
1. 四个问题
-
解决什么问题
自监督点云预训练,与PointContrast相比,输入更简单了:single-view depth maps -
用了什么方法
instance discrimination with a momentum encoder
Point input:PointNet++ [64]
Voxel input:sparse convolution U-Net model [17]
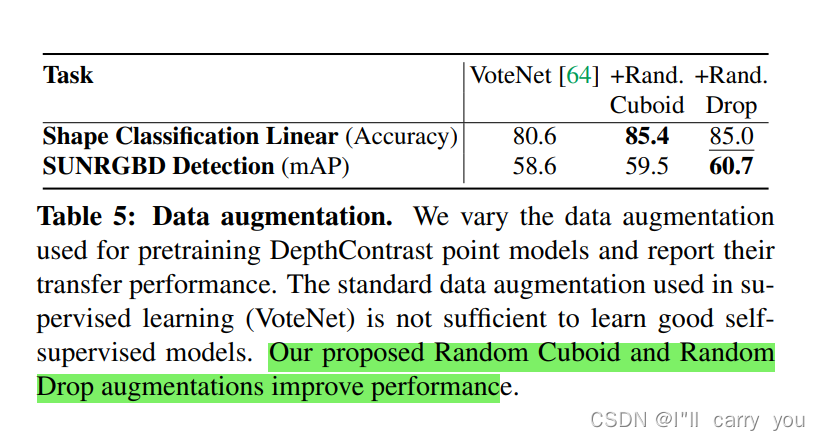
额外增加2种数据增强:random cuboid and random drop patches
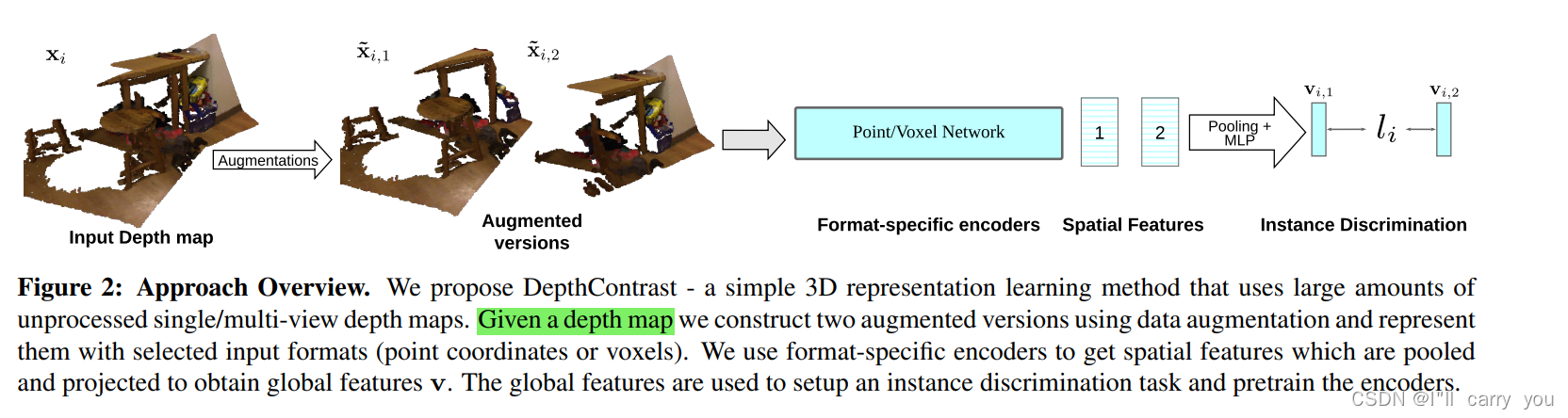
联合架构:
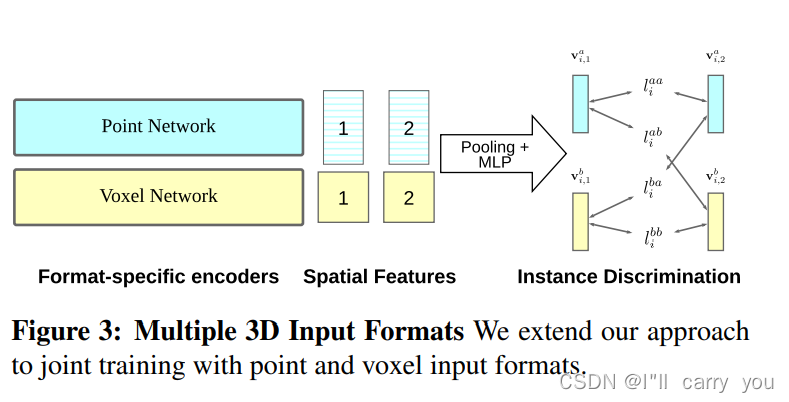
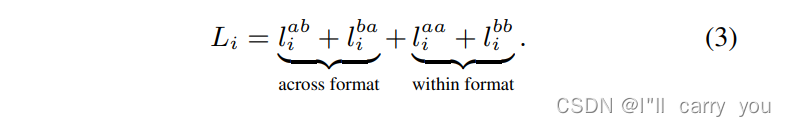
-
效果如何
9个benchmark,有效地小样本学习器
We evaluate our models on 9 benchmarks for object detection, semantic segmentation, and object classification, where they achieve state-of-the-art results. Most notably, we set a new state-ofthe-art for object detection on ScanNet (69.0% mAP) and SUNRGBD (63.5% mAP). Our pretrained models are label efficient and improve performance for classes with few examples.
- 还存在什么问题
?
2. 论文介绍
Abstract
- 预训练在3D中少见,因为缺少大型数据集
- 我们的方法主要与PointContrast对比。
- PointContrast:需要multi-view data and point correspondences.
- 我们:只需要single-view depth scans acquired by varied sensors, without 3D registration and point correspondences ,而且还能 用point cloud and voxel based model architectures 两种架构
Recent work shows that self-supervised learning is useful to pretrain models in 3D but requires multi-view data and point correspondences.
We present a simple self-supervised pretraining method that can work with single-view depth scans acquired by varied sensors, without 3D registration and point correspondences. We pretrain standard point cloud and voxel based model architectures, and show that joint pretraining further improves performance.
