
C语言零基础入门级 联合类型+预处理+文件组织
- 【1】C语言-》结构体基本概念
- 【2】C语言-》结构体初始化
- 【3】C语言-》结构体成员引用
- 【4】C语言-》结构体指针与数组
- 【5】C语言-》CPU字长
- 【6】C语言-》地址对齐
- 【7】C语言-》普通变量的m值
- 【8】C语言-》结构体的M值
- 【9】C语言-》联合体基本概念
- 【10】C语言-》联合体操作
- 【11】 C语言-》枚举
- 【12】C语言-》预处理
- 【13】C语言-》宏的概念
- 【14】C语言-》无参宏
- 【15】 C语言-》带参宏
- 【16】C语言-》带参宏的副作用
- 【17】C语言-》无值宏定义
- 【18】C语言-》条件编译
- 【19】 C语言-》条件编译的使用场景
- 【20】 C语言-》头文件的作用
- 【21】 C语言-》头文件的内容extern 关键字
- 【22】 C语言-》头文件的使用
- 【23】 C语言-》头文件的格式
- 【24】 C语言-》面试题
【1】C语言-》结构体基本概念
C语言提供了众多的基本类型,但现实生活中的对象一般都不是单纯的整型、浮点型或字符串,而是这些基本类型的综合体。比如一个学生,典型地应该拥有学号(整型)、姓名(字符串)、分数(浮点型)、性别(枚举)等不同侧面的属性,这些所有的属性都不应该被拆分开来,而是应该组成一个整体,代表一个完整的学生。
在C语言中,可以使用`结构体`来将多种不同的数据类型组装起来,
形成某种现实意义的自定义的变量类型。结构体本质上是一种自定义类型。
结构体的定义:
struct 结构体标签
{
成员1;
成员2;
...
};
语法:
结构体标签,用来区分各个不同的结构体。
成员,是包含在结构体内部的数据,可以是任意的数据类型。
示例:
// 定义了一种称为 struct node 的结构体类型
struct node
{
int a;
char b;
double c;
};
int main()
{
// 定义结构体变量
struct node n;//分配栈空间
}
【2】C语言-》结构体初始化
结构体跟普通变量一样,涉及定义、初始化、赋值、取址、传值等等操作,这些操作绝大部分都跟普通变量别无二致,只有少数操作有些特殊性。这其实也是结构体这种组合类型的设计初衷,就是让开发者用起来比较顺手,不跟普通变量产生太多差异。
结构体的定义和初始化
由于结构体内部拥有多个不同类型的成员,因此初始化采用与数组类似的列表方式。
结构体的初始化有两种方式:①普通初始化;②指定成员初始化。
为了能适应结构体类型的升级迭代,一般建议采用指定成员初始化。
示例:
// 1,普通初始化
struct node n = {
100, 'x', 3.14};
// 2,指定成员初始化
struct node n = {
.a = 100, // 此处,小圆点.被称为成员引用符
.b = 'x',
.c = 3.14
}
指定成员初始化的好处:
[1]成员初始化的次序可以改变。
[2]可以初始化一部分成员。
[3]结构体新增了成员之后初始化语句仍然可用。
【3】C语言-》结构体成员引用
结构体相当于一个集合,内部包含了众多成员,每个成员实际上都是独立的变量,都可以被独立地引用。引用结构体成员非常简单,只需要使用一个成员引用符即可:
结构体.成员
示例:
n.a = 200;
n.b = 'y';
n.c = 2.22;
printf("%d, %c, %lf\n", n.a, n.b, b.c);
【4】C语言-》结构体指针与数组
跟普通变量别无二致,可以定义指向结构体的指针,也可以定义结构体数组。
结构体指针:
struct node n = {
100, 'x', 3.14};
struct node *p = &n;
// 以下语句都是等价的
printf("%d\n", n.a);
printf("%d\n", (*p).a);
printf("%d\n", p->a); // 箭头 -> 是结构体指针的成员引用符
结构体数组:
struct node s[5];
s[0].a = 300;
s[0].b = 'z';
s[0].c = 3.45;
【5】C语言-》CPU字长
字长的概念指的是处理器在一条指令中的数据处理能力,当然这个能力还需要搭配操作系统的设定,比如常见的32位系统、64位系统,指的是在此系统环境下,处理器一次存储处理的数据可以达32位或64位。
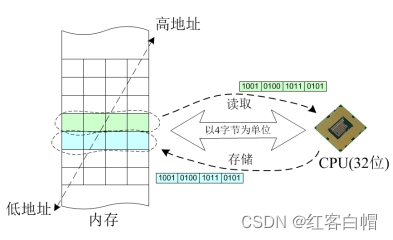
【6】C语言-》地址对齐
CPU字长确定之后,相当于明确了系统每次存取内存数据时的边界,以32位系统为例,
32位意味着CPU每次存取都以4字节为边界,因此每4字节可以认为是CPU存取内存数据的一个单元。如果存取的数据刚好落在所需单元数之内,那么我们就说这个
数据的地址是对齐的,如果存取的数据跨越了边界,使用了超过所需单元的字节,那么我们就说这个数据的地址是未对齐的。
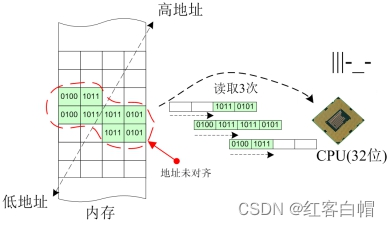
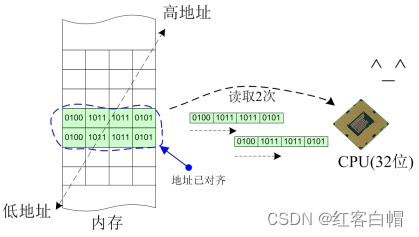
从图中可以明显看出,数据本身占据了
8个字节,在地址未对齐的情况下,CPU需要分3次才能完整地存取完这个数据,但是在地址对齐的情况下,CPU可以分2次就能完整地存取这个数据。
`总结:`
如果一个数据满足以最小单元数存放在内存中,则称它地址是对齐的,
否则是未对齐的。地址对齐的含义用大白话说就是1个单元能塞得下的就不用2个;2个单元能塞得下的就不用3个。
`如果发生数据地址未对齐的情况,有些系统会直接罢工,有些系统则降低性能。`
【7】C语言-》普通变量的m值
以32位系统为例,由于CPU存取数据总是以4字节为单元,因此对于一个尺寸固定的数据而言,当它的地址满足某个数的整数倍时,就可以保证地址对齐。这个数就被称为变量的
m值。
根据具体系统的字长,和数据本身的尺寸,m值是可以很简单计算出来的。
举例:
char c; // 由于c占1个字节,因此c不管放哪里地址都是对齐的,因此m=1
short s; // 由于s占2个字节,因此s地址只要是偶数就是对齐的,因此m=2
int i; // 由于i占4个字节,因此只要i地址满足4的倍数就是对齐的,因此m=4
double f; // 由于f占8个字节,因此只要f地址满足4的倍数就是对齐的,因此m=4
printf("%p\n", &c); // &c = 1*N,即:c的地址一定满足1的整数倍
printf("%p\n", &s); // &s = 2*N,即:s的地址一定满足2的整数倍
printf("%p\n", &i); // &i = 4*N,即:i的地址一定满足4的整数倍
printf("%p\n", &f); // &f = 4*N,即:f的地址一定满足4的整数倍
注意,变量的m值跟变量本身的尺寸有关,但它们是两个不同的概念。
手工干预变量的m值:
char c __attribute__((aligned(32))); // 将变量 c 的m值设置为32
语法:
attribute 机制是GNU特定语法,属于C语言标准语法的扩展。
attribute 前后都是双下划线,aligned两边是双圆括号。 attribute 语句,出现在变量定义语句中的分号前面,变量标识符后面。
attribute 机制支持多种属性设置,其中aligned用来设置变量的m 值属性。 一个变量的 m值只能提升,不能降低,且只能为正的2的n次幂。
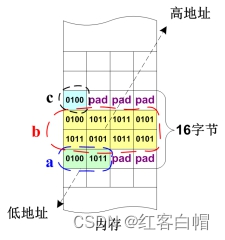
【8】C语言-》结构体的M值
概念: 结构体的M值,
取决于其成员的m值的最大值。即:M = max{m1, m2, m3, …};结构体的地址和尺寸,都必须等于M值的整数倍。
示例:
struct node
{
short a; // 尺寸=2,m值=2
double b; // 尺寸=8,m值=4
char c; // 尺寸=1,m值=1
};
struct node n; // M值 = max{2, 4, 1} = 4;
以上结构体成员存储分析:
`结构体的M值等于4,这意味着结构体的地址、尺寸都必须满足4的倍数。`
成员a的m值等于2,但a作为结构体的首元素,必须满足M值约束,
即a的地址必须是4的倍数
成员b的m值等于4,因此在a和b之间,需要填充2个字节的无效数据(一般填充0)
成员c的m值等于1,因此c紧挨在b的后面,占一个字节即可。
结构体的M值为4,因此成员c后面还需填充3个无效数据,才能将结构体尺寸凑足4的倍数。
`以上结构体成员图解分析:`
可移植性
可移植指的是相同的一段数据或者代码,在不同的平台中都可以成功运行。对于数据来说,有两方面可能会导致不可移植: 数据尺寸发生变化 数据位置发生变化
第一个问题,起因是基本的数据类型在不同的系统所占据的字节数不同造成的,解决办法是使用教案04讨论过的可移植性数据类型即可。本节主要讨论第二个问题。
考虑结构体:
struct node
{
int8_t a;
int32_t b;
int16_t c;
};
以上结构体,在不同的的平台中,成员的尺寸是固定不变的,但由于不同平台下各个成员的m值可能会发生改变,因此成员之间的相对位置可能是飘忽不定的,这对数据的可移植性提出了挑战。
解决的办法有两种:
第一,固定每一个成员的m值,也就是每个成员之间的塞入固定大小的填充物固定位置:
struct node
{
int8_t a __attribute__((aligned(1))); // 将 m 值固定为1
int64_t b __attribute__((aligned(8))); // 将 m 值固定为8
int16_t c __attribute__((aligned(2))); // 将 m 值固定为2
};
第二,将结构体压实,也就是每个成员之间不留任何空隙:
struct node
{
int8_t a;
int64_t b;
int16_t c;
} __attribute__((packed));
【9】C语言-》联合体基本概念
联合体的外在形式跟结构体非常类似,但它们有一个·
本质的区别:结构体中的各个成员是各自独立的,而联合体中的各个成员却共用同一块内存,因此联合体也称为共用体。
联合体内部成员的这种特殊的“堆叠”效果,使得联合体有如下基本特征:
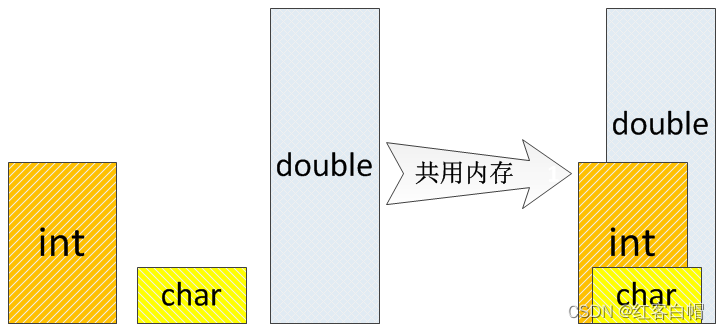
整个联合体变量的尺寸,取决于联合体中尺寸最大的成员。 给联合体的某个成员赋值,会覆盖其他的成员,使它们失效。
联合体各成员之间形成一种“互斥”的逻辑,在某个时刻只有一个成员有效。
联合体的定义:
union 联合体标签
{
成员1;
成员2;
...
