实验内容:
1.复现,K-means的两个案例:iris和基于经纬度的城市聚类。
2.对于给定的项目,自行编写程序,使用K-means算法不同含量果汁饮料的聚类:
某企业通过采集企业自身流水线生产的一种果汁饮料含量的数据集,来实现K-Means算法。通过聚类以判断该果汁饮料在一定标准含量偏差下的生产质量状况,对该饮料进行类别判定。
- 加载数据集,读取数据,探索数据。
- 样本数据转化(可将pandasframe格式的数据转化为数组形式),并进行可视化(绘制散点图),观察数据的分布情况,从而可以得出k的几种可能取值。
- 针对每一种k的取值,进行如下操作:
- 进行K-Means算法模型的配置、训练。
- 输出相关聚类结果,并评估聚类效果。 这里可采用CH指标来对聚类有效性进行评估。在最后用每个k取值时评估的CH值进行对比,可得出k取什么值时,聚类效果更优。注:这里缺乏外部类别信息,故采用内部准则评价指标(CH)来评估。 (metrics.calinski_harabaz_score())
- 输出各类簇标签值、各类簇中心,从而判断每类的果汁含量与糖分含量情况。
- 聚类结果及其各类簇中心点的可视化(散点图),从而观察各类簇分布情况。(不同的类表明不同果汁饮料的果汁、糖分含量的偏差情况。)
- 【扩展】(选做):设置k一定的取值范围,进行聚类并评价不同的聚类结果。 参考思路:设置k的取值范围;对不同取值k进行训;计算各对象离各类簇中心的欧氏距离,生成距离表;提取每个对象到其类簇中心的距离,并相加;依次存入距离结果;绘制不同看、值对应的总距离值折线图。
第一个鸢尾花可以用在线的,这里就不发了,其他两个数据集:
https://pan.baidu.com/s/1mgZTpGkxX7pTU6xAEkO-WA
提取码:5613
1.复现iris示例:
#作 者:Asita
#开发时间:2021/11/26 19:41
#导入必要的包
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.cluster import KMeans
