一. awk概述
1.1 awk的前世今生
awk名字的由来:分别取三个创始人Ah,Weiberger,Kernighan三个人的首字母。
awk是一个报告生成器可以格式化输出文本内容。模式扫描和处理语言(pattern scarming and processing language)
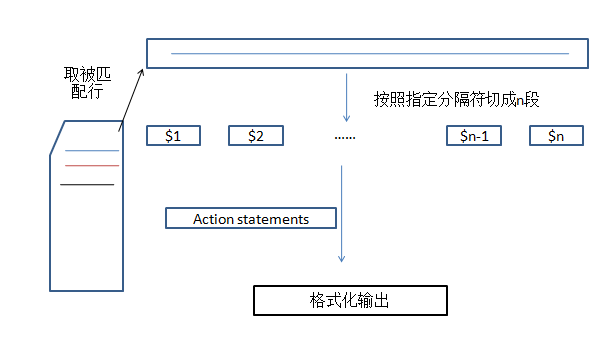
1.2 awk工作流程图
一次读取一行文本,按输入分隔符进行切片,切成多个组成部分,将每片直接保存在内建的变量中,$1,$2,$3…,引用指定的变量,可以显示指定断,或者多个断。如果需要显示全部的,需要使用$0来引用。可以对单个片断进行判断,也可以对所有断进行循环判断。其默认分隔符为空格。
第一步:读取被匹配到的行数据。
第二步:按照输入分隔符将整行数据分成n段。
第三步:将每一段保存到awk的内置变量,依次为$1~$n。
第四部:格式化输出。全部输出使用$0。
对段的操作:
如:判断第二个字段是否>2
如:循环$1~$n,对其进行统一操作
1.3 awk语法
语法:
-- 语句之间用分号分隔
awk [options] 'program' FILE......
其中[options]:
-F : 指明输入时用到的字段分隔符
-v var=VALUE : 自定义变量
在awk中变量的引用不需要加$,而是直接引用
1.3.1 第一种模式
awk [options] 'scripts' file1,file2.....
在这种模式中,scripts主要是命令的堆砌,对输入的文本行进行处理,通过命令print,printf或是输出重定向的方式显示出来,这里经常用到的知识点是:awk的内置变量,以及命令print和printf的使用
1.3.2 第二种模式
awk [options] 'PATTERN{action}' file,file2.....
在这种模式中,最重要的是5种模式和5种action的使用,以及awk的数组的使用和内置函数
#二. 第一种模式详解
2.1 print
- 各项目之间使用逗号隔开,而输出时则以空白字符分隔
- 输出的Item可以为字符串或数值,当前记录的字段(如$1)、变量或awk的表达式,数值会先转换为字符串,而后再输出
- print命令后面的Item可以省略,此时其功能相当于print $0,因此,如果想输出空白行,则需要使用print""
- 如果引用变量$1或其他的,是不能使用引号引起来
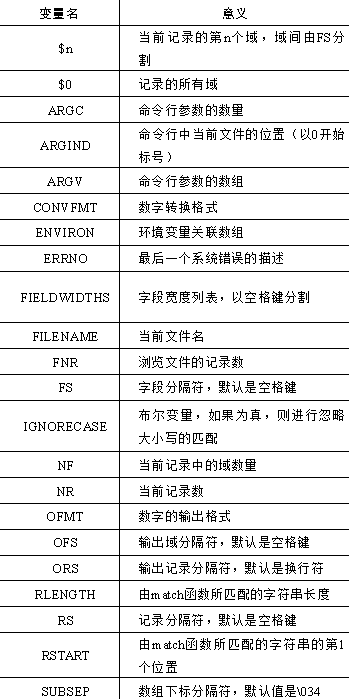
2.2 内置变量
2.3 自定义变量
-v var=VALUE : 在选项位置定义
eg:
awk 'BEGIN{test="hello";print test}'
变量在program中定义时,需要使用引号引起来
2.4 printf命令
其格式化输出:printf FORMAT,item1,item2…
要点:
- 其与print命令最大不同是,printf需要指定format
- printf后面的字串定义内容需要使用双引号引起来
- 字串定义后的内容需要使用","分隔,后面直接跟Item1,item2…
- format用于指定后面的每个item的输出格式
- printf语句不会自动打印换行符,\n
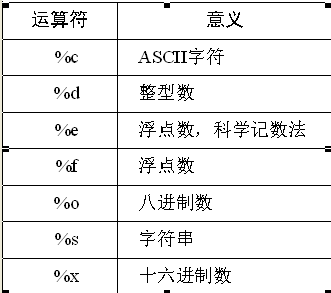
格式符:
修饰符:
N : 显示宽度
- : 左对齐(默认为右对齐)
- : 显示数值符号
示例:
awk -F: '{printf "username: %s,UID:%d\n",$1,$3}' /etc/passwd
awk -F: '{printf "username: %-20s shell: %s\n",$1,$NF}' /etc/passwd
测试记录:
[root@hp8 ~]# more /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
[root@hp8 ~]# awk -F: '{printf "username: %s,UID:%d\n",$1,$3}' /etc/passwd
username: root,UID:0
username: bin,UID:1
[root@hp8 ~]# awk -F: '{printf "username: %-20s shell: %s\n",$1,$NF}' /etc/passwd
username: root shell: /bin/bash
username: bin shell: /sbin/nologin
2.5 输出重定向
print items > "output-file"
print items >> "output-file"
print items | command
特殊文件描述符:
/dev/stdin :标准输入
/dev/stdout:标准输出