- 实验效果:9个benchmark ( object detection, semantic segmentation, and object classification),在 object detection on ScanNet (69.0% mAP) and SUNRGBD (63.5% mAP) 刷新记录。
We pretrain standard point cloud and voxel based model architectures, and show that joint pretraining further improves performance. We evaluate our models on 9 benchmarks for object detection, semantic segmentation, and object classification, where they achieve state-of-the-art results. Most notably, we set a new state-of-the-art for object detection on ScanNet (69.0% mAP) and SUNRGBD (63.5% mAP).
- 少样本良好学习器
Our pretrained models are label efficient and improve performance for classes with few examples.
1. Introduction
- 我们的优势:输入只需要single-view depth maps,很容易从传感器中获得,例如手机。
- 分析最近工作[105]:PointContrast(2020)的缺点:需要multi-view depth scans with point correspondences,但是3D sensors 只能得到single-view depth scans,multi-view depth scans and point correspondences 通常需要3D重建获得,然而3D重建在不稳定的环境下很容易失败。
Recent work [105] applies self-supervised pretraining to 3D models but uses multi-view depth scans with point correspondences. Since 3D sensors only acquire single-view depth scans, multi-view depth scans and point correspondences are typically obtained via 3D reconstruction. Unfortunately, even with good sensors, 3D reconstruction can fail easily for a variety of reasons such as non-static environments, fast camera motion or odometry drift [16].