from sklearn import metrics
# 一、加载数据集:
iris = datasets.load_iris() # 导入鸢尾花数据集
# 数据拆分
iris_X_train , iris_X_test , iris_y_train , iris_y_test = train_test_split(iris.data,iris.target,test_size=0.2)
# 注:这里是从sklearn中直接导入的数据集,也可以采用自己导入数据的方式。
# 二、配置模型
Kmeans = KMeans(n_clusters = 3) #K-Means算法模型,3类标签
# 三、训练模型
kmeans_fit=Kmeans.fit(iris_X_train) #模型训练
# 四、模型预测
y_predict=Kmeans.predict(iris_X_train)
#print(y_predict)
# 五、模型评估
#iris_y_train[iris_y_train==11]=0
#print("调整",iris_y_train) #显示调整后的预测
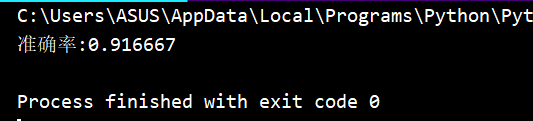
score=metrics.accuracy_score(iris_y_train,Kmeans.predict(iris_X_train))
print('准确率:{0:f}'.format(score)) #显示准确率输出:Accuracy:0.8
# 六、结果可视化
# 因为图形只有两个维度X和Y,所以该程序只有将特征值的第一个和第二个分别当成表格中X和Y的位置,第三个和第四个特征值虽然在计算时会使用,但显示图片的时候就不使用。
x1=iris_X_train[:, 0] #鸢尾花花萼长度
y1=iris_X_train[:, 1] #鸢尾花花萼宽度
