1. 序言
脑电信号是一种非平稳的随机信号,一般而言随机信号的持续时间是无限长的,因此随机信号的总能量是无限的,而随机过程的任意一个样本函数都不满足绝对可积条件,所以其傅里叶变换不存在。
不过,尽管随机信号的总能量是无限的,但其平均功率却是有限的,因此,要对随机信号的频域进行分析,应从功率谱出发进行研究才有意义。正因如此,在研究中经常使用功率谱密度(Power spectral density, PSD)来分析脑电信号的频域特性。
本文简单的演示了对脑电信号提取功率谱密度特征然后分类的基本流程。希望对那些尚未入门、面对 BCI 任务不知所措的新手能有一点启发。
2. 功率谱密度理论基础简述
功率谱密度描是对随机变量均方值的量度,是单位频率的平均功率量纲。对功率谱在频域上积分就可以得到信号的平均功率。
功率谱密度 S ( f ) S(f) S(f) 是一个以频率 f f f 为自变量的映射, S ( f ) S(f) S(f) 反映了在频率成分 f f f 上信号有多少功率。
我们假定一个随机过程 X ( t ) X(t) X(t),并定义一个截断阈值 t 0 t_0 t0,随机过程 X X X 的截断过程 X t 0 ( t ) X_{t_0}(t) Xt0(t) 就可以定义为
X t 0 ( t ) = { X ( t ) ∣ t ∣ ≤ t o 0 ∣ t ∣ > t o \begin{aligned} X_{t_0}(t)=\left\{\begin{array}{cl} X(t) & |t| \leq t_{o} \\ 0 & |t|>t_{o} \end{array}\right. \end{aligned} Xt0(t)={ X(t)0∣t∣≤to∣t∣>to
则该随机过程的能量可定义为
E X t 0 = ∫ − t 0 t 0 X 2 ( t ) d t = ∫ − ∞ ∞ X t 0 2 ( t ) d t \begin{aligned} E_{X_{t_0}}=\int_{-t_0}^{t_0} X^{2}(t) d t=\int_{-\infty}^{\infty} X_{t_0}^{2}(t) dt \end{aligned} EXt0=∫−t0t0X2(t)dt=∫−∞∞Xt02(t)dt
对能量函数求导,就可以获得平均功率。
P X t 0 = 1 2 t o ∫ − ∞ ∞ X t 0 2 ( t ) d t \begin{aligned} P_{X_{t_0}}=\frac{1}{2 t_{o}} \int_{-\infty}^{\infty} X_{t_0}^{2}(t) dt \end{aligned} PXt0=2to1∫−∞∞Xt02(t)dt
根据 Parseval 定理(即能量从时域角度和频域角度来看都是相等的)可得:
P X t 0 = 1 2 t o ∫ − ∞ ∞ ∣ X t 0 2 ( f ) ∣ 2 d f \begin{aligned} P_{X_{t_0}} =\frac{1}{2 t_{o}} \int_{-\infty}^{\infty}\left|X_{t_0}^{2}(f)\right|^{2} df \end{aligned} PXt0=2to1∫−∞∞∣∣Xt02(f)∣∣2df
这里 X t 0 ( f ) X_{t_0}(f) Xt0(f) 是 X t 0 ( t ) X_{t_0}(t) Xt0(t) 经过傅里叶变换后的形式。由于随机过程 X X X 被限定在了一个有限的时间区间 [ − t 0 , t 0 ] [-t_0, t_0] [−t0,t0] 之间,所以对随机过程的傅里叶变换不再受限。另外我们还需要注意到, P X t 0 P_{X_{t_0}} PXt0 是一个随机变量,因此为了得到最终总体的平均功率,还需要求取随机变量的期望值。
