一、线性回归概述
1、概述
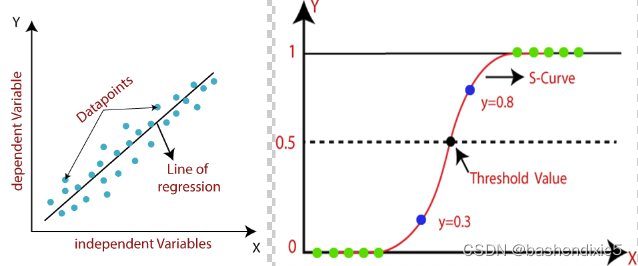
线性回归算法是一种预测连续型变量的方法。它的基本思想是通过已给样本点的因变量和自变量的关系,设定一个数学模型,来拟合这些样本点。线性回归算法就是为了找到最佳模型。
线性回归算法的核心有两个。第一,假设合适的模型,比如是使用一次曲线拟合还是二次曲线拟合;第二,寻找最佳的拟合参数,不同的参数对应了模型不同的形态,如何找到最佳的参数是非常关键的。
回归的目的是预测数值型的目标值。最直接的办法是依据输入写出一个目标值的计算公式。假如想要预测下一季度内汽车销售的数量,可能会用以下公式。
nums = 0.005*d - 0.00099f
这就是所谓的回归方程(regression equation),其中的0.0015和-0.99称作回归系数(regression weights),求这些回归系数的过程就是回归。
2、优缺点
优点:结果易于理解,计算上不复杂。
缺点:对非线性的数据拟合不好。
适用数据类型:数值型和标称型数据。
3、通常应用流程
(1)收集数据:采用任意方法收集数据。
(2)准备数据:回归需要数值型数据,标称型数据将被转成二值型数据。
(3)分析数据:绘出数据的可视化二维图将有助于对数据做出理解和分析,在采用缩减法求得新回归系数之后,可以将新拟合线绘在图上作为对比。
(4)训练算法:找到回归系数。
(5)测试算法:使用R2或者预测值和数据的拟合度,来分析模型的效果。
(6)使用算法:使用回归,可以在给定输入的时候预测出一个数值,这是对分类方法的提升,因为这样可以预测连续型数据而不仅仅是离散的类别标签。
二、逻辑回归概述
1、概述
逻辑回归可用于二分类或多分类。
逻辑回归(Logistic Regression)是最流行的机器学习算法之一,属于监督学习技术。它用于使用给定的一组自变量预测分类。
逻辑回归是一种使用逻辑函数对条件概率进行建模的统计模型。逻辑回归的思想是找到一个特征与特定结果概率之间的关系。
2、优缺点
优点:计算代价不高,易于理解和实现。
缺点:容易欠拟合,分类精度可能不高。
适用数据类型:数值型和标称型数据。
3、通常应用流程
(1)收集数据:采用任意方法收集数据。
(2)准备数据:由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据格式则最佳。
(3)分析数据:采用任意方法对数据进行分析。
(4)训练算法:大部分时间将用于训练,训练的目的是为了找到最佳的分类回归系数。
(5)测试算法:一旦训练步骤完成,分类将会很快。
(6)使用算法:首先,我们需要输入一些数据,并将其转换成对应的结构化数值;接着,基于训练好的回归系数就可以对这些数值进行简单的回归计算,判定它们属于哪个类别;在这之后,我们就可以在输出的类别上做一些其他分析工作。
三、线性回归与逻辑回归的异同
机器学习中有三大问题,分别是回归、分类和聚类。
线性回归属于回归问题,而逻辑回归属于分类问题。
虽然二者解决的是截然不同的问题,但是如果深究算法的本质,它们还是有很多共通的地方,比如它们都是通过梯度下降的方法寻找最优的拟合模型。
但是,线性回归拟合的目标是尽量让数据点落在直线上,而逻辑回归的目标则是尽量将不同类别的点落在直线的两侧。
表格形式对照
| 线性回归 |
逻辑回归 |
| 线性回归是一种监督回归模型。 |
逻辑回归是一种有监督的分类模型。 |
| 在线性回归中,我们通过整数预测值。 |
在逻辑回归中,我们将值预测为 1 或 0。 |
| 这里没有使用激活函数。 |
这里激活函数用于将线性回归方程转换为逻辑回归方程 |
| 不需要阈值。 |
需要阈值。 |
| 这里我们计算均方根误差(RMSE)来预测下一个权重值。 |
这里我们使用精度来预测下一个权重值。 |
| 这里因变量应该是数字,响应变量是连续的。 |
这里的因变量只包含两个类别。给定一组定量或分类自变量,逻辑回归估计因变量的几率结果。 |
| 它基于最小二乘估计。 |
它基于最大似然估计。 |
| 在这里,当我们绘制训练数据集时,可以绘制一条触及最大图的直线。 |
系数的任何变化都会导致逻辑函数的方向和陡度的变化。这意味着正斜率导致 S 形曲线,负斜率导致 Z 形曲线。 |
| 线性回归用于在自变量发生变化的情况下估计因变量。例如,预测房价。 |
而逻辑回归用于计算事件的概率。例如,分类组织是良性还是恶性。 |
| 线性回归假设因变量的正态或高斯分布。 |
逻辑回归假设因变量的二项式分布。 |
四、简单示例
1、简单线性回归
数据集非常简单,一列时间,一列分数。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cross_validation import train_test_split
from sklearn.linear_model import LinearRegression
# 读取数据
dataset = pd.read_csv('studentscores.csv')
X = dataset.iloc[ : , : 1 ].values
Y = dataset.iloc[ : , 1 ].values