- 我们的方法DepthContrast:只需要single-view depth scans,回避了上面问题。
- 我们的工作基于 Instance Discrimination method by Wu et al. [103] applied to depth maps, by considering
each depth map as an instance and discriminating between them, even if they come from the same scene - 因3D数据有不同的表示,我们采取联合架构 voxels and point clouds
Since different 3D applications require different 3D scene representations such as voxels for segmentation [17], point clouds for detection [64], we use our method for both voxels and point clouds. We jointly learn features by considering voxels and point clouds of the same 3D scene as data augmentations that are processed with their associated networks [93]
- Our contributions can be summarized as follows:
- single-view 3D depth scans 可以用于自监督学习
- single-view representations 很有用,甚至超过 multi-view
- 可以用多种架构,例如voxels和 point cloud
- 多种表征 联合起来 效果更好
- 9个下游任务效果提升, two object detection tasks (ScanNet and SUNRGBD)取得SOTA效果。我们的模型是有效的小样本学习器。
2. Related Work
- Self-supervised learning for images
Our method extends the work of Wu et al. [103] to multiple 3D input formats following Tian et al. [93] using a momentum encoder [36] instead of a memory bank.
-
Self-supervised learning for 3D data.
最主要的是与PointContrast[15]对比


-
Representations of 3D scenes
In this work, we propose to jointly pretrain two architectures for points and voxels, that are PointNet++ [68] for points and Sparse Convolution based U-Net [17] for voxels.
- 3D transfer tasks and datasets
We use these datasets and evaluate the performance of our methods on the indoor detection [12, 22, 64, 65, 114], scene segmentation [17, 68, 92, 101, 108], and outdoor detection tasks [15, 48, 76–78, 109, 111].