plt.scatter(x1,y1, c=y_predict, cmap='viridis') #画每一条的位置
centers = Kmeans.cluster_centers_ #每个分类的中心点
plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5); #中心点
plt.show() #显示图像
实验结果:
复现基于经纬度的城市聚类案例
#作 者:Asita
#开发时间:2021/11/26 20:31
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 一、数据获取
# ------ 1.1.导入数据 ------
df = pd.read_csv('F:/data/China_cities.csv',encoding='GB18030') # 你的数据集地址
# print(df)
print(df.shape) # 输出数据维度
print(df.head()) # 展示前5行数据
# 二、数据预处理
# ------ 2.1.提取经纬度数据 ------
x = df.drop('省级行政区', axis=1) # 删除 省级行政区 这一列
# print(x)
x = x.drop("城市", axis=1) # 删除 城市 这一列
# print(x)
x_np = np.array(x) # 将x转化为numpy数组
# print(x)
# 三、模型构建与训练
# ------ 3.1.构造K-Means聚类器 ------
n_clusters = 7 # 类簇的数量
estimator = KMeans(n_clusters) # 构建聚类器
# ------ 3.2.训练K-Means聚类器 ------
estimator.fit(x)
# 四、数据可视化
markers = ['*', 'v', '+', '^', 's', 'x', 'o'] # 标记样式列表
