案例1
背景
我们知道,ThreadLocal 适用于变量在线程间隔离,而在方法或类间共享的场景。如果用户信息的获取比较昂贵(比如从数据库查询用户信息),那么在 ThreadLocal 中缓存数据是比较合适的做法。但,这么做为什么会出现用户信息错乱的 Bug 呢?
存在问题案例
@RestController
@RequestMapping("/threadlocal")
public class UserController {
/**
* 线程池中初始值默认为null
*/
private ThreadLocal<Integer> currentUser = ThreadLocal.withInitial(()->null);
@GetMapping("/wrong")
public Map wrong(@RequestParam("userId") Integer userId) {
//设置用户信息之前先查询一次ThreadLocal中的用户信息
String before = Thread.currentThread().getName() + ":" + currentUser.get();
//设置用户信息到ThreadLocal
currentUser.set(userId);
// 设置用户信息之后再查询一次ThreadLocal中的用户信息
String after = Thread.currentThread().getName() + ":" + currentUser.get();
//汇总输出两次查询结果
Map result = new HashMap();
result.put("before", before);
result.put("after", after);
return result;
}
}
为了能够让问题快速重现,设置为tocat最大的线程为1
server:
tomcat:
threads:
max: 1
测试


在输入userId等于2时发现线程1并不是初始值null
这是为什么呢?首先理解代码为什么会在多线程下运行?我们设置的环境是单线程的
虽然我们的代码是在单线程环境中,但是底层是用tomcat(工作线程是基于线程池的)或者web服务器上运行是多线程,并不是不在多线程运行就代表线程安全。
解决方案案例
将每次执行完作业后就移除线程池
@RestController
@RequestMapping("/threadlocal")
public class UserController {
/**
* 线程池中初始值默认为null
*/
private ThreadLocal<Integer> currentUser = ThreadLocal.withInitial(()->null);
@GetMapping("/wrong")
public Map wrong(@RequestParam("userId") Integer userId) {
//设置用户信息之前先查询一次ThreadLocal中的用户信息
String before = Thread.currentThread().getName() + ":" + currentUser.get();
//设置用户信息到ThreadLocal
currentUser.set(userId);
try {
// 设置用户信息之后再查询一次ThreadLocal中的用户信息
String after = Thread.currentThread().getName() + ":" + currentUser.get();
//汇总输出两次查询结果
Map result = new HashMap();
result.put("before", before);
result.put("after", after);
return result;
} finally {
currentUser.remove();
}
}
}
再次测试


案例2
背景
误认为ConcurrentHashMap是线程安全的,ConcurrentHashMap只保证提供的原子性读写操作是线程安全的。
有一个含有800个元素的Map,需要再补充100给元素,交给多线程进行处理
存在问题案例
/**
* 线程数量
*/
private static int THREAD_COUNT = 10;
/**
* 总元素数量
*/
private static int ITEM_COUNT = 900;
/**
* 用来获取元素模拟数据的ConcurrentHashMap
* @param count
* @return
*/
public ConcurrentHashMap<String,Long> getData(int count) {
return LongStream.rangeClosed(1,count)
.boxed()
.collect(Collectors.toMap(i -> UUID.randomUUID().toString(), Function.identity(),
(o1,o2) -> o1,ConcurrentHashMap::new));
}
@GetMapping("/wrong3")
public String wrong3() throws InterruptedException {
ConcurrentHashMap<String, Long> concurrentHashMap = getData(ITEM_COUNT - 100);
// 初始化800给元素
log.info("init size:{}",concurrentHashMap.size());
ForkJoinPool forkJoinPool =new ForkJoinPool(THREAD_COUNT);
// 使用线程池并发处理逻辑
forkJoinPool.execute(() -> IntStream.rangeClosed(1,10).parallel().forEach(i -> {
// 查询还需要补充多少元素
int gap = ITEM_COUNT - concurrentHashMap.size();
log.info("gap size:{}",gap);
// 补充元素
concurrentHashMap.putAll(getData(gap));
}));
// 等待所有的任务完成
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
// 最后元素给书会是9000吗?
log.info("finish size:{}",concurrentHashMap.size());
return "OK";
}
测试

