Shell编程
文章目录
一、Shell介绍
Shell是一个可以让用户向Linux内核发送命令以便运行程序的命令行解释器。用户可以用Shell来启动、挂起、停止甚至是编写一些程序。如下图所示:
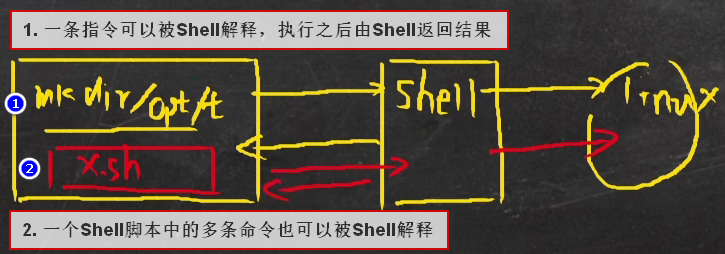
注:比如GNOME等图形界面也都是Shell,只不过是GUI Shell,而Bash Shell是命令行形式的Shell。
二、Shell脚本的执行方式
1. 脚本中的内容必须以 #!/bin/bash 开头
这句话的意思是告诉执行器需要调用 /bin/bash 来执行这个脚本文件。
这也是在Shell中唯一以 # 号开头却不代表注释的语句,脚本文件中的其他任何地方以 # 号开头的语句都会被认为是注释语句而忽略执行,所以这句话只能写在Shell的开头才有效。
2. 脚本需要有可执行权限
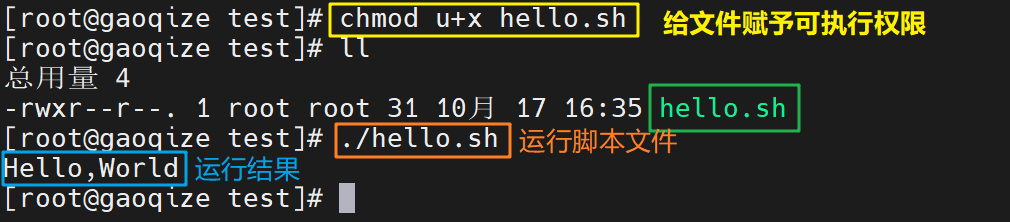
2.1 方式一:可以先赋予脚本 +x 权限,再执行脚本
2.2 方式二:不用赋予权限,通过 sh 脚本文件 的方式直接执行脚本
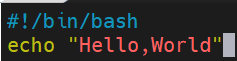
例子:编写一个Shell脚本,输出Hello,World
-
执行命令
vim hello.sh创建并编辑脚本文件注意:也可以使用其他结尾,但Shell脚本一般以sh结尾
-
脚本中输入以下内容:
-
方式一:赋予权限,并在脚本文件所在的目录(相对路径)通过 ./ 运行脚本:
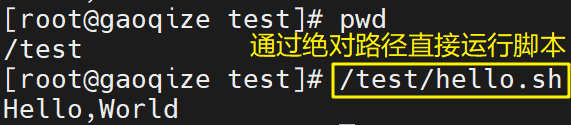
也可以通过绝对路径而不加 ./ 运行脚本,如下图所示:
-
方式二:不用赋予脚本文件权限,直接执行:

补充:
Shell脚本的多行注释:
:<<!
注释内容
!
三、Shell的变量
1. Shell变量介绍
Linux Shell中的变量分为系统变量和用户自定义变量,可以通过 set 命令显示所有变量。
常见的系统变量比如: $HOME, $PWD, $SHELL, $USER等等,如下图:

2. 自定义变量
2.1 基本语法
-
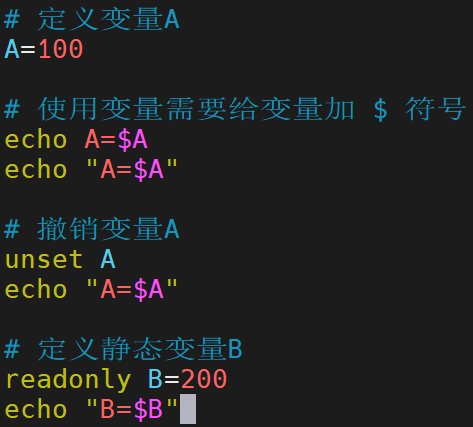
定义变量:
变量=值注意:等号左右不能有空格
-
撤销变量:
unset 变量名 -
静态变量:
readonly 变量=值注意:静态变量不能被撤销,如果撤销,执行时会报错,如下图:

2.2 例子
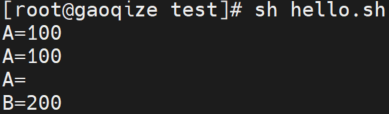
运行结果:
2.3 一些规则
-
变量名可以由字母、数字、下划线组成,但是不能以数字开头
-
给变量赋值时,等号两侧不能有空格
-
变量名一般习惯大写
-
A=`命令` 表示运行引号中的命令,并把结果返回给变量A
也可以使用 A=$(命令),一样的效果
2.4 例子
# 脚本中的内容
C=`date`
echo "C=$C"
# 运行结果
C=2021年 10月 17日 星期日 19:08:15 CST
四、设置环境变量
- 环境变量又叫做全局变量,也就是说在其他的Shell文件中可以直接引用这个变量
基本语法
export 变量名=变量值,功能描述:将Shell变量输出为环境变量/全局变量source 脚本文件,功能描述:让修改后的配置信息立即生效$变量名,功能描述:获取变量的值
例子
# 在脚本文件hello.sh中定义一个环境变量
export JayChou_HOME=/opt/JayChou
# 刷新脚本文件
source /test/hello.sh
# 查询环境变量的值
echo $JayChou_HOME
# 执行结果
/opt/JayChou
五、位置参数变量
定义
当想要在脚本中获取执行脚本时指定的参数信息就需要使用位置参数变量,比如 sh myshell.sh 100 200 表示执行Shell脚本的同时指定了100、200两个参数,在脚本中使用位置参数变量就可以获取到脚本之外的这两个变量(参数)的值。
基本语法
- $n:n为数字,$0代表命令本身,$1 - $9代表第一到第九个参数,第十个及以上的参数需要用大括号包含,如 ${10}
- $*:代表命令行中所有的参数,把所有的参数看成一个整体
- $@:代表命令行中所有的参数,把每个参数区分对待,不再是一个整体
- $#:代表命令行中所有参数的个数
例子
脚本文件:

执行结果:

六、预定义变量
定义
预定义变量指的是Shell设计者事先已经定义好的变量,可以直接在Shell脚本中使用这些变量。
基本语法
- $$:当前进程的进程号(PID)
- $!:后台运行的最后一个进程的进程号(PID)
- $?:最后一次执行的命令的返回状态
- 如果这个变量的值为0,证明上一个命令正确执行
- 如果这个变量的值为非0(具体是哪个数,由命令自己来决定),则证明上一个命令执行不正确
例子
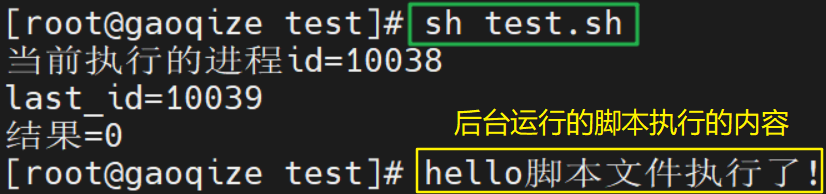
在test.sh文件中编辑内容:

执行结果:
七、运算符
方式一
变量=$((运算式))
方式二
变量=$[运算式]
方式三
变量=`expr 运算式`
注意:
- 使用expr关键字时,运算式的运算符两侧要加空格
- 使用expr做运算时乘法运算必须使用
\*才能实现乘法运算,使用[]则不需要转义
例子
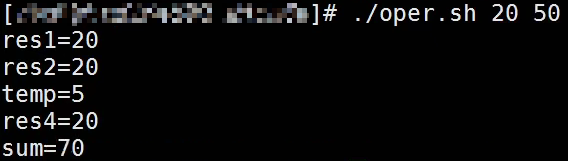
编辑oper.sh脚本文件:

执行结果:
八、条件判断
基本语法
[ 待判断条件 ]
注意:
- 中括号前后必须要有空格
- 非空返回true,为空返回false
常用判断条件
- 字符串比较,使用
= - 整数比较
- lt:小于
- le:小于等于
- eq:等于
- gt:大于
- ge:大于等于
- ne:不等于
- 文件权限判断
- -r:有读权限
- -w:有写权限
- -x:有执行权限
- 文件类型判断
- -e:文件存在
- -f:文件存在且是一个常规文件
- -d:文件存在且是一个文件夹
九、流程控制
1. if语句
基本语法
单分支:
if [ 待判断条件 ]
then
待执行语句
fi
多分支:
if [ 待判断条件 ]
then
待执行语句
elif [ 待判断条件 ]
then
待执行语句
fi
例子1
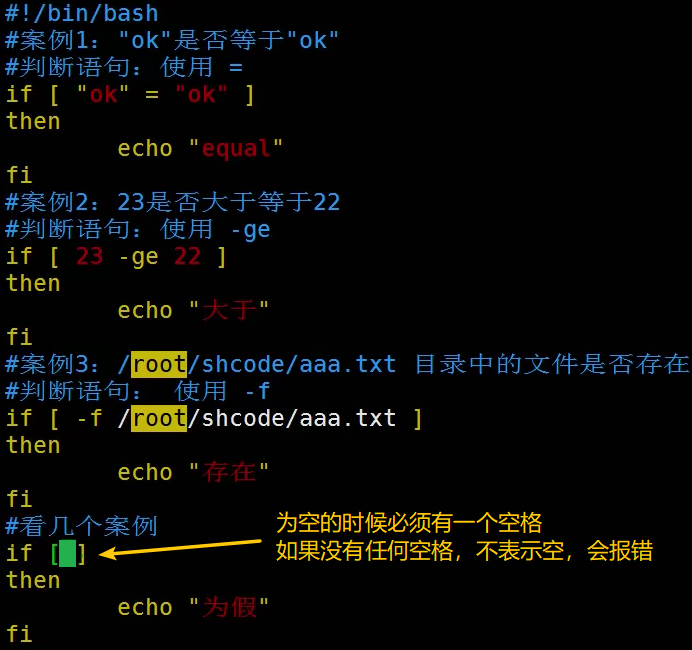
运行结果:
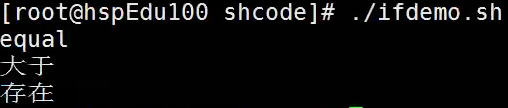
例子2

运行结果:

2. case语句
基本语法
case 变量 in
"值1")
待执行语句
;;
"值2")
待执行语句
;;
*) # 不满足任何值则执行此语句
待执行语句
;;
esac
注意:一旦变量等于某个值就会一直往下执行直到遇到分号,但不会进入其他值的执行语句。
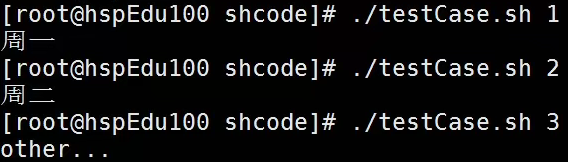
例子