3. DepthContrast
Our method, illustrated in Fig 2, is based on the instance discrimination framework from Wu et al. [103] with a momentum encoder [36].
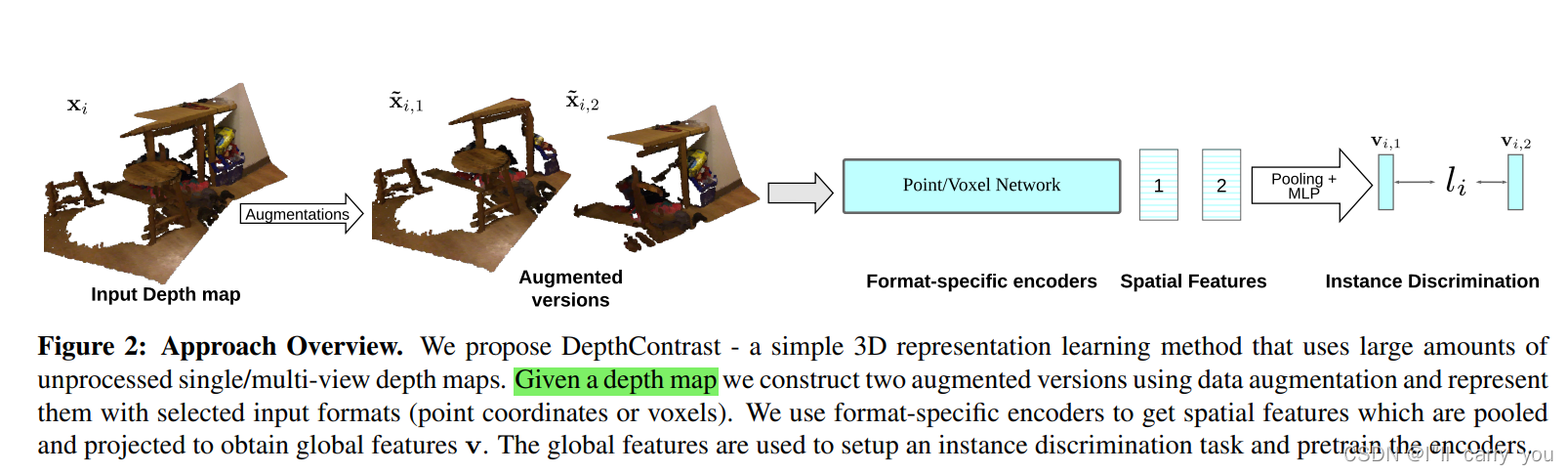
3.1. Instance Discrimination

用了Momentum encoder:This allows us to use a large number K of negative samples without increasing the training batch size


3.2. Extension to Multiple 3D Input Formats
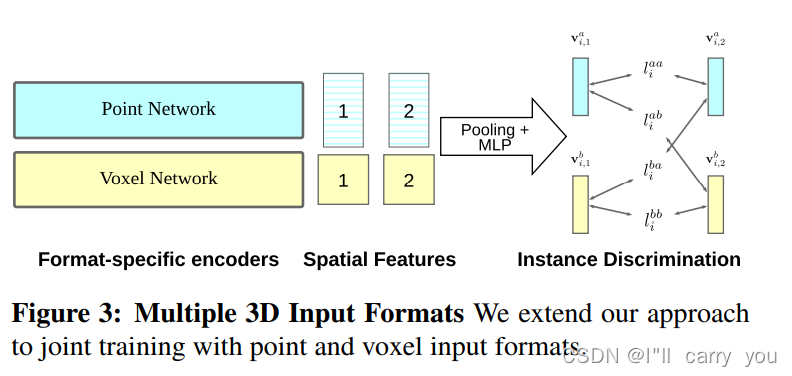
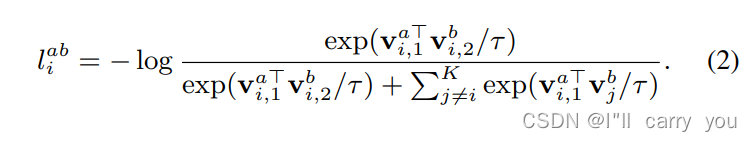
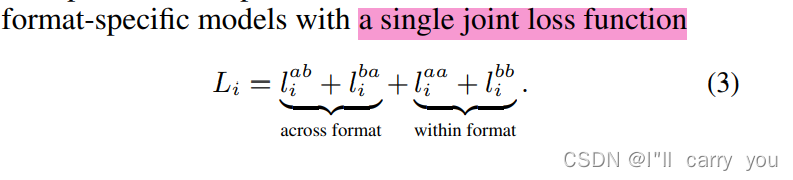
3.3. Model Architecture

3.4. Data Augmentation for 3D

3.5. Implementation Details
4. Experiments
预训练数据集:We use single-view depth map videos from the popular ScanNet [18] dataset and term it as ScanNet-vid.

下游任务:
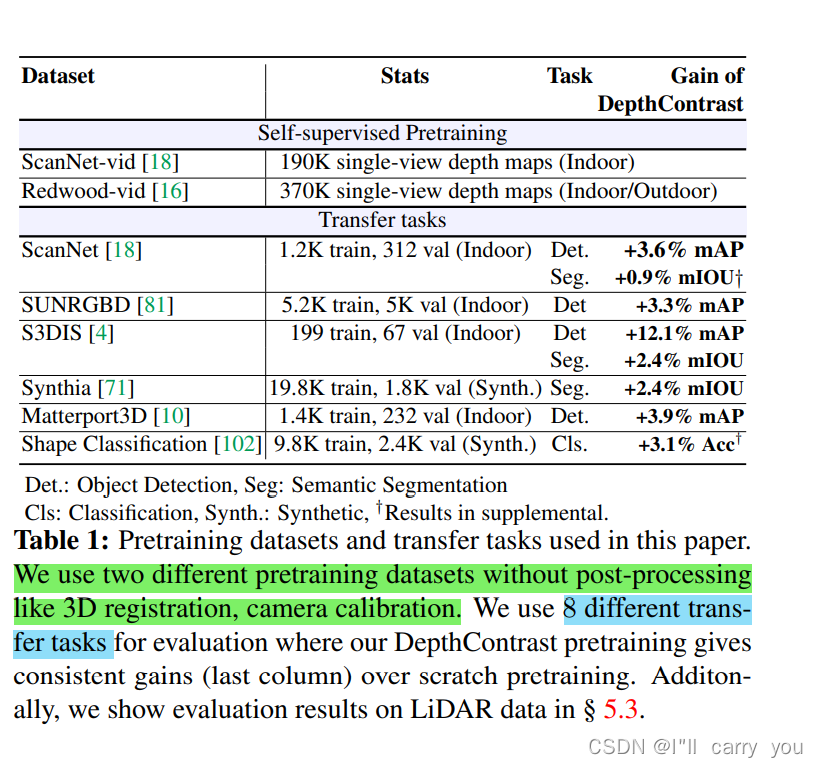
