率相对较高。到了晚间,卡资源基本就处于闲置状态,白白浪费!在一个证券客户那里,我们尝试着利用OrionX解决这个问题。通过软件定义的方式,弹性的分配和调度资源,晚上利用卡资源进行训练任务的运算,大大提升了闲时(夜间)资源利用率。
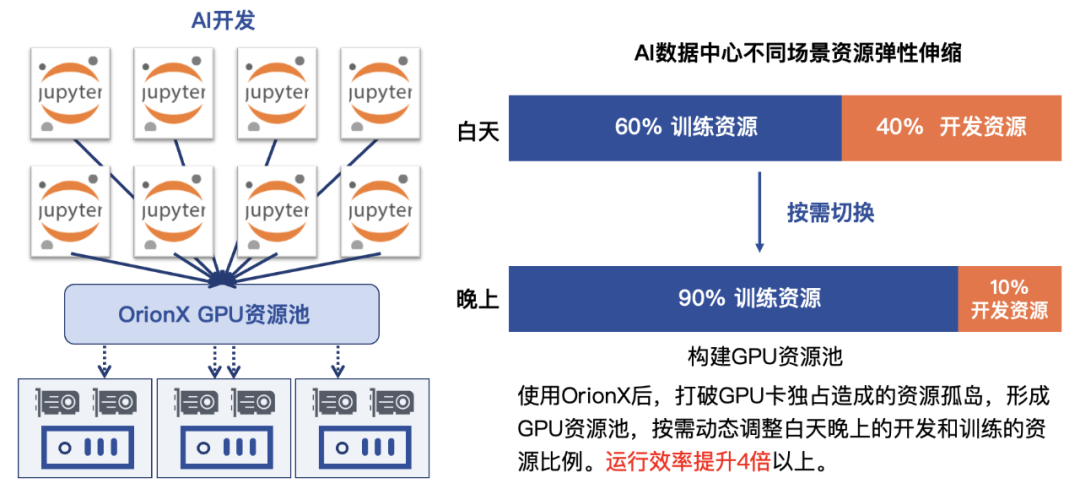
图3: OrionX按需对卡进行昼夜复用示例
◆ ◆ ◆ ◆
场景四:CPU和GPU的资源配比
◆ ◆ ◆ ◆
大多数的AI开发涉及到从数据准备,预处理,模型训练,调参,部署模型,线上推理,持续监控,数据收集,迭代优化的过程。在整个业务流程中,有些工作是需要大量CPU,不需要GPU资源的,在CPU运算的时候,其实GPU是闲置的;在一个自动驾驶客户那里,我们看到在仿真场景下,一个8卡的GPU的服务器,在CPU耗尽(占用100%)的情况下,最多只能使用到其中的3块GPU卡,剩下的5张GPU卡处在闲置状态,无法被充分利用。同样的道理,也可能存在GPU卡在大量占用,CPU资源被闲置的情况。通过利用软件定义的AI算力,将CPU和GPU解耦,一举解决CPU/GPU资源不匹配的问题。
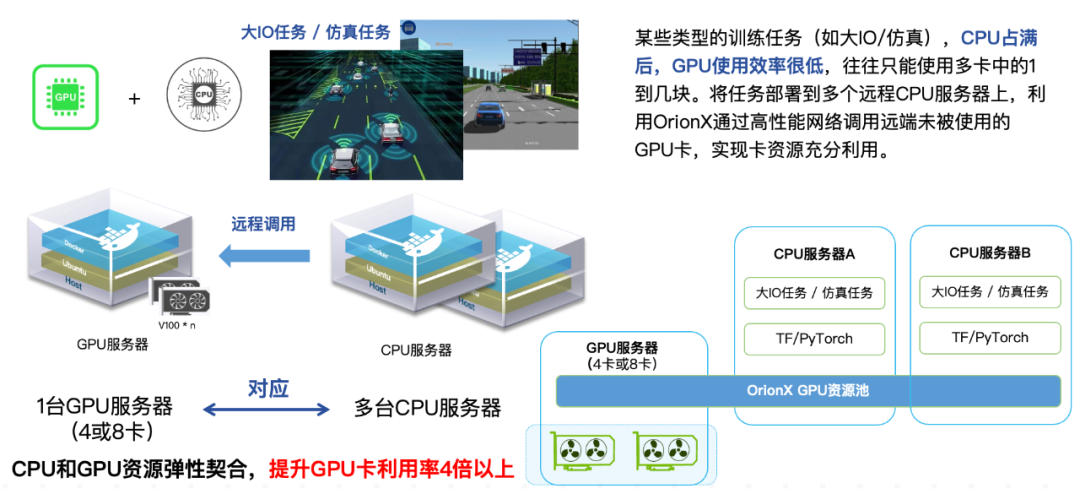
图4: OrionX优化CPU和GPU资源配比示例
◆ ◆ ◆ ◆
场景五:显存超分
◆ ◆ ◆ ◆
这是我们在一个金融客户那里遇到的真实案例,我们看到一个大数据AI分析流程,运行在1张16G显存的T4卡上,其需要占用大约20%的算力,12Gb的显存,服务常驻用在处理保单的识别和分析。在这种情况下,该卡剩余的80%算力,4Gb(25%)的显存处在闲置状态,无法被使用,成了资源碎片。
要想利用资源碎片,一种思路是找到适合碎片的算力任务也运行到这张卡(未必好找)。运用软件定义的虚拟显存的技术,使用部分内存来补足显存,让两个任务同时运行在这张卡上。资源不变,通量达到1.8倍!