发现我们只需填充100的最后总数缺变成了1800
解决方案案例
我们只需对ConcurrentHashMap对外提供的方法或能力进行限制,怎么限制呢?加同步锁
@GetMapping("/wrong4")
public String wrong4() throws InterruptedException {
ConcurrentHashMap<String, Long> concurrentHashMap = getData(ITEM_COUNT - 100);
// 初始化800给元素
log.info("init size:{}",concurrentHashMap.size());
ForkJoinPool forkJoinPool =new ForkJoinPool(THREAD_COUNT);
// 使用线程池并发处理逻辑
forkJoinPool.execute(() -> IntStream.rangeClosed(1,10).parallel().forEach(i -> {
synchronized (concurrentHashMap) {
// 查询还需要补充多少元素
int gap = ITEM_COUNT - concurrentHashMap.size();
log.info("gap size:{}",gap);
// 补充元素
concurrentHashMap.putAll(getData(gap));
}
}));
// 等待所有的任务完成
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
// 最后元素给书会是900吗?
log.info("finish size:{}",concurrentHashMap.size());
return "OK";
}
再次测试,发现可以了!

案例3
背景
没有充分了解并发工具的特性,从而无法发挥其威力
依旧会有使用新的数据结构而调用就的方法
未优化案例
@GetMapping("/wrong5")
public Map<String, Long> wrong5() throws InterruptedException {
ConcurrentHashMap<String, Long> freqs =new ConcurrentHashMap<>(ITEM_COUNT);
// 初始化0个元素
log.info("init size:{}",freqs.size());
ForkJoinPool forkJoinPool =new ForkJoinPool(THREAD_COUNT);
// 使用线程池并发处理逻辑
forkJoinPool.execute(() -> IntStream.rangeClosed(1,Loop_COUNT).parallel().forEach(i -> {
String key = "item" + ThreadLocalRandom.current().nextInt(ITEM_COUNT);
synchronized (freqs) {
if (freqs.containsKey(key)) {
freqs.put(key, freqs.get(key) + 1);
} else {
freqs.put(key, 1L);
}
}
}));
// 等待所有的任务完成
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
// 最后元素给书会是1000吗?
log.info("finish size:{}",freqs.size());
return freqs;
}
优化后案例
使用ConcurrentHashMap新特性computeIfAbsent
/**
* ConcurrentHashMap新特性
* @return
* @throws InterruptedException
*/
@GetMapping("/wrong6")
public Map<String, Long> wrong6() throws InterruptedException {
ConcurrentHashMap<String, LongAdder> freqs =new ConcurrentHashMap<>(ITEM_COUNT);
// 初始化0个元素
log.info("init size:{}",freqs.size());
ForkJoinPool forkJoinPool =new ForkJoinPool(THREAD_COUNT);
// 使用线程池并发处理逻辑
forkJoinPool.execute(() -> IntStream.rangeClosed(1,Loop_COUNT).parallel().forEach(i -> {
String key = "item" + ThreadLocalRandom.current().nextInt(ITEM_COUNT);
freqs.computeIfAbsent(key,k->new LongAdder()).increment();
}));
// 等待所有的任务完成
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
// 最后元素给书会是1000吗?
log.info("finish size:{}",freqs.size());
return freqs.entrySet().stream()
.collect(Collectors.toMap(e->e.getKey(),e->e.getValue().longValue()));
}
测试
@GetMapping("/good")
public String good() throws InterruptedException {
StopWatch stopWatch = new StopWatch();
stopWatch.start("wrong5");
Map<String, Long> wrong5 = wrong5();
stopWatch.stop();
Assert.isTrue(wrong5.size() == ITEM_COUNT,"wrong5 size error");
Assert.isTrue(wrong5.entrySet().stream().mapToLong(item->item.getValue()).reduce(0,Long::sum) == Loop_COUNT,"wrong5 count error");
stopWatch.start("wrong6");
Map<String, Long> wrong6 = wrong6();
stopWatch.stop();
Assert.isTrue(wrong6.size() == ITEM_COUNT,"wrong6 size error");
Assert.isTrue(wrong6.entrySet().stream().mapToLong(item->item.getValue()).reduce(0,Long::sum) == Loop_COUNT,"wrong6 count error");
System.out.println(stopWatch.prettyPrint());
return "ok";
}
使用StopWatch进行比较,使用computeIfAbsent效率提高十倍。
ps:Spring计时器StopWatch使用
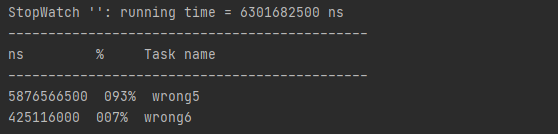
为什么使用computeIfAbsent效率就会这么高?
原来是Java有自带的CAS,它是确保Java虚拟机底层确保写入数据的原子性。