};
语法:
联合体标签,用来区分各个不同的联合体。
成员,是包含在联合体内部的数据,可以是任意的数据类型。
// 定义了一种称为 union attr 的联合体类型
union attr
{
int x;
char y;
double z;
};
int main()
{
// 定义联合体变量
union attr n;
}
【10】C语言-》联合体操作
联合体的操作跟结构体形式上别无二致,但由于联合体特殊的存储特性,不管怎么初始化和赋值,最终都有且仅有一个成员是有效的。
初始化:
`普通初始化:第一个成员有效(即只有100是有效的,其余成员会被覆盖)`
union attr at = {
100, 'k', 3.14};
`指定成员初始化:最后一个成员有效(即只有3.14是有效的,
其余成员会被覆盖)`
union attr at = {
.x = 100,
.y = 'k',
.z = 3.14,
};
成员引用:
at.x = 100;
at.y = 'k';
at.z = 3.14; // 只有最后一个赋值的成员有效
printf("%d\n", at.x);
printf("%c\n", at.y);
printf("%lf\n", at.z);
联合体指针:
union attr *p = &at;
p->x = 100;
p->y = 'k';
p->z = 3.14; // 只有最后一个赋值的成员有效
printf("%d\n", p->x);
printf("%c\n", p->y);
printf("%lf\n", p->z);
联合体的使用
联合体一般很少单独使用,而经常以结构体的成员形式存在,用来表达某种互斥的属性。
//示例:
struct node
{
int a;
char b;
double c;
union attr at; // at内有三种互斥的属性,非此即彼
};
int main()
{
struct node n;
n.at.x = 100; // 使用连续的成员引用符来索引结构体中的联合体成员
}
【11】 C语言-》枚举
枚举类型的本质是提供一种范围受限的整型,比如用0-6表示七种颜色,用0-3表示四种状态等,但枚举在C语言中并未实现其本来应有的效果,直到C++环境下枚举才拥有原本该有的属性。
枚举常量列表
enum是关键字
`spectrum是枚举常量列表标签`,可以省略。省略的情况下无法定义枚举变量
enum spectrum{
red, orange, yellow, green, blue, cyan, purple};
enum {
reset, running, sleep, stop};
//枚举变量
enum spectrum color = orange; // 等价于 color = 1
语法要点:
枚举常量实质上就是整型,首个枚举常量默认为0。 枚举常量在定义时可以赋值,若不赋值,则取其前面的枚举常量的值加1。
C语言中,枚举等价于整型,支持整型数据的一切操作。
使用举例:
switch(color)
{
case red:
// 处理红色...
case orange:
// 处理橙色...
case yellow:
// 处理黄色...
}
枚举数据最重要的作用,是使用有意义的单词,来替代无意义的数字,提高程序的可读性。
【12】C语言-》预处理
在C语言程序源码中,凡是以井号(#)开头的语句被称为预处理语句,这些语句严格意义上并不属于C语言语法的范畴,它们在编译的阶段统一由所谓预处理器(cc1)来处理。所谓预处理,顾名思义,指的是真正的C程序编译之前预先进行的一些处理步骤,这些预处理指令包括:
`头文件:#include
定义宏:#define
取消宏:#undef
条件编译:#if、#ifdef、#ifndef、#else、#elif、#endif
显示错误:#error
修改当前文件名和行号:#line
向编译器传送特定指令:#progma`
基本语法
一个逻辑行只能出现一条预处理指令,多个物理行需要用反斜杠连接成一个逻辑行 预处理是整个编译全过程的第一步:预处理 - 编译 - 汇编 - 链接 可以通过如下编译选项来指定来限定编译器只进行预处理操作:
gcc example.c -o example.i -E
【13】C语言-》宏的概念
宏(macro)实际上就是一段特定的字串,在源码中用以替换为指定的表达式。例如:
#define PI 3.14
此处,PI
就是宏(宏一般习惯用大写字母表达,以区分于变量和函数,但这并不是语法规定,只是一种习惯),是一段特定的字串,这个字串在源码中出现时,将被替换为3.14。例如:
int main()
{
printf("圆周率: %f\n", PI);
// 此语句将被替换为:printf("圆周率: %f\n", 3.14);
}
宏的作用:
使得程序更具可读性:字串单词一般比纯数字更容易让人理解其含义。 使得程序修改更易行:修改宏定义,即修改了所有该宏替换的表达式。
提高程序的运行效率:程序的执行不再需要函数切换开销,而是就地展开。
【14】C语言-》无参宏
无参宏意味着使用宏的时候,无需指定任何参数,比如:
#define PI 3.14
#define SCREEN_SIZE 800*480*4
int main()
{
// 在代码中,可以随时使用以上无参宏,来替代其所代表的表达式:
printf("圆周率: %f\n", PI);
mmap(NULL, SCREEN_SIZE, PROT_READ|PROT_WRITE, MAP_SHARED, ...);
}
注意到,上述代码中,除了有自定义的宏,还有系统预定义的宏:
// 自定义宏:
#define PI 3.14
#define SCREEN_SIZE 800*480*4
// 系统预定义宏
#define NULL ((void *)0)
#define PROT_READ 0x1 /* Page can be read. */
#define PROT_WRITE 0x2 /* Page can be written. */
#define MAP_SHARED 0x01 /* Share changes. */
宏的最基本特征是进行直接文本替换,以上代码被替换之后的结果是:
int main()
{
printf("圆周率: %f\n", 3.14);
mmap(((void *)0), 800*480*4, 0x1|0x2, 0x01, ...);
}
【15】 C语言-》带参宏
带参宏意味着宏定义可以携带“参数”,从形式上看跟函数很像,例如:
#define MAX(a, b) a>b ? a : b
#define MIN(a, b) a<b ? a : b
以上的MAX(a,b) 和 MIN(a,b)
都是带参宏,不管是否带参,宏都遵循最初的规则,即宏是一段待替换的文本,例如在以下代码中,宏在预处理阶段都将被替换掉:
int main()
{
int x = 100, y = 200;
printf("最大值:%d\n", MAX(x, y));
printf("最小值:%d\n", MIN(x, y));
// 以上代码等价于:
// printf("最大值:%d\n", x>y ? x : y);
// printf("最小值:%d\n", x<y ? x : y);
}
带参宏的特点:
1,直接文本替换,不做任何语法判断,更不做任何中间运算。
2,宏在编译的第一个阶段就被替换掉,运行中不存在宏。
3,宏将在所有出现它的地方展开,这一方面浪费了内存空间,另一方面有节约了切换时间。
【16】C语言-》带参宏的副作用
由于宏仅仅做文本替换,中间不涉及任何语法检查、类型匹配、数值运算,因此用起来相对函数要麻烦很多。例如:
#define MAX(a, b) a>b ? a : b
int main()
{
int x = 100, y = 200;
printf("最大值:%d\n", MAX(x, y==200?888:999));
}
直观上看,无论 y 的取值是多少,表达式 y==200?888:999 的值一定比 x
要大,但由于宏定义仅仅是文本替换,中间不涉及任何运算,因此等价于:
printf("最大值:%d\n", x>y==200?888:999 ? x : y==200?888:999);
可见,带参宏的参数不能像函数参数那样视为一个整体,整个宏定义也不能视为一个单一的数据,事实上,不管是宏参数还是宏本身,都应被视为一个字串,或者一个表达式,或者一段文本,因此最基本的原则是:
将宏定义中所有能用括号括起来的部分,都括起来,比如:
#define MAX(a, b) ((a)>(b) ? (a) : (b))
宏定义中的符号粘贴
有些时候,宏参数中的符号并非用来传递数据,而是用来形成多种不同的字串,例如在某些系统函数中,系统本身规范了函数接口的部分标准,形如:
void __zinitcall_service_1(void)
{
...
}
void __zinitcall_service_2(void)
{
...
}
void __zinitcall_feature_1(void)
{
...
}
void __zinitcall_feature_2(void)
{
...
