一、概述
训练深度学习模型既简单又复杂。因为使用 TensorFlow(特别是tensorflow.keras)这样的库非常容易上手。但是,虽然创建第一个模型很容易,但在知道自己在做什么的同时对其进行微调则要复杂一些。
比如,您需要了解有关监督学习过程、梯度下降或其他优化、正则化以及许多其他影响因素。
因此,洞察正在发生的事情和自动化控制是调整深度学习模型非常重要的一点,以避免浪费时间进行人工干预。在 Keras 中,这可以通过tensorflow.keras.callbacksAPI 来实现。在本文中,我们将更详细地研究回调。我们将首先通过展示它们在监督机器学习过程中的作用来说明它们是什么。然后,我们介绍回调 API - 并针对每个回调,用示例说明它可以用于什么。最后,我们将展示如何使用tensorflow.keras.callbacks.Base该类创建自己的回调。
二、回调的作用
训练监督机器学习模型流程大致如下:
1、机器学习模型(通常是神经网络)被初始化。
2、训练集中的样本通过模型前馈,从而产生一组预测。
3、将预测与训练样本对应的标签进行比较,产生一个值(损失值)告诉我们模型预测和真值的差距。
4、基于损失值和随后的误差反向计算,进行权重微调,以期望模型表现得更好一些。然后,我们要么回到第 2 步,要么停止训练过程。
训练流程示意图如下
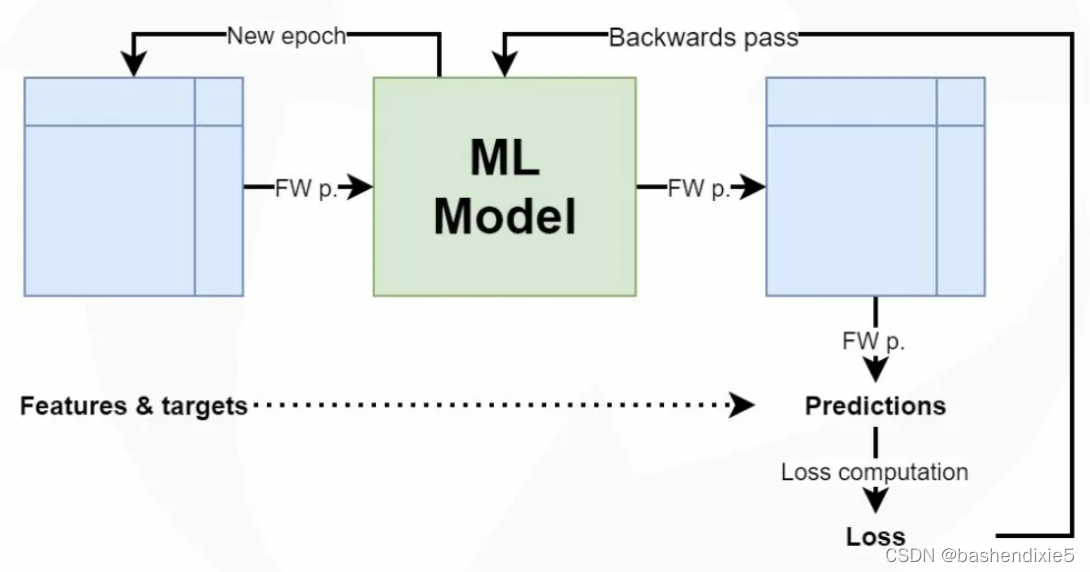
在机器学习术语中,每次迭代也称为epoch。因此,训练机器学习模型需要完成至少一次,但通常是多个epoch。我们通常不会一次前馈所有数据。相反,我们使用所谓的小批量方法——整批数据以称为小批量进行前馈。因此,每个 epoch 至少包含一个但通常是多个批次的数据。
现在,我们希望在对训练过程进行监控。这种情况下我们向Keras模型添加回调。回调是一个对象,它可以在训练的各个阶段(例如,在一个时期的开始或结束,单个批次之前或之后等)执行操作。
对于回调的时间点,Keras提供了多个定义。
on_train_begin、on_train_end --- 训练开始、训练结束
on_epoch_begin、on_epoch_end --- 一个epoch开始或结束
on_test_begin、on_test_end --- 评估模型开始或结束
on_predict_begin、on_predict_end --- 预测开始或结束
on_predict_batch_begin、on_predict_batch_end --- 批量预测开始或结束
on_train_batch_begin、on_train_batch_end、on_test_batch_begin、on_test_batch_end --- 批次输入到训练或测试过程之前或之后直接执行特定操作。
三、Keras回调API
现在我们了解了回调是什么,以及在基于 TensorFlow 2.x 的 Keras 中,哪些定义以及挂钩可用的“时间点”。现在,是时候看看 Keras 回调 API,即tensorflow.keras.callbacks,它是一组回调,可用于各种情况。
tensorflow.keras.callbacks它包含以下回调:
1、BaseLogger 回调:会积累训练轮平均评估的回调函数。
2、TerminateOnNaN 回调:如果损失值为非数字(NaN),则训练过程停止。
3、ProgbarLogger 回调:用于确定在 Keras 进度条中打印到标准输出的内容。
4、History 回调:
5、ModelCheckpoint 回调:可用于在每个 epoch 后自动保存一个模型,或者只保存最好的一个。
6、EarlyStopping 回调:确保在损失值不再提高时停止训练过程。