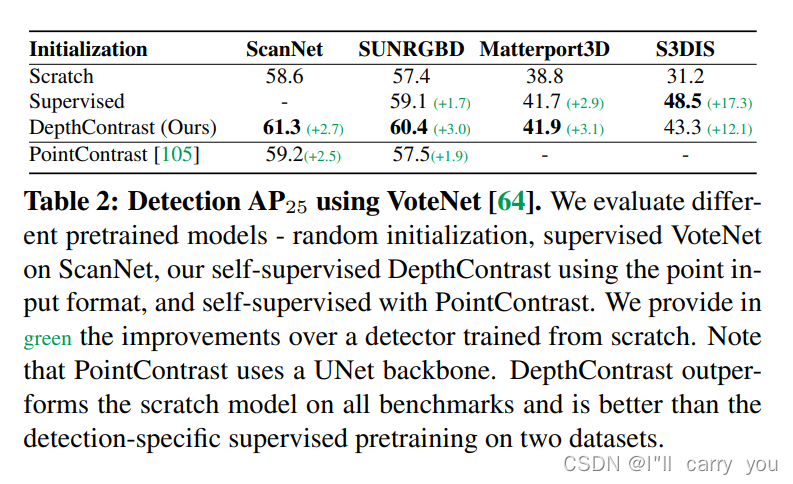
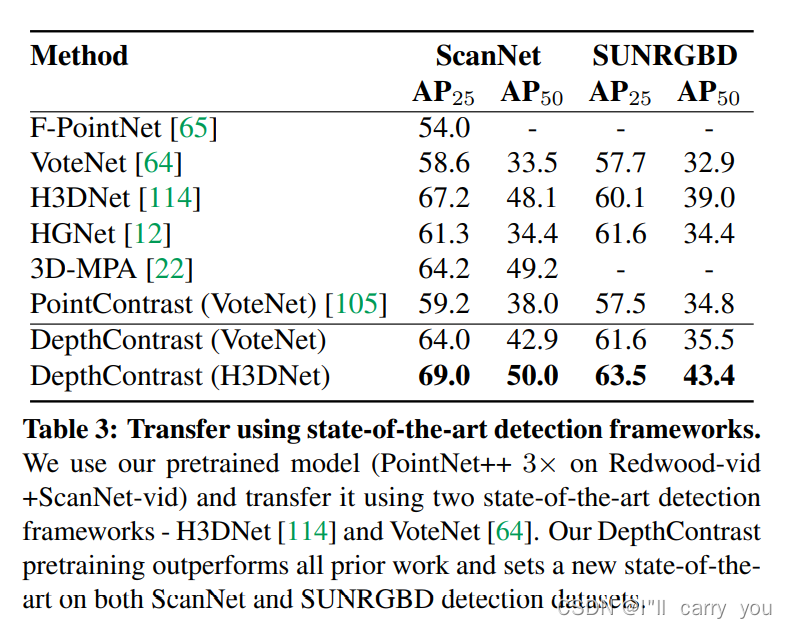
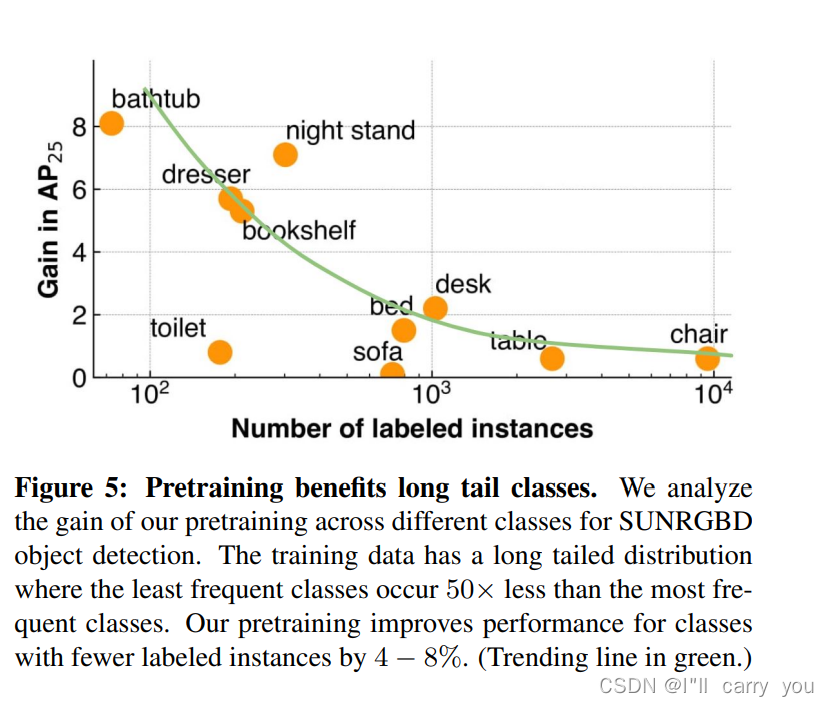
消融实验:
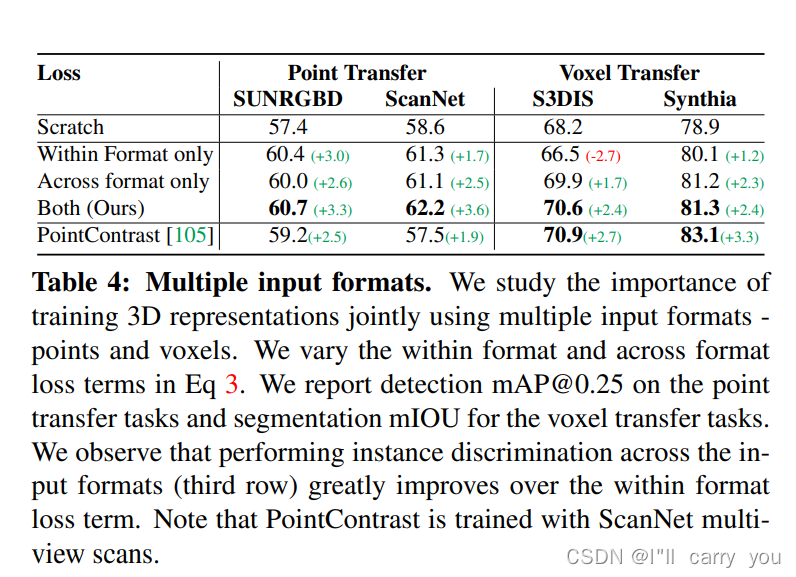
5. Analysis
5.1. Importance of Data Augmentation
5.2. Impact of Single-view or Multi-view 3D Data
5.3. Generalization to Outdoor LiDAR data
6. Conclusion

3. 参考资料
【论文翻译】【ICCV_2021_精】DepthContrast:Self-Supervised Pretraining of 3D Features on any Point-Cloud
4. 收获
- 主要与PointContrast 对比,输入更简单了,但是用的预训练数据集 更大了(ScanNet,Redwood)(在PointContrast 提供了一个见解:预训练 模型要大,自然数据集也跟着变大)
- 这两篇文章 出自 Facebook AI Research, 可以看出 引用资料很多, 实验很足。(按图索骥 点云相关工作…)
- 联合架构的对比损失
- 思想比较简单,但是要做的实验很多…
- 见到了很多点云的很多任务和很多数据集…
- 预训练对长尾分布有用
- 数据增强也重要,这篇文章 增加了自己两个数据增强方法
预训练的关键点:数据集(ScanNet,Redwood),模型( PointNet++ [64] ,sparse convolution U-Net model [17]
),损失函数(Instance Discrimination)