P X t 0 ‾ = E [ P X t 0 ] = 1 2 t o ∫ − ∞ ∞ E [ ∣ X t 0 2 ( f ) ∣ 2 ] d f \begin{aligned} \overline{P_{X_{t_0}}} = E \left[ P_{X_{t_0}} \right] = \frac{1}{2 t_{o}} \int_{-\infty}^{\infty} E\left[\left|X_{t_0}^{2}(f)\right|^{2}\right] df \end{aligned} PXt0=E[PXt0]=2to1∫−∞∞E[∣∣Xt02(f)∣∣2]df
由此,通过求取 t 0 → ∞ t_0 \rightarrow \infty t0→∞ 时的极限,就可以得到原始随机过程的平均功率 P X ‾ \overline{P_X} PX。
P X ‾ = lim t 0 → ∞ 1 2 t 0 ∫ − ∞ ∞ E [ ∣ X t 0 ( f ) ∣ ] d f = ∫ − ∞ ∞ lim t 0 → ∞ E [ ∣ X t 0 ( f ) ∣ ] 2 t 0 d f \begin{aligned} \overline{P_{X}}=\lim_{t_{0} \rightarrow \infty} \frac{1}{2 t_{0}} \int_{-\infty}^{\infty} E\left[\left|X_{t_0}(f)\right|\right] d f=\int_{-\infty}^{\infty} \lim_{t_{0} \rightarrow \infty} \frac{E\left[\left|X_{t_0}(f)\right|\right]}{2 t_{0}} df \end{aligned} PX=t0→∞lim2t01∫−∞∞E[∣Xt0(f)∣]df=∫−∞∞t0→∞lim2t0E[∣Xt0(f)∣]df
将式中被积函数单独提取出来,定义为 S ( f ) S(f) S(f):
S ( f ) = lim t 0 → ∞ E [ ∣ X t 0 ( f ) ∣ ] 2 t 0 \begin{aligned} S(f) = \lim_{t_0 \rightarrow \infty} \frac{E\left[\left|X_{t_0}(f)\right|\right]}{2 t_{0}} \end{aligned} S(f)=t0→∞lim2t0E[∣Xt0(f)∣]
这样一来,平均功率 P X ‾ \overline{P_X} PX 可以表示为 ∫ − ∞ ∞ S ( f ) d f \int_{-\infty}^{\infty}S(f) df ∫−∞∞S(f)df。通过这种定义方式,函数 S ( f ) S(f) S(f) 可以表征每一个最小极限单位的频率分量所拥有的功率大小,因此我们把 S ( f ) S(f) S(f) 称为功率谱密度。
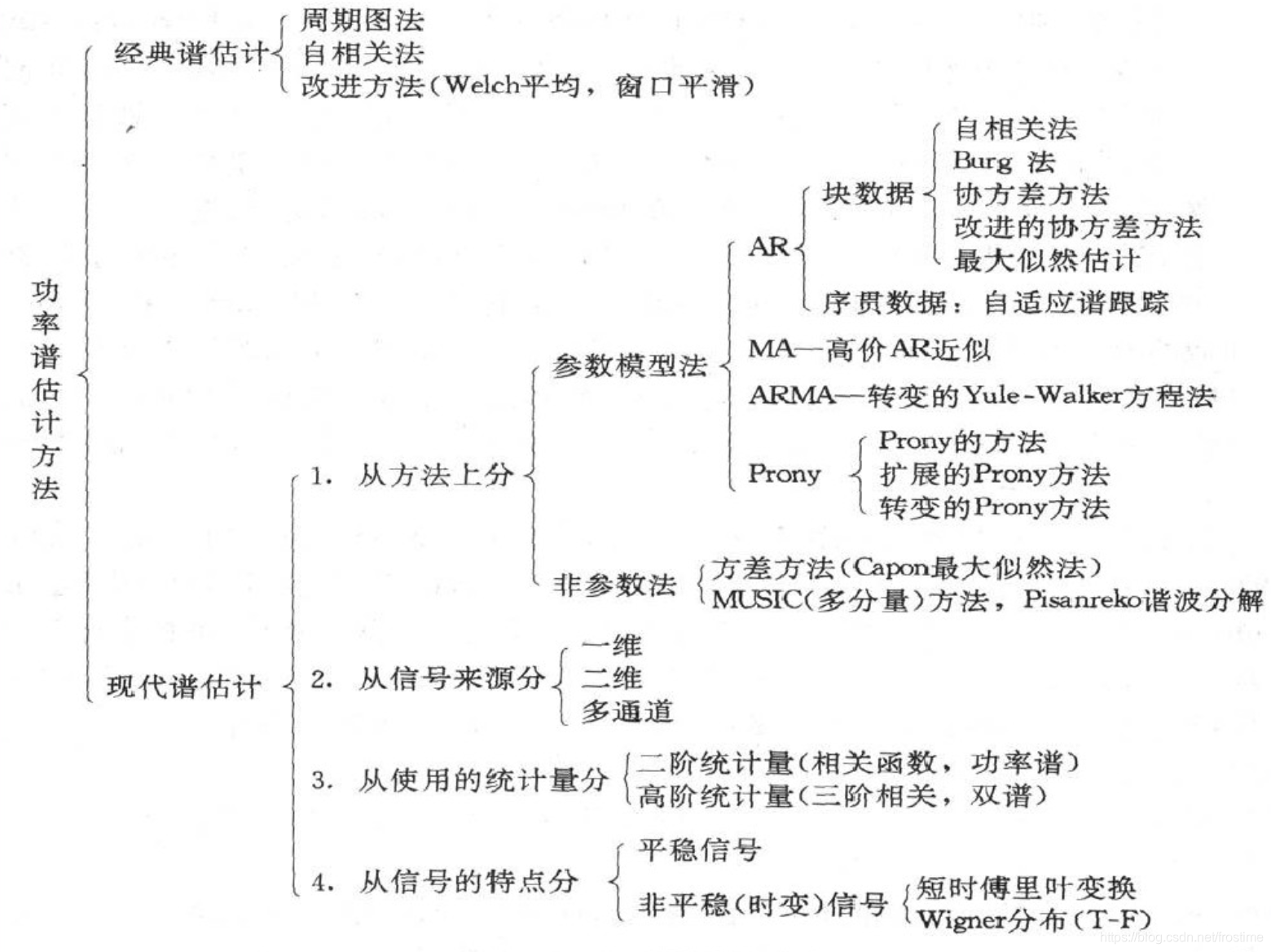
3. Matlab 中 PSD 函数的使用
功率谱密度的估计方法有很多。总体来讲可以分为两大类:传统的非参数方法,和现代的参数方法。
本节不对理论知识做详细的叙述,感兴趣的可以深入查阅文献,这里只介绍一下有哪些方法,以及他们在 matlab 当中的使用。
3.1 传统非参数方法估计 PSD
最简单的方法是周期图法,先对信号做 FFT 变换,然后求平方,periodogram 函数实现了这个功能。不过周期图法估计的方差随采样点数N的增加而增加,不是很建议使用。