7、RemoteMonitor 回调:将 TensorFlow 训练事件发送到远程监视器,例如日志系统。
8、LearningRateScheduler 回调:基于一个scheduler函数在一个 epoch 开始之前更新学习率。
9、TensorBoard 回调:允许我们使用TensorBoard实时监控训练过程。
10、ReduceLROnPlateau 回调:如果损失值不再提高,则降低学习率。
11、CSVLogger 回调:将 epoch 的结果流式传输到 CSV 文件。
12、LambdaCallback:允许我们定义可以作为回调执行的简单函数。
四、如何添加回调
使用tensorflow.keras.callbacks API添加回调十分简单。
1、将特定回调导入。
2、初始化要使用的回调,包括它们的配置;
3、将回调添加到model.fit中。
通过这三个简单的步骤,回调与训练过程就会挂钩了。
例如,如果我们想同时使用ModelCheckpoint和EarlyStopping我们首先添加导入:
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint然后,对于步骤 (2),我们在列表中初始化回调:
keras_callbacks = [
EarlyStopping(monitor='val_loss', patience=5, mode='min', min_delta=0.01),
ModelCheckpoint(checkpoint_path, monitor='val_loss', save_best_only=True, mode='min')
]然后,对于第 (3) 步,我们只需将回调添加到model.fit:
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)五、了解各个回调
1、默认应用:History 和 BaseLogger 回调
有两个回调是tensorflow.keras.callbacks虽然是API的一部分,但是它们已经应用于在Keras模型的底层,所以一般不需要手动调用。
它们是History和BaseLogger回调。
回调在调用时History生成一个History 对象model.fit。
回调累积基本指标以BaseLogger供稍后显示。
2、ModelCheckpoint
如果您想定期将您的 Keras 模型(或模型权重)保存到某个文件,那么您需要ModelCheckpoint回调。会以某种频率保存 Keras 模型或模型权重的回调。
示例如下:
tf.keras.callbacks.ModelCheckpoint(
filepath, monitor='val_loss', verbose=0, save_best_only=False,
save_weights_only=False, mode='auto', save_freq='epoch', options=None, **kwargs
)参数说明:
filepath:您可以指定必须保存模型的位置。
monitor:如果您只想在某个数量发生变化时保存,您可以通过设置monitor。默认设置为验证损失。
verbose:可以指定回调输出是否应在标准输出(通常是终端)中输出。
save_best_only:如果您只想在准确率增加时保存模型,您可以设置save_best_only为True。
save_weights_only:通常,会保存整个模型- 即层堆栈以及模型权重。如果您只想保存权重(例如,因为您可以自己初始化模型),您可以设置save_weights_only为True.