/dev/stderr:错误输出
/dev/fd/N : 某特定文件描述符,如/dev/stdin就相当于/dev/fd/0
示例
awk -F: '{printf "%-15s %i\n",$1,$3 > "/dev/stderr"}' /etc/passwd
三. 第二种模式详解
语法:
awk [option] 'PATTERN{action}' file1,file2....
3.1 PATTERN的使用
3.1.1 REGEXP
**REGEXP:**正则表达式,格式为/regular expression/,仅处理能够被此处模式匹配到的行
-- 匹配行首为UUID的
awk '/^UUID/{print $1}' /etc/fstab
-- 匹配行首不为UUID的
awk '!/^UUID/{print $1}' /etc/fstab
测试记录:
[root@hp8 ~]# more /etc/fstab
#
# /etc/fstab
# Created by anaconda on Thu Aug 20 09:51:06 2020
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/centos-root / xfs defaults 0 0
UUID=760bc1c2-4625-49d0-a6e2-11b16f8071b3 /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
[root@hp8 ~]# awk '/^UUID/{print $1}' /etc/fstab
UUID=760bc1c2-4625-49d0-a6e2-11b16f8071b3
[root@hp8 ~]# awk '!/^UUID/{print $1}' /etc/fstab
#
#
#
#
#
#
#
/dev/mapper/centos-root
/dev/mapper/centos-home
/dev/mapper/centos-swap
[root@hp8 ~]#
3.1.2 relational expression
**relational expression:**表达式,其值非0或为非空字符时满足条件,用运算符(匹配)和!(不匹配)
$1 ~ /foo/ 或者 $1 == "magedu"
测试记录:
[root@hp8 ~]# awk '$2=="swap"{print $1}' /etc/fstab
/dev/mapper/centos-swap
3.1.3 Ranges
Ranges : 指定匹配范围,格式为/pat1/,/pat2/,范围为:[pat1,pat2]
-- 输出行号大于等于40的
awk -F: 'NR>=40{print $1,NR}' /etc/passwd
-- 输出从root用户开始到sync用户结束的第一个域
awk -F: '/^root/,/^sync/{print $1}' /etc/passwd
注意:不支持直接给出数字的格式
测试记录:
[root@hp8 ~]# awk -F: 'NR>=40{print $1,NR}' /etc/passwd
sshd 40
avahi 41
postfix 42
tcpdump 43
rbl 44
mysql 45
mongod 46
redis 47
es 48
[root@hp8 ~]# awk -F: '/^root/,/^sync/{print $1}' /etc/passwd
root
bin
daemon
adm
lp
sync
3.1.4 BEGIN/END模式
BEGIN/END模式 : 特殊模式,仅在awk命令执行前运行一次或结束前运行一次
-- 先打印一个表头
awk -F: 'BEGIN{print "Username ID Shell"}{printf "%-10s%-10s%-20s\n",$1,$3,$7}' /etc/passwd
-- 打印一个表尾
awk -F: 'BEGIN{print "username ID Shell"}{printf "%-10s%-10s%-20s\n",$1,$3,$7}END{print "end of report."}' /etc/passwd
测试记录:
[root@hp8 ~]# awk -F: 'BEGIN{print "Username ID Shell"}{printf "%-10s%-10s%-20s\n",$1,$3,$7}' /etc/passwd
Username ID Shell
root 0 /bin/bash
bin 1 /sbin/nologin
daemon 2 /sbin/nologin
adm 3 /sbin/nologin
lp 4 /sbin/nologin
sync 5 /bin/sync
......