运行结果:
3. for循环
基本语法1
for 变量 in 值1 值2 值3
do
每次循环执行的代码
done
表示每将值赋给一次变量就会执行一次循环
基本语法2
for ((初始值; 循环条件; 变量变化))
do
每次循环执行的代码
done
例子1
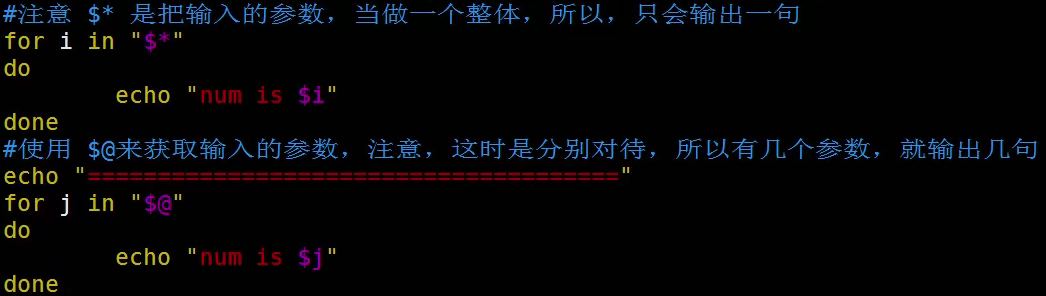
运行结果:
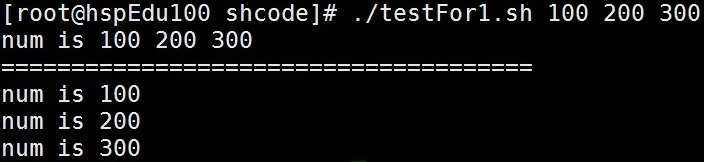
例子2

运行结果:

4. while循环
基本语法
while [ 条件判断式 ]
do
每次循环待执行的代码
done
注意:条件判断式的中括号左右都有空格。
例子
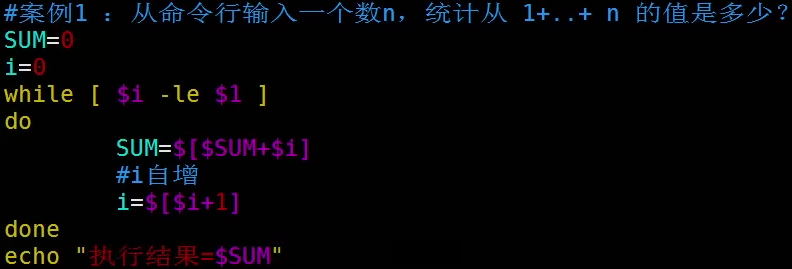
运行结果:

十、读取输入
基本语法
read [选项] 参数
- 选项:
- -p:等待用户输入时的提示内容
- -t:指定读取用户输入时等待的时间,如果超过了指定的时间,则读取的内容为空,不再等待
- 参数:
- 将用户输入的内容赋值给指定的变量
例子

运行结果:

十一、函数
1. 系统函数
basename
-
格式:
basename 路径 [后缀] -
功能:返回路径的最后一个 “/” 之后的内容(不包括 “/” ),一般用于获取文件名
-
如果指定了后缀,则只返回文件的名称,不会返回文件的后缀
dirname
- 格式:
dirname 路径 - 功能:返回路径的最后一个 / 之前的内容(不包括 “/” ),一般用于获取文件所在的路径
例子
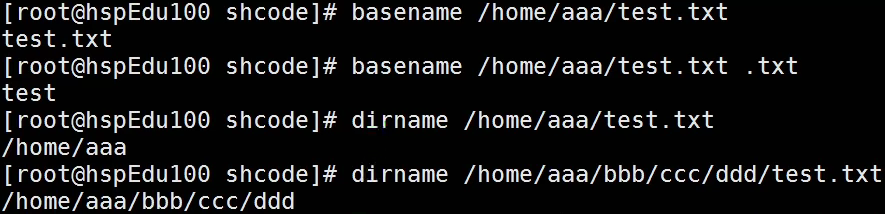
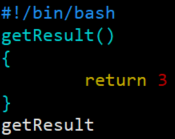
2. 自定义函数
- 必须在调用函数之前先声明函数,Shell是逐行执行的,不会像其他语言一样先编译
- 函数定义时不能指定任何形参,也就是必须是空的小括号
- return语句只能返回0-255数值之间的整数
- 如果没有显式声明return语句,则以最后一条命令运行结果作为返回值,0表示执行成功,非0表示执行失败
- return语句的返回结果只能通过
$?接收 - 调用函数时不用加函数名后的小括号,只需要在函数名之后跟参数即可
格式1
function 函数名称()
{
函数内容
[return 整数]
}
# 调用
函数名称 参数1 参数2...
格式2
函数名称()
{
函数内容
[return 整数]
}
# 调用
函数名称 参数1 参数2...
注意:当不写 function 关键字时,函数名后面一定要跟着小括号,而写了关键字时,小括号是可选的。
例子1
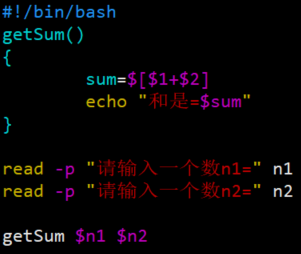
运行结果:
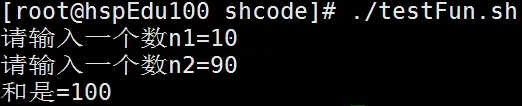
例子2
运行结果:

例子3

运行结果:

十二、Shell工具
1. cut
- cut的工作就是“剪”,具体的说就是在文件中负责剪切数据用的
- 并不会修改原文件的内容,只是将对应的内容显示出来
基本语法
cut [选项参数] filename
- 选项参数说明
- -f:列号,提取第几列
- -d:分隔符,列是按照哪种分隔符分割的,默认是制表符
例子1
数据准备:
[atguigu@hadoop101 datas]$ vim cut.txt
dong shen # 一个空格
guan zhen # 一个空格
wo wo # 两个空格
lai lai # 两个空格
le le # 两个空格
操作1:切割cut.txt第一列
[atguigu@hadoop101 datas]$ cut -d " " -f 1 cut.txt # 以空格作为分割列的标准
dong
guan
wo
lai
le
操作2:切割cut.txt第二、三列
[atguigu@hadoop101 datas]$ cut -d " " -f 2,3 cut.txt
shen
zhen
wo
lai
le
操作3:在cut.txt文件中切割出所有的guan
[atguigu@hadoop101 datas]$ cat cut.txt | grep "guan" | cut -d " " -f 1 # 先通过grep提取出所有以guan开头的行
guan
例子2
获取系统变量PATH的值,第2个 “:” 开始后的所有路径
[atguigu@hadoop101 datas]$ echo $PATH
/usr/lib64/qt-3.3/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/atguigu/bin
[atguigu@hadoop102 datas]$ echo $PATH | cut -d : -f 3- # 以":"作为分隔符,3-表示第3列及之后的所有列
/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/atguigu/bin
2. sed
sed是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕,也就是说原文件内容并没有改变。接着处理下一行,这样不断重复,直到文件末尾。
基本语法
sed [选项参数] 命令 文件名
- 选项参数
- -e:直接在指令行模式下进行sed的动作编辑,可以省略
- 命令
- a:新增,a的后面可以接字串,这些字串会在下一行出现
- i:插入, i 的后面可以接字串,这些字串会在上一行出现
- d:删除
- s:查找并替换
例子
数据准备:
[atguigu@hadoop102 datas]$ vim sed.txt
dong shen
guan zhen
wo wo
lai lai
le le
操作1:将“mei nv”这个单词插入到sed.txt第二行下
[atguigu@hadoop102 datas]$ sed '2a mei nv' sed.txt # 2a表示插入到第2行之后
dong shen
guan zhen
mei nv
wo wo
lai lai
le le
[atguigu@hadoop102 datas]$ cat sed.txt # 原文件内容并未改变
dong shen
guan zhen
wo wo
lai lai
le le
操作2:删除sed.txt文件所有包含wo的行
[atguigu@hadoop102 datas]$ sed '/wo/d' sed.txt
dong shen
guan zhen
lai lai
le le
注意:删除2~5行使用 sed '2,5d'
操作3:将sed.txt文件中wo替换为ni
[atguigu@hadoop102 datas]$ sed 's/wo/ni/g' sed.txt # ‘g’表示global,全部替换
dong shen
guan zhen
ni ni
lai lai
le le
操作4:将sed.txt文件中的第二行删除并将wo替换为ni