mode:您可以确定monitor数量必须向哪个方向移动才能将其视为改进。您可以从中选择任何一个{auto, min, max}。设置为 时auto,mode根据monitor-with loss 来判断,例如为min; 准确地说,它将是max。
save_freq:允许指定save_freq何时保存模型。默认情况下,它在每个 epoch 后保存(或在每个 epoch 后检查它是否有所改进)。通过将'epoch'字符串更改为整数,您还可以指示 Keras 在每个nminibatch 后保存。
如果需要,您也可以指定其他兼容options的。查看ModelCheckpoint文档(请参阅参考资料中的链接)以获取有关这些options.
完整示例:
checkpoint_path=f'{os.path.dirname(os.path.realpath(__file__))}/covid-convnet.h5'
keras_callbacks = [
ModelCheckpoint(checkpoint_path, monitor='val_loss', save_best_only=True, mode='min')
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)3、TensorBoard
使用TensorBoard可以实时可视化训练过程。通过TensorBoard回调,您可以将 TensorBoard 与您的 Keras 模型链接。
回调将训练过程中的一系列项目记录到您的 TensorBoard 日志位置:
指标汇总图、训练图可视化、激活直方图、采样分析
示例如下:
tf.keras.callbacks.TensorBoard(
log_dir='logs', histogram_freq=0, write_graph=True, write_images=False,
update_freq='epoch', profile_batch=2, embeddings_freq=0,
embeddings_metadata=None, **kwargs
)参数说明:
log_dir: 用来保存被 TensorBoard 分析的日志文件的文件名。
istogram_freq: 对于模型中各个层计算激活值和模型权重直方图的频率(训练轮数中)。 如果设置成 0 ,直方图不会被计算。对于直方图可视化的验证数据(或分离数据)一定要明确的指出。
write_graph: 是否在 TensorBoard 中可视化图像。 如果 write_graph 被设置为 True,日志文件会变得非常大。
write_grads: 是否在 TensorBoard 中可视化梯度值直方图。 histogram_freq 必须要大于 0 。
batch_size: 用以直方图计算的传入神经元网络输入批的大小。
write_images: 是否在 TensorBoard 中将模型权重以图片可视化。
embeddings_freq: 被选中的嵌入层会被保存的频率(在训练轮中)。
embeddings_layer_names: 一个列表,会被监测层的名字。 如果是 None 或空列表,那么所有的嵌入层都会被监测。
embeddings_metadata: 一个字典,对应层的名字到保存有这个嵌入层元数据文件的名字。 查看 详情 关于元数据的数据格式。 以防同样的元数据被用于所用的嵌入层,字符串可以被传入。
embeddings_data: 要嵌入在 embeddings_layer_names 指定的层的数据。 Numpy 数组(如果模型有单个输入)或 Numpy 数组列表(如果模型有多个输入)。 Learn ore about embeddings。
update_freq: 'batch' 或 'epoch' 或 整数。当使用 'batch' 时,在每个 batch 之后将损失和评估值写入到 TensorBoard 中。同样的情况应用到 'epoch' 中。如果使用整数,例如 10000,这个回调会在每 10000 个样本之后将损失和评估值写入到 TensorBoard 中。注意,频繁地写入到 TensorBoard 会减缓你的训练。
完整示例:
keras_callbacks = [
TensorBoard(log_dir="./logs")
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)4、EarlyStopping
一般应用EarlyStopping是用于当监控的指标长时间停止改进,希望模型就此停止训练的场景。
示例如下:
tf.keras.callbacks.EarlyStopping(
monitor='val_loss', min_delta=0, patience=0, verbose=0, mode='auto',
baseline=None, restore_best_weights=False
)参数说明:
monitor是监控改进的数量;它类似于监控的数量ModelCheckpointing。
对于mode,{auto, min, max} 其中之一。 在 min 模式中, 当被监测的数据停止下降,训练就会停止;在 max 模式中,当被监测的数据停止上升,训练就会停止;在 auto 模式中,方向会自动从被监测的数据的名字中判断出来。
