可选择 TaildirSource和KafkaChannel,并配置日志校验拦截器。
选择TailDirSource和KafkaChannel的原因如下:
1)TailDirSource
TailDirSource相比ExecSource、SpoolingDirectorySource的优势
- TailDirSource:断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。
- ExecSource可以实时搜集数据,但是在Flume不运行或者Shell命令出错的情况下,数据将会丢失。
- SpoolingDirectorySource监控目录,支持断点续传。
2)KafkaChannel
采用Kafka Channel,省去了Sink,提高了效率。
日志采集Flume关键配置如下:
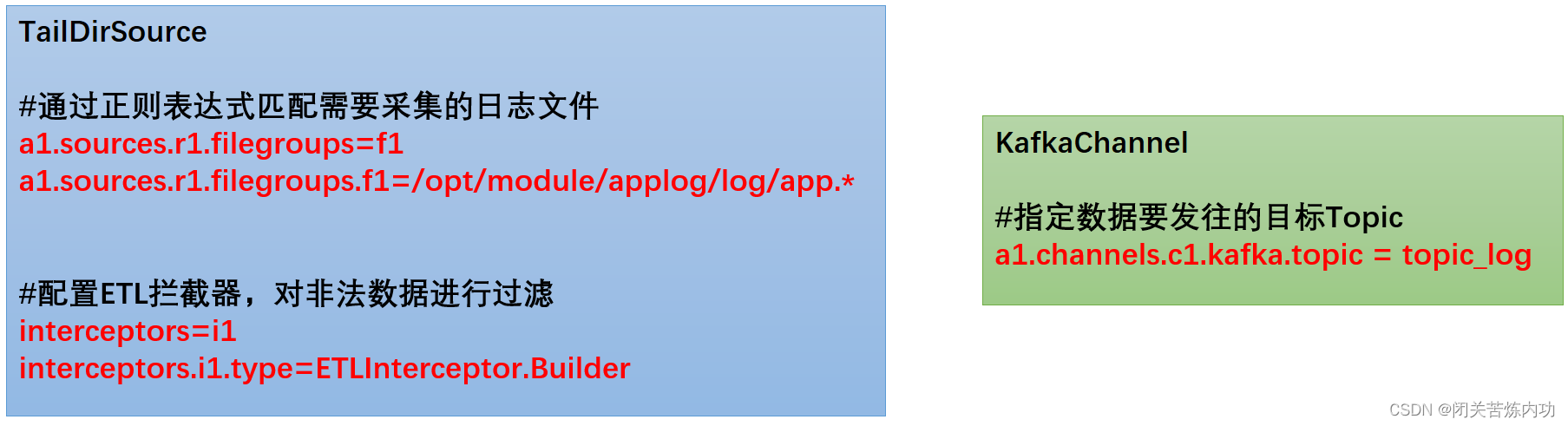
Flume组件选型
1)Source
(1)Taildir Source相比Exec Source、Spooling Directory Source的优势
TailDir Source:断点续传、多目录。
Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。
不会丢数据,但是有可能会导致数据重复。
Exec Source可以实时搜集数据,但是在Flume不运行或者Shell命令出错的情况下,数据将会丢失。
Spooling Directory Source监控目录,支持断点续传。
(2)batchSize大小如何设置?
答:Event 1K左右时,500-1000合适(默认为100)
2)Channel
采用Kafka Channel,省去了Sink,提高了效率。
KafkaChannel数据存储在Kafka里面,所以数据是存储在磁盘中。
注意在Flume1.7以前,Kafka Channel很少有人使用,因为发现parseAsFlumeEvent这个配置起不了作用。
也就是无论parseAsFlumeEvent配置为true还是false,都会转为Flume Event。
这样的话,造成的结果是,会始终都把Flume的headers中的信息混合着内容一起写入Kafka的消息中,这显然不是我所需要的,我只是需要把内容写入即可。