}
此时,若需要向用户提供一个方便整合字串的宏定义,可以这么写:
连接符##
#define LAYER_INITCALL(num, layer) __zinitcall_##layer##_##num
用户的调用如下:
LAYER_INITCALL(service, 1);
LAYER_INITCALL(service, 2);
LAYER_INITCALL(feature, 1);
LAYER_INITCALL(feature, 2);
注意:
在书写非字符串的字串时(如上述例子),使用两边双井号来粘贴字串,并且要注意如果字串出现在最末尾,则最后的双井号必须去除,例如上述代码不可写成:
#define LAYER_INITCALL(num, layer) __zinitcall_##layer##_##num##
但如果粘贴的字串并非出现在最末尾,则前后都必须加上双井号:
#define LAYER_INITCALL(num, layer) __zinitcall_##layer##_##num##end
注意:
另外,如果字串本身拼接为字符串,那么只需要使用一个井号即可,比如:
#define domainName(a, b) "www." #a "." #b ".com"
int main()
{
printf("%s\n", domainName(yueqian, lab));
}
执行打印如下:
gec@ubuntu:~$ ./a.out
www.yueqian.lab.com
gec@ubuntu:~$
【17】C语言-》无值宏定义
定义无参宏的时候,不一定需要带值,无值的宏定义经常在条件编译中作为判断条件出现,例如:
#define BIG_ENDIAN
#define __cplusplus
【18】C语言-》条件编译
概念:有条件的编译,通过控制某些宏的值,来决定编译哪段代码。 形式:
形式1:判断表达式 MACRO 是否为真,据此决定其所包含的代码段是否要编译
注意:#if形式条件编译需要有值宏
#define A 0
#define B 1
#define C 2
#if A
... // 如果 MACRO 为真,那么该段代码将被编译,否则被丢弃
#endif
// 二路分支
#if A
...
#elif B
...
#endif
// 多路分支
#if A
...
#elif B
...
#elif C
...
#endif
形式:
形式2:判断宏 MACRO 是否已被定义,据此决定其所包含的代码段是否要编译
// 单独判断
#ifdef MACRO
...
#endif
// 二路分支
#ifdef MACRO
...
#else
...
#endif
形式:
形式3:判断宏MACRO是否未被定义,据此决定其所包含的代码段是否要编译
// 单独判断
#ifndef MACRO
...
#endif
// 二路分支
#ifndef MACRO
...
#else
...
#endif
总结:
#ifdef 此种形式,判定的是宏是否已被定义,这不要求宏有值。
#if 、#elif 这些形式,判定的是宏的值是否为真,这要求宏必须有值。
【19】 C语言-》条件编译的使用场景
控制调试语句:在程序中,用条件编译将调试语句包裹起来,通过gcc编译选项随意控制调试代码的启停状态。例如:
gcc example.c -o example -DMACRO
以上语句中,-D意味着 Define,MACRO
是程序中用来控制调试语句的一个宏,如此一来就可以在完全不需要修改源代码的情况下,通过外部编译指令选项非常方便地控制调试信息的启停。
选择代码片段:在一些大型项目中(例如 Linux
内核),某个相同功能的模块往往有不同的实现,需要用户根据具体的情况来“配置”,这个所谓的配置的过程,就是对代码中不同的宏的选择的过程。
例如:
#define A 0 // 网卡1
#define B 1 // 网卡2 √
#define C 0 // 网卡3
// 多路分支
#if A
...
#elif B
...
#elif C
...
#endif
【20】 C语言-》头文件的作用
通常,一个常规的C语言程序会包含多个源码文件(.c),当某些公共资源需要在各个源码文件中使用时,为了避免多次编写相同的代码,一般的做法是将这些大家都需要用到的公共资源放入头文件(.h)当中,然后在各个源码文件中直接包含即可。

【21】 C语言-》头文件的内容extern 关键字
头文件中所存放的内容,就是各个源码文件的彼此可见的公共资源,包括:
全局变量的声明。
普通函数的声明。
静态函数的定义。
宏定义。
结构体、联合体的定义。
枚举常量列表的定义。
其他头文件。
示例代码:
// head.h
extern int global; // 1,全局变量的声明
extern void f1(); // 2,普通函数的声明
static void f2() // 3,静态函数的定义
{
...
}
#define MAX(a, b) ((a)>(b)?(a):(b)) // 4,宏定义
struct node // 5,结构体的定义
{
...
};
union attr // 6,联合体的定义
{
...