案例4
背景
没有认清并发工具的使用场景,因而导致性能问题
在 Java 中,CopyOnWriteArrayList 虽然是一个线程安全的 ArrayList,但因为其实现方式是,每次修改数据时都会复制一份数据出来,所以有明显的适用场景,即读多写少或者说希望无锁读的场景
案例
@GetMapping("write")
public Map testWriter() {
List<Integer> copyOnWriteArrayList = new CopyOnWriteArrayList<>();
List<Object> synchronizedList = Collections.synchronizedList(new ArrayList<>());
StopWatch stopWatch = new StopWatch();
int loopCount =100000;
stopWatch.start("Write:copyOnWriteArrayList");
IntStream.rangeClosed(0,loopCount).parallel().forEach(__->copyOnWriteArrayList.add(ThreadLocalRandom.current().nextInt(loopCount) ));
stopWatch.stop();
stopWatch.start("Write:synchronizedList");
IntStream.rangeClosed(0,loopCount).parallel().forEach(__->synchronizedList.add(ThreadLocalRandom.current().nextInt(loopCount) ));
stopWatch.stop();
log.info(stopWatch.prettyPrint());
Map map = new HashMap();
map.put("copyOnWriteArrayList",copyOnWriteArrayList.size());
map.put("synchronizedList",synchronizedList.size());
return map;
}
/**
* 获取数据
* void
*/
private void addAll(List<Integer> list) {
list.addAll(IntStream.rangeClosed(1,Loop_COUNT).boxed().collect(Collectors.toList()));
}
@GetMapping("read")
public Map testRead() {
List<Integer> copyOnWriteArrayList = new CopyOnWriteArrayList<>();
List<Integer> synchronizedList = Collections.synchronizedList(new ArrayList<>());
addAll(copyOnWriteArrayList);
addAll(synchronizedList);
StopWatch stopWatch = new StopWatch();
int loopCount = 100000;
int count = copyOnWriteArrayList.size();
stopWatch.start("Read:copyOnWriteArrayList");
IntStream.rangeClosed(0,loopCount).parallel().forEach(__->copyOnWriteArrayList.get(ThreadLocalRandom.current().nextInt(count) ));
stopWatch.stop();
stopWatch.start("Read:synchronizedList");
IntStream.rangeClosed(0,loopCount).parallel().forEach(__->synchronizedList.get(ThreadLocalRandom.current().nextInt(count) ));
stopWatch.stop();
log.info(stopWatch.prettyPrint());
Map map = new HashMap();
map.put("copyOnWriteArrayList",copyOnWriteArrayList.size());
map.put("synchronizedList",synchronizedList.size());
return map;
}
测试
