1. 图书管理
增删改查四个接口, 使用分页器对数据进行分页返回.
1.1 准备环境
* 1. 新建项目, 不勾选模块层.
* 2. 将rest_farmework添加到app应用列表中.
INSTALLED_APPS = [
...
'rest_framework',
]
* 3. 自定义响应模块
1. 正常响应
2. dispatch异常响应
# 1. 继承Response自定响应信息
from rest_framework.response import Response
from rest_framework import status
class CustomResponse(Response):
def __init__(self, code=200, msg='访问成功!', data=None, status=status.HTTP_200_OK, **kwargs):
back_info_dict = {
'code': code, 'msg': msg}
if data:
back_info_dict.update(data=data)
back_info_dict.update(kwargs)
# 调用父类的方法生成对象
super().__init__(data=back_info_dict, status=status)
# 2. 定义dispatch的异常的返回格式
from rest_framework.views import exception_handler
def exception_response(exc, context):
# 执行drf的异常处理程序
response = exception_handler(exc, context)
# 返回值为空
if not response:
# 细分请求异常信息
if isinstance(exc, Exception):
return CustomResponse(501, f'访问不成功! {
exc}', status=status.HTTP_501_NOT_IMPLEMENTED)
# 三大认证异常
return CustomResponse(501, f"访问不成功! {
response.data}", status=status.HTTP_501_NOT_IMPLEMENTED)
* 4. 项目配置文件settings.py中, 全局配置dispatch异常响应.
只能全局配置, 自定义的异常响应, 值就是一个字符串, 不能是列表['自定义的异常响应']
# DRF配置
REST_FRAMEWORK = {
# dispatch异常响应, 值只能是一个字符串, 不要使用列表
'EXCEPTION_HANDLER': 'utils.response.exception_response',
}
* 5. 测试路由, 路由分发模式
from django.conf.urls import url, include
from django.contrib import admin
# 导入子路由
from app01 import urls
urlpatterns = [
url(r'^admin/', admin.site.urls),
# books api
url(r'^app01/api/', include(urls))
]
* 6. 子路由
from django.conf.urls import url, include
from django.contrib import admin
# 导入视图层
from app01 import views
urlpatterns = [
# 主键有或没有
url('^books/(?P<pk>(\d+)?)', views.BookAPI.as_view()),
]
* 7. BooksAPI视图
# BooksAPI视图
class BookAPI(GenericAPIView):
...
1.2 表设计
外键字段参数:
on_delete: 删除关联数据与之关联的信息的行为
当删除关联表中的数据数, 当前表与其关联表的行为.
models.CASCADE 删除关联数据, 与之关联的信息也删除, 慎重使用.
models.DOTHING 删除关联数据, 引发错误IntegerityError
models.PROTECT 删除关联数据, 引发错误ProtectedError
models.SET_NULL 删除关联数据, 与之关联的值设置为null, 前提条件: 该字段可为空.
models.SET_DEFAULT 删除关联数据, 与之关联的值设置为默认值, 前提条件: 该字段可设置默认值.
models.SET 删除关联数据,
1. 与之关联的值设置为指定值, 设置: models.SET(值)
2. 与之关联的值设置为可执行对象的放回值, 设置: models.SET(可执行对象)
db_constraint: 与外键建立的关系.
db_constraint=True 建立真正的关联, 增删的操作受外键影响.
db_constraint=False 建立逻辑关联, 增删的操作不受外键影响. ORM操作与之前一样.
增删的操作.
表断关联
1. 表之间没有外键关联, 但是有外键逻辑关联(有充当外键的字段)
2. 断关联后不会影响数据库查询效率, 但是会极大提高数据库的增删改效率(不影响增删改查操作)
3. 段关联一定要通过编写逻辑代码保证表之间数据安全, 不要出现脏数据.
4. 级联关系:
一对一, 作者没有, 作者详情页也跟随没有, on_delete=models.CASCADE
一对多, 出版社没有了, 书还是存在, 出版的的id还在, on_delete=models.DO_NOTHING
部门没了, 员工没有部分, on_delete=models.SET_NULLM, 该字段允许为空 null=true
部门没了, 员工进入默认部门, on_delete=models.SET_DEFAULT, 该字段设置了默认值, default='z部门'
* 1. 基础表
删除数据不是真正的删除, 设置一个字段, 值为False代表数据被删除
创建数据时, 自动添加创建时间
修改数据时, 自动更新修改文件时间
from django.db import models
# Create your models here.
# 1. 继承表
class BaseModel(models.Model):
# 删除标识
is_delete = models.BooleanField(default=False)
# 创建时间, auto_now_add=True 创建数据时, 自动添加当前时间
create_time = models.DateTimeField(auto_now_add=True)
# 修改数据, auto_now=True 修改文件时候, 自动添加当前时间
last_update_time = models.DateTimeField(auto_now=True)
# 定义Meta类
class Meta:
abstract = True # 抽象类, 不在数据库中创建这张表
* 2. 书籍表
# 2. 书籍表
class Book(BaseModel):
# 主键 verbose_name 详细名称, help_text 提示信息
book_id = models.AutoField(primary_key=True, verbose_name='书籍主键', help_text='书籍主键')
# 书名
title = models.CharField(max_length=32, verbose_name='书名', help_text='书的名字')
# 价格
price = models.CharField(max_length=32, verbose_name='价格', help_text='书的价格')
# 外键 出版社一对多书籍表, db_constraint=False, 不建立真正的关联
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE, db_constraint=False, verbose_name='外键,关联出版社')
# 虚拟字段 书籍表多对多作者, 虚拟表不能设置on_delete
author = models.ManyToManyField(to='Author', db_constraint=False, verbose_name='虚拟, 关联作者')
# 定义Meta类
class Meta:
# 在后台管理显示的表名称
verbose_name_plural = '书籍表'
# 打印对象展示的信息
def __str__(self):
return f'{
self.title}'
* 3. 出版社
# 3.出版社表
class Publish(BaseModel):
# 主键
publish_id = models.AutoField(primary_key=True, verbose_name='出版社主键')
# 出版社名字
name = models.CharField(max_length=32, verbose_name='出版社名字', help_text='出版社名字')
# 邮箱
email = models.EmailField(verbose_name='出版社邮箱')
# 地址
address = models.CharField(max_length=32, verbose_name='出版社地址')
# 定义Meta类
class Meta:
# 在后台管理显示的表名称
verbose_name_plural = '出版社表'
# 打印对象展示的信息
def __str__(self):
return f'{
self.name}'
* 4. 作者
# 4. 作者表
class Author(BaseModel):
# 主键
author_id = models.AutoField(primary_key=True, verbose_name='作者主键')
# 名字
name = models.CharField(max_length=32, verbose_name='作者名字')
# 性别
gender = models.IntegerField(choices=((1, '男'), (2, '女')), verbose_name='性别')
# 外键
detail = models.OneToOneField(to='AuthorDetail', on_delete=models.CASCADE, db_constraint=False,
verbose_name='外键, 关联详情')
# 定义Meta类
class Meta:
# 在后台管理显示的表名称
verbose_name_plural = '作者表'
# 打印对象展示的信息
def __str__(self):
return f'{
self.name}'
* 5. 作者详情
# 5. 作者详情表
class AuthorDetail(BaseModel):
# 自动生成主键
# 邮箱
email = models.EmailField(verbose_name='作者邮箱')
# 微信
WeChat = models.CharField(max_length=32, verbose_name='微信')
# 定义Meta类
class Meta:
# 在后台管理显示的表名称
verbose_name_plural = '作者详情表'
# 打印对象展示的信息
def __str__(self):
return f'邮箱: {
self.email} - 微信: {
self.WeChat}'
生成表记录, 数据库迁移
python3.6 manage.py makemigrations
python3.6 manage.py migrate
1.3 注册表
使用admin的后台管理操作表, 在app应用的admin.py文件中注册表.
from django.contrib import admin
# Register your models here.
# 导入模型层
from app01 import models
# 注册表
admin.site.register(models.Book)
admin.site.register(models.Publish)
admin.site.register(models.Author)
admin.site.register(models.AuthorDetail)
1.4 创建超级用户
python3.6 manage.py createsuperuser
Username (leave blank to use '13600'): root
Email address: 136@qq.com
Password: zxc123456
Password (again): zxc123456
Superuser created successfully.
1.5 登入后台
* 1. 为作者详情添加表数据

* 2. 为作者表添加数据
* 3. 为出版社添加数据
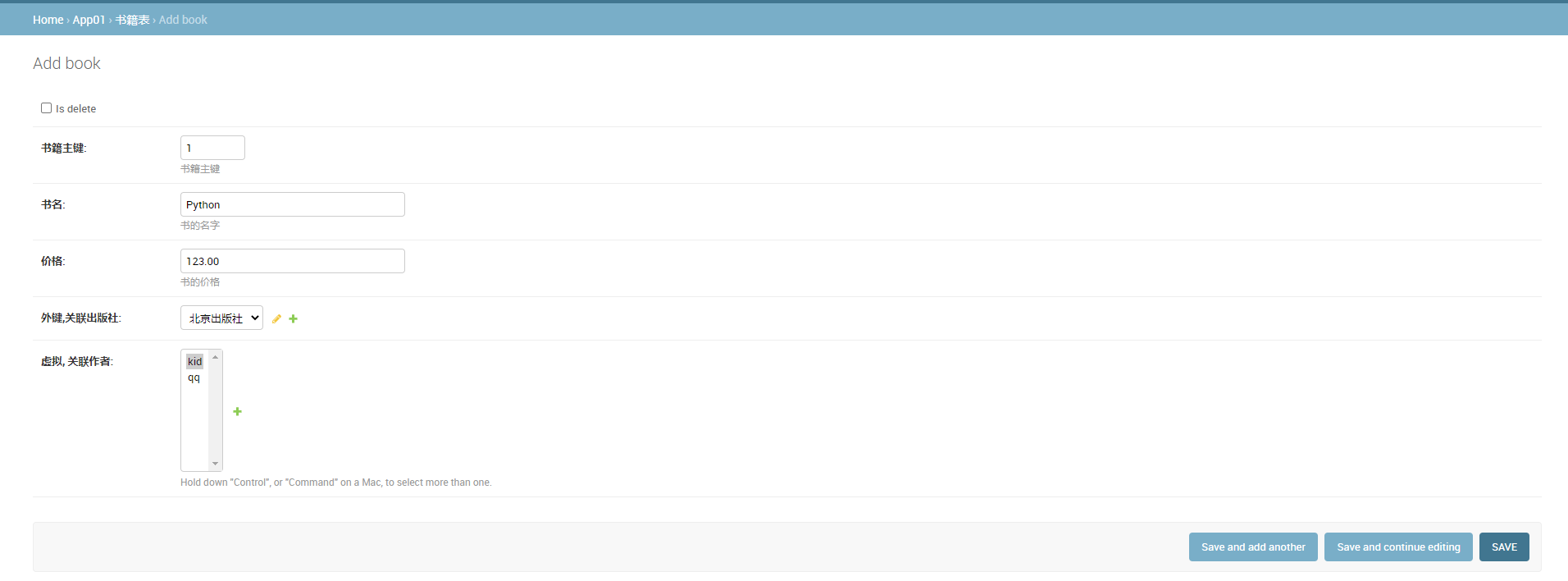
* 4. 为书籍表添加数据
1.6 数据查询
* 1. 模型序列化器
# 导入序列化器模块
from rest_framework import serializers
# 导入模型层
from app01 import models
# 图书序列化器
class BookModelSerializer(serializers.ModelSerializer):
# 定义Meta类
class Meta:
# 关联的表模型
model = models.Book
# 序列化的字段
fields = ('title', 'price', 'publish', 'author')
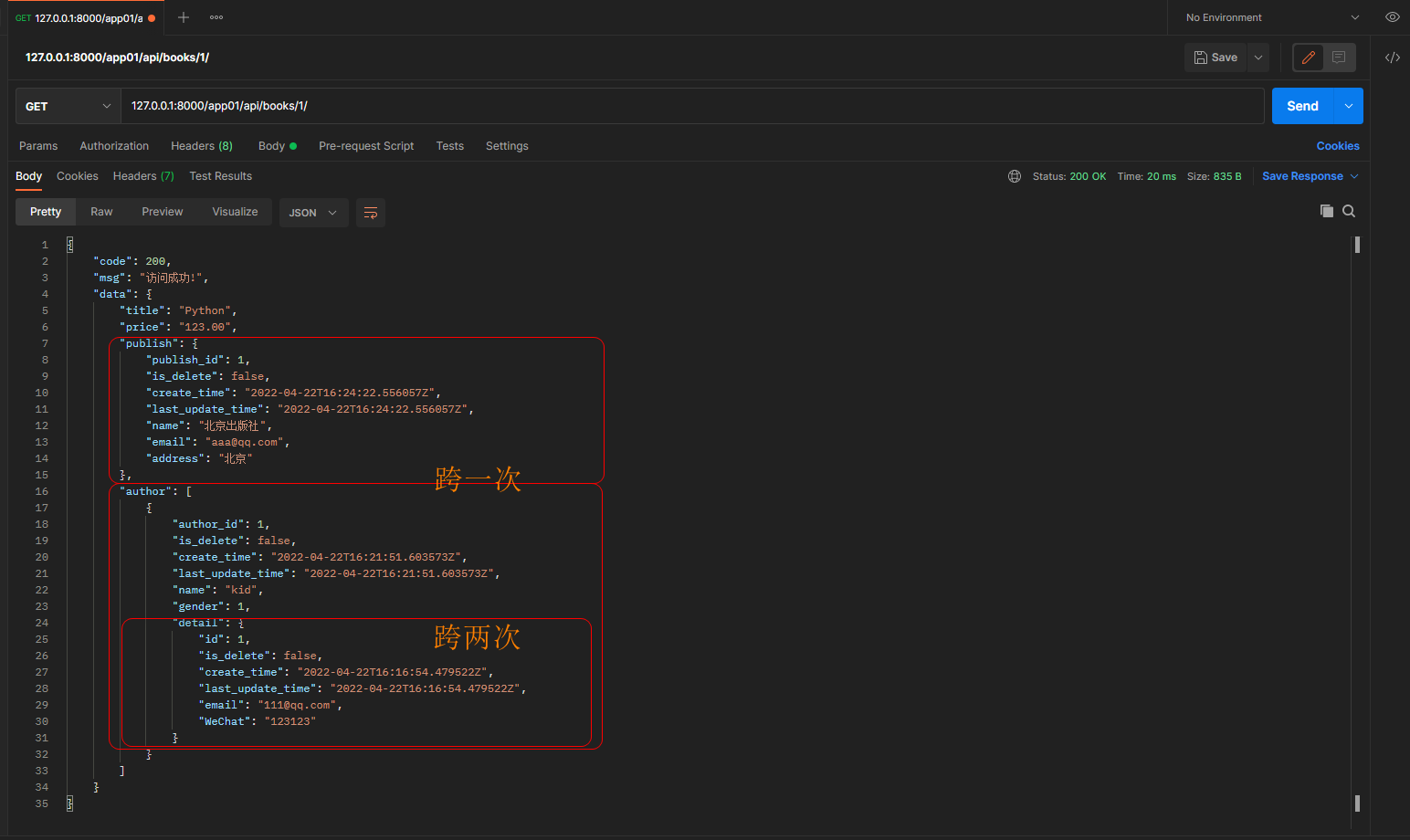
# 跨记张表进行查询, 不推荐使用, 最大不推荐超过10
depth = 2
* 2. BooksAPI 视图类
from django.shortcuts import render
# Create your views here.
# book api
from rest_framework.generics import GenericAPIView
from app01 import models
from utils import serializers
from utils.response import CustomResponse
class BookAPI(GenericAPIView):
queryset = models.Book.objects.all()
serializer_class = serializers.BookModelSerializer
# 查
def get(self, request, *args, **kwargs):
# 判断是否有主键, 单数据查询
pk = kwargs.get('pk')
if pk:
print(pk)
book_obj = self.get_object()
book_dict = self.get_serializer(instance=book_obj)
# 查询所有数据
else:
book_obj = self.get_queryset().filter(is_delete=False)
# 转换数据 queryset --> dict
book_dict = self.get_serializer(instance=book_obj, many=True)
return CustomResponse(data=book_dict.data)
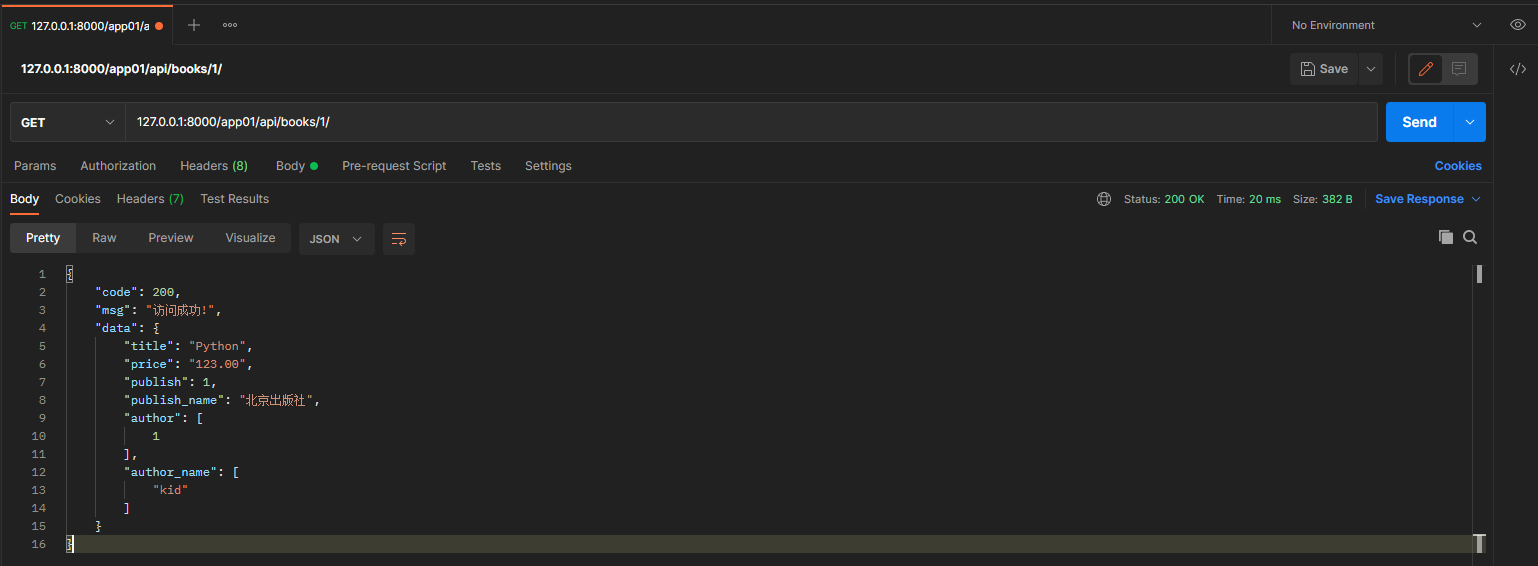
* 3. 单条数据查询, depth = 2
get请求: 127.0.0.1:8000/app01/api/books/1/
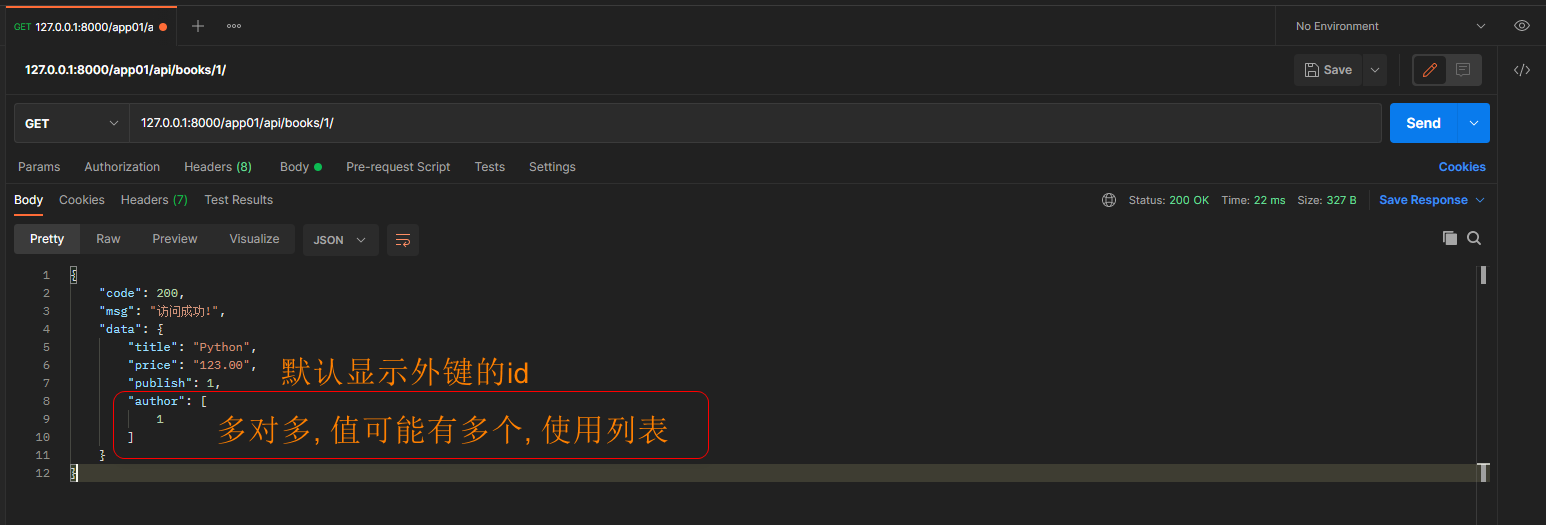
* 4. 单条数据查询, depth = 0
get请求: 127.0.0.1:8000/app01/api/books/1/
扫描二维码关注公众号,回复:
14141798 查看本文章

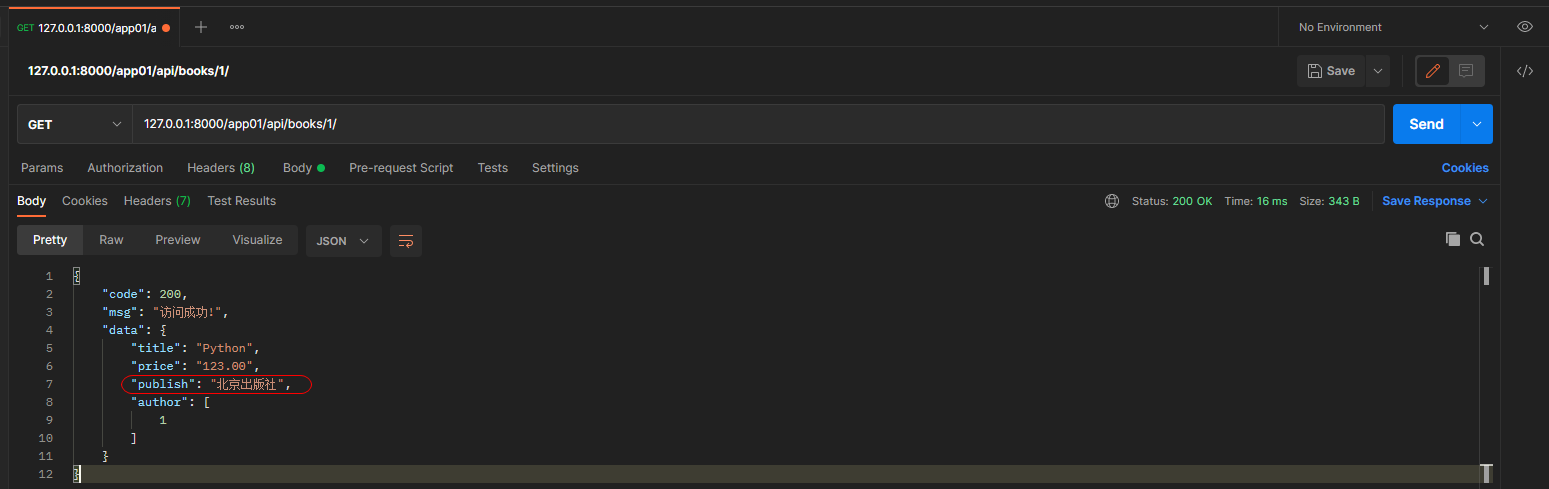
* 5. 在序列化器中设置想要展示的值, 方式1:
重写 publish字段的序列化, source = '表名.字段'
# 图书序列化器
class BookModelSerializer(serializers.ModelSerializer):
# 定义Meta类
# 重写 publish字段的序列化, 在写入数据反序列化会有问题
publish = serializers.CharField(source='publish.name')
class Meta:
# 关联的表模型
model = models.Book
# 序列化的字段
fields = ('title', 'price', 'publish', 'author')
get请求: 127.0.0.1:8000/app01/api/books/1/
* 6. 在序列化器中设置想要展示的值, 方式2:
在表模型类中添加静态方法, fields = ['静态方法', ]
# 获取出版社的名字
@property
def publish_name(self):
return self.publish.name
# 获取作者的名字, 值可能有多个
@property
def author_name_list(self):
authors = self.author.all()
# [作者1, 作者2]
return [author.name for author in authors]
* 7. 设置原来的外键为只些模式, 读出来也没有用, 在写入数据时使用. 需要使用.
# 图书序列化器
class BookModelSerializer(serializers.ModelSerializer):
# 定义Meta类
# 重写 publish字段的序列化
# publish = serializers.CharField(source='publish.name')
class Meta:
# 关联的表模型
model = models.Book
# 序列化的字段
fields = ('title', 'price', 'publish', 'publish_name', 'author', 'author_name_list')
# 跨记张表进行查询, 不推荐使用, 最大不推荐超过10
depth = 0
extra_kwargs = {
# 原本的出版社外键 作者表虚拟字段 设置为只读
'publish': {
'write_only': True},
'publish_name': {
'read_only': True},
'author': {
'write_only': True},
'author_name_list': {
'read_only': True},
}
get请求: 127.0.0.1:8000/app01/api/books/1/
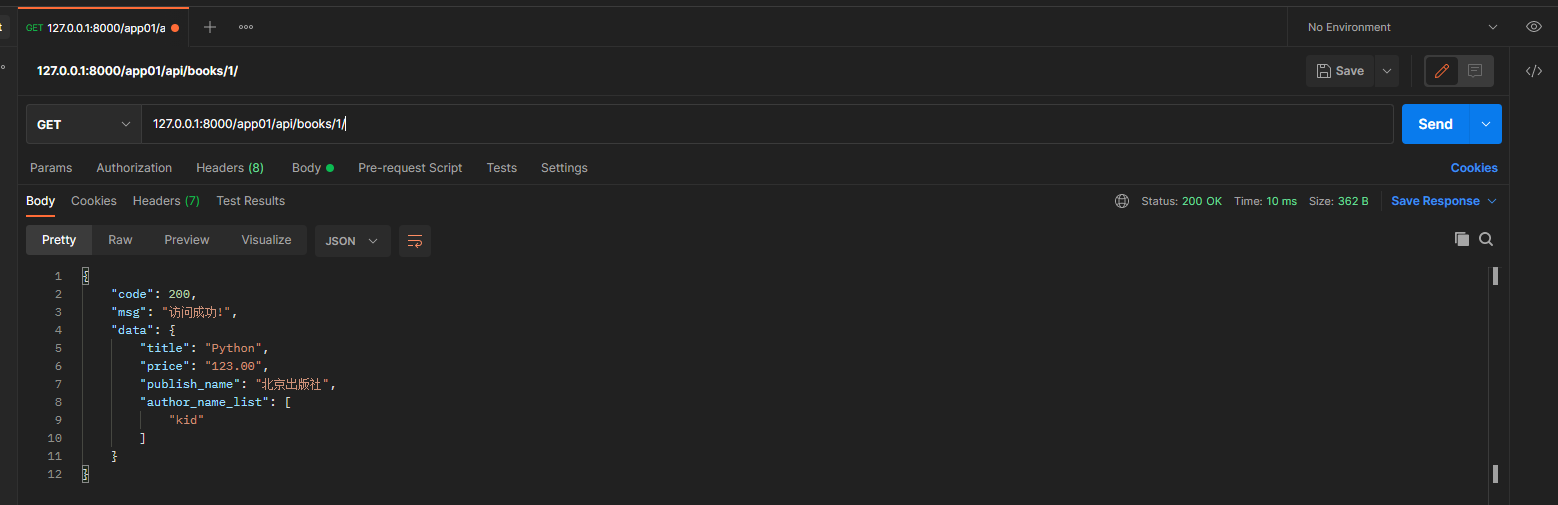
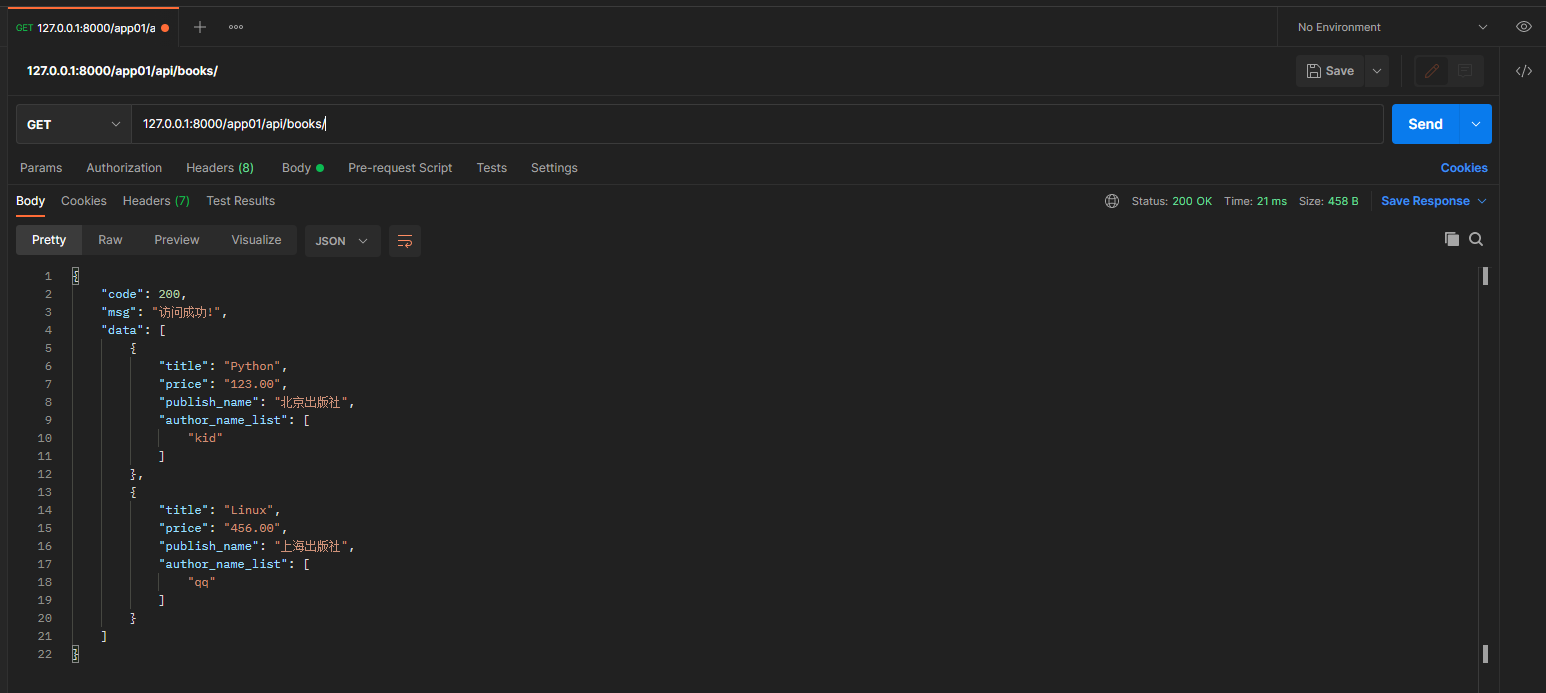
* 8. 查询所有数据
get请求: 127.0.0.1:8000/app01/api/books/
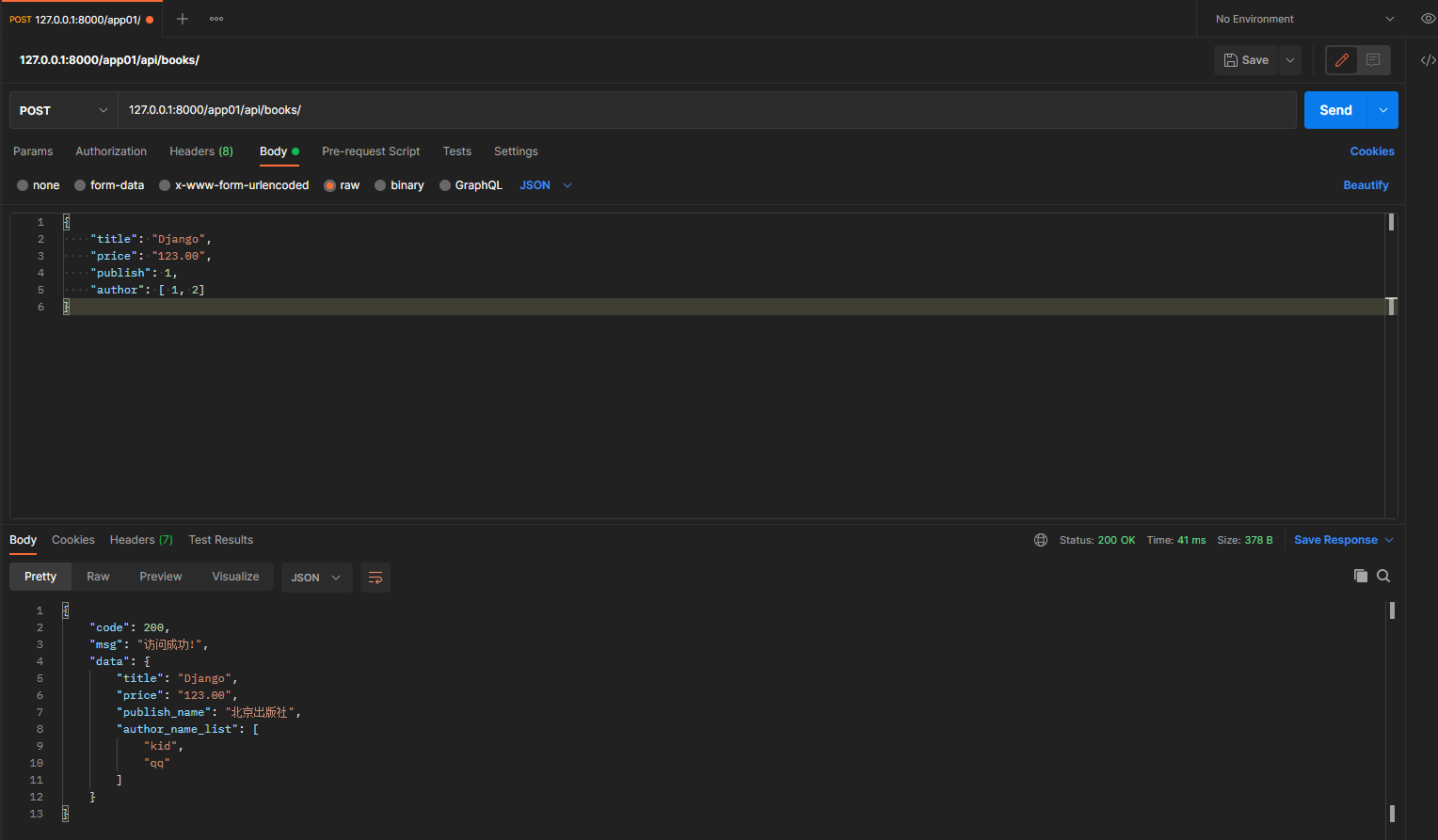
1.7 新增数据
手动删除books表中的两条数据, 等下数据多了不好做实验.
* 1. 新增一条数据
post请求: 127.0.0.1:8000/app01/api/books/
携带的json数据:
{
"title": "Django",
"price": "123.00",
"publish": 1,
"author": [ 1, 2]
}
* 2. 批量增加数据
# 增, 单增, 多增
def post(self, request, *args, **kwargs):
# request.data 一条数据是字典, 多条数据是列表
if isinstance(request.data, dict):
# 调用模型序列化器
book_obj = self.get_serializer(data=request.data)
else:
# 调用模型序列化器, 多个值
book_obj = self.get_serializer(data=request.data, many=True)
# 校验数据, raise_exception 数据不合格之后抛异常
book_obj.is_valid(raise_exception=True)
# 保存数据
book_obj.save()
# 返回新增的数据
return CustomResponse(data=book_obj.data)
self.get_serializer(data=request.data,)
对应的类型: <class 'utils.serializers.BookModelSerializer'>
self.get_serializer(data=request.data, many=True)
对应的类型: <class 'rest_framework.serializers.ListSerializer'>
from rest_framework.serializers import ListSerializer
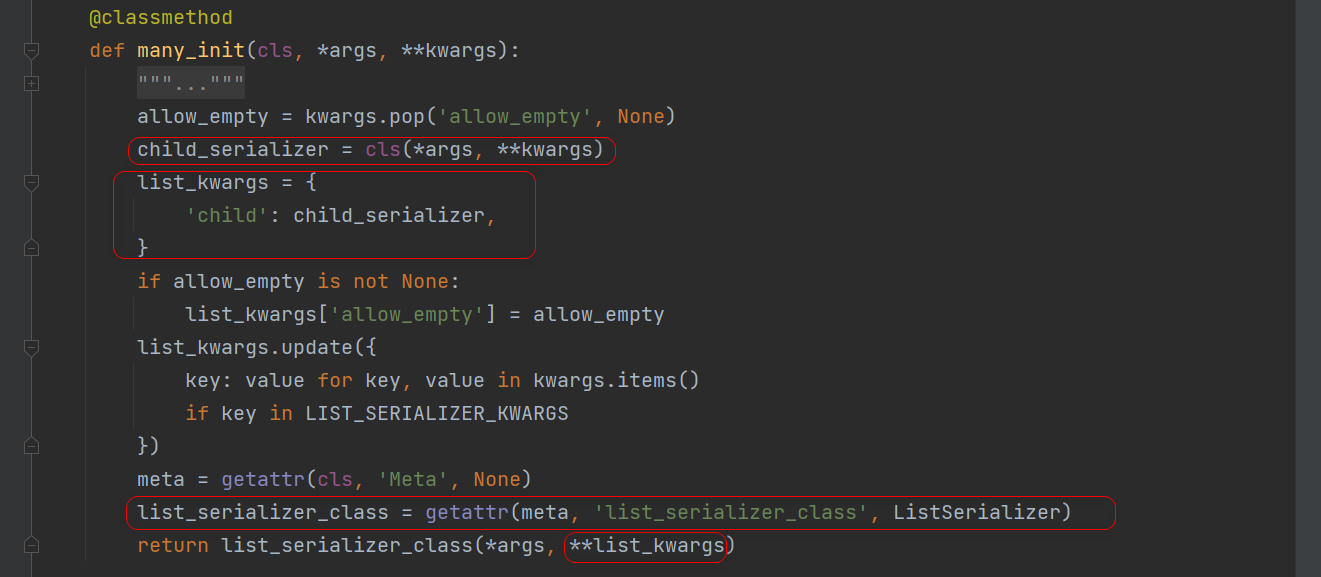
从序列化对象中, 获取list_serializer_class 属性的值, 如果获取不到就是用ListSerializer
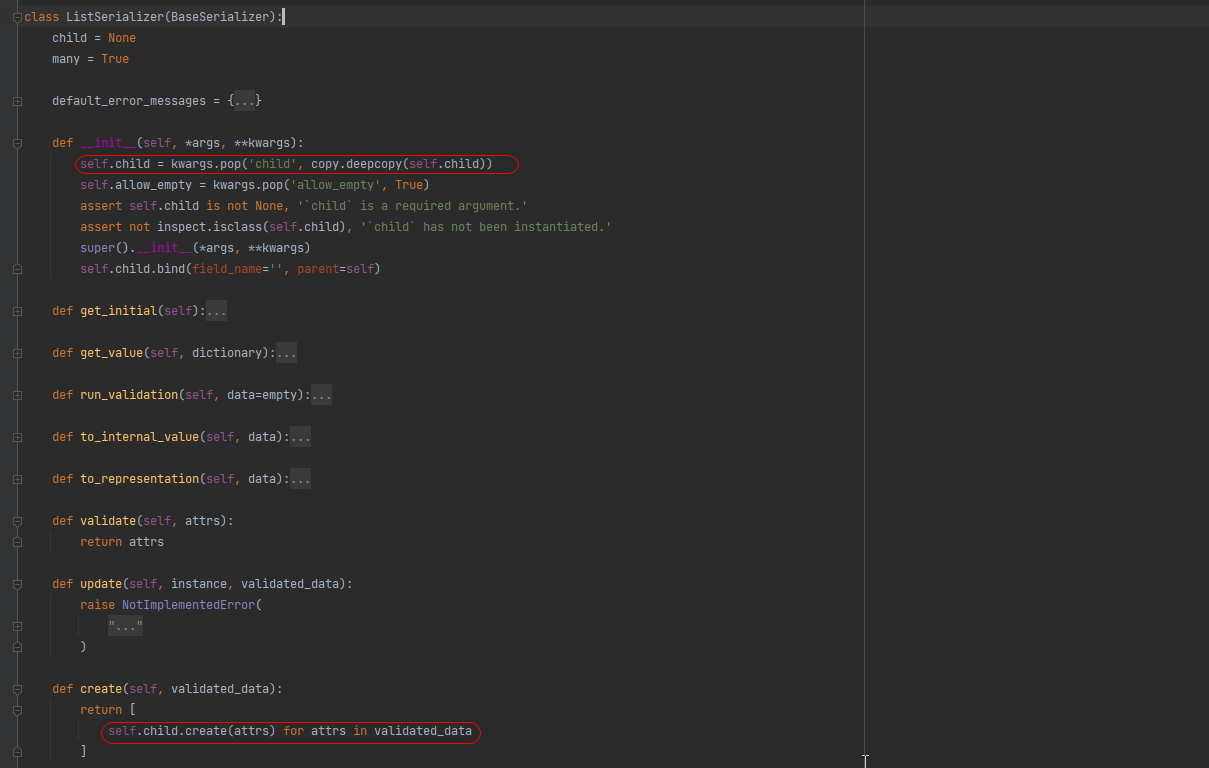
many不为True 使用的是 ModelSerializer的create()方法.
many为True ListSerializer 重复使用 ModelSerializer的create()方法创建数据.
ListSerializer 对象.create()
# 创建方法, 重复调用child的create方法将数据创建到数据库.
def create(self, validated_data):
return [
self.child.create(attrs) for attrs in validated_data
]
validated_data的数据:
[{
'title': 'Python', 'price': '123.00',
'publish': <Publish: 北京出版社>, 'author': [<Author: 北京出版社>]},
{
'title': 'Linux', 'price': '456.00',
'publish': <Publish: 上海出版社>, 'author': [<Author: 上海出版社>]}]
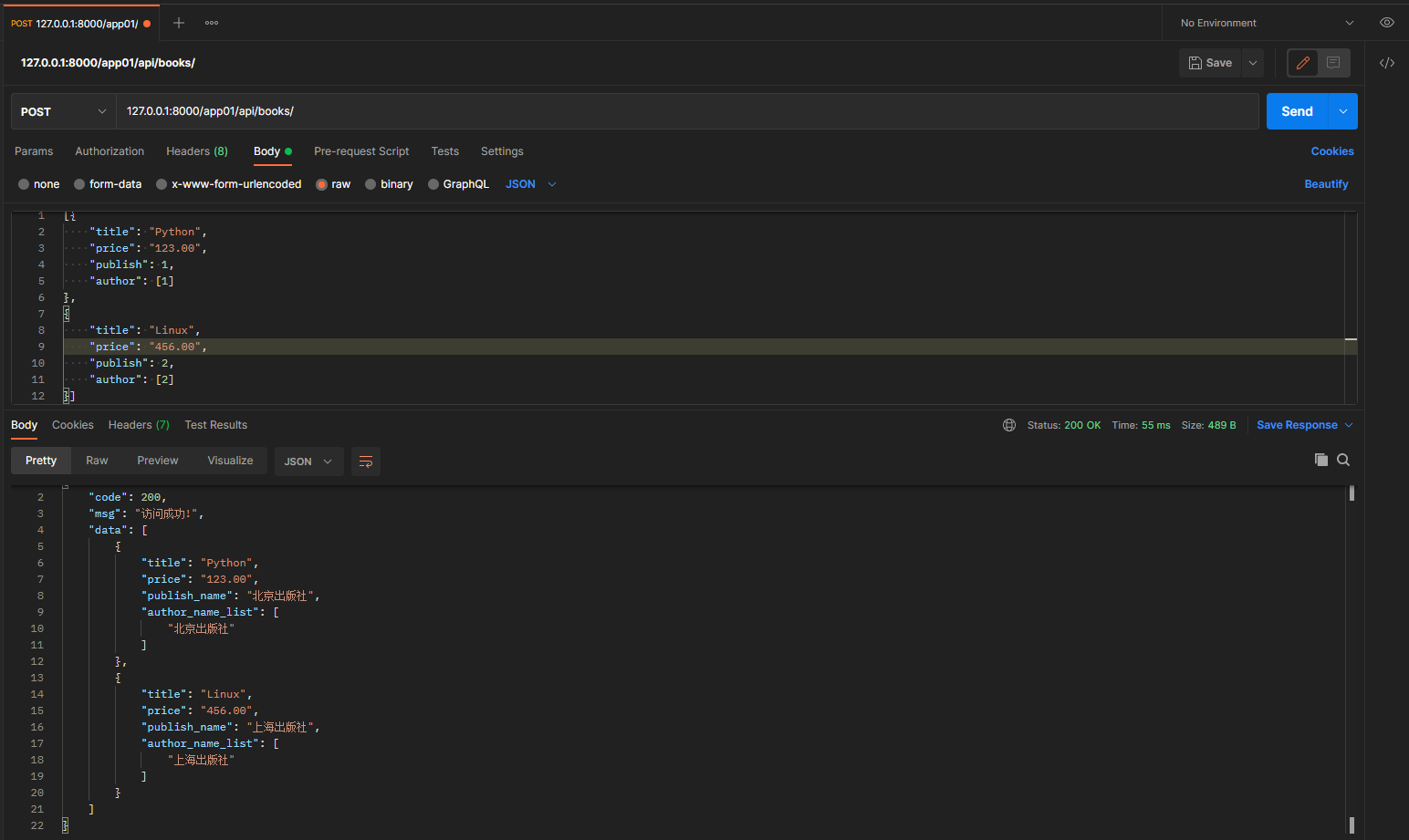
post请求: 127.0.0.1:8000/app01/api/books/
携带的json数据:
[{
"title": "Python",
"price": "123.00",
"publish": 1,
"author": [1]
},
{
"title": "Linux",
"price": "123.00",
"publish": 2,
"author": [2]
}]
1.8 修改数据
* 1. 单条数据修改
# 改, 单该
def put(self, request, *args, **kwargs):
pk = kwargs.get('pk')
#
if pk:
book_obj = self.get_queryset().filter(pk=pk).first()
book_dic = self.get_serializer(instance=book_obj, data=request.data)
# 数据校验
book_dic.is_valid(raise_exception=True)
# 保存数据
book_dic.save()
return CustomResponse(data=book_dic.data)
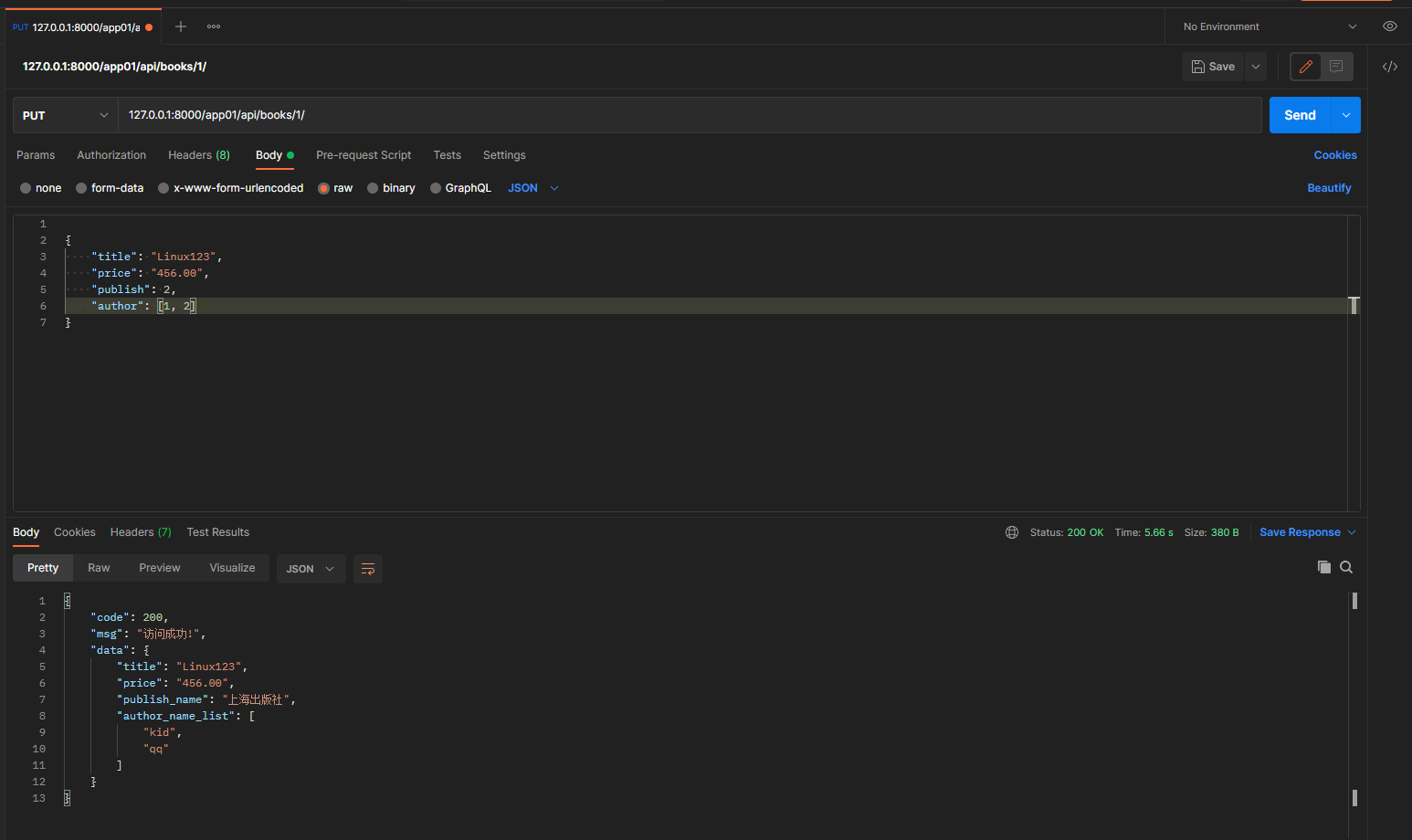
put请求: 127.0.0.1:8000/app01/api/books/1/
携带的json数据:
{
"title": "Linux123",
"price": "456.00",
"publish": 2,
"author": [1, 2]
}
* 2. 多条数据修改, 数据传入的格式是多条[{}, {}], 在使用序列化器之后many=True, 生成一个ListSerializer
对象. 改对象中作者只写了create方法, update没有写, 我们可以继承ListSerializer, 重新该方法.
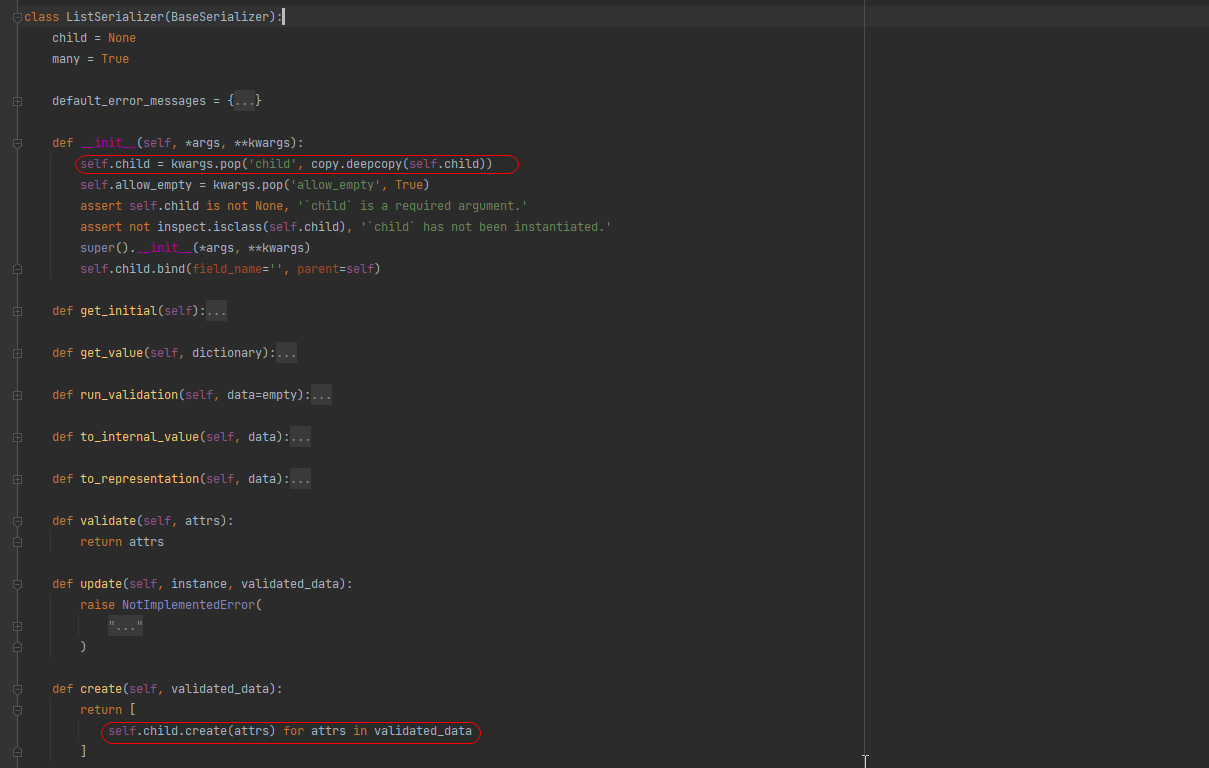
* 3. 继承ListSerializer重新update方法. 在自定义update方法中循环调用模型序列化类的update方法添加数据.
前端传递的数据需要携带主键.
# 导入序列化器模块
from rest_framework import serializers
# 导入模型层
from app01 import models
# 定义一个ListSerializer
class BookListSerializer(serializers.ListSerializer):
# instance参数接收数据对象, data接收修改的数据,
def update(self, instance, validate_value):
return [ # # 修改的对象 写入的数据
self.child.update(instance[i], data) for i, data in enumerate(validate_value)
]
# 图书序列化器
class BookModelSerializer(serializers.ModelSerializer):
# 定义Meta类
# 重写 publish字段的序列化
# publish = serializers.CharField(source='publish.name')
class Meta:
# 使用自定义的ListSerializer
list_serializer_class = BookListSerializer
# 关联的表模型
model = models.Book
# 序列化的字段
fields = ('title', 'price', 'publish', 'publish_name', 'author', 'author_name_list')
# 跨记张表进行查询, 不推荐使用, 最大不推荐超过10
depth = 0
extra_kwargs = {
# 原本的出版社外键 作者表虚拟字段 设置为只读
'publish': {
'write_only': True},
'publish_name': {
'read_only': True},
'author': {
'write_only': True},
'author_name_list': {
'read_only': True},
}
* 4. 批量修改代码
# 改, 单该, 批量修改
def put(self, request, *args, **kwargs):
pk = kwargs.get('pk')
# 单改
if pk:
# 获取修改的对象
book_obj = self.get_queryset().filter(pk=pk).first()
# 序列化处理
book_dic = self.get_serializer(instance=book_obj, data=request.data)
# 批量改
else:
# 一个数据对象列表, 一个提交的数据列表
data_dict = []
obj_list = []
# 遍历提交的数据
for items in request.data:
# 获取book_id
pk = items.pop('book_id')
# 获取对应的数据对象
book_obj = self.get_queryset().filter(pk=pk).first()
# 将剔除了book_id的字典数据存储到列表中
data_dict.append(items)
# 将对应的数据对象条件到列表中
obj_list.append(book_obj)
# 多个数据序列化
book_dic = self.get_serializer(instance=obj_list, data=data_dict, many=True)
# 校验数据
book_dic.is_valid(raise_exception=True)
# 保存数据, get_serializer传递instance, data会 触发update方法
"""
type(book_dic)
没有使用 many=True 序列化的是 模型序列化类.
调用轨迹 模型序列化类的父类的父类.save() 中self.update() self是 模型序列化类, 调用模型序列化类.update()方法
使用 many=True 序列化的是 ListSerializer类
调用轨迹 模型序列化类的父类的父类.save() 中self.update() self是 ListSerializer类, 调用ListSerializer类.update()方法
ListSerializer类.update()方法 中 在遍历调用 调用模型序列化类.update()方法, 自己控制好传入的值就好了...
"""
book_dic.save()
return CustomResponse(data=book_dic.data)
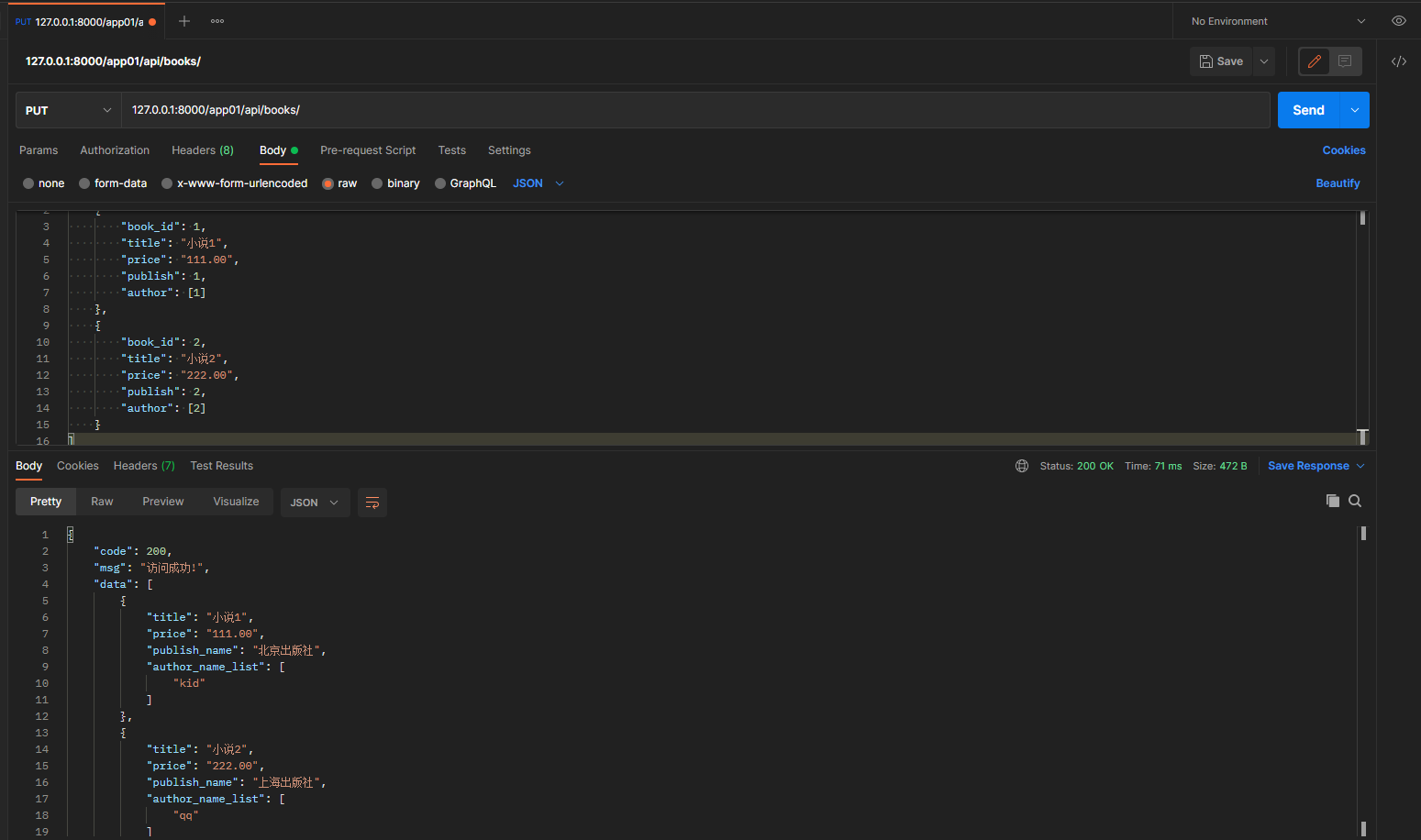
put请求: 127.0.0.1:8000/app01/api/books/
携带的json格式数据:
[
{
"book_id": 1,
"title": "小说1",
"price": "111.00",
"publish": 1,
"author": [1]
},
{
"book_id": 2,
"title": "小说2",
"price": "222.00",
"publish": 2,
"author": [2]
}
]
1.9 删除数据
修改数据对象的is_delete字段, 不是真正的删除数据...
# 删 单除, 批量删除
def delete(self, request, *args, **kwargs):
# 定义一个列表, 存储需要删除的书籍主键
del_list = []
# 获取pk
pk = kwargs.get('pk')
if pk:
del_list.append(pk)
else:
del_list = request.data.get('del_list')
# 修改字段is_delete的值 __in [ , , ] 返回被影响的数目
num = self.get_queryset().filter(pk__in=del_list, is_delete=False).update(is_delete=True)
if num:
return CustomResponse(data=f'删除了{
num}条数据')
return CustomResponse(data='没有删除数据, 删除的数据可能不存在, 或者已经被删除!')
* 1. 删除一条数据
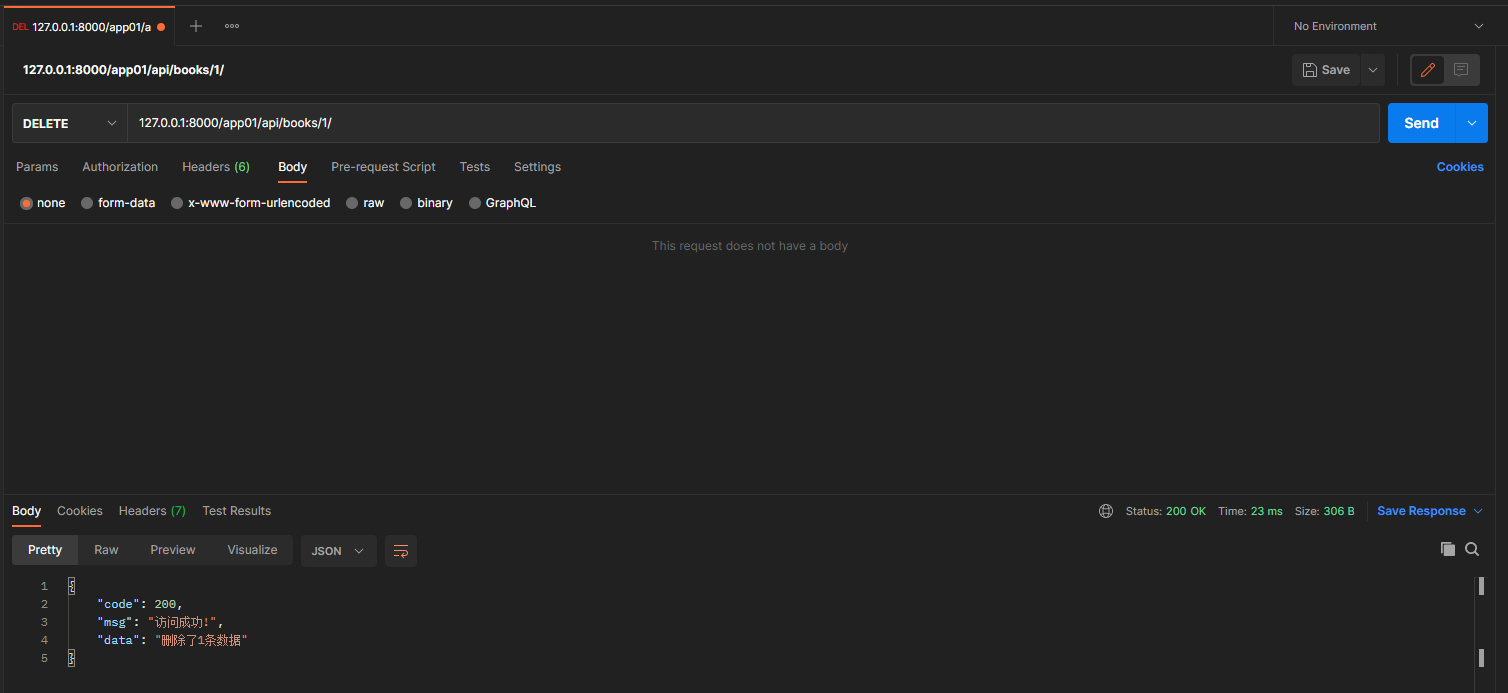
* 2. 批量删除数据

1.10 局部修改
patch方法用来更新局部资源, 入数据有10个字段, 修改数据时自己只提供2个字段, 其他的字段信息都不提供.
put可以通通过修改一些参数来实现以上的功能, 就没必要在写patch请求方法了.
eg: 发送put请求, 序列化的字段就是必填的. 可以通过参数设置改字段不是必须填写的.
或者在使用模型序列化器时, 设置partial=True, 没有传递值的字段不是必填的.
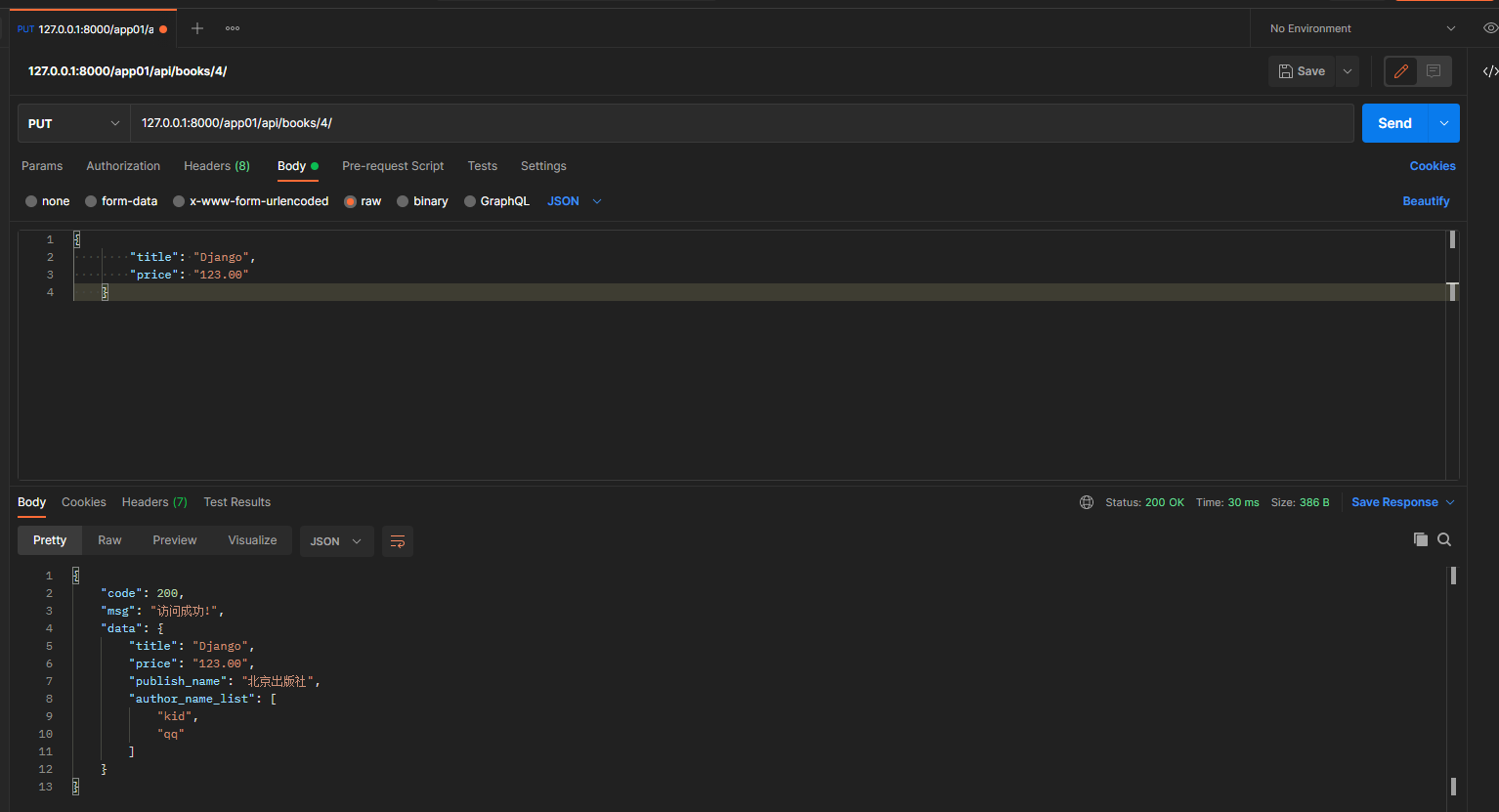
put请求: 127.0.0.1:8000/app01/api/books/4/
携带的json数据:
{
"title": "Django",
"price": "123.00"
}
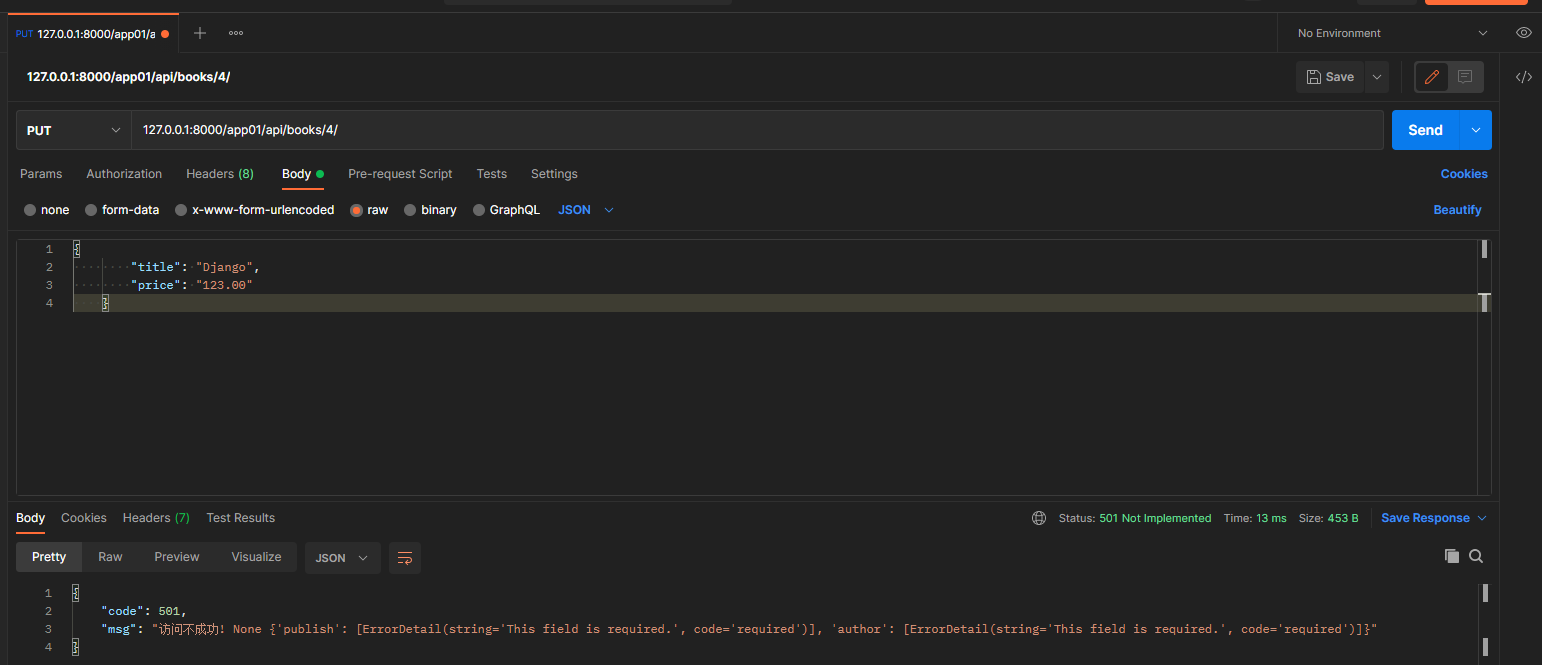
# 单条数据修改, 添加partial参数
book_dic = self.get_serializer(instance=book_obj, data=request.data, partial=True)
再次访问, 实现局部修改...
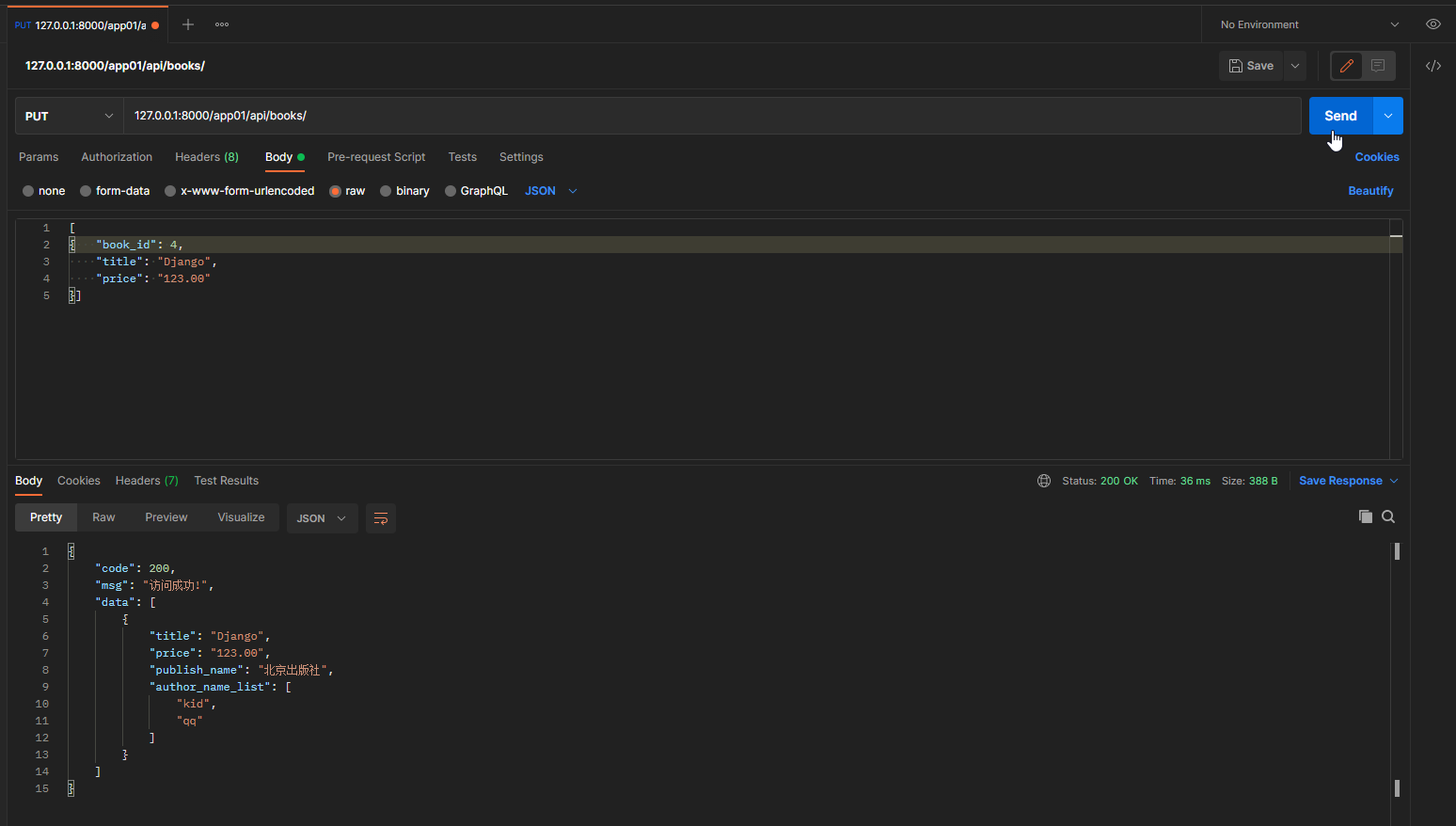
# 多条数据修改, 添加partial参数
book_dic = self.get_serializer(instance=obj_list, data=data_dict, many=True, partial=True)
put请求: 127.0.0.1:8000/app01/api/books/
携带的json数据:
[
{
"book_id": 4,
"title": "Django",
"price": "123.00"
}]
1.11 视图子类使用分页器
rest_framework 内置三种分页器
from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination, CursorPagination
页码分页, 限制偏移分页, 光标分页
从视图子类开始不需要手定调用分类器的方法. 只需要配置好属性值即可使用.
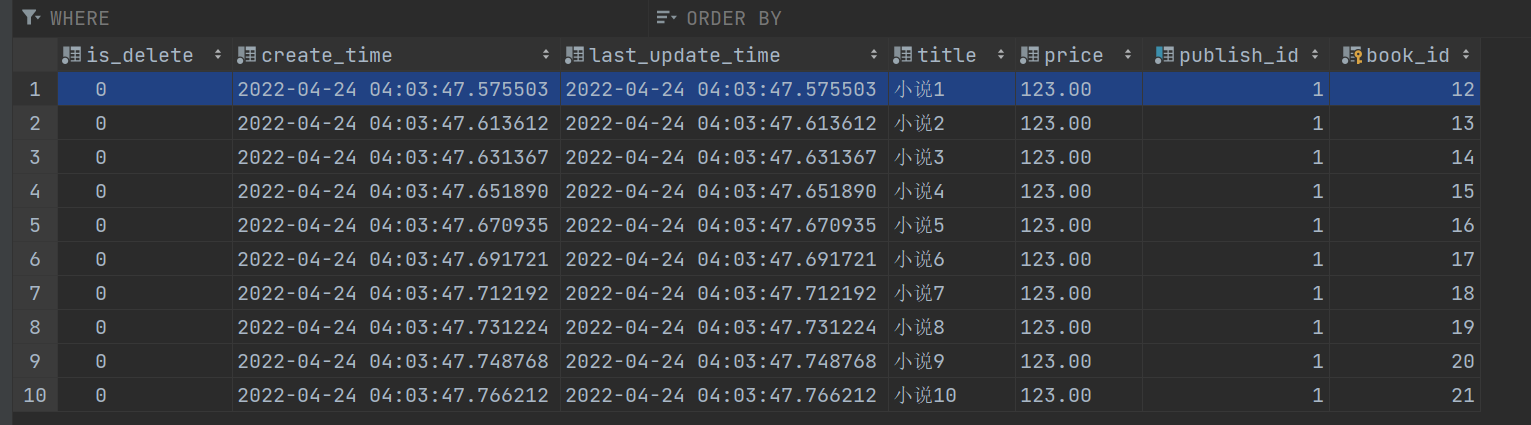
在数据库中写入10条数据
post请求: 127.0.0.1:8000/app01/api/books/
携带的json数据:
[
{
"title": "小说1",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说2",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说3",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说4",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说5",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说6",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说7",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说8",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说9",
"price": "123.00",
"publish": 1,
"author": [
1
]
},
{
"title": "小说10",
"price": "123.00",
"publish": 1,
"author": [
1
]
}
]
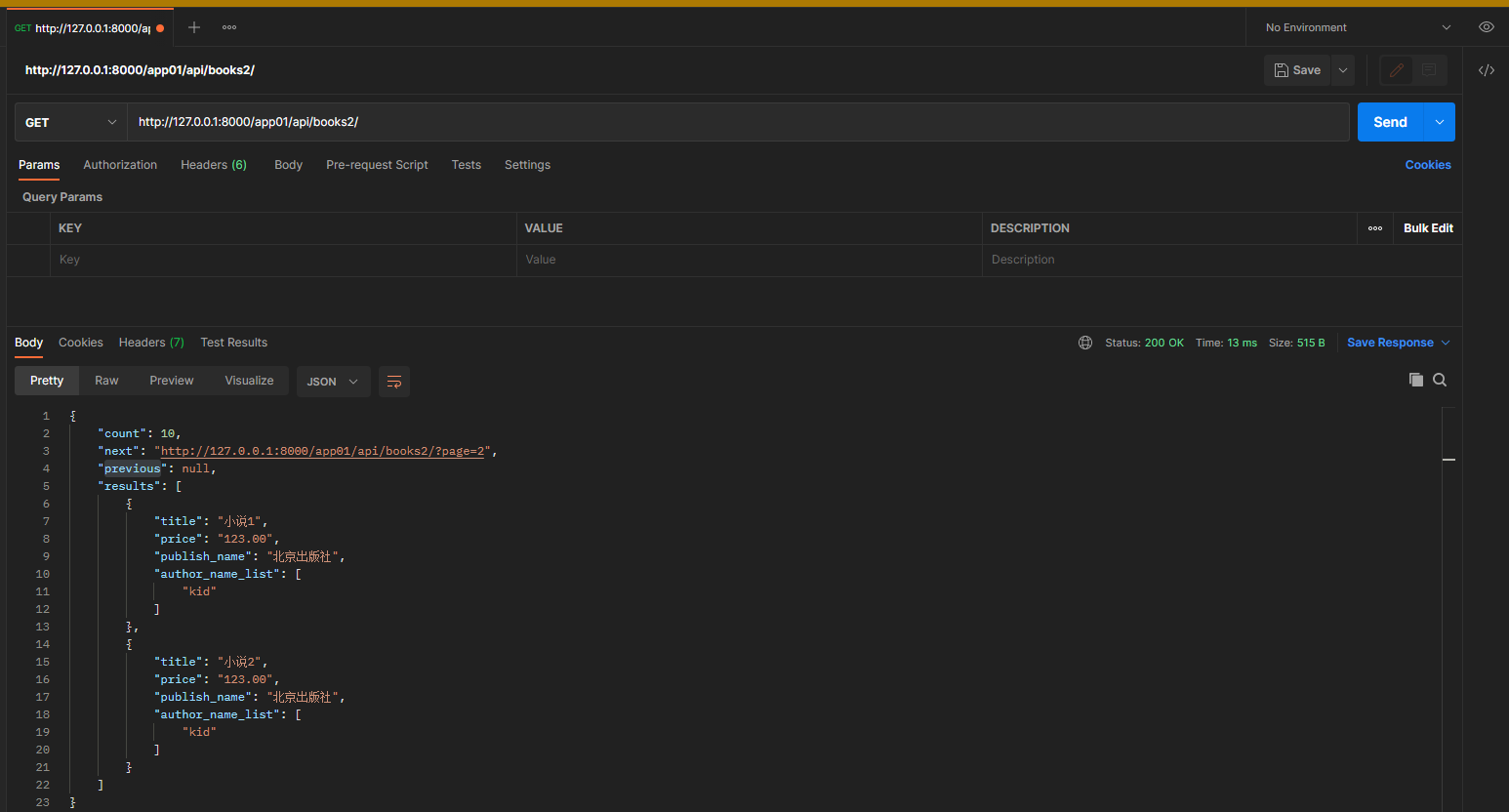
11.1 页码分页
DEFAULT_PAGINATION_CLASS 的默认值为无, 默认使用PageNumberPagination页面分页.
1. 全局配置
在项目配置文件中设置.
# DRF配置
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
# 每页展示的条数
'PAGE_SIZE': 2,
}
2. 局部配置
在需要设置页码的类中设置 pagination_class属性值.
# 导入ListAPIView
from rest_framework.generics import ListAPIView
# 带入分页器模块
from rest_framework.pagination import PageNumberPagination
# 定义一个ListAPIView
class BookListAPIView(ListAPIView):
queryset = models.Book.objects.all()
serializer_class = serializers.BookModelSerializer
# 分页器配置
pagination_class = PageNumberPagination
在项目配置文件中设置PAGE_SIZE属性.
# DRF配置
REST_FRAMEWORK = {
# 每页展示的条数
'PAGE_SIZE': 2,
}
3. 重新页码分页
继承PageNumberPagination类, 在该类中定义配置数据. 可以局部使用, 也可以全局使用.
参数:
page_size 每页的数目
page_query_param 页数关键字名, 默认为'page'
page_size_query_param 每页数目关键字, 默认为None
max_page_size 每页最大的显示条数
# 视图子类分页器路由
url('^books2/', views.BookListAPIView.as_view()),
# 定义一个ListAPIView
from rest_framework.generics import ListAPIView
from rest_framework.pagination import PageNumberPagination
class Pager(PageNumberPagination):
# 每页的条数
page_size = 2
# 查询的key
page_query_param = 'aa'
# 指定一个关键字, 前端指定的关键字获取页多少条数据 page_size的值就会失效
page_size_query_param = 'size'
# 每页最大的显示条数
max_page_size = 5
# 定义一个ListAPIView
class BookListAPIView(ListAPIView):
queryset = models.Book.objects.all()
serializer_class = serializers.BookModelSerializer
# 分页器配置
pagination_class = Pager
get请求: 127.0.0.1:8000/app01/api/books2/
每页的条数: page_size = 2
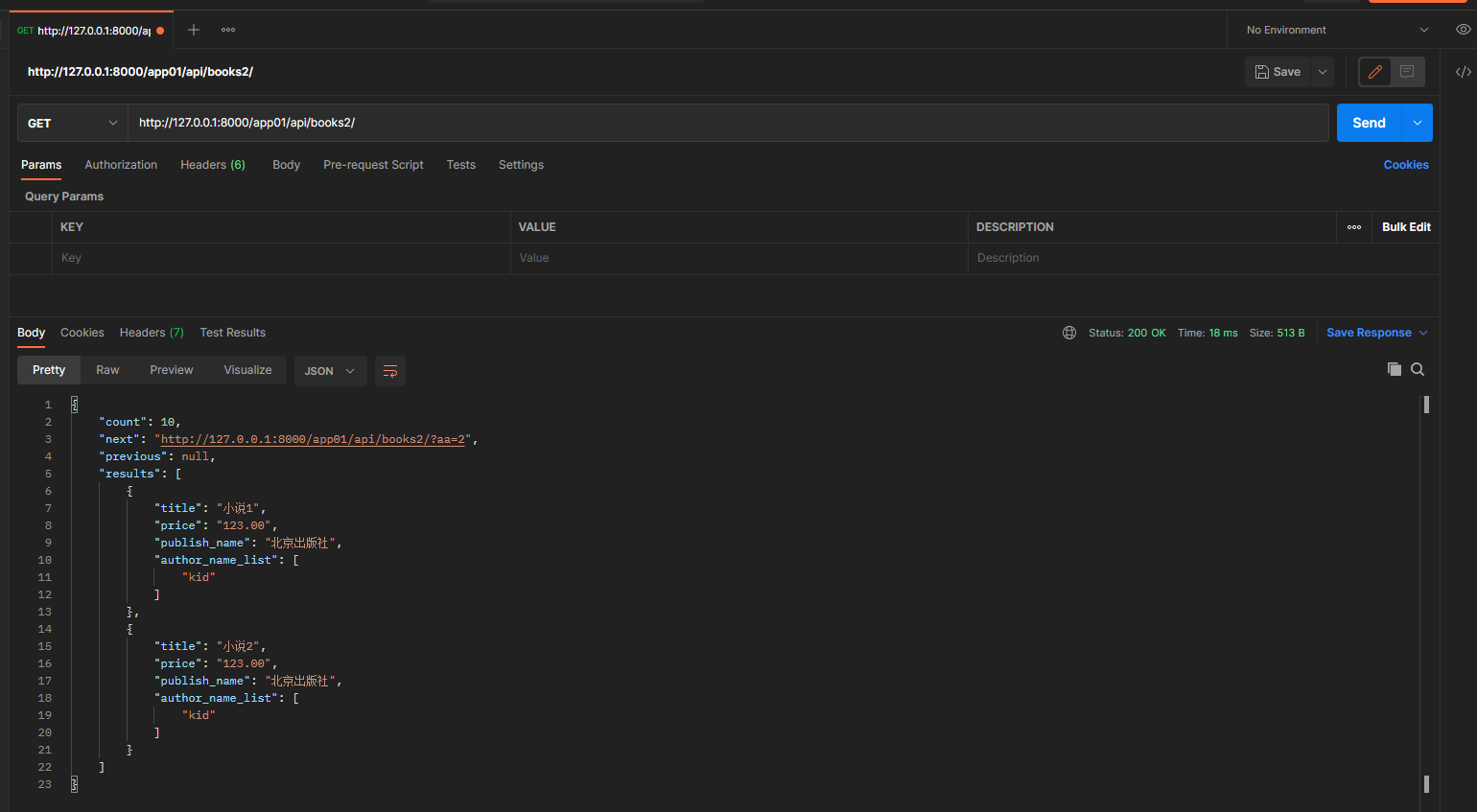
get请求: 127.0.0.1:8000/app01/api/books2/?size=3
每页的条数: size=3 ==> page_size = 3
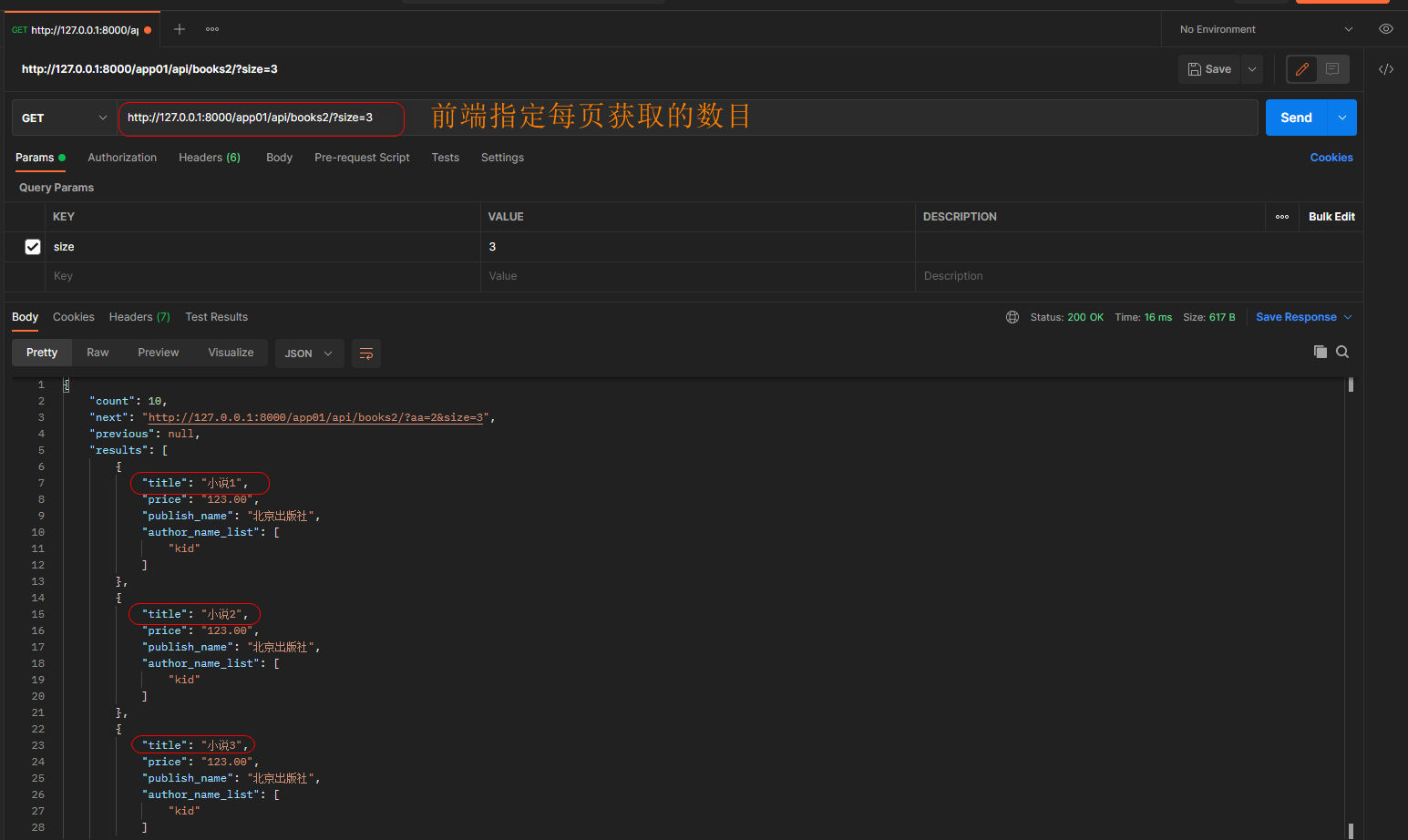
get请求: 127.0.0.1:8000/app01/api/books2/?size=10
限制每页最大的显示条数: max_page_size = 5
11.2 偏移分页
继承LimitOffsetPagination类, 在该类中定义配置数据. 可以局部使用, 也可以全局使用.
参数:
default_limit 每页的偏移数, 偏移一位获取一条数据.
milit_query_pagam 指定每页偏移的关键字, 默认为limit.
offset_query_pagam 指定起始位的关键字, 默认为offset.
max_milit 最大偏移的位数
default_limit自己没有定义使用的配置文件的PAGE_SIZE.
from rest_framework.pagination import LimitOffsetPagination
class Offset(LimitOffsetPagination):
# 每页显示3条数据
default_limit = 3
# 定义一个ListAPIView
class BookListAPIView(ListAPIView):
queryset = models.Book.objects.all()
serializer_class = serializers.BookModelSerializer
# 分页器配置
pagination_class = Offset
# 最偏移的位数
max_limit = 5
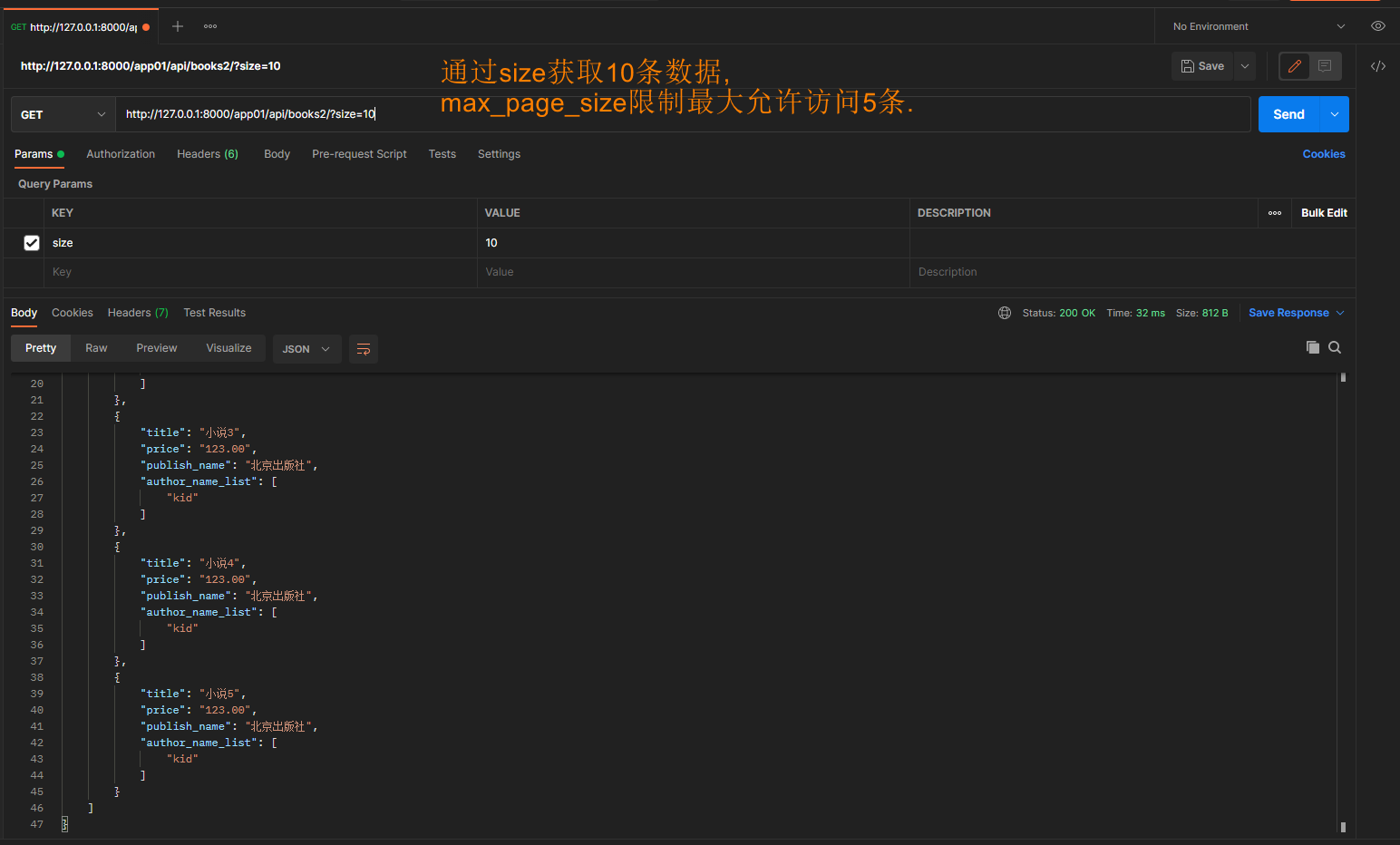
第一页 127.0.0.1:8000/app01/api/books2/?limit=3
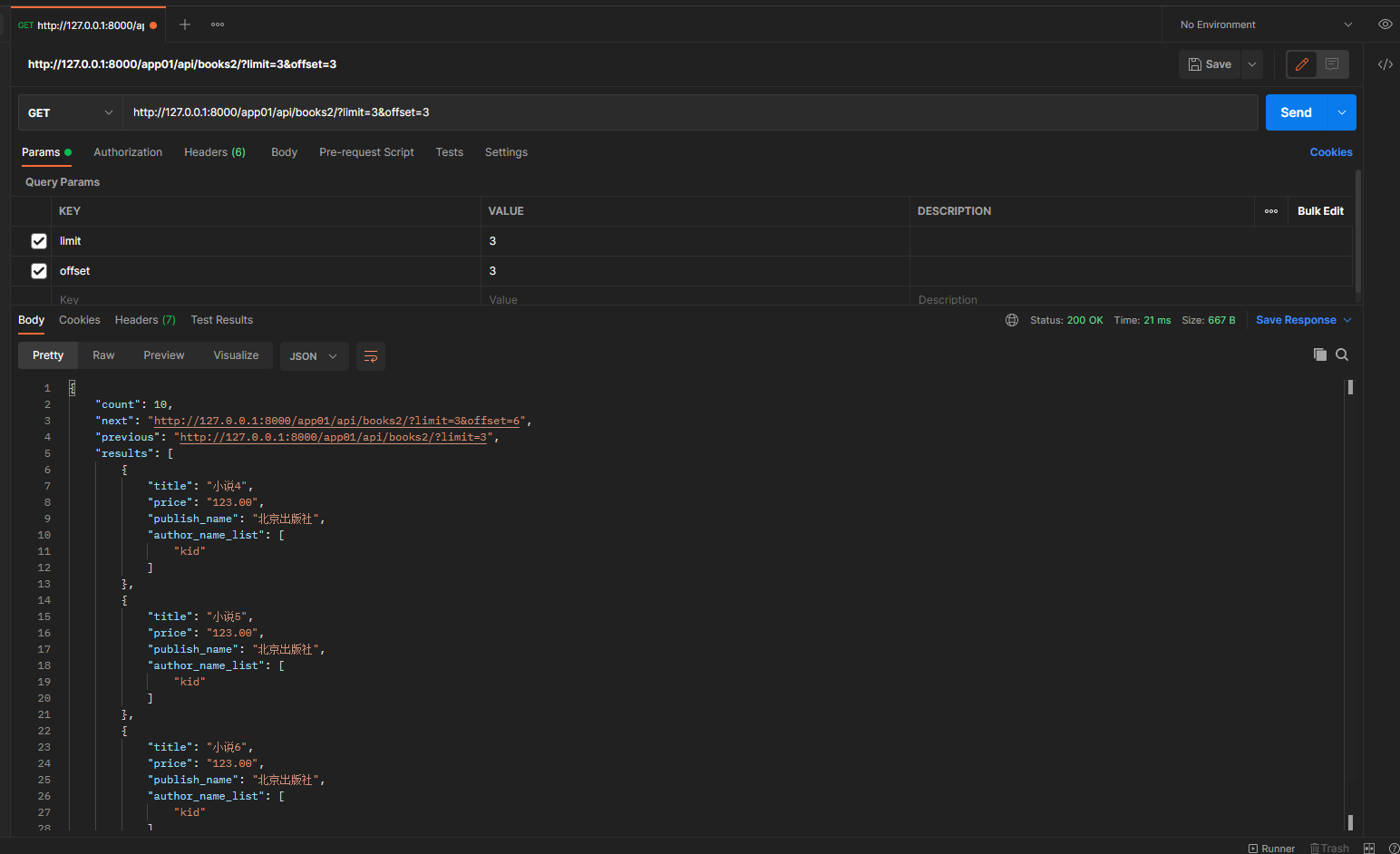
第二页 127.0.0.1:8000/app01/api/books2/?limit=3&offset=3 limit获取几条 offset 指定起始位
127.0.0.1:8000/app01/api/books2/?limit=3&offset=5
从第五条的后面开始向后面获取3条数据
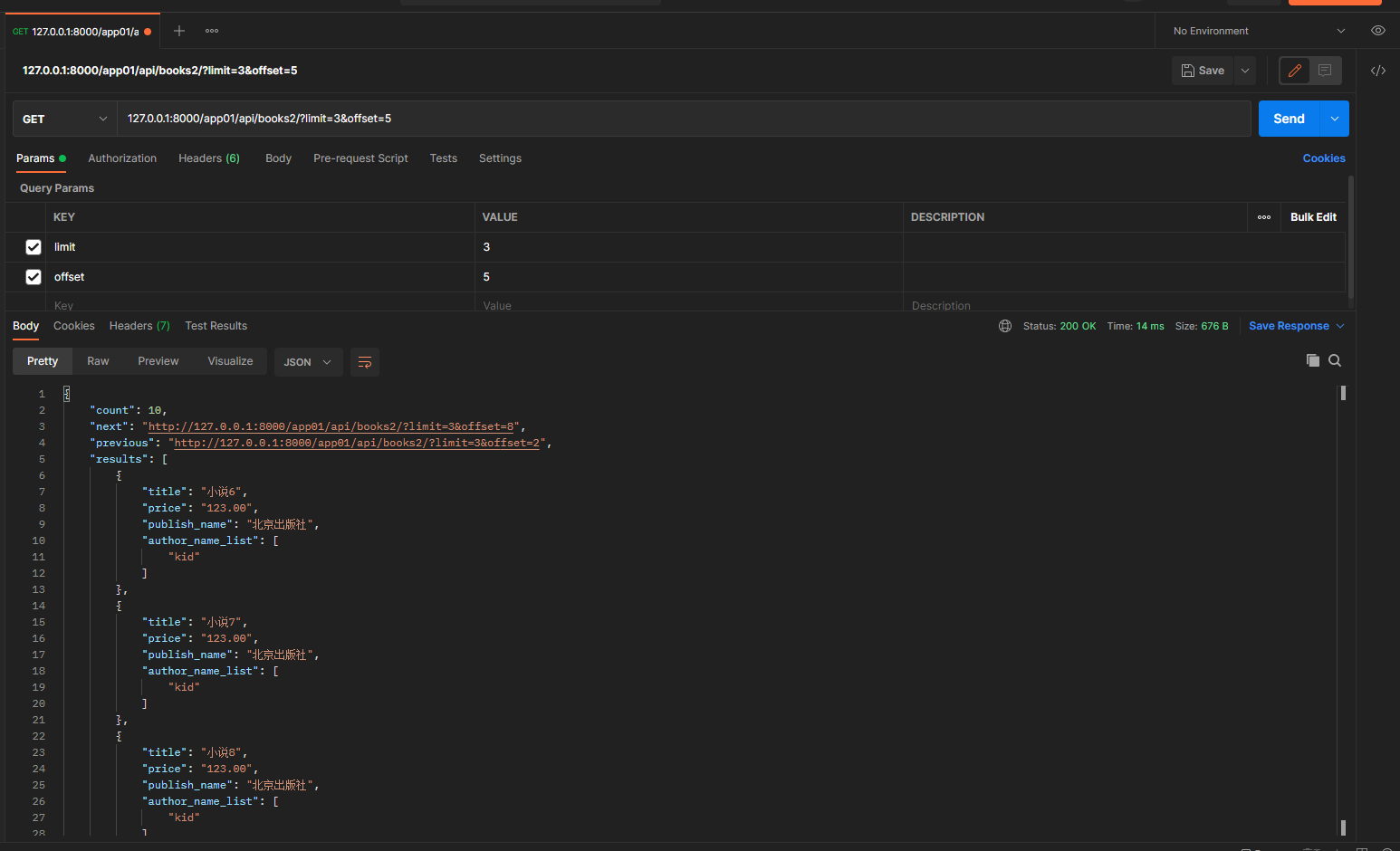
127.0.0.1:8000/app01/api/books2/?limit=30&offset=1
limit=30
max_limit = 5 限制 limit最大的值为5
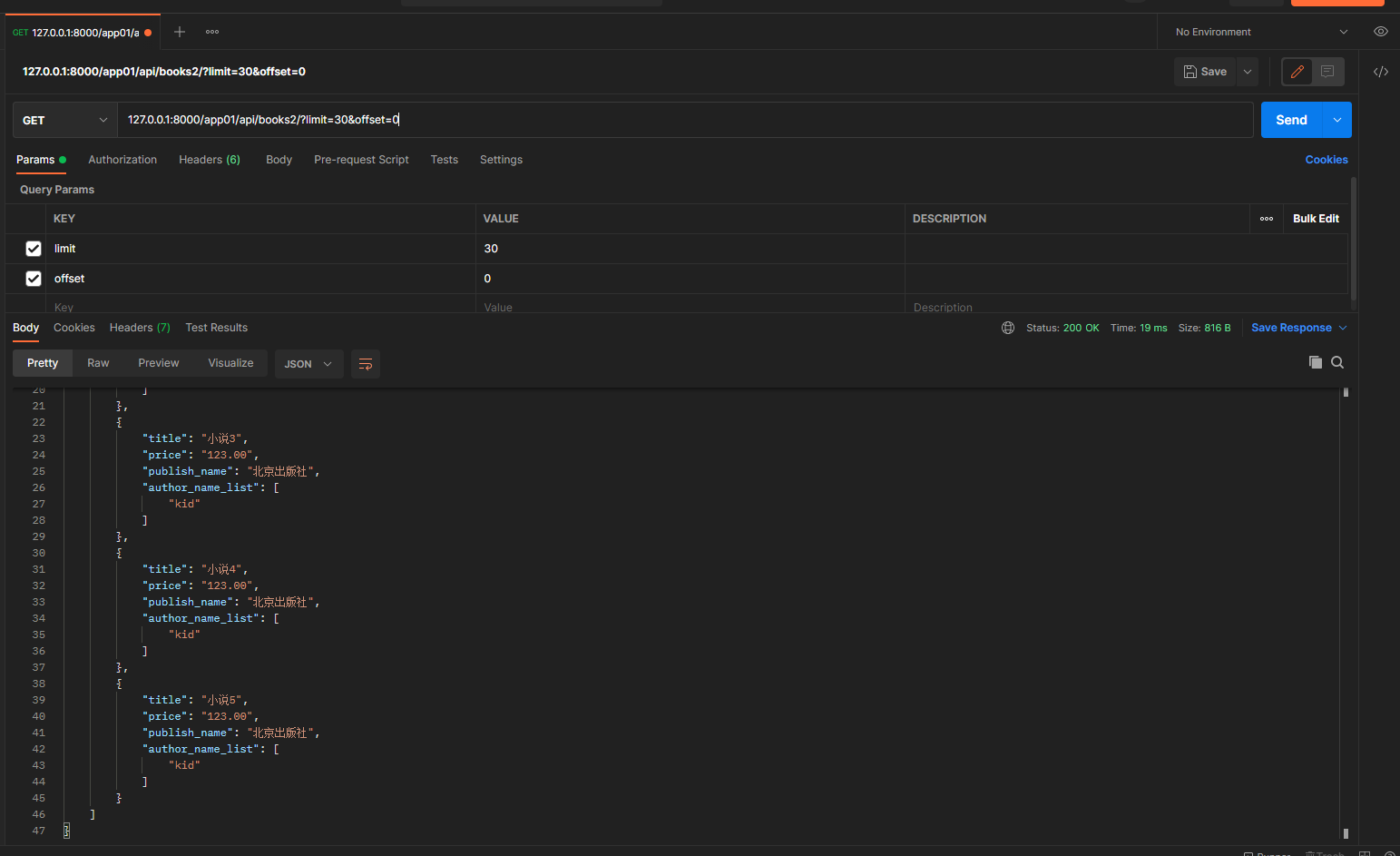
11.3 光标分页
前两种方法可以指定位置开始查, 查的时候需要将数据都读取,效率低. 光标分页只能点击上下翻页, 查询效率最高.
继承CursorPagination类, 在该类中定义配置数据. 可以局部使用, 也可以全局使用.
参数:
page_size: 每页展示的数目
cursor_query_param: 页码的关键字参数, 默认为 'cursor'
ordering: 排序中的字段, 默认 ordering = '-created', 以创建时间排序,
自己没有定义该属性会报错, 自己的表中没有改字段.
- 倒序, 在取值.
from rest_framework.pagination import CursorPagination
class Cursor(CursorPagination):
cursor_query_param = 'page'
page_size = 3
ordering = '-book_id'
# 定义一个ListAPIView
class BookListAPIView(ListAPIView):
queryset = models.Book.objects.all()
serializer_class = serializers.BookModelSerializer
# 分页器配置
pagination_class = Cursor
get请求 127.0.0.1:8000/app01/api/books2/
ordering = '-book_id' 指定排序字段为book_id, -为倒序, 倒序之后取数据.
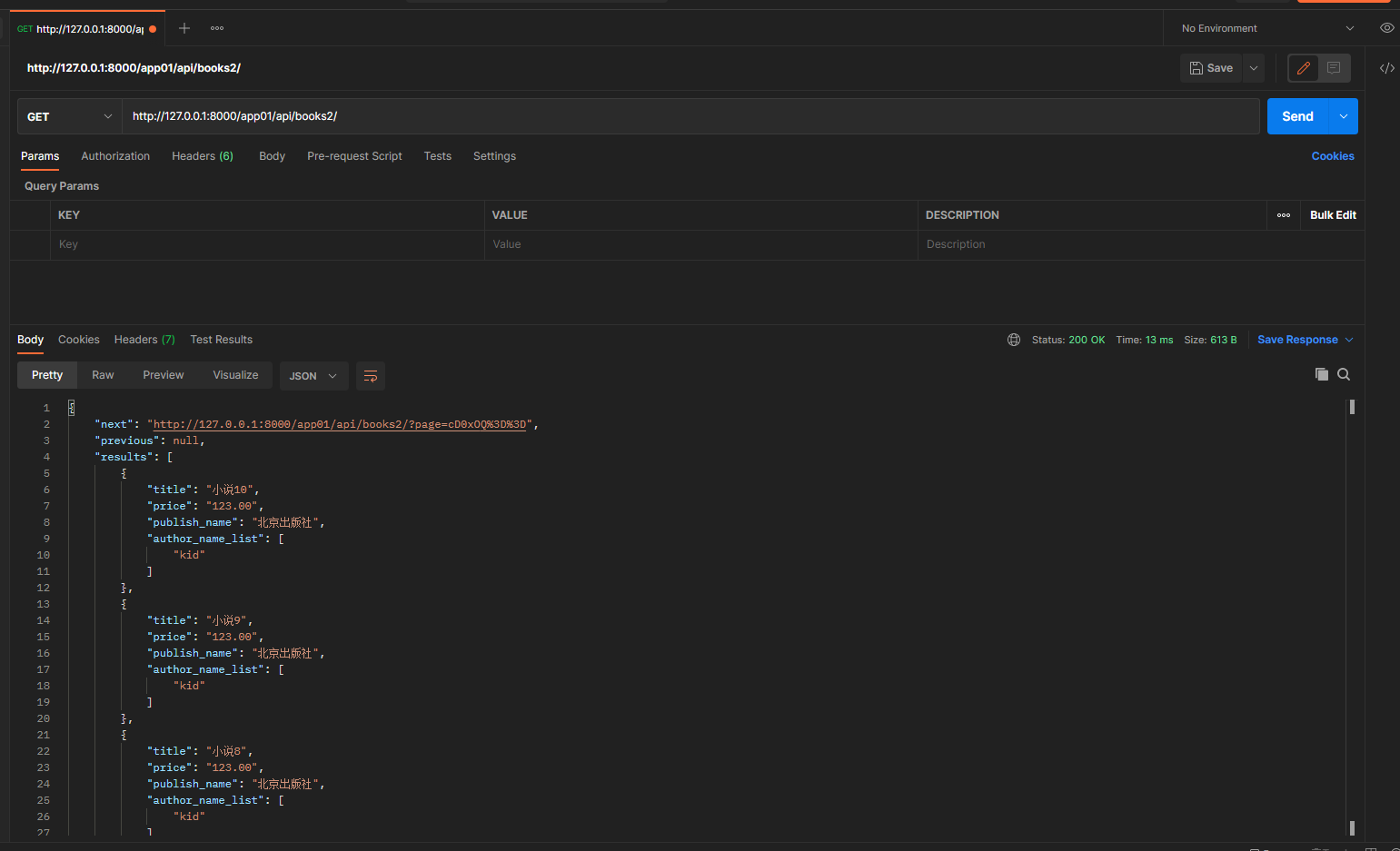
只能通过 next previous 翻页
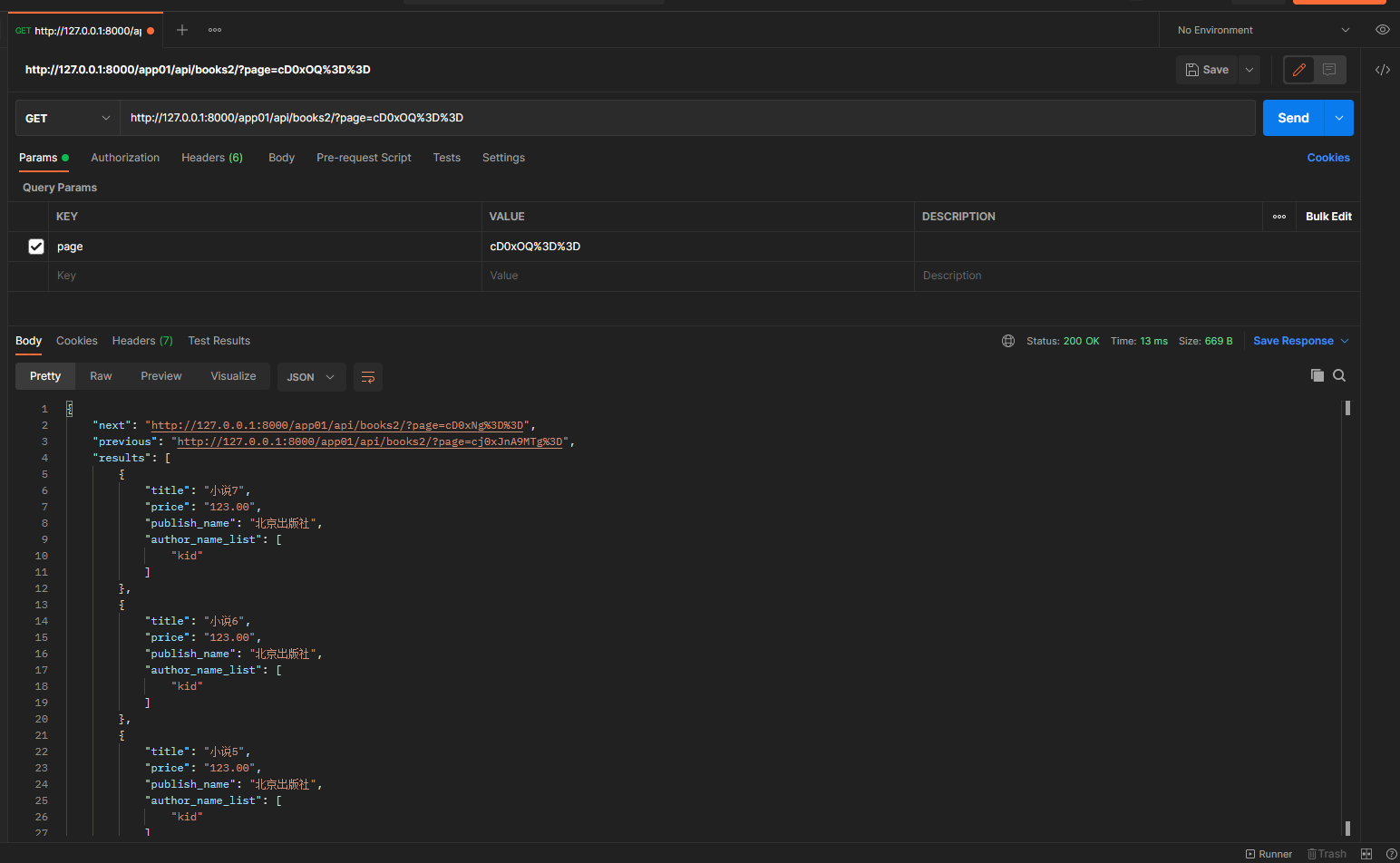
1.12 视图基类使用分页器
从基础视图类需要手定调用分类器的方法. 使用方法按要求传递参数.
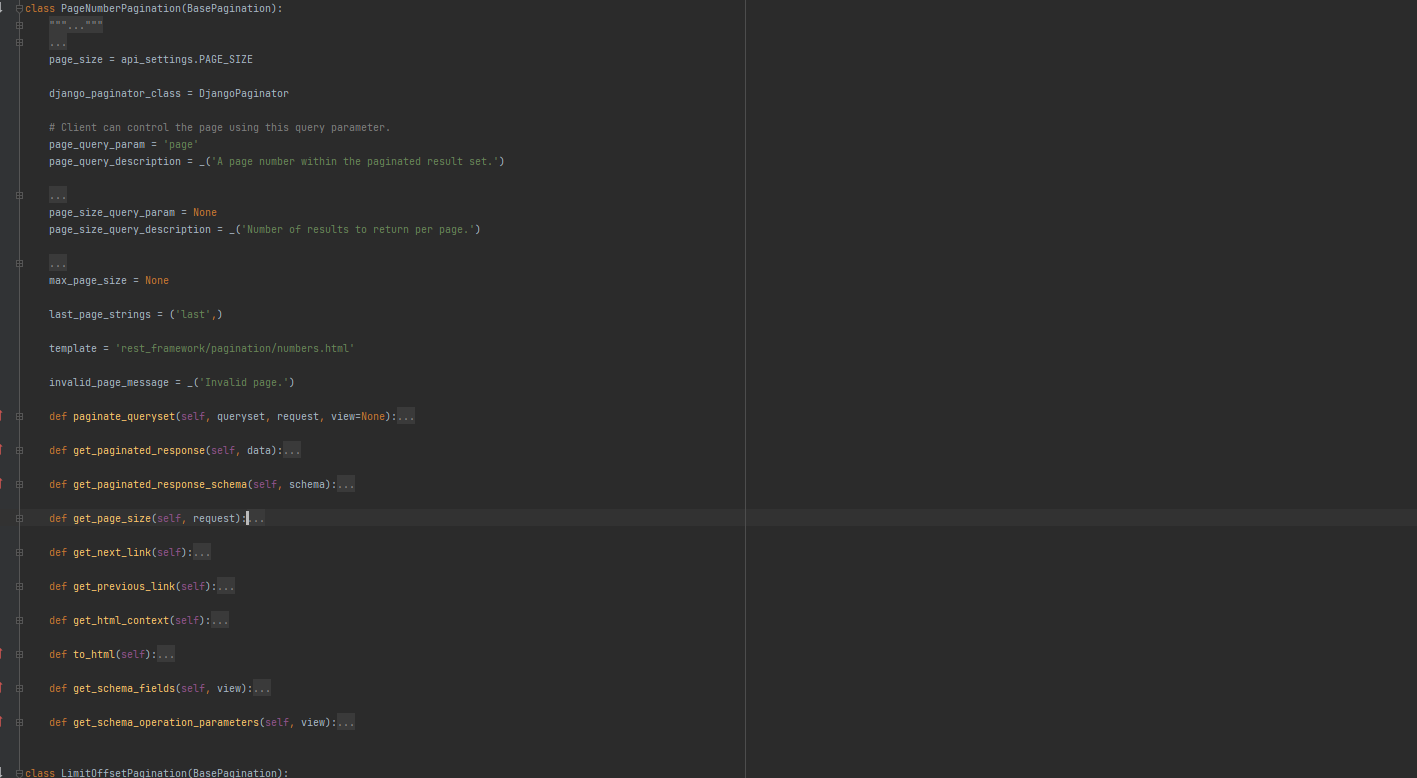
# 视图基类路由
url('^books3/', views.BookAPIView.as_view()),
from rest_framework.pagination import PageNumberPagination
class Pager(PageNumberPagination):
# 每页的条数
page_size = 2
# 查询的key
page_query_param = 'aa'
# 指定一个关键字, 前端指定的关键字获取页多少条数据 page_size的值就会失效
page_size_query_param = 'size'
# 每页最大的显示条数
max_page_size = 5
# 定义一个APIView类
from rest_framework.views import APIView
class BookAPIView(APIView):
def get(self, request):
# 获取数据对象
books_obj = models.Book.objects.all()
# 分页器对象
pager_obj = Pager()
# 使用方法 paginate_queryset 分器, (书籍对象, request对象, 视图类对象)
books_obj_list = pager_obj.paginate_queryset(books_obj, request, self)
# 序列化模型对象
books_dic = serializers.BookModelSerializer(instance=books_obj_list, many=True)
# 获取上下页码
next_link = pager_obj.get_next_link()
previous_link = pager_obj.get_previous_link()
# 将上下页码添加到页面中
page_link = {
'next_link': next_link, 'previous_link': previous_link}
print(books_dic.data)
# 将数据放回
return CustomResponse(data=books_dic.data, page=page_link)
先对数据划分, 在对序列化数据. 上下页码通过自定义的Response组织放回.
get请求: 127.0.0.1:8000/app01/api/books3/?aa=2
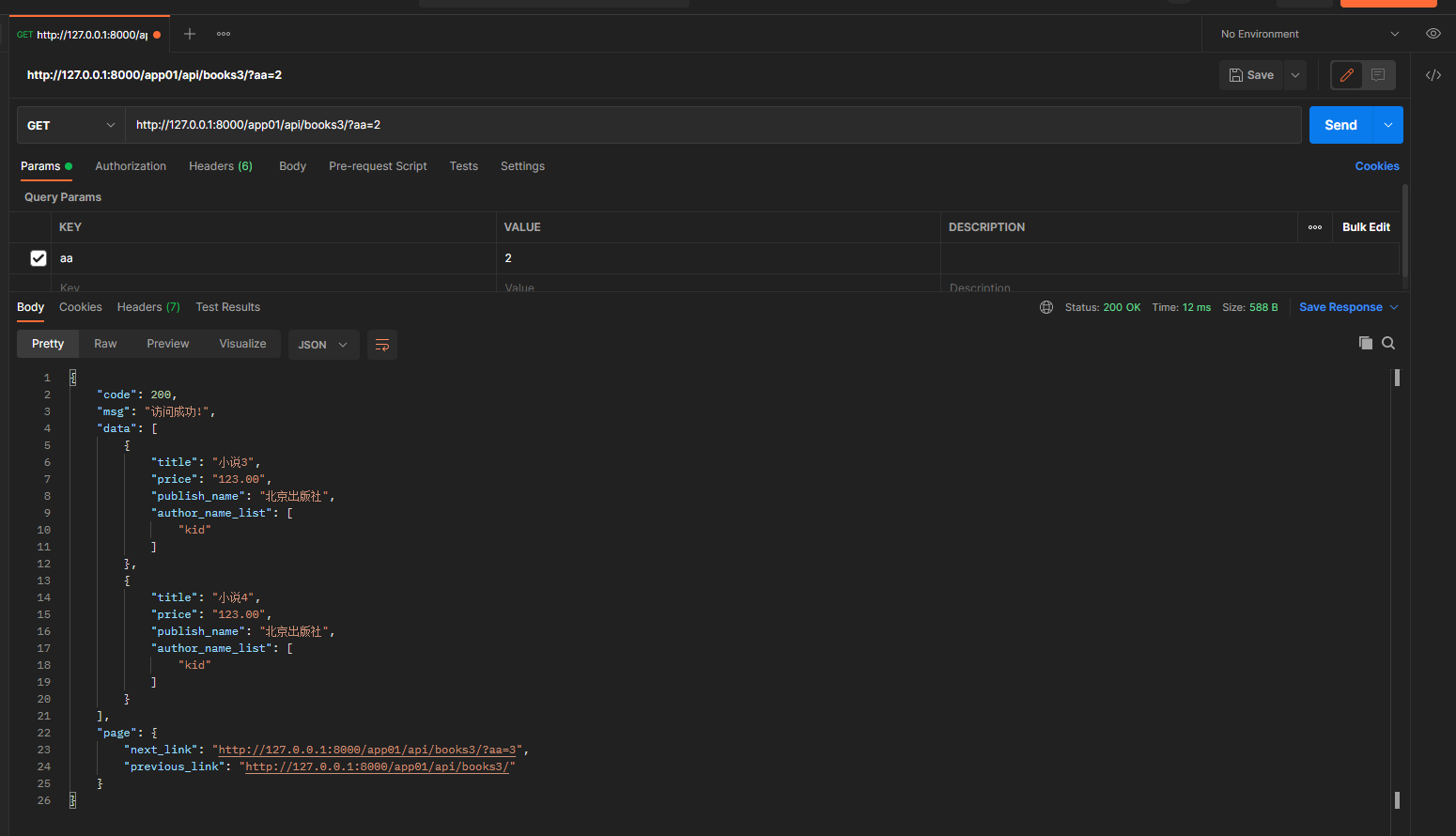
2. 多序列化练习
1. 继承AbstractUser自定义UserInfo表,
新增mobile_phone 手机号码字段, 唯一约束,
新增icon用户头像字段, 设置默认头像.
2. 使用视图集GenericViewSet + 视图拓展类RetrieveModeMixin + 模型序列化器完成User表新增数据接口
GenericViewSet: 继承ViewSetMixin和GenericAPIView
CreateModelMixin: 创建数据模块, 内置create方法.
ViewSetMixin: 重写的view函数内存地址, view函数中遍历actions字段, 为请求绑定方法.
3. 使用视图集GenericViewSet + 数图拓展类RetrieveModekMixin + 模型序列化器完成User表的查询接口
4. 使用视图集GenericViewSet + UpdateModelMixin + 模型序列化器完成User表修改头像的接口
2.1 准备环境
* 1. 新建项目

* 2. 本地化设置
# DRF_test2/settings.py
# 中文简体
LANGUAGE_CODE = 'zh-hans'
# 时区 亚洲上海
TIME_ZONE = 'Asia/shanghai'
USE_I18N = True
USE_L10N = True
# UTC时间关闭
USE_TZ = False
* 3. 继承AbstractUser内置用户表, 创建UserInfo表模型
# api/models.py
from django.db import models
# Create your models here.
# 导入 AbstractUser
from django.contrib.auth.models import AbstractUser
# 定义用户表
class UserInfo(AbstractUser):
# 新增手机号码字段, 字段信息唯一
mobile_phone = models.CharField(max_length=11, unique=True, verbose_name='手机号码')
# 头像, upload_to指定文件存放的位置, default设置默认头像
icon = models.ImageField(upload_to='icon', default='default.png', verbose_name='头像')

创基media媒体文件夹, 存放一张default.png 默认头像
配置使用的User表
# DRF_test2/settings.py
# 指定使用的User表, app应用名.表名
AUTH_USER_MODEL = 'api.UserInfo'
* 4. 配置媒体文件夹
1. 项目目录下新建media文件夹
2. 项目配置文件中配置媒体文件夹
# DRF_test2/settings.py
# 媒体文件夹
MEDIA_URL = '/media/'
# 媒体文件夹绝对路径
MEDIA_ROOT = Path(BASE_DIR, 'media')
* 5. 生成用户信息表
1. 生成表操作记录 python manage.py makemigrations
2. 数据集迁移 python manage.py migrate
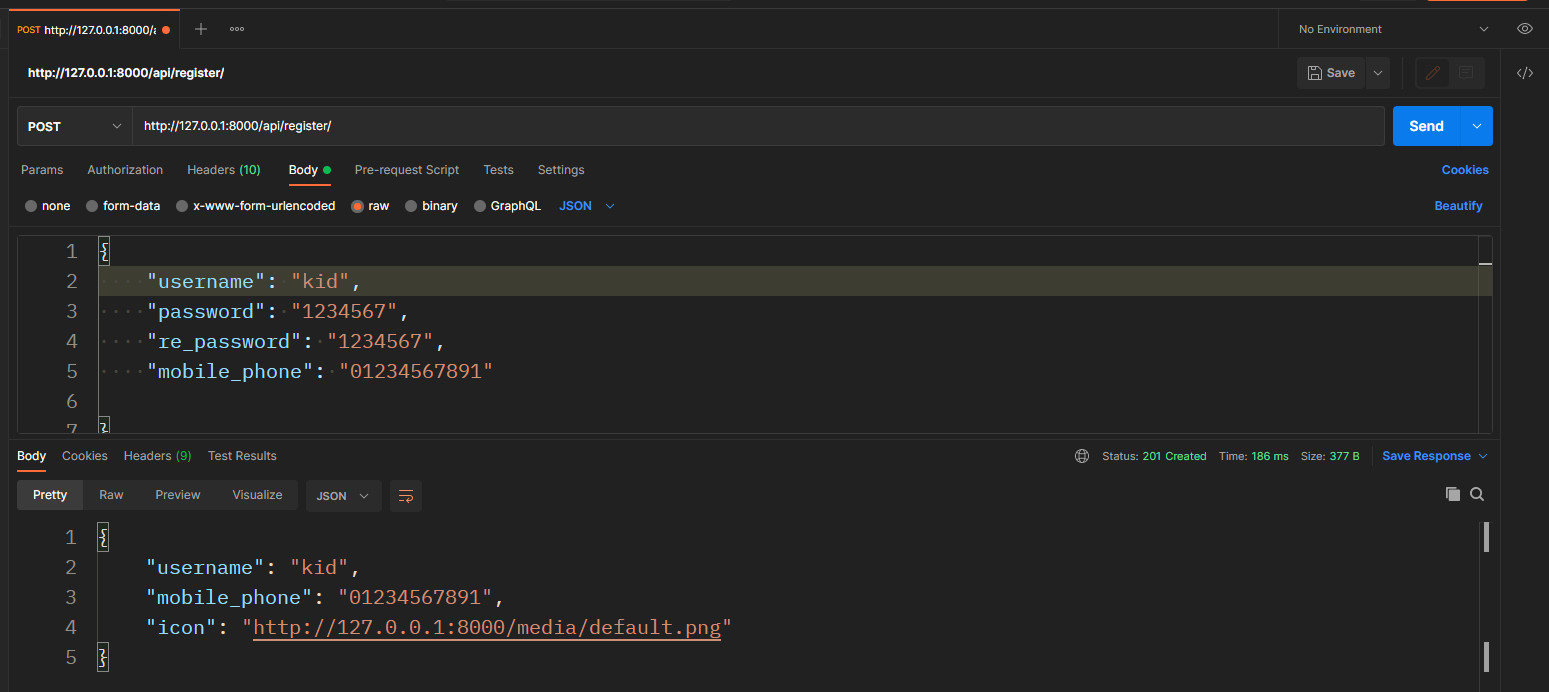
2.2 创建用户
使用视图集GenericViewSet + 视图拓展类RetrieveModeMixin + 模型序列化器完成User表新增数据接口
GenericViewSet: 继承ViewSetMixin和GenericAPIView
CreateModelMixin: 创建数据模块, 内置create方法.
ViewSetMixin: 重写的view函数内存地址, view函数中遍历actions字段, 为请求绑定方法.
* 1. 继承ViewSetMixin后可以自定生成路由
# 总路由
from django.contrib import admin
# 导入模块
from django.urls import path, re_path, include
# 子路由
from api import urls
urlpatterns = [
path('admin/', admin.site.urls),
re_path('^api/', include(urls))
]
# 子路由, api文件夹中新建urls.py文件
from django.urls import re_path, include
from api import views
# 导入自动生成路由模块
from rest_framework.routers import SimpleRouter
# 生成对象
router = SimpleRouter()
# 生成路由
router.register('register', views.RegisterAPI)
# 路由列表
urlpatterns = [
re_path('', include(router.urls))
]
* 2. 创建用户视图类
# 注册api
# 导入通用视图集
from rest_framework.viewsets import GenericViewSet
# 导入视图拓展类
from rest_framework.mixins import CreateModelMixin
# 导入模型层
from api import models
# 导入模型序列化器
from utils import serializers
class RegisterAPI(GenericViewSet, CreateModelMixin):
# 获取表数据
queryset = models.UserInfo.objects.all()
# 定义使用的模型序列化器
serializer_class = serializers.UserModelSerializer
* 4. 定义模型序列化器, 钩子函数与META类同级, 否则钩子函数失效!!!
# 定义模型序列化器
from rest_framework import serializers
# 导入模型层
from api import models
# 导入异常模块
from rest_framework.exceptions import ValidationError
# 定义用户模型序列化器
class UserModelSerializer(serializers.ModelSerializer):
# 定义二次密码 required改字段必填, 最短6 最长12, 字段不存在必须设置为只写
re_password = serializers.CharField(
required=True, min_length=6, max_length=12, write_only=True, )
# 定义Meta类
class Meta:
# 使用的表模型
model = models.UserInfo
# 需要序列化的字段
fields = ['username', 'password', 're_password', 'mobile_phone', 'icon']
extra_kwargs = {
'password': {
'write_only': True, 'min_length': 6, 'max_length': 12}}
# 局部钩子 判断手机号码是否是11位, 不是11位直接抛出异常
def validate_mobile_phone(self, data):
if len(data) != 11:
raise ValidationError('手机号码必须是11位!')
# 将值返回
return data
# 全局钩子 检验两次密码是否一致
def validate(self, attrs):
if attrs.get('password') == attrs.get('re_password'):
# 将所有的值返回
return attrs
raise ValidationError('两次密码不一致!')
# 自己定义create方法, 如果使用ModelSerializer模型序列化类的create的方法创建的用户则是明文的
def create(self, validated_data):
# re_password是不存在的, 需要将该值pop掉
validated_data.pop('re_password')
# 将用户对象返回
user_obj = models.UserInfo.objects.create_user(**validated_data)
return user_obj
* 5. 将rest_framework 添加到app应用类别中
INSTALLED_APPS = [
...
'rest_framework'
]
* 6. 开发图片访问路径, 在主路由中配置
from django.contrib import admin
from django.urls import path, re_path, include
from api import urls
# 导入访问媒体资源视图类
from django.conf import settings
from django.views.static import serve
urlpatterns = [
path('admin/', admin.site.urls),
# 主路由
re_path('^media/(?P<path>.*)', serve, {
'document_root': settings.MEDIA_ROOT}),
# 图片访问
re_path('^api/', include(urls))
]
get请求: http://127.0.0.1:8000/media/default.png
serve是内置的视图类
def serve(request, path, document_root=None, show_indexes=False):
第一个参数request 会自动传入, path是通过有名分组获取的, document_root文档的根路径.
show_indexes 显示索引可以不开启
re_path('^media/(?P<path>.*)', serve, {
'document_root': settings.MEDIA_ROOT}),
from django.conf import settings
from 项目 import settings
这两个方式都可以获取到settings.py的信息
项目的settings.py 是为开始者提供的配置, 配置少. (不推荐使用)
直接查找项目的settings.py数据
conf的settings.py 存放程序的默认配置, 配置多. (推荐使用)
执行顺序: 同一个配置优先使用项目的settings.py 中的设置, 没有配置在使用conf的settings.py 的.
在项目的settings.py中写的配置覆盖conf的settings.py 的配置.
2.3 查询信息
在视图类中使用拓展类RetrieveModelMixin + 另一个模型序列化器完成User表查询接口
直接为数图类添加继承RetrieveModelMixin类, 便拥有了通过主键访问数据的API接口.
主要是新增数据使用一个模型序列化器, 查询数据使用另一个序列化请求.
* 1. 定义一个模型序列化器
# 获取信息模型序列化器
class RetrieveModelSerializer(serializers.ModelSerializer):
# 定义META类
class Meta:
model = models.UserInfo
# 排除密码字段的转换, 其他的字段全部转换
exclude = ['password', ]
* 2. 在视图类中定义 get_serializer_class 方法,
继承了ViewSetMixin的类使用自动生成路由, view函数中遍历actions字段, 为请求绑定方法.
在get_serializer_class 方法中判断请求绑定的方法, 返回不同的模型序列化.
self.action 在经过
def dispatch(self, request, *args, **kwargs):
...
request = self.initialize_request(request, *args, **kwargs)
之后self.action 便有了请求绑定的方法名字
# 注册api
# 导入通用视图集
from rest_framework.viewsets import GenericViewSet
# 导入视图拓展类
from rest_framework.mixins import CreateModelMixin, RetrieveModelMixin
# 导入模型层
from api import models
# 导入模型序列化器
from utils import serializers
class RegisterAPI(GenericViewSet, CreateModelMixin, RetrieveModelMixin):
# 获取表数据
queryset = models.UserInfo.objects.all()
# 定义使用的模型序列化器
def get_serializer_class(self):
print(self.action)
# 创建数据
if self.action == 'create':
return serializers.UserModelSerializer
# 通过主键查询数据
if self.action == 'retrieve':
return serializers.RetrieveModelSerializer
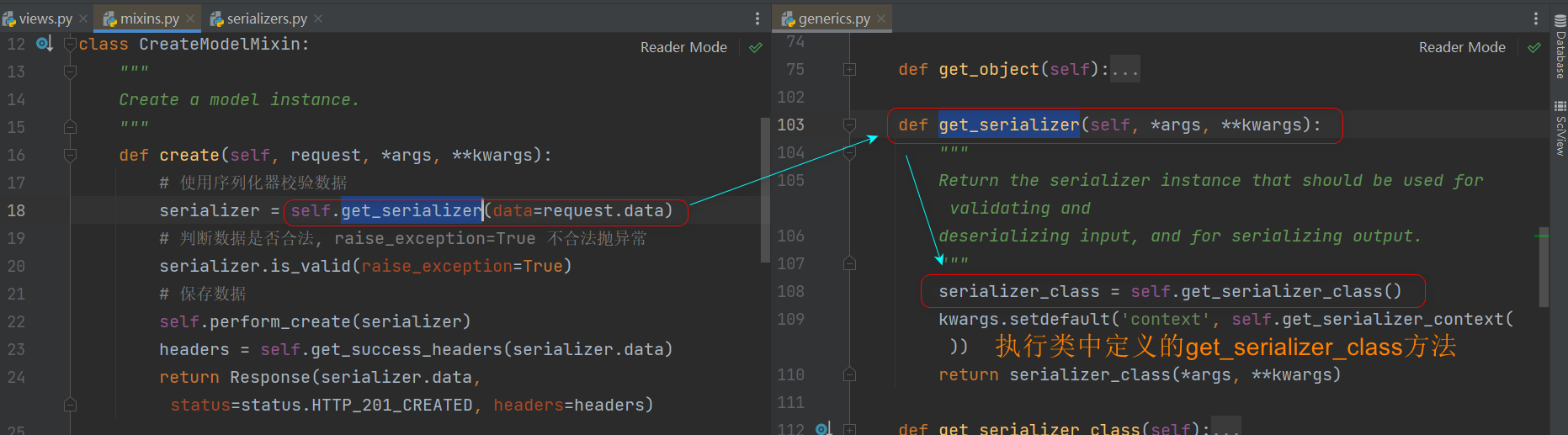
内置的get_serializer_class是直接返回 类中定义serializer_class属性
在类中自定义get_serializer_class, 通过对应的请求, 返回不同的序列化器.
2.4 修改头像
为视图类添加UpdateModelMixin类, + 另一个模型序列化器完成User表修改头像的接口.
# 注册api
# 导入通用视图集
from rest_framework.viewsets import GenericViewSet
# 导入视图拓展类
from rest_framework.mixins import CreateModelMixin, RetrieveModelMixin, UpdateModelMixin
# 导入模型层
from api import models
# 导入模型序列化器
from utils import serializers
class RegisterAPI(GenericViewSet, CreateModelMixin, RetrieveModelMixin, UpdateModelMixin):
# 获取表数据
queryset = models.UserInfo.objects.all()
# 定义使用的模型序列化器
def get_serializer_class(self):
print(self.action)
# 创建数据
if self.action == 'create':
return serializers.UserModelSerializer
# 通过主键查询数据
if self.action == 'retrieve':
return serializers.RetrieveModelSerializer
# 通过主键修改用户头像
if self.action == 'update':
return serializers.UpdateModelSerializer
# 定义模型序列化器
class UpdateModelSerializer(serializers.ModelSerializer):
# 定义META类
class Meta:
model = models.UserInfo
fields = ['icon']
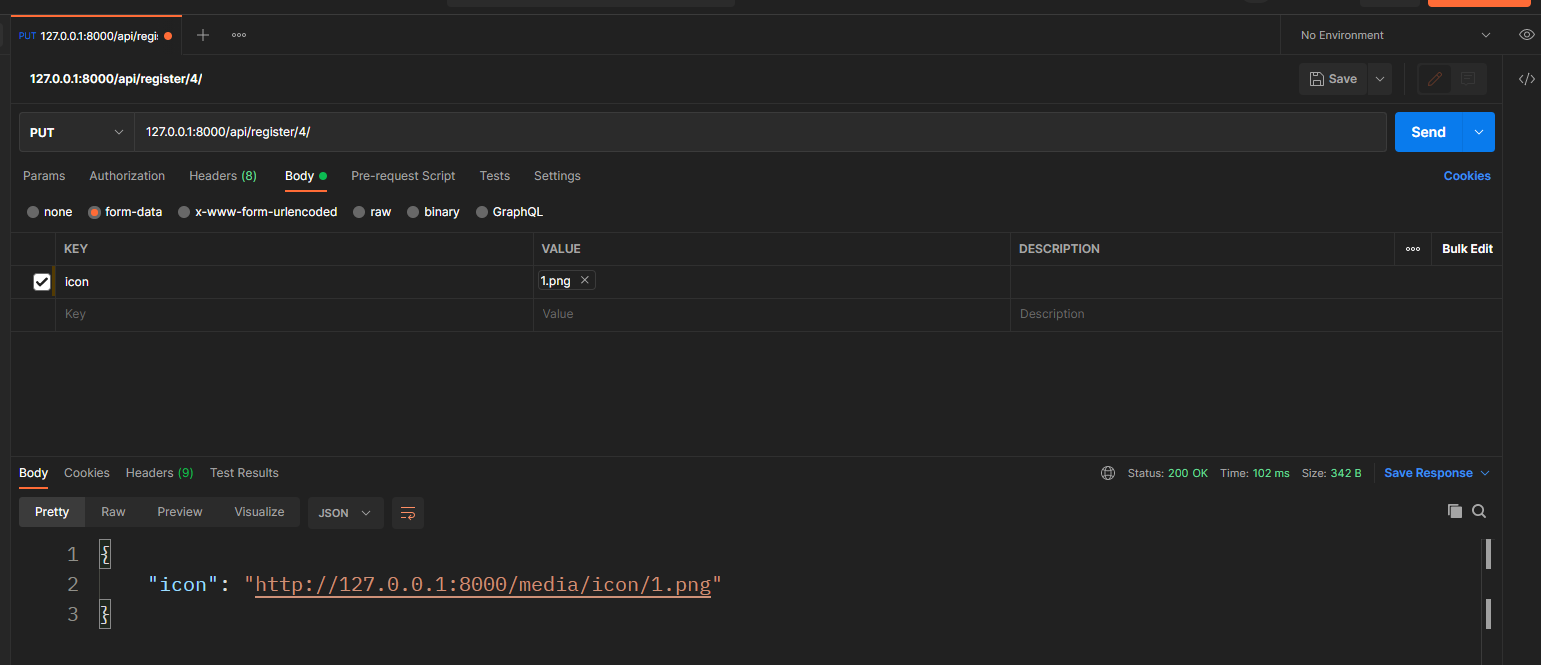
PUT请求: 127.0.0.1:8000/api/register/4/
上传文件选择form-dat, 键为字段的中设置的upload_to值'icon'.