另一种自相关方法,基于维纳辛钦定律:信号的功率谱估计等于该信号自相关函数的离散DTFT,不过我没有在 matlab 里找到对应的函数,如果有知道的朋友请告诉我一下。
最常用的函数是 pwelch 函数,利用 welch 方法来求 PSD,这也是最推荐使用的。
3.2 参数方法估计 PSD
包括 pconv、pburg、pyulear 等几个方法。
这些方法我没用过,所以也不敢随便乱说。
4. 实验示例
给出从 EEG 信号中提取功率谱特征并分类的简单范例。
4.1 实验数据
本文选用的实验数据为BCI Competition Ⅱ的任务四,使用的数据为 sp1s_aa_1000Hz.mat。
这个数据集中,受试者坐在一张椅子上,手臂放在桌子上,手指放在电脑键盘的标准打字位置。被试需要用食指和小指依照自己选择的顺序按相应的键。实验的目标是预测按键前130毫秒手指运动的方向(左 OR 右)。
在 matlab 中导入数据。
%% 导入数据
% 1000 Hz 记录了 500 ms
load('sp1s_aa_1000Hz.mat');
% 采样率 1000 Hz
srate = 1000;
[frames, channels, epochs] = size(x_train);
rightwards = sum(y_train);
leftwards = length(y_train) - rightwards;
fprintf('一共有 %d 个训练样本,其中往左运动有 %d 个,往右运动有 %d 个\n',...
length(y_train), leftwards, rightwards);
一共有 316 个训练样本,其中往左运动有 159 个,往右运动有 157 个
4.2 提取特征
我们使用 welch 法来提取功率谱密度,利用 pwelch 函数计算功率谱,使用 bandpower 函数可以提取特定频段的功率信息,所以分别提取 δ \delta δ、 θ \theta θ、 α \alpha α、 β \beta β节律的功率。最后取各通道平均功率的前12个点(根据 f 来看,前 12 个点基本覆盖了 0到 40Hz 的频带)
%% 提取 PSD 特征
function [power_features] = ExtractPowerSpectralFeature(eeg_data, srate)
% 从 EEG 信号中提取功率谱特征
% Parameters:
% eeg_data: [channels, frames] 的 EEG 信号数据
% srate: int, 采样率
% Returns:
% eeg_segments: [1, n_features] vector
%% 计算各个节律频带的信号功率
[pxx, f] = pwelch(eeg_data, [], [], [], srate);
power_delta = bandpower(pxx, f, [0.5, 4], 'psd');
power_theta = bandpower(pxx, f, [4, 8], 'psd');
power_alpha = bandpower(pxx, f, [8, 14], 'psd');
power_beta = bandpower(pxx, f, [14, 30], 'psd');
% 求 pxx 在通道维度上的平均值
mean_pxx = mean(pxx, 2);
% 简单地堆叠起来构成特征(可以用更高级地方法,比如考虑通道之间的相关性的方法构成特征向量)
power_features = [
power_delta, power_theta, ...
