
文 @ 不愿透露姓名的小P同学
0 前言
大家好,本次分享作为 AI 框架基础系列,将为大家详细讲述如何基于 Python API 快速搭建深度学习模型。
随着 AI 框架的发展,搭建深度学习模型变得越来越容易。好比以前建房子,需要自己一砖一瓦地往上添加,后来人们可以用现成的模块如预制板像搭建积木一般地来建造房屋。再往后,可以根据图纸直接用 3D 打印技术来打印出一个成形的房子。
搭建深度学习模型也是如此,按照搭建复杂度从繁到简可以分为三个阶段:
- 在 AI 框架出现之前的第一个阶段,我们需要自己实现模型的每一个算子。
- 第二阶段,我们可以调用框架提供的算子单元比如卷积、激活函数、时序处理单元等来搭建模型,目前大部分主流框架主要处于这个阶段。
- 第三阶段,我们基于 AI 框架提供的算子单元进一步开发出一些通用模板,基于这些模板进行模型搭建会更加便捷。
OpenMMlab 系列算法框架就是第三阶段的典型代表,这些模型模板一般做好了解耦,模块之间一般可以拆解重组,方便灵活地应用于不同的任务,以及后续的调试和升级。
除了上述三个阶段,甚至可以使用包括网络结构搜索(NAS)等在内的 AutoML 技术直接输出一个不错的模型。
不管经历以上哪个阶段,构建的实用深度学习网络,都会面临训练耗时长的问题。
例如,经典的 ResNet 网络在单张 V100 GPU上,完成一次 ImageNet 数据集的完整训练需要超过一周时间。因此,在日常训练过程中,研究者们集合实践与经验,沉淀出了大量实用技巧,可以大幅缩短模型训练的时间。
本次分享将聚焦于如何利用 AI 框架提供的算子积木搭建深度学习模型,并高效进行模型训练。
全文将从以下两个部分展开,文中代码均以 PyTorch 为例。
- 基于 Python API 搭建深度学习模型
- 搭建深度学习模型时的加速进阶技巧
1 基于 Python API 搭建深度学习模型
简单来说,搭建一个可以随时启动训练的深度学习模型主要包含四步:
- 搭建模型主体架构
- 配置优化策略
- 定义数据
- 定义训练 pipeline
下面将从这四个方面展开。
1.1 搭建模型主体架构
以搭建模型 my_model 为例,单个算子就像积木,搭建时可以简单地堆叠,只要相邻的两块接口能够兼容。如下面这个例子,就用了一个卷积层作为 layer1,用了一个线性全连接层作为 classifier。积木之间的连接先后顺序在 forward中定义。每一块积木的特性,即算子的参数,可以随机初始化。在复杂任务中,也可以加载事先准备好的预训练模型。
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self, inplanes, features, num_classes=1000):
super(MyModel, self).__init__()
self.layer1 = nn.Conv2d(inplanes, inplanes)
self.classifier = nn.Sequential(
nn.Linear(features, num_classes)
)
self._initialize_weights()
def forward(self, x):
x = self.layer1(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def _initialize_weights(self):
pass
my_model = MyModel(...)
1.2 配置优化策略
对于普通上班族,每周一到周五的工作会不断循环往复,但可能大多数人向往的生活是每天都会有一些新的收获。
那么一份普通的数据样本,无休无止地开始输入和处理的循环。理想的情况是每一份数据来了又走之后都能留下一些东西,至于留下来的,就是损失函数所定义的loss计算规则。通过损失函数得到的 loss 反向传播得到的模型参数的梯度。这些梯度如何内化到模型中,正是优化器要做的事。
总的来说,如下示例,损失函数(criterion)决定了在训练过程中要用什么样的评判标准。优化器(optimizer)决定了模型的参数如何更新。
optimizer = torch.optim.SGD(my_model.parameter(), ...)
criterion = nn.CrossEntropyLoss()
1.3 定义数据
模型的训练需要以数据为输入,PyTorch 通过 Dataset 和 Dataloader 来表示数据。
以如下代码为例,自定义的数据集通常需要包含数据集的大小(__len__)和数据读取的方式(__getitem__)。在每一轮输入数据规模确定的前提下,前者决定了遍历完全部数据所需要的轮次,后者决定了在每一轮读取数据的过程中如何去获取输入。
my_dataloader 则决定每一轮训练中,数据如何被分配和组合,这个一般AI训练框架能做到完全的自动化。
from torch.utils.data import Dataset
from torch.utils.data import Dataloader
class MyDataset(Dataset):
def __init__(self, meta_file):
# 自定义处理元数据文件的函数 parse_meta
self.meta_list = parse_meta(meta_file)
def __getitem__(self, index):
# 自定义从元数据信息读取实际数据的函数 get_data
return get_data(self.meta_list[index])
def __len__(self):
return len(self.meta_list)
my_dataset = MyDataset(...)