......
[root@hp8 ~]# awk -F: 'BEGIN{print "username ID Shell"}{printf "%-10s%-10s%-20s\n",$1,$3,$7}END{print "end of report."}' /etc/passwd
username ID Shell
root 0 /bin/bash
bin 1 /sbin/nologin
daemon 2 /sbin/nologin
adm 3 /sbin/nologin
lp 4 /sbin/nologin
sync 5 /bin/sync
......
......
es 1001 /bin/bash
end of report.
[root@hp8 ~]#
3.1.4 Empty(空模式)
**Empty(空模式):**匹配任意输入行
/正则表达式/:使用通配符的扩展集。
关系表达式:可以用下面运算符表中的关系运算符进行操作,可以是字符串或数字的比较,如$2>$1选择第二个字段比第一个字段长的行。
模式匹配表达式:
模式,模式:指定一个行的范围。该语法不能包括BEGIN和END模式。
BEGIN:让用户指定在第一条输入记录被处理之前所发生的动作,通常可在这里设置全局变量。
END:让用户在最后一条输入记录被读取之后发生的动作。
3.2 常见的Action
- Expressions
- Control statements :if while等
- Compound statements:组合语句
- Input statements
- Output statements
下面主要讲解控制语句
3.2.1 if-else
语法:
if (condition){then-body} else{[else-body]}
示例:
awk -F: '{if($3>=1000)print $1,$3}' /etc/passwd
awk -F: '{if($3>=1000){printf "Common user: %s\n",$1} else {printf "root or sysuser: %s\n",$1}}' /etc/passwd
awk -F: '{if($NF=="/bin/bash")print $1}' /etc/passwd
awk -F: '{if(NF>5) print $0}' /etc/fstab
df -h | awk -F[%] '/^/dev/{print $1}' | awk {if($NF>=20) print $1}'
awk -F: '{if($1=="root") print $1,"Admin";else print $1, "Common User"}' /etc/passwd
awk -F: '{if($1=="root") printf "%-15s: %s\n",$1,"Admin";else printf "%-15s: %s\n",$1, "Common user"}' /etc/passwd
awk -F: -v sum=0 '{if($3>=500) sum++}END{print sum}' /etc/passwd : 统计用户ID大于500的有多少行
awk -F: -v OFS="\t" '{if($3<=999)printf "Sys user:\t%-15s ID is :%d\n", $1,$3;else{printf "Common user:\t%-15s ID is :%d\n",$1,$3}}' /etc/passwd :可以使用\t制表符控制 输出格式
3.2.2 while:用于循环字段的
语法:
while (condition){statement1;statment2;....}
示例:
awk '/^[[:space:]]*linux16/{print}' /boot/grub2/grub.cfg
awk '/^[[:space:]]*linux16/{i=1;while(i<=NF){print $i,length($i);i++}}' /etc/grub2.cfg :对每个字段进行字符个数统计
awk '/^[[:space:]]]*linux16/{i=1;while(i<=NF){if(length($i)<=7)print $i,length($i);i++}}' /etc/grub2.cfg
awk -F: '{i=1;while(i<=3){print $i;i++}}' /etc/passwd:打印用户名、密码占位符、ID
awk -F: '{i=1;while(i<=NF){if(length($i)>=4){print $i};i++}}' /etc/passwd : 字段大小于等于4的都显示
3.2.3 do-while
语法:
do {statement1,statement2,....} while (dondition)
示例:
-- 打印用户名、密码占位符、UID
awk -F: '{i=1;do{print $i;i++}while(i<=3)}' /etc/passwd
3.2.4 for
语法:
for(variable assignment;condition;iteration process){ statement1,statement2,...}
示例:
awk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++) {print $i,length($i)}}' /etc/grub2.cfg
awk -F: '{for(i=1;i<=3;i++)print $i}' /etc/passwd
awk -F: '{for(i=1;i<=NF;i++) { if (length($i)>=4) {print $i}}}' /etc/passwd
3.2.5 case
语法:
switch (expression) { case VALUE or /REGEXP/: statement1, statement2,... default: statement1, ...}
3.2.6 break和continue
break [n]
continue : 进入下一个字段
3.2.7 next
功能:提前结束本行文本的处理,并接着处理下一行
示例:
awk -F: '{if($3%2==0) next;print $1,$3}' /etc/passwd
awk -F: ‘{if ($3%2!=0) next;print $1,$3}’ /etc/passwd
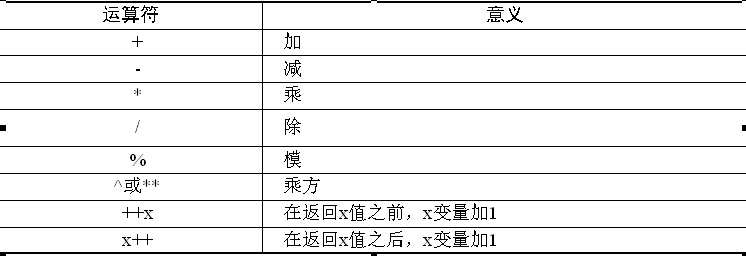
四. awk操作符
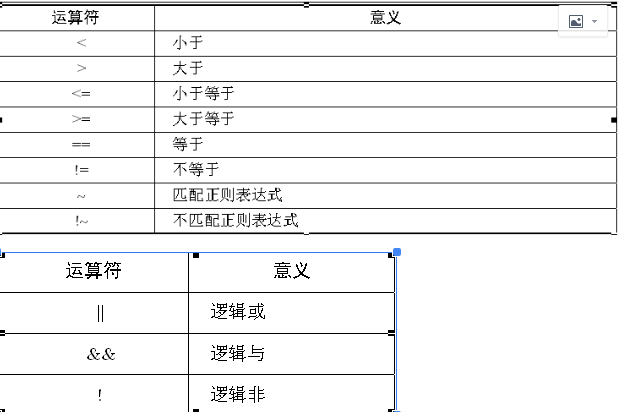
与其他编程语言一样,awk表达式用于存储、操作和获取数据,一个awk表达式可由数值、字符常量、变量、操作符、函数和正则表达式自由组合而成
变量是一个值的标识符,定义awk变量非常方便,只需定义一个变量名并将值赋给它即可。变量名只能包含字母、数字和下划线,而且不能以数字开头
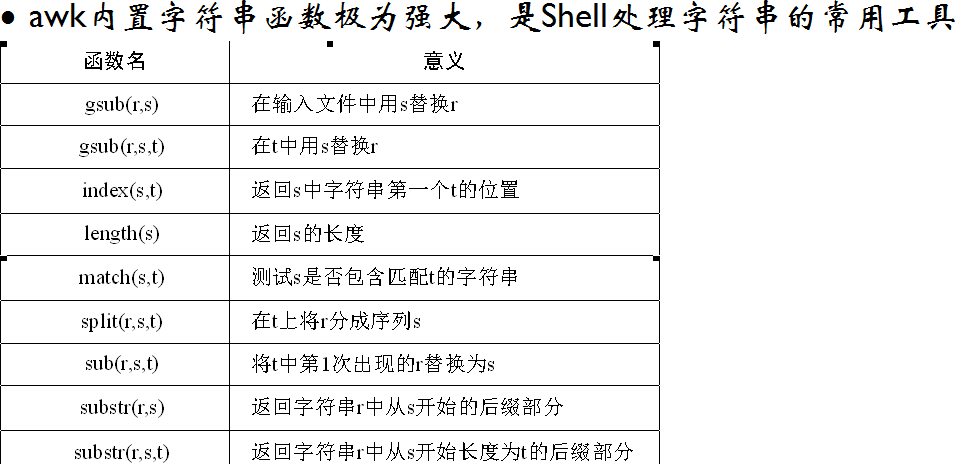
五. awk的内置函数
六. awk数组
数组是用于存储一系列值的变量,这些值之间通常是有联系的,可通过索引来访问数组的值,索引需要用中括号括起,数组的基本格式为:
array[index]=value
关联数组是指数组的索引可以是字符串,也可以是数字
关联数组在索引和数组元素值之间建立起关联,对每一个数组元素,awk自动维护了一对值:索引和数组元素值
关联数组的值无需以连续的地址进行存储,awk的所有数组都是关联数组
字符串和数字之间的差别是明显的,如,我们使用array[09]指定一个数组值,如果换成array[9]就不能指定到与array[09]相同的值
split(r,s,t)函数将字符串以t为分隔符,将r字符串拆分为字符串数组,并存放在s中,此时s通常就是一个数组
awk 'BEGIN {print split("abc/def/xyz",str,"/")}'
上面命令以“/”为分隔符,将字符串abc/def/xyz分开,并存在str数组中,split函数的返回值是数组的大小
awk可使用for循环打印数组内容
for (variable in array)
do something with array[variable]
ARGC是ARGV数组中元素的个数,与C语言一样,从ARGV[0]开始,到ARGV[ARGC-1]结束
ARGV[0]中存储的是awk,即执行该脚本的程序名
ARGV[1]到ARGV[ARGC-1]存储了脚本后跟的位置参数
七.awk实例
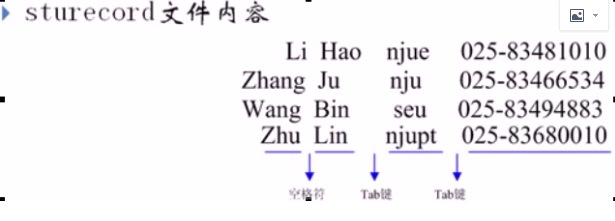
sturecord
Li Hao njue 025-83481010
Zhang Ju nju 025-83466534
Wang Bin seu 025-83494883
Zhu Lin njupt 025-83680010
sturecord1
Li Hao,njue,025-83481010,85,92,78,94,88
Zhang Ju,nju,025-83466534,89,90,75,90,86
Wang Bin,seu,025-83494883,84,88,80,92,84
Zhu Lin,njupt,025-83680010,98,78,81,87,76
7.1 打印指定域
依次打印文件的第二域,第一域,第三域,第四域
[root@node1 awk]# awk '{print $2,$1,$4,$3}' sturecord
Hao Li 025-83481010 njue
Ju Zhang 025-83466534 nju
Bin Wang 025-83494883 seu
Lin Zhu 025-83680010 njupt
$0代表所有的域
7.2 修改域分隔符
awk -F 修改域分隔符,如下"\t"代表将域分隔符转换为tab键,此时的第三个域就是电话号码
[root@node1 awk]# awk -F"\t" '{print $3}' sturecord
025-83481010
025-83466534
025-83494883
025-83680010
如下语句是将awk的域设置成","
[root@node1 awk]# awk 'BEGIN {FS=","} {print $1,$3}' sturecord1
Li Hao 025-83481010
Zhang Ju 025-83466534
Wang Bin 025-83494883
Zhu Lin 025-83680010
7.3 匹配行
在/etc/passwd这个文件中匹配含有root字样的行
[root@node1 awk]# awk 'BEGIN {FS=":"} $0~/root/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
在/etc/passwd中不匹配nologin字段的
[root@node1 awk]# awk 'BEGIN {FS=":"} $0!~/nologin/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
zqs:x:500:500:zqs:/home/zqs:/bin/bash
oracle:x:505:505::/home/oracle:/bin/bash
在/etc/passwd中匹配第三域或者第四域为10的
[root@node1 awk]# awk 'BEGIN {FS=":"} {if($3==10||$4==10) print $0}' /etc/passwd
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
将等号修改为~
[root@node1 awk]# awk 'BEGIN {FS=":"} {if($3~10||$4~10) print $0}' /etc/passwd
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
7.4 求出每个学员的平均分
scr2.awk
#!/bin/awk -f
BEGIN {FS=","}
{total=$4+$5+$6+$7+$8
avg=total/5
print $1,avg}
测试记录:
[root@node1 awk]# ./scr2.awk sturecord1
Li Hao 87.4
Zhang Ju 86
Wang Bin 85.6
Zhu Lin 84
7.5 输出行号
NF代表有多少个域
NR代表行号
[root@node1 awk]# awk 'BEGIN {FS=","} {print NF,NR,$0} END {print FILENAME}' sturecord1
8 1 Li Hao,njue,025-83481010,85,92,78,94,88
8 2 Zhang Ju,nju,025-83466534,89,90,75,90,86
8 3 Wang Bin,seu,025-83494883,84,88,80,92,84
8 4 Zhu Lin,njupt,025-83680010,98,78,81,87,76
sturecord1
参考:
- https://www.jianshu.com/p/ea22c809ae9f
- https://www.cnblogs.com/wxxjianchi/p/9143936.html