介绍
贝叶斯定理是用来做什么的?简单说,概率预测:某个条件下,一件事发生的概率是多大?
wiki 把为什么要做这个定理谈的很清楚,是为了覆盖逆概的场景:
在贝叶斯写这篇文章之前,人们已经能够计算“正向概率”,如“假设袋子里面有N个白球,M个黑球,你伸手进去摸一把,摸出黑球的概率是多大”。
而一个自然而然的问题是反过来:“如果我们事先并不知道袋子里面黑白球的比例,而是闭着眼睛摸出一个(或好几个)球,观察这些取出来的球的颜色之后,那么我们可以就此对袋子里面的黑白球的比例作出什么样的推测”。这个问题,就是所谓的逆概问题。
了解一下公式
事件B发生的条件下,事件A发生的概率为:
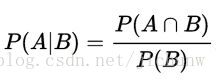
同理可得,事件A发生的条件下,事件B发生的概率为:
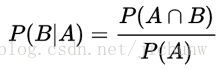
很容易推导得到:
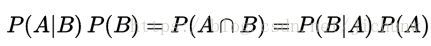
假设若P(A)≠0,那么就可以得到用来预测概率的贝叶斯定理了:

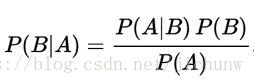
这个定理显然是可以推导到多个条件的,比如在2个条件的情况下:
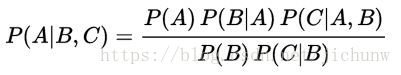
经典案例
信某宗教的人是恐怖分子的概率是多少?
假设 100% 的恐怖分子都相信某宗教,而某人相信某宗教,并不代表此人 100% 是恐怖分子,还需要考虑先验概率,假设全球有 7万 恐怖分子(全球人口 70亿 ),假设全球有 1/3 的人口相信某宗教,那么这个人是恐怖分子的概率是多少?
解:
我们要求解的是这个概率: P(恐怖分子|信某教)
套用公式,得到 :
P(恐怖分子|信某教)
= P(信某教|恐怖分子) P(恐怖分子) / P(信某教)
= 100% * (7万人/70亿人) / (1/3)
= 0.003%
也即十万分之三的概率。
延展开去,从数学理论上讲,民主党不针对某个信教人群是对的,但是题目中设定 100% 的恐怖分子信某教,这个假设就比较…
检测呈阳性的雇员吸毒概率是多少?
假设一个常规的检测结果的敏感度与可靠度均为 99% ,即吸毒者每次检测呈阳性 (+) 的概率为 99% 。而不吸毒者每次检测呈阴性 (-) 的概率为 99% 。假设某公司对全体雇员进行吸毒检测,已知 0.5% 的雇员吸毒。请问每位检测结果呈阳性的雇员吸毒的概率有多高?
解:
我们要求解的是这个概率: P(吸毒|检测呈阳性的雇员)
套用公式,得到 :
P(吸毒|检测呈阳性雇员)
= P(检测呈阳性雇员|吸毒) P(吸毒) / P(检测呈阳性雇员)
= 99% * 0.5% / [P(检测呈阳性雇员∩吸毒) + P(检测呈阳性∩不吸毒)]
= 99% * 0.5% / [P(检测呈阳性雇员|吸毒) * P(吸毒) + P(检测呈阳性|不吸毒) * P(不吸毒)]
= 99% * 0.5% / [99% * 0.5% + 1% * 99.5%]
= 0.3322
也就是说,尽管吸毒检测的准确率高达 99% ,但贝叶斯定理告诉我们:如果某人检测呈阳性,其吸毒的概率只有大约 33% ,不吸毒的可能性比较大。
不过也要注意,检测的准确率高低,十分影响结果的概率,如果检测精度达到 99.9% ,那么检测呈阳性的雇员吸毒的概率就上升到了 83.39% 。
垃圾邮件的过滤
这是 Paul Graham 在 《黑客与画家》 中提到的办法。这个问题其实可以倒推,我们要求解的是这个概率: P(垃圾邮件|检测到某种特征) 。
这个某种特征可以是 关键词,可以是 时间,可以是 频次,可以是 邮件附件类型 …包括以上各种特征 混合 的特征等等。
我们先用最简单的 关键词 来做推测,根据我个人的经验,一个中国式垃圾邮件很可能会包含两个字:发票 。好,那么我们要求解的一封邮件是不是垃圾邮件的概率就变成 P(垃圾邮件|检测到“发票”关键词),根据贝叶斯定理
P(垃圾邮件|检测到“发票”关键词)
= P(检测到“发票”关键词|垃圾邮件) / P(检测到“发票”关键词)
好,这里遇到了一个问题,我们怎么知道垃圾邮件里出现 发票 关键词的概率?
怎么知道在所有邮件里出现 发票 关键词的概率?理论上,除非我们统计所有邮件,否则我们是得不出的。这时候,就得做个妥协,在工程上做个近似,我们自己找到一定数量的真实邮件,并分为两组,一组正常邮件,一组垃圾邮件,然后进行计算,看 发票 这个词,在垃圾邮件中出现的概率是多少,在正常邮件里出现的概率是多少。
显然,这里的训练数量大一些的话,计算得到的概率会更逼近真实值。 Paul Graham 使用的邮件规模,是正常邮件和垃圾邮件各 4000封 。如果某个词只出现在垃圾邮件中, Paul Graham 就假定,它在正常邮件的出现频率是 1% ,反之亦然,这样做是为了避免概率为 0 。随着邮件数量的增加,计算结果会自动调整。
这样的话,将公式继续分解为如下:
P(垃圾邮件|检测到“发票”关键词)
= P(检测到“发票”关键词|垃圾邮件) / P(检测到“发票”关键词)
= P(检测到“发票”关键词|垃圾邮件) / [P(检测到“发票”关键词∩垃圾邮件) + P(检测到“发票”关键词∩正常邮件)]
= P(检测到“发票”关键词|垃圾邮件) / [P(检测到“发票”关键词|垃圾邮件) / P(垃圾邮件) + P(检测到“发票”关键词|正常邮件) / P(正常邮件)]
就又可以根据训练模型得到的概率,进行初始值计算了。此后,可以通过大量用户将垃圾邮件标注为正常邮件,正常邮件挪到垃圾邮件的动作,进行反复训练纠正,直至逼近一个合理值了。
不过这里还涉及到一个问题,就是单个关键词的概率(单个条件)无论如何再高,这封邮件仍然有可能不是垃圾邮件,所以在此处应用贝叶斯定理时,我们显然要用到多个条件,也就是计算这个概率:
P(垃圾邮件|检测到“A”关键词,检测到“B”关键词,检测到"C",...)
Paul Graham 的做法是,选出邮件中 P(垃圾邮件|检测到“X”关键词) 最高的 15个词 ,计算它们的联合概率。(如果关键词是第一次出现,Paul Graham 就假定这个值等于 0.4 ,也即认为是negative normal)。