power_alpha, power_beta, ...
mean_pxx(1:12)';
];
end
然后对每个样本都提取特征,构造一个二维矩阵 X_train_features。
X_train_features = [];
for i = 1:epochs
% 取出数据
eeg_data = squeeze(x_train(:, :, i));
feature = ExtractPowerSpectralFeature(eeg_data, srate);
X_train_features = [X_train_features; feature];
end
% 原始的 y_train 是行向量,展开成列向量
y_train = y_train(:);
4.3 分类
使用 SVM 进行简单的分类任务,由于只是简单演示,所以不划分训练集、交叉验证集。
% 由于只是简单演示,所以不划分训练集、交叉验证集
model = fitcsvm(X_train_features, y_train,...
'Standardize', true, 'KernelFunction', 'RBF', 'KernelScale', 'auto', 'verbose', 1);
y_pred = model.predict(X_train_features);
acc = sum(y_pred == y_train) / length(y_pred);
fprintf('Train Accuracy: %.2f%%\n', acc * 100);
结果如下:
|===================================================================================================================================|
| Iteration | Set | Set Size | Feasibility | Delta | KKT | Number of | Objective | Constraint |
| | | | Gap | Gradient | Violation | Supp. Vec. | | Violation |
|===================================================================================================================================|
| 0 |active| 316 | 9.968454e-01 | 2.000000e+00 | 1.000000e+00 | 0 | 0.000000e+00 | 0.000000e+00 |
| 350 |active| 316 | 5.175246e-05 | 9.741516e-04 | 5.129944e-04 | 312 | -1.850933e+02 | 5.967449e-16 |
由于 DeltaGradient,收敛时退出活动集。
Train Accuracy: 94.62%
Extra Update (2021.11)
Update On 2021/11/04。
之前写这篇文章几乎是随手写的,无论是文本还是代码都写得很粗糙。但不曾想这篇文章这么受欢迎,以至于之前粗糙的地方使得不断有朋友来提出疑问。比如这样。
我在这里再加一些解释。
在本文的 demo 里,我调用了 pwelch 函数。
[pxx, f] = pwelch(eeg_data, [], [], [], srate);
这个函数的具体调用格式应该是:
[pxx,f] = pwelch(x,window,noverlap,f,fs)
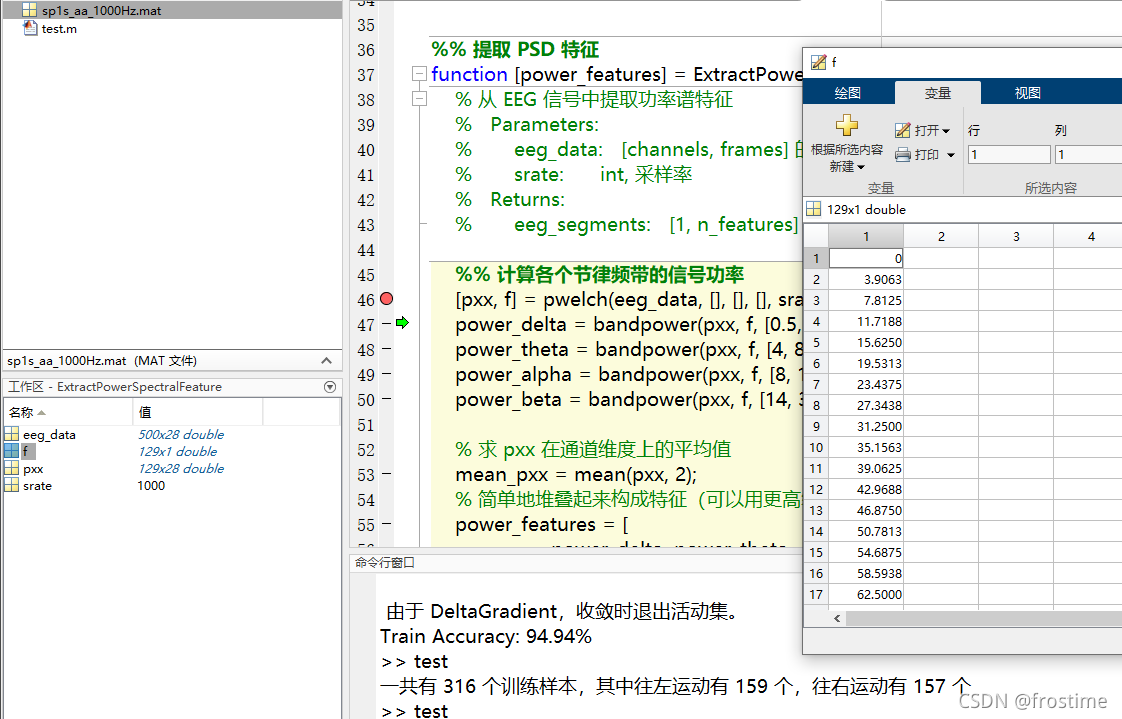
因为偷懒,中间的三个参数 window、noverlap、f 都被我省略掉了。根据 pwelch 的官方文档,如果 f 空着不写,就会被默认解释为256 个 nfft (也就是 fft 的点的个数)。

而 pwelch 默认做的是双边谱分析,所以参与单边 FFT 的点的个数就是 256 / 2 +1 = 129 个,刨除掉 0Hz 的一个点,也就是总共 128 个点。由于我们信号的采样率是 1000Hz,所以单边谱的最大频率范围也就是 500Hz。频率分辨率就是 500 / 129 = 3.9Hz。
我们可以简单验证,在 pwelch 的地方打一个断点。可以看到 f 是一个 [129, 1] 的向量。这就代表了傅里叶变换后,每个离散点对应的频谱成分是多少,很容易看出,前 12 个点覆盖了大约 42Hz 的范围。考虑到 EEG 的主要频段也就在这个范围,所以可以只取前 12 个点作为特征进行分析。
还是要再次强调,由于这篇文章只是一个演示,所以代码写得很粗糙。各位完全可以自己修改参数,比如这样:
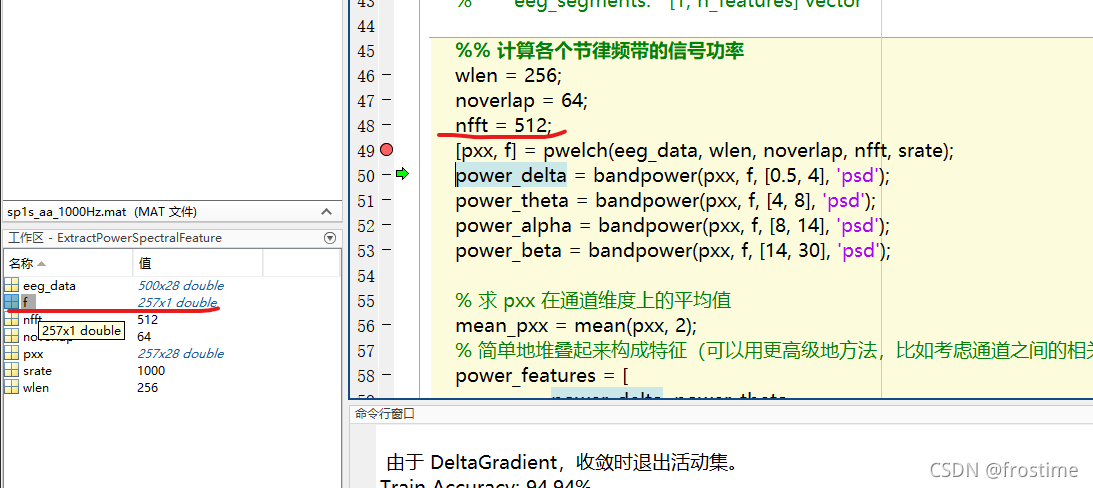
把 nfft 变大一点以后,由于参加fft的点的个数变多,频率分辨率也变会大。