};
#include <unistd.h> // 7,其他头文件
#include <string.h>
#include <stdint.h>
特别说明:
全局变量、普通函数的定义一般出现在某个源文件(*.c *.cpp)中,其他的源文件想要使用都需要进行声明,因此一般放在头文件中更方便。
静态函数、宏定义、结构体、联合体的定义都只能在其所在的文件可见,因此如果多个源文件都需要使用的话,放到头文件中定义是最方便,也是最安全的选择。
【22】 C语言-》头文件的使用
头文件编写好了之后,就可以被各个所需要的源码文件包含了,包含头文件的语句就是如下预处理指令:
// main.c
#include "head.h" // 包含自定义的头文件
#include <stdio.h> // 包含系统预定义的文件
int main()
{
...
}
可以看到,在源码文件中包含指定的头文件有两种不同的形式:
使用双引号:在指定位置 + 系统标准路径搜索 head.h
使用尖括号:在系统标准路径搜索 stdio.h
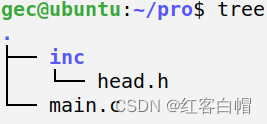
一个简易示例
由于自定义的头文件一般放在源码文件的周围,因此需要在编译的时候通过特定的选项来指定位置,而系统头文件都统一放在标准路径下,一般无需指定位置。
假设在源码文件 main.c 中,包含了两个头文件:head.h 和 stdio.h
,由于他们一个是自定义头文件,一个是系统标准头文件,前者放在项目 pro/inc 路径下,后者存放于系统头文件标准路径下(一般位于
/usr/include),因此对于这个程序的编译指令应写作:
gec@ubuntu:~/pro$ gcc main.c -o main -I /home/gec/pro/inc
其中,/home/gec/pro/inc 是自定义头文件 head.h 所在的路径
语法要点:
预处理指令 #include 的本质是复制粘贴:将指定头文件的内容复制到源码文件中。 系统标准头文件路径可以通过编译选项 -v来获知,比如:
gec@ubuntu:~/pro$ gcc main.c -I /home/gec/pro/inc -v
... ...
#include "..." search starts here:
#include <...> search starts here:
/usr/lib/gcc/x86_64-linux-gnu/7/include
/usr/local/include
/usr/lib/gcc/x86_64-linux-gnu/7/include-fixed
/usr/include/x86_64-linux-gnu
/usr/include
... ...
【23】 C语言-》头文件的格式
由于头文件包含指令 #include 的本质是复制粘贴,并且一个头文件中可以嵌套包含其他头文件,因此很容易出现一种情况是:头文件被重复包含。
使用条件编译,解决头文件重复包含的问题,格式如下:
#ifndef _HEADNAME_H
#define _HEADNAME_H
...
... (头文件正文)
...
#endif
其中,HEADNAME一般取头文件名称的大写
【24】 C语言-》面试题
(结构体基本语法) 【1】指出以下代码片段的不妥之处。
structure node
(
char itable,
int num[5],
char * togs
)
解析: structure写错了,改为:struct 结构体定义是花括号{} 每个成员的定义,使用分号结束 结构体定义最后一定要带分号
正确写法:
struct node
{
char itable;
int num[5];
char *togs;
};
(地址对齐、结构体大小) 【2】分析以下结构体所占的存储空间大小。假设是64位系统
struct animals
{
char dog;
unsigned long cat;
short pig;
char fox;
};
解析: 首先,对于64位系统来说,处理器每次存取数据以8字节为单位,以此可以推断出该结构体中各个成员的“m值”分别为:
struct animals
{
char dog; // m = 1
unsigned long cat; // m = 8
short pig; // m = 2
char fox; // m = 1
}; // M = max{1,8,2,1} = 8
注意到,整个结构体也是需要地址对齐的,并且结构体变量的 “M值” 取决于其成员“m值”的最大值,因此 M=8。
由于一个变量的m值决定了
①起始地址必须是m的整数倍;
②所占内存必须是m的整数倍,可以容易得到如下结论:
dog占1个字节 + 填充7个字节(因为后续的cat的m值为8)
cat占8个字节,无需填充(因为后续的pig的m值为2)
pig占2个字节,无需填充(因为后续的fox的m值为1)
fox占1个字节 + 填充5个字节(因为整个结构体的M值为8,大小需是8的倍数)
最后,整个结构体的大小是
1+7+8+2+1+5字节,即24个字节。还要注意,这是64位系统8字节对齐的情况,如果是32位系统的话要根据实际情况另行计算。
(结构体基本语法) 【3】定义一个结构体来存储日期(含年、月、日)。并设计一个函数,计算传入的结构体存储的日期是一年中的第几天。