使用min_delta,您可以配置必须从当前发生的最小更改,monitor以便将更改视为改进。
使用patience,您可以指示在停止训练过程之前等待额外改进的时间。
使用verbose,您可以指定回调的详细程度,即是否将输出写入标准输出。
该baseline值可以配置为指定在任何更改都可以被视为改进monitor之前必须达到的最小值
如您所料,patience大于 0 将确保模型经过patience更多时期的训练,可能会使情况变得更糟。有了restore_best_weights,我们可以在训练过程停止时恢复表现最好的模型实例的权重。如果您在停止训练过程后直接执行模型评估,这将很有用。
完整示例:
keras_callbacks = [
EarlyStopping(monitor='val_loss', min_delta=0.001, restore_best_weights=True)
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)5、LearningRateScheduler
学习率最好在早期迭代中相对较大,在后期阶段较低,我们必须在训练过程中调整学习率。这称为学习率衰减。LearningRateScheduler回调实现了这个功能。
在每个 epoch 开始时,此回调从schedule提供的函数中获取更新的学习率值,以及当前 epoch 和当前学习率,并将更新的学习率应用于优化器。
示例如下:
tf.keras.callbacks.LearningRateScheduler(
schedule, verbose=0
)参数说明:
接受一个schedule函数,您可以使用该函数来决定在每个时期必须如何安排学习率。
使用verbose,您可以决定在标准输出中说明回调输出。
完整示例:
def scheduler(epoch, learning_rate):
if epoch < 15:
return learning_rate
else:
return learning_rate * 0.99
keras_callbacks = [
LearningRateScheduler(scheduler)
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)6、ReduceLROnPlateau
当标准评估停止提升时,降低学习速率。通过ReduceLROnPlateau回调,可以指示优化过程在遇到平台期时降低学习率(并因此降低步长)。
一旦学习停滞,模型通常会受益于将学习率降低 2-10 倍。此回调监视一个数量,如果“耐心”的 epoch 数量没有改善,则学习率会降低。
示例如下:
tf.keras.callbacks.ReduceLROnPlateau(
monitor='val_loss', factor=0.1, patience=10, verbose=0, mode='auto',
min_delta=0.0001, cooldown=0, min_lr=0, **kwargs
)参数说明:
monitor: 被监测的数据。
factor: 学习速率被降低的因数。新的学习速率 = 学习速率 * 因数
patience: 没有进步的训练轮数,在这之后训练速率会被降低。
verbose: 整数。0:安静,1:更新信息。
mode: {auto, min, max} 其中之一。如果是 min 模式,学习速率会被降低如果被监测的数据已经停止下降; 在 max 模式,学习塑料会被降低如果被监测的数据已经停止上升; 在 auto 模式,方向会被从被监测的数据中自动推断出来。
min_delta: 对于测量新的最优化的阀值,只关注巨大的改变。
cooldown: 在学习速率被降低之后,重新恢复正常操作之前等待的训练轮数量。
min_lr: 学习速率的下边界。
完整示例:
keras_callbacks = [
ReduceLROnPlateau(monitor='val_loss', factor=0.25, patience=5, cooldown=5, min_lr=0.000000001)
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)7、RemoteMonitor
回调用于将事件流式传输到服务器。
上面,我们看到训练日志可以分发到TensorBoard以进行可视化和日志记录。但是,您可能拥有自己的日志记录和可视化系统——无论是基于云的系统还是本地安装的 Grafana 或 Elastic Stack 可视化工具。
在这些情况下,您可能希望将训练日志发送到那里。RemoteMonitor回调可以帮助您做到这一点。
示例如下:
tf.keras.callbacks.RemoteMonitor(
root='http://localhost:9000', path='/publish/epoch/end/', field='data',
headers=None, send_as_json=False
)参数说明:
root: 字符串;目标服务器的根地址。