colors = ['r', 'g', 'm', 'c', 'y', 'b', 'orange'] # 标记颜色列表
labels = estimator.labels_ # 获取聚类标签
plt.figure(figsize=(9, 6))
plt.title("Major Cities in China", fontsize=25)
plt.xlabel('East Longitude', fontsize=18)
plt.ylabel('North Latitude', fontsize=18)
for i in range(n_clusters):
members = labels == i # members是一个布尔型数组
plt.scatter(
x_np[members, 1], # 城市经度数组
x_np[members, 0], # 城市纬度数组
marker = markers[i], # 标记样式
c = colors[i] # 标记颜色
) # 绘制散点图
plt.grid()
plt.show()
实验结果:
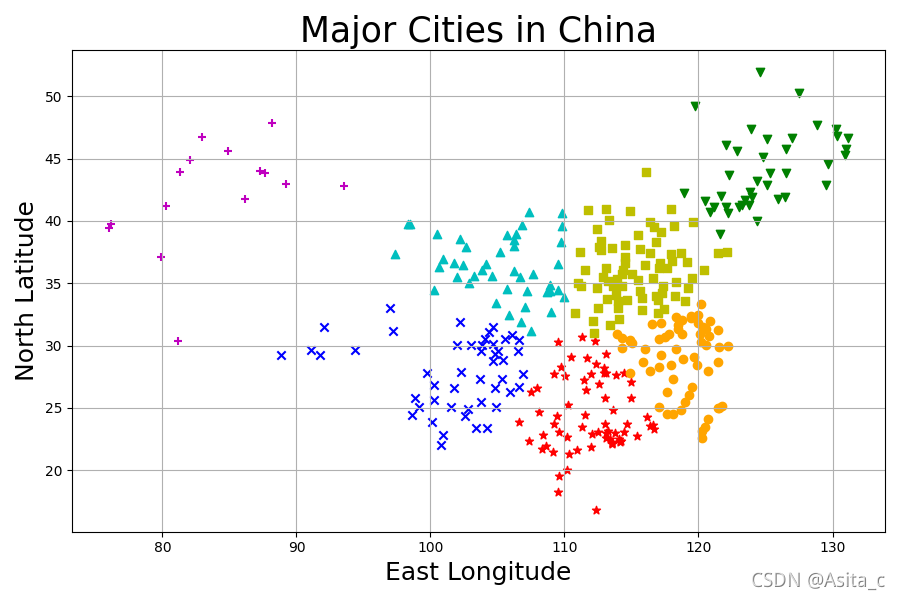
2、基于饮料的聚类:
设置了不同的k值(2~7)进行聚类:
完整代码:
#作 者:Asita
#开发时间:2021/11/28 9:43
import pandas as pd
import numpy as np
from sklearn import metrics
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 一、数据获取
# ------ 1.1.导入数据 ------
df = pd.read_csv('F:/研究生/课程/机器学习/聚类/beverage.csv',encoding='GB18030') # 你的数据集地址
# print(df)
print(df.shape) # 输出数据维度
print(df.head()) # 展示前5行数据