[atguigu@hadoop102 datas]$ sed -e '2d' -e 's/wo/ni/g' sed.txt
dong shen
ni ni
lai lai
le le
3. awk
把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理。
基本语法
awk [选项参数] 'pattern1{action1} pattern2{action2}...' filename
-
pattern:表示awk在文件中查找的内容,正则表达式的用法
-
action:在找到匹配内容时所执行的一系列命令
-
选项参数
- -F:指定每行拆分的分隔符
- -v:定义一个自定义变量
例子
数据准备:
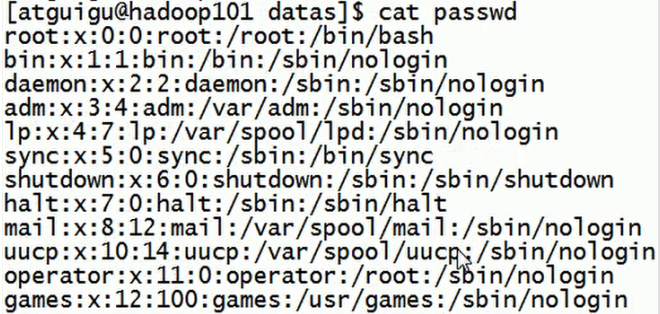
操作1:搜索passwd文件以root关键字开头的所有行,并输出该行的第7列
[atguigu@hadoop102 datas]$ awk -F : '/^root/ {print $7}' passwd # 1. 正则表达式两边要加/,2. $7表示第7列
/bin/bash
操作2:搜索passwd文件以root关键字开头的所有行,并输出该行的第1列和第7列,两列以 , 号分割
[atguigu@hadoop102 datas]$ awk -F : '/^root/ {print $1","$7}' passwd
root,/bin/bash
操作3:只显示passwd文件的所有行的第一列和第七列,两列以逗号分割,且在结果的首行添加usershell,在最后一行添加"dahaige "
[atguigu@hadoop102 datas]$ awk -F : 'BEGIN{print "usershell"} {print $1","$7} END{print "dahaige "}' passwd # BEGIN表示首行,END表示最后一行
usershell
root,/bin/bash
bin,/sbin/nologin
#....
atguigu,/bin/bash
dahaige
操作4:将passwd文件中的用户id增加数值1并输出
[atguigu@hadoop102 datas]$ awk -v i=1 -F : '{print $3+i}' passwd # 不使用$取变量i的值
1
2
3
4
awk的内置变量
| 变量 | 说明 |
|---|---|
| FILENAME | 文件名 |
| NR | 已读行数 |
| NF | 切割后列的个数 |
例子
统计passwd文件名,每行的行号,每行的列数
[atguigu@hadoop102 datas]$ awk -F : '{print "filename:" FILENAME ", linenumber:" NR ", columns:" NF}' passwd
filename:passwd, linenumber:1, columns:7
filename:passwd, linenumber:2, columns:7
filename:passwd, linenumber:3, columns:7
#...
4. sort
将文件进行排序,并将排序结果标准输出。
基本语法
sort 选项 文件
| 选项 | 说明 |
|---|---|
| -n | 依照数值的大小排序 |
| -r | 以相反的顺序排序 |
| -t | 设置排序时所用的分隔字符 |
| -k | 指定需要排序的列 |
例子
数据准备:
[atguigu@hadoop102 datas]$ vim sort.sh
bb:40:5.4
bd:20:4.2
xz:50:2.3
cls:10:3.5
ss:30:1.6
操作:按照 : 分割后的第三列倒序排序
[atguigu@hadoop102 datas]$ sort -t : -nrk 3 sort.sh
bb:40:5.4
bd:20:4.2
cls:10:3.5
xz:50:2.3
ss:30:1.6