path: 字符串;相对于 root 的路径,事件数据被送达的地址。
field: 字符串;JSON ,数据被保存的领域。
headers: 字典;可选自定义的 HTTP 的头字段。
send_as_json: 布尔值;请求是否应该以 application/json 格式发送。
8、Lambda
在训练进行中创建简单,自定义的回调函数的回调函数。
在这里,可以用 Python 定义填充基于on_epoch_begin、on_epoch_end、on_batch_begin、和事件的参数。它们在正确的时间点执行。on_batch_endon_train_beginon_train_end
示例如下:
tf.keras.callbacks.LambdaCallback(
on_epoch_begin=None, on_epoch_end=None, on_batch_begin=None, on_batch_end=None,
on_train_begin=None, on_train_end=None, **kwargs
)
keras_callbacks = [
LambdaCallback(on_batch_end=lambda batch, log_data: print(batch))
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)9、TerminateOnNaN
遇到 NaN 损失时终止训练的回调。
keras_callbacks = [
TerminateOnNaN()
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)10、CSVLogger
把训练轮结果数据流到 csv 文件的回调函数。
该filename属性确定 CSV 文件的位置。如果没有,它将被创建。
该separator属性确定用什么字符分隔单行中的列,也称为分隔符。
使用append,您可以指示是否应将数据简单地添加到文件末尾,或者每次新文件都应覆盖旧文件。
keras_callbacks = [
CSVLogger('./logs.csv', separator=';', append=True)
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)11、ProgbarLogger
会把评估以标准输出打印的回调函数。
count_mode: "steps" 或者 "samples"。 进度条是否应该计数看见的样本或步骤(批量)。
stateful_metrics: 可重复使用不应在一个 epoch 上平均的指标的字符串名称。 此列表中的度量标准将按原样记录在 on_epoch_end 中。 所有其他指标将在 on_epoch_end 中取平均值。
keras_callbacks = [
ProgbarLogger(count_mode='samples')
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)六、实验性回调BackupAndRestore
当您训练神经网络时,尤其是在分布式环境中,如果您的训练过程突然停止(例如由于机器故障),将会出现问题。到目前为止通过的每个迭代都将消失。通过实验性BackupAndRestore回调,您可以指示 Keras 在每个 epoch 之后创建临时检查点文件,您可以稍后恢复到这些文件。
BackupAndRestore callback 旨在通过在每个 epoch 结束时将训练状态备份到临时检查点文件(基于 TF CheckpointManager)中,从 model.fit 执行过程中发生的中断中恢复。
backup_dir属性指示应在其中创建检查点的文件夹。
keras_callbacks = [
BackupAndRestore('./checkpoints')
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)七、使用 Base Callback 创建自己的回调
有时,默认值或lambda回调都不能提供您需要的功能。在这些情况下,您可以使用 Base 回调类创建自己的回调tensorflow.keras.callbacks.Callback。创建一个非常简单:您定义一个class,创建相关定义(您可以从on_epoch_begin、on_epoch_end、on_batch_begin、on_batch_end等中选择),on_train_begin然后on_train_end将回调添加到您的回调列表中。
class OwnCallback(tensorflow.keras.callbacks.Callback):
def on_train_begin(self, logs=None):
print('Training is now beginning!')
keras_callbacks = [
OwnCallback()
]
model.fit(train_generator,
epochs=50,
verbose=1,
callbacks=keras_callbacks,
validation_data=val_generator)