my_dataloader = Dataloader(my_dataset, batch_size=4)
1.4 定义训练 pipeline
如下图所示,在一次训练中,数据流按序进入网络,根据网络结构和损失函数得到前向输出后,再进行反向传播,保存参数的梯度值,并按照优化器定义的策略更新到网络的参数中。更新后的参数会和下一轮的数据一起开始新的一天。
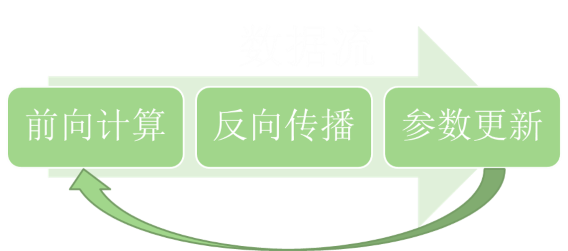
用 Python API 来简单描述,如以下代码所示:
def train(my_model, my_dataloader, criterion, optimizer):
for index, (input, target) in enumerate(my_dataloader):
output = my_model(input)
loss = criterion(output, target)
loss.backward()
optimizer.step()
这样,一个完整的深度学习模型就搭建好了。
就像人是一个家的关键因素,数据也是整个模型的关键,它决定了要去搭建什么样的模型,要采用什么样的优化策略,从而最终决定了模型的性能表现。
2 搭建深度学习模型时的加速进阶技巧
目前主要的加速方法包括:
- 分布式并行
- 混合精度
- 在线编译
下面简单分享一下这些方法,更细节的部分将会在后续的分享内容中详细介绍。
2.1 分布式并行
分布式并行包含两种方式:数据并行、模型并行,以及这两种方式的融合。
理想情况下,多卡运行所需时间应该与卡数成反比,但在实际操作中,由于通信等因素,往往不能达到理想的效果。
2.1.1 数据并行
在多卡(多进程)训练中,数据会被分发到不同的卡,各自独立进行前向计算和反向传播,得到梯度信息之后再进行同步和更新。
相对应的代码改动如下:
# dataloader 中的 sampler 将在后续的数据分发过程中决定每张卡上的数据排列
train_sampler = torch.utils.data.DistributedSampler(my_dataset, shuffle=True)
train_loader = DataLoader(my_dataset, sampler = train_sampler)
# 将模型变成一个分布式模型
my_model = torch.nn.parallel.DistributedDataParallel(my_model)
DistributedDataParallel 主要做了两件事情:
- 初始化时,使每张卡上的参数需要保持一致;
- 每一轮迭代之后,不同卡上参数的梯度会通过通信来同步,保证各卡的参数仍然一致。
这样做有两个好处,一是能充分且灵活地利用计算资源,大大缩短模型训练所需时间,二是相当于增大 batch_size,梯度下降方向会更贴合数据集整体的实际情况。
2.1.2 模型并行
当模型的参数量非常大时,即便是 32GB 的显卡,也难以容纳如此之大的模型训练任务。我们可以将参数分发到不同的卡上。模型并行可以在模型的任意一层进行,如果在前面的层中用到了数据并行,则根据当前层的计算规则决定要不要将数据归并到一起。
参数的分发可以在线性的全连接层等无参数顺序要求的层进行,也可以在多任务模型中,将不同的任务执行代码块分发到不同的卡。
2.2 混合精度
混合精度训练主要用半精度(float16)进行训练,同时能保持单精度(float32)结果的一种训练方式,为了能保持精度,在一些运算单元上会掺杂 float32 的计算。它可以减小计算内存,加快计算速度。
由于在一些算子上存在溢出的问题,在训练过程中需要先将这些算子转换成 float32 进行计算后再转回 float16。
从用户 Python 代码的角度,混合精度需要修改以下三方面的内容:模型参数的转换,输入的转换,以及参数更新过程中的 loss scaling 等优化策略的更新。具体原理可以参考 自动混合精度,以下仅为示意代码:
my_model.half()
for index, (input, target) in enumerate(my_dataloader):
input = input.half()
# forward
loss = ...
# backward,scale 为对 loss 进行的放大操作
scale(loss).backward()
# fused_sgd 为用户自定义或者框架提供的包含 loss scaling 和 master copy of weights 的优化器
fused_sgd.step()
2.3 在线编译
Python 和动态图的结合使用户可以灵活地定义模型计算流程,但在一些比较复杂的算子计算中,大量小 op 的叠用,会增加调度开销,使得模型具有较大的优化空间。我们通过在线编译技术,可以在小算子密集的场景下实现加速。
在模型训练中,还有很多更为灵活的应用,譬如我们可以规定在特定的轮次只训练模型的部分特定参数。
另外,我们还可以自定义模块和算子,只要实现了 forward 和 backward,那么它就可以在模型中被当作积木来使用。
使用 pybind 等机制可以将 C++ 代码编译成 Python 模块,兼顾速度和易用性。
结语
感谢阅读,关于 Python API 搭建深度学习模型相关问题欢迎大家一起留言讨论哦~
更期待有相同兴趣的同学加入我们,一同探索解决 AI 框架面临的问题和挑战!
大家如果有感兴趣的技术内容和难点欢迎随时指出,可以在评论区给我们留言~
关注 公众号「SenseParrots」,获取人工智能框架前沿业界动态与技术思考:
