
1.概述
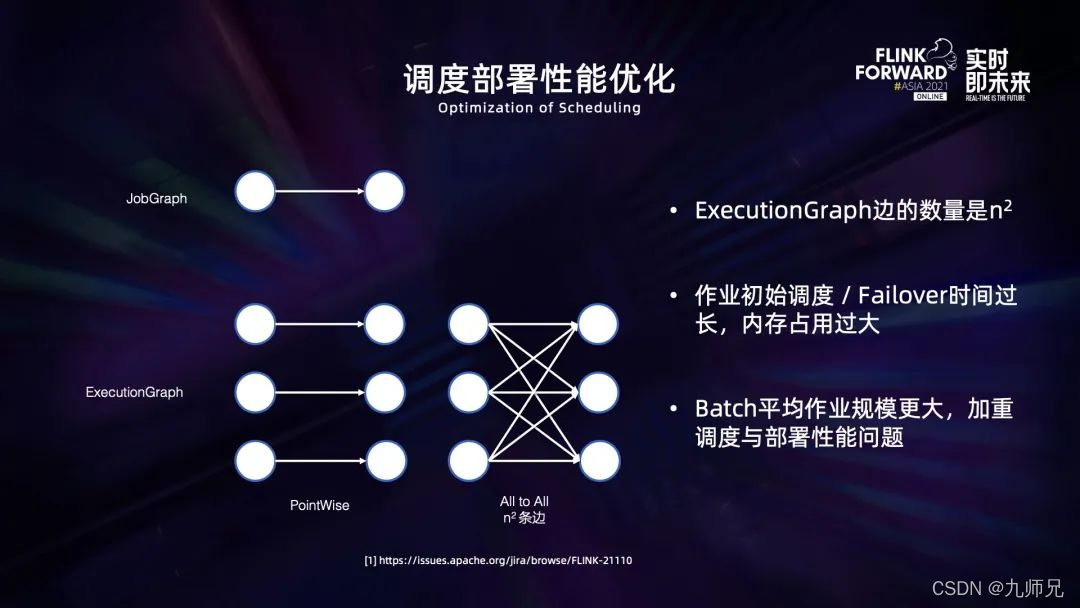
首先是关于调度部分的性能优化。Flink 由于存在 all to all 的连接关系,两个并发为 n 的算子之间会有 n² 条边,这 n² 条边显式地存在 jm 的内存中,并且许多调度和部署逻辑也会直接依赖于它进行处理,从而导致 jm 内存空间和许多计算的时间和空间复杂度都是 on²。由于 batch 作业一般具有更大的规模,并且调度更加细粒度,因此这会加重调度和部署的性能问题。
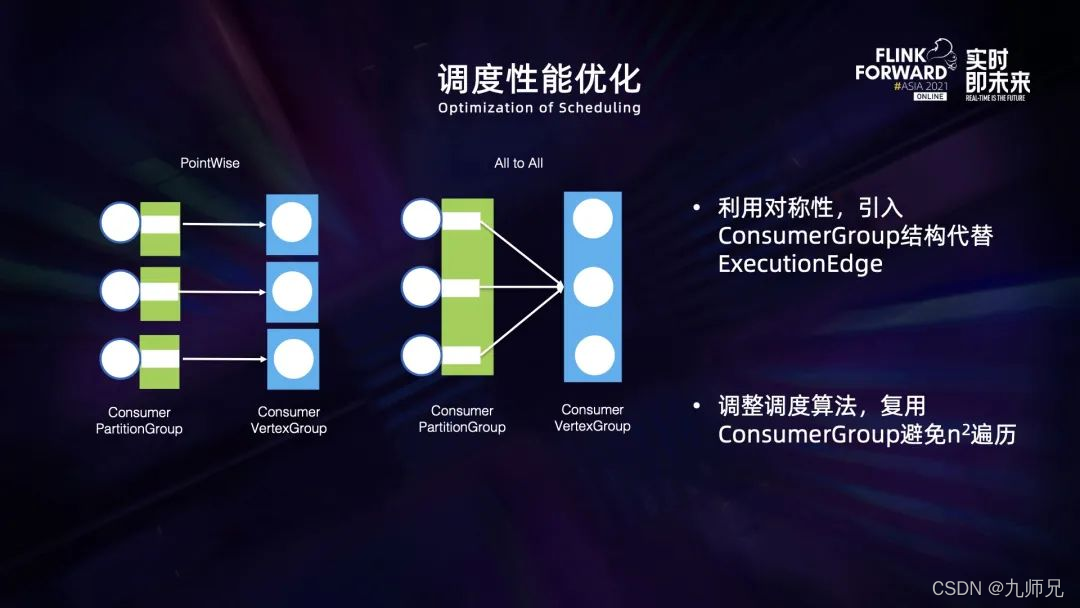
为了解决这一问题,我们利用 all to all 边的对称性,对内存中的数据结构和计算逻辑进行了重构,引入了 comsumergroup 的数据结构来代替之前的 excutionEdge 对算子之间的连接关系进行统一描述。这种方式不再重复描述堆对称的信息,从而避免了 n² 的复杂度。基于这一新的描述方式,我们不再在内存中维护 excutionEdge。
此外我们调整了许多调度的算法,比如计算 pipeline region、在一个 task 结束之后计算后续需要调度的 task 等,将它们的时间复杂度也降低到了 O(n)。
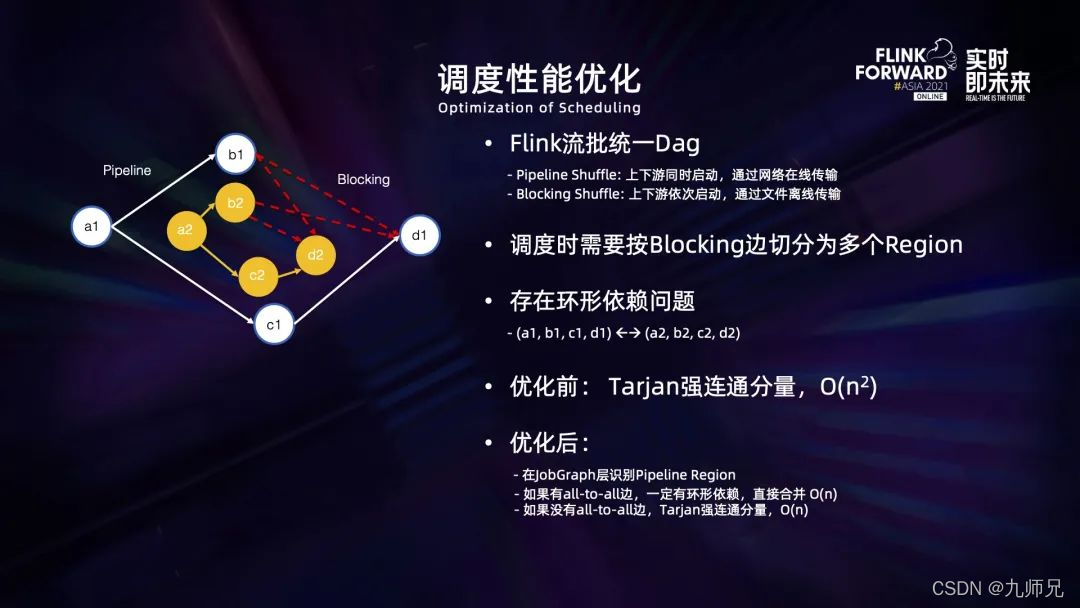
计算 pipeline region 过程中还有一部分特殊逻辑,Flink 在作业 dag 图中包含两种边, pipeline 边和 blocking 边。前者要求上下游的任务必须同时启动并通过网络传输数据,后者则要求上下游任务依次启动并通过文件来传输数据。在调度前首先需要计算 pipeling region,一般来说可以按照 blocking 边进行打断,将所有通过 pipeline 边相连的 task 放到同一个region里,但这种逻辑存在一个问题,如上图所示可以看出,因为并发 1 的 task 和并发 2 的 task 之间是通过 blocking 边分成两个 region 的,如果直接通过 blocking 边打断将它分为两个 region。而因为 task1 和 task2 之间存在 all to all 的 shuffle 关系,最后在 region 组成的图上会存在环形依赖的问题,在调度的时候会产生死锁。
在之前的实践中,我们通过 tarjan 强联通分支算法来识别这种环境依赖,彼时的识别是直接在 excutiongraph 上进行,所以它的时间复杂度是 O(n²),因为 all to all 的边存在 n² 的连接。通过进一步分析发现,如果在 jobgraph 中直接进行 pipeline 的认证识别,只要图中有 all to all 的边就一定存在环形依赖,因此可以直接在 jobgraph 上先进行判断,识别出所有 all to all 的边,然后在 excutiongraph 上再对非 all to all 的边进行处理。
通过这种方式,可以将环形依赖识别的复杂度降低到 O(n)。
3.2 部署性能优化

另一部分优化是关于部署性能。

Flink 在部署 task 的时候会携带它的 shuffle descriptors。对于上游来说,shuffle descriptors 描述了数据产出的位置,而对于下游来说,它描述了需要拉取数据的位置。shuffle descriptors 与 ExcutionEdge 的数量是相等的,因此这个数量级也是 O(n²)。在内存中进行计算序列化存储的时候,shuffle descriptors 会消耗大量 CPU 和内存,卡死主线程,导致 TM 及耗尽内存的问题。
但是由于上下游存在对称性,因此有很多 shuffle descriptors 其实是重复的,我们可以通过缓存 shuffle descriptors 的方式来降低维护它的数量。
另外为了进一步防止并发量过大导致 shuffle descriptors 过大,导致内存 oom,我们改用 BlobServer 来传输 shuffle descriptors。
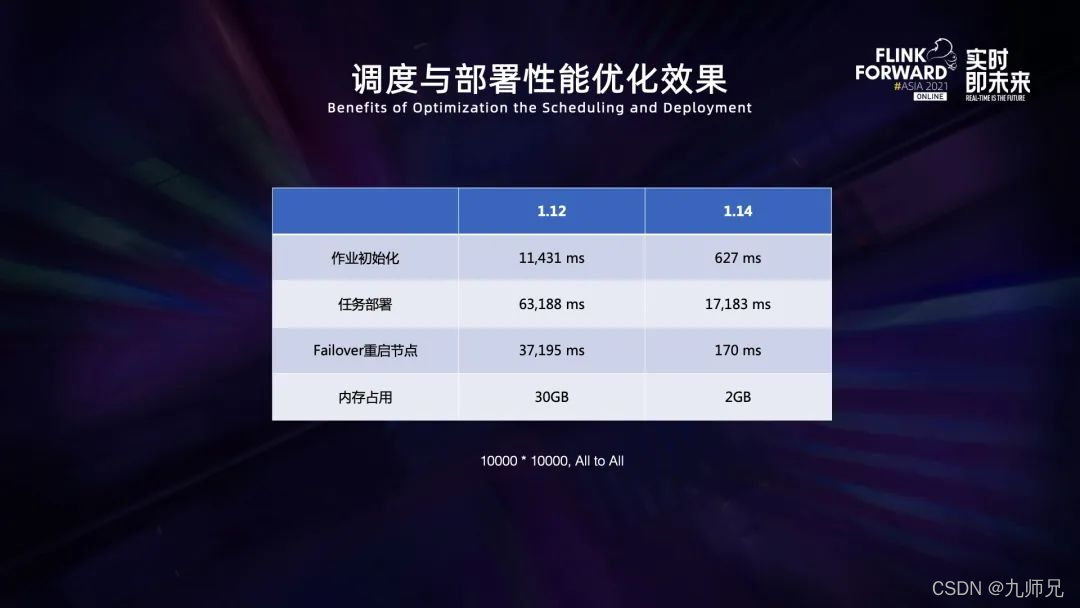
实现了上述优化以后,我们采用一个 10000×10000 的 all to all 两级作业进行测试,可以看出调度和内存占用缩减了 90% 以上,部署时间缩减 65% 以上,极大提高了调度和部署的性能。
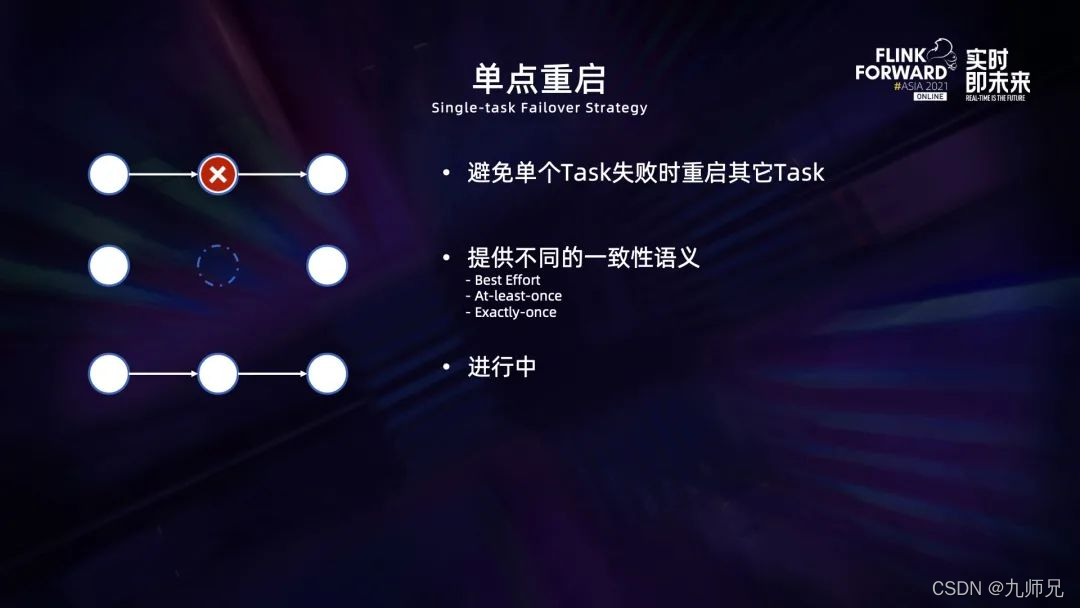
流执行模式调度和部署的优化极大地减少作业 failover 时重新启动的时间,但是一旦发生 failover,仍然需要花费一定的时间来进行重新部署以及初始化、加载 state 等工作。为了进一步减少这个时间,我们正在尝试在作业发生 failover 的时候,只重启出错节点。其中的难点在于如何保证数据的一致性,我们目前正在探索中。
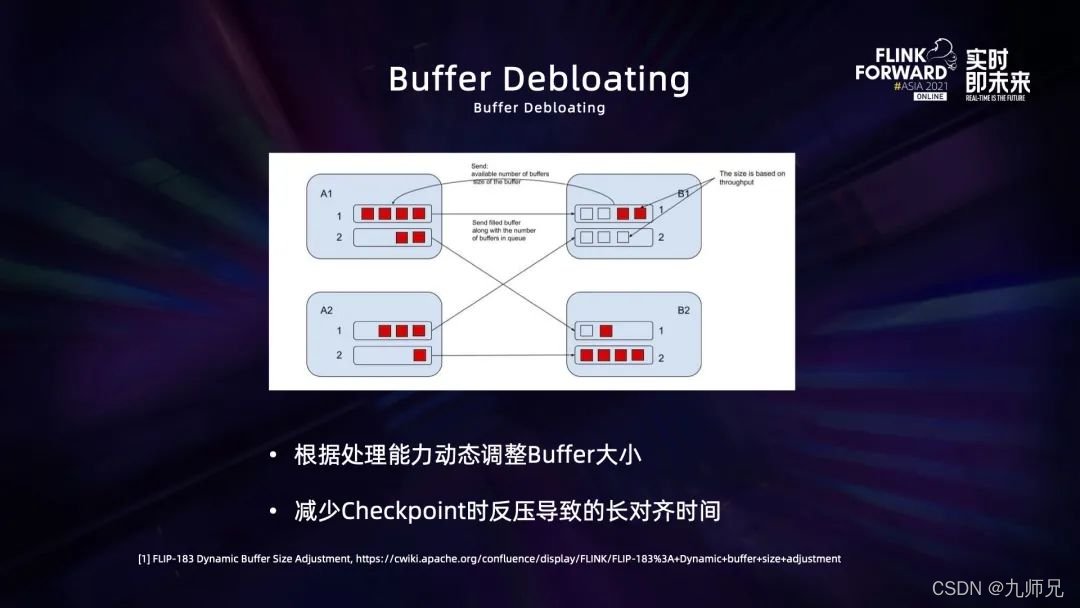
另外一部分 runtime 的优化是在流模式下通过 Buffer Debloating 来动态调整 buffer 的大小,从而在反压的情况下减少 checkpoint 的 buffer 对齐所需要的时间,避免 checkpoint 超时。如果产生反压,当作业中间缓存的数据量过大时,可以及时减少 buffer 的大小来控制中间缓存的数据大小,从而避免因为处理数据而阻塞 barrier 的情况。