# 分割训练数据和测试数据
X_train, X_test, Y_train, Y_test = train_test_split( X, Y, test_size = 1/4, random_state = 0)
# 使用线性回归进行训练
regressor = LinearRegression()
regressor = regressor.fit(X_train, Y_train)
# 进行预测
Y_pred = regressor.predict(X_test)
# 可视化训练结果
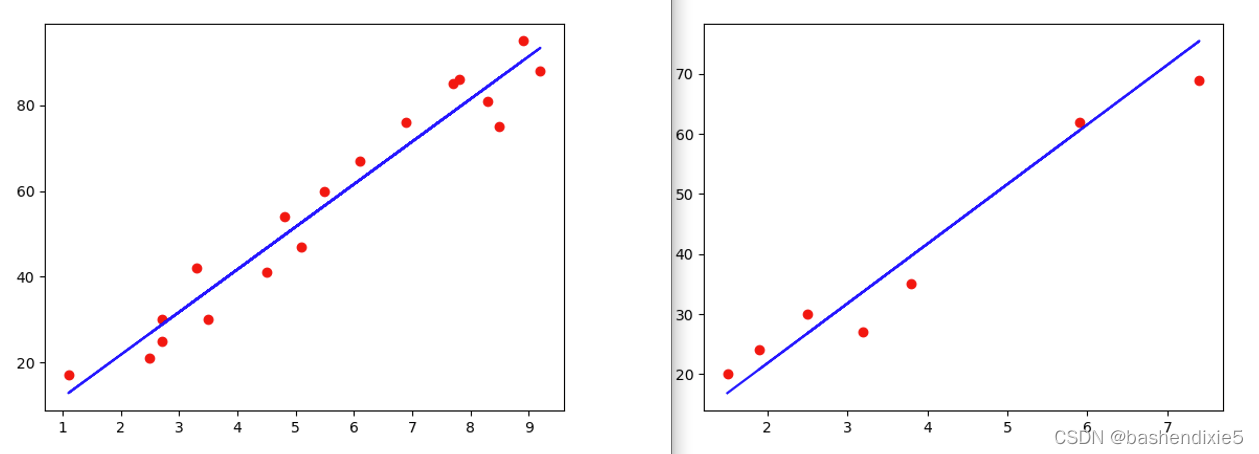
plt.scatter(X_train , Y_train, color = 'red')
plt.plot(X_train , regressor.predict(X_train), color ='blue')
# 可视化预测结果
plt.scatter(X_test , Y_test, color = 'red')
plt.plot(X_test , regressor.predict(X_test), color ='blue')下图是训练结果可视化
2、多元线性回归
数据集示例如下
| R&D Spend | Administration | Marketing Spend | State | Profit |
| 165349.2 | 136897.8 | 471784.1 | New York | 192261.83 |
| 162597.7 | 151377.59 | 443898.53 | California | 191792.06 |
| 153441.51 | 101145.55 | 407934.54 | Florida | 191050.39 |
| 144372.41 | 118671.85 | 383199.62 | New York | 182901.99 |
参考代码如下
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
dataset = pd.read_csv('50_Startups.csv')
X = dataset.iloc[ : , :-1].values
Y = dataset.iloc[ : , 4 ].values
labelencoder = LabelEncoder()
X[: , 3] = labelencoder.fit_transform(X[ : , 3])
onehotencoder = OneHotEncoder()
X = onehotencoder.fit_transform(X).toarray()
X = X[: , 1:]
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 0)
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X_train, Y_train)
y_pred = regressor.predict(X_test)3、简单逻辑回归
数据集包含社交网络中用户的信息。 这些信息是用户ID、性别、年龄和估计工资。 一家汽车公司刚刚推出了他们全新的豪华 SUV。 我们正在尝试查看社交网络的哪些用户将购买这款全新的 SUV 这里的最后一列告诉如果用户购买了这款 SUV,我们将构建一个模型来预测 用户是否要根据年龄和估计工资这两个变量购买或不购买 SUV。 所以我们的特征矩阵只有这两列。 我们希望找到用户的年龄和估计工资以及他是否购买 SUV 的决定之间的一些相关性。
数据集示例如下
| User ID | Gender | Age | EstimatedSalary | Purchased |
| 15624510 | Male | 19 | 19000 | 0 |
| 15810944 | Male | 35 | 20000 | 0 |
| 15668575 | Female | 26 | 43000 | 0 |
| 15603246 | Female | 27 | 57000 | 0 |
| 15804002 | Male | 19 | 76000 | 0 |
| 15728773 | Male | 27 | 58000 | 0 |
| 15598044 | Female | 27 | 84000 | 0 |
| 15694829 | Female | 32 | 150000 | 1 |
代码参考如下
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 读取数据集
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, 4].values
# 分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
# 实现特征缩放
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# 创建并训练
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
# 测试
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)