你可能还会想到,如果在跑一个训练任务的时候,模型所需的物理显存不够,是不是也可以用内存来补足加载?是的。可以加载运行,但是要付出一定的性能损耗。此方案在必须改模型或要采购大显存物理卡之外,又提供了一种可能的选择。

图5: OrionX显存超分提升资源利用率示例
以上利用软件定义GPU的方法来优化AI算力的五大场景,只是我们看到的冰山一角。软件定义GPU所能带来的业务价值,还有待于企业客户在各个领域的不停探索。
除此之外,不得不提一下此项技术额外的Bonus,降低碳排放,保护地球家园!
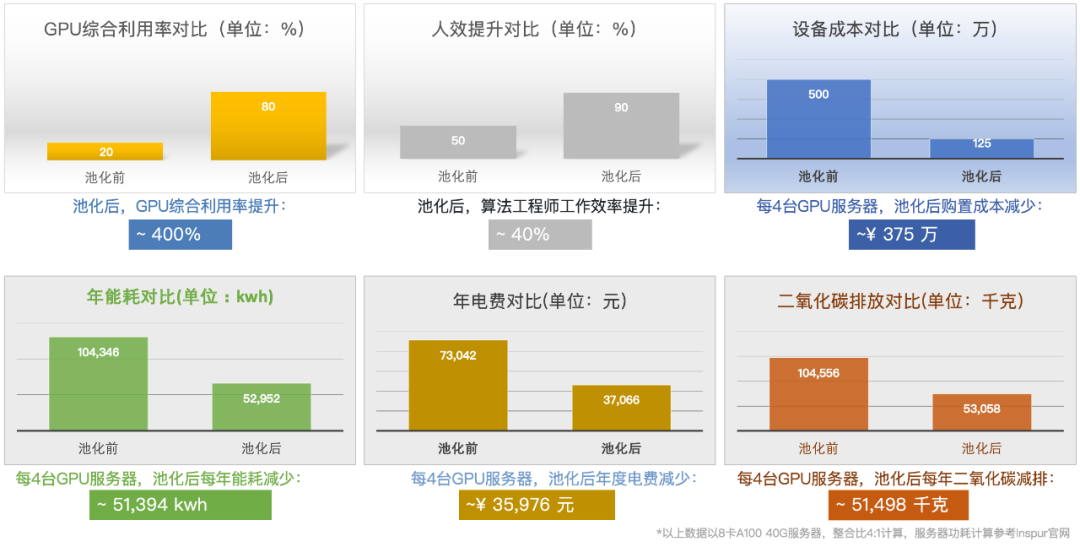
图6: OrionX关键效能指标收益对比示例
最后,做个小结。软件定义的核心是通过软件定义的方法,将各种硬件(CPU、内存、磁盘、I/0等)变成可以动态管理的“资源池”,从而提升资源的利用率,简化系统管理,实现资源整合,让IT对业务的变化更具适应力。
软件定义的AI算力,一方面可以把一颗物理加速芯片(GPU或ASIC)变成几个或几十个互相隔离的小的计算单元,也可以把分布在不同物理服务器上的加速芯片聚合给一个操作系统(物理机/虚拟机)或容器,完成分布式任务。此外,没有加速芯片(GPU或ASIC)的CPU服务器也可以调用远程服务器上的加速卡(GPU或ASIC)完成AI运算,实现CPU与GPU设备的解耦。软件定义实质是通过软件的方法提供更有弹性的硬件。