# 二、数据可视化
def showOrgData(dataMat):
df=np.array(dataMat)
print(type(df))
plt.scatter(df[:, 0], df[:, 1],color='m', marker='o', label='Org_data')
plt.xlabel('juice')
plt.ylabel('sweet')
plt.legend(loc=2) # 把说明放在左上角,具体请参考官方文档
plt.show()
#三、数据处理
df=np.array(df) # 将pandasframe格式的数据转化为numpy的数组形式
# 样本数据散点图(未划分之前的数据集)
showOrgData(df)
#四、训练不同k值下的kmeans
score_all=[]
list1=range(2,8)
for i in range(2,8):
estimator = KMeans(n_clusters=i)
estimator.fit(df)
y_pred = estimator.fit_predict(df)
#五、画出不同k值下的结果散点图
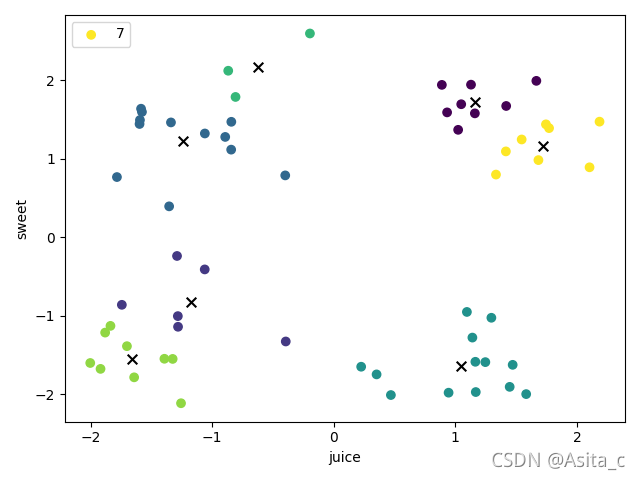
plt.scatter(df[:, 0], df[:, 1], c=y_pred,label=i)
plt.legend(loc=2) # 把说明放在左上角,具体请参考官方文档
plt.xlabel('juice')
plt.ylabel('sweet')
# 重要属性cluster_centers_,查看质心
centroid = estimator.cluster_centers_
print("k=%d:" % i)
print("centroid:\n",centroid)
# 各类簇中心点的可视化
plt.scatter(
centroid[:, 0],
centroid[:, 1],
marker="x",
c="black",
s=48
)
#六、记录不同k值下聚类的CH评价指标的结果
score = metrics.calinski_harabasz_score(df, y_pred)
score_all.append(score)
print("score=",score)
print('------------------------------')
plt.show()
#七、画出不同k值对应的聚类效果(折线)
plt.plot(list1,score_all)
plt.xlabel('k')
plt.ylabel('CH')
plt.show()
实验结果:
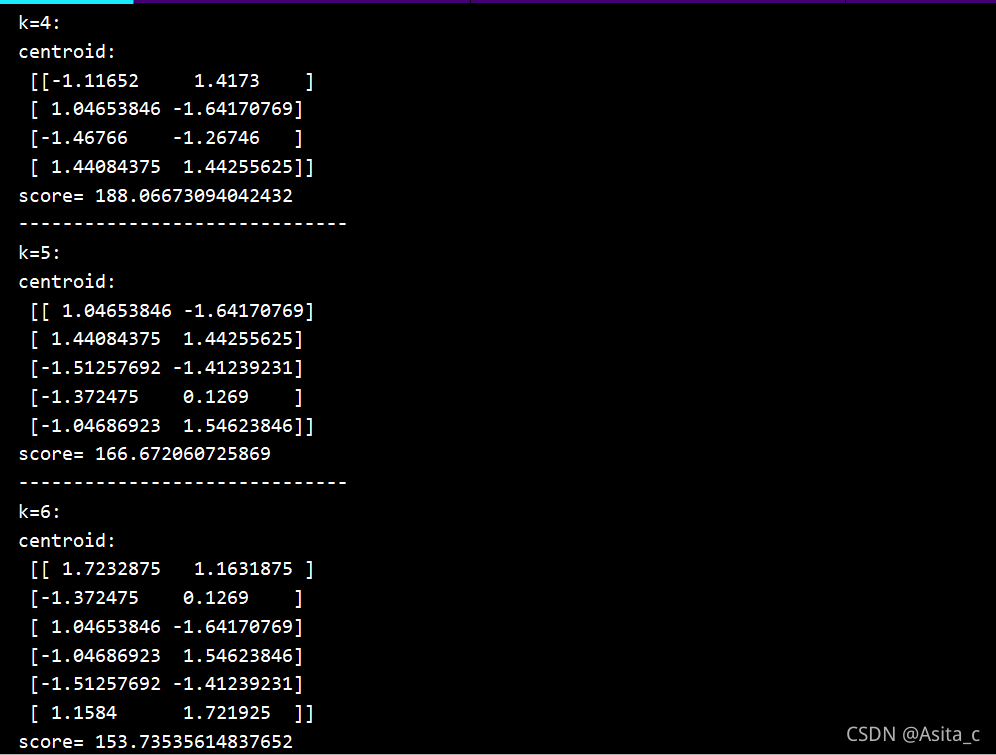
输出了不同k值下的各类簇标签值、各类簇中心
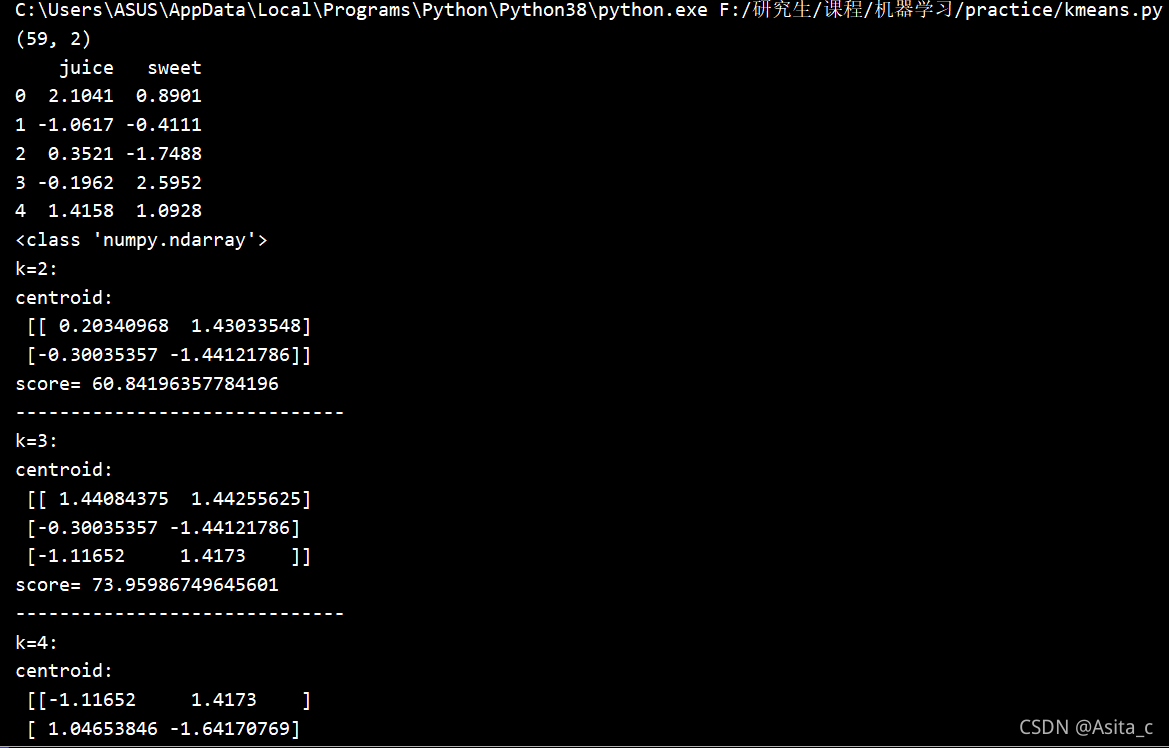
原始数据集:
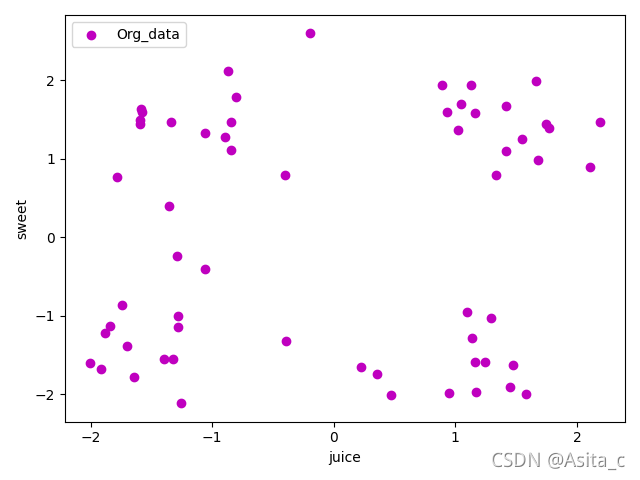
通过观察数据的分布情况,从而可以得出k的可能取值为2~4(肉眼观察的),但为了实测不同的聚类结果,最终设置的k为2 ~ 7。
当k=2时:
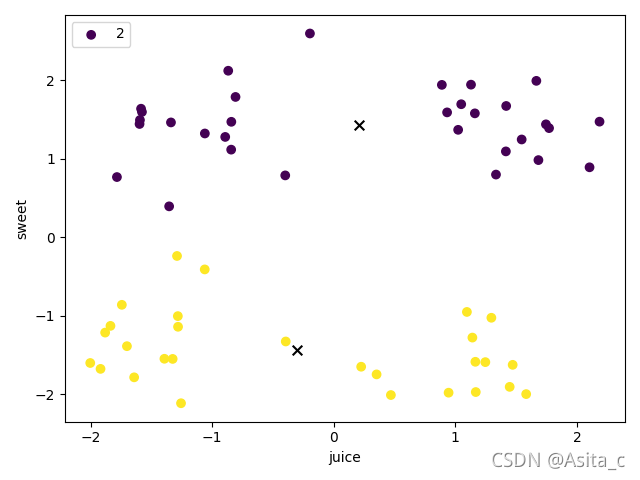
当k=3时:
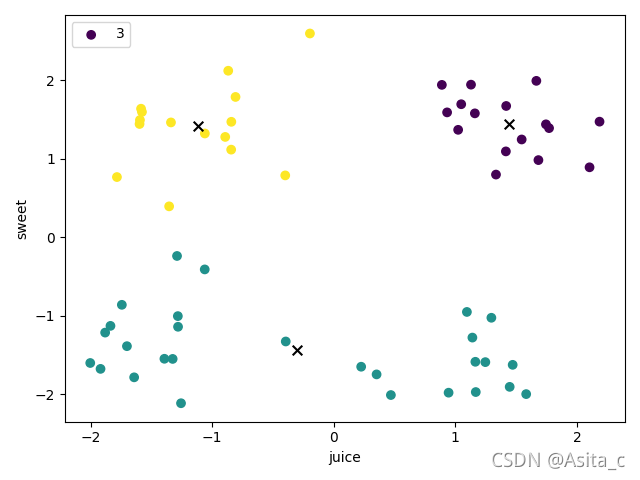
当k=4时:
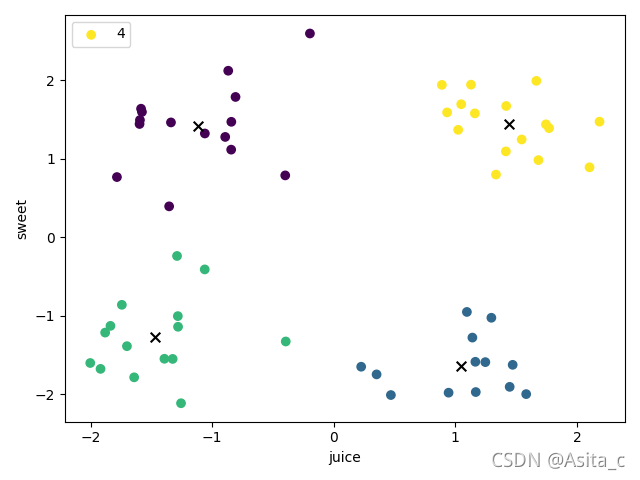
当k=5时:
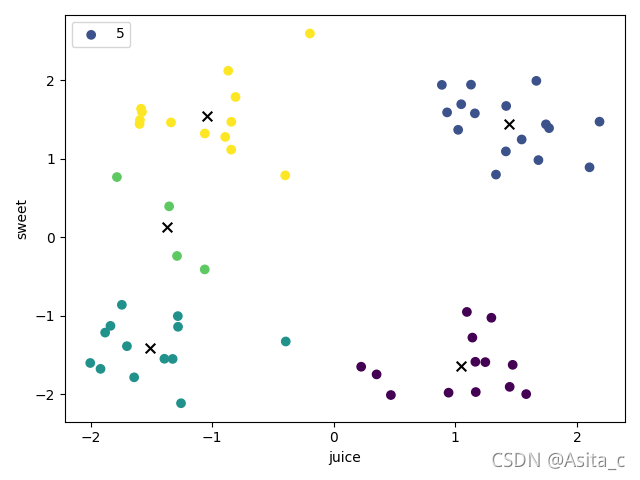
当k=6时:
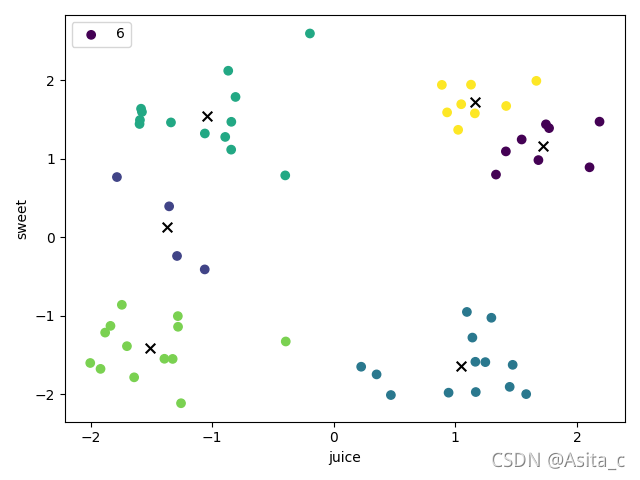
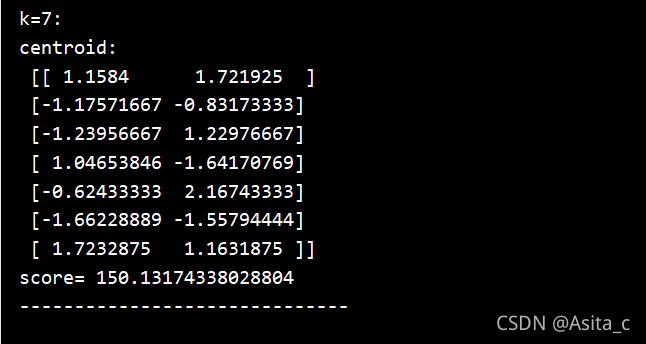
当k=7时:
跟据不同的k值以及内部评价指标CH的折线图来:
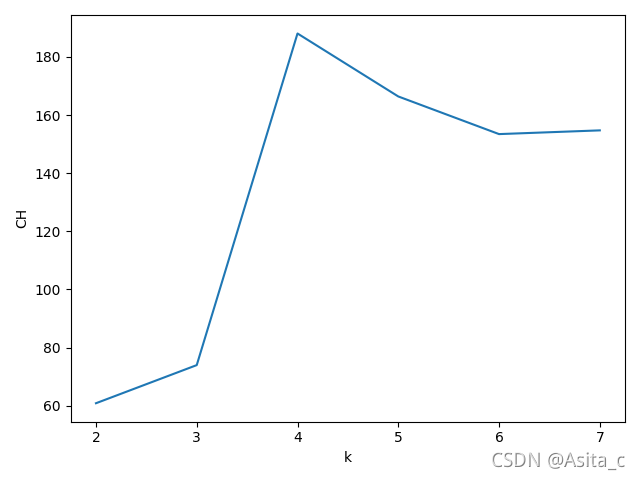
可以看到,当k=4时对于该数据集的聚类效果是最好的。