解析: 首先要设计好一个可以储存年月日的结构体,其次在判断第几天的时候还要考虑年份是否闰年。
参考代码:
#include <stdio.h>
struct date
{
short year;
char month;
char day;
};
int main(void)
{
printf("请输入年月日(格式:1969/09/23) :");
struct date sunny;
scanf("%hd/%hhd/%hhd", &sunny.year,
&sunny.month,
&sunny.day);
if(sunny.month<1 ||
sunny.month>12 ||
sunny.day<1 ||
sunny.day>31)
{
printf("非法日期.\n");
exit(0);
}
if(((sunny.month%2 == 0) && (sunny.day > 31)) ||
(sunny.month == 2 && sunny.day > 29))
{
printf("非法日期.\n");
exit(0);
}
int days[12] = {
31, 0, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
int i, total_days = 0;
// 判断是否闰年
if((sunny.year%4==0 && sunny.year%100!=0) ||
(sunny.year%400==0))
days[1] = 29;
else
days[1] = 28;
for(i=0; i<sunny.month-1; i++)
total_days += days[i];
total_days += sunny.day;
printf("该日期是第%d天\n", total_days);
return 0;
}
(函数指针、库文件编译与使用)
【4】编写一个transform()函数,接口约定如下所示:
void transform(double source[],
double target[],
int num,
double (*p)(double));
它接受4个参数:
double类型数据的源数组名
double类型的目标数组名
表示数组元素个数的int变量
函数指针p。
transform()函数把指定的函数作用于源数组source中的每个元素,并将转换后的结果一一对应地放到目标数组target中。
`要求:
使用数学库中的正弦函数和余弦函数,即 sin() 和 cos() 进行转换。
使用自定义的函数,进行转换。`
解析:
函数本质就是函数代码块本身的地址,因此函数就是一个指针,指向它自身。基于这个简单的事实,所有的函数(包括自定义的、系统预定义的)都可以作为参数进行传递。
参考代码:
#include <stdio.h>
#include <math.h>
#define SIZE 3
void transform(double source[], double target[],
int size, double (*func)(double))
{
int i;
for(i=0; i<size; i++)
target[i] = func(source[i]);
}
double func1(double i)
{
return i+1;
}
double func2(double i)
{
return i*2;
}
void show(double ar[])
{
int i;
for(i=0; i<SIZE; i++)
{
printf("%f\t", ar[i]);
}
printf("\n");
}
int main(void)
{
// 源数组
double source[SIZE] = {
0.1, 0.2, 0.3};
// 目标数组
double target[SIZE];
// 使用自定义函数 func1,将源数组转入目标数组
transform(source, target, SIZE, func1);
show(target);
printf("--------------\n");
// 使用自定义函数 func2,将源数组转入目标数组
transform(source, target, SIZE, func2);
show(target);
printf("--------------\n");
// 使用库函数sin,将源数组转入目标数组
transform(source, target, SIZE, sin);
show(target);
printf("--------------\n");
// 使用库函数cos,将源数组转入目标数组
transform(source, target, SIZE, cos);
show(target);
return 0;
}
(带参宏定义) 【5】写一个带参数的宏 MIN(x, y),使之可用于求解给定两个数的最小值。
解析:
本题考查对C语言宏定义的基本使用,有几个注意点:
第一,宏是直接替换,不是函数封装,因此没有返回值。
第二,如果传入的数据运算过程中会被多次操作,为避免计算谬误,要进行二次封装。
参考代码:
#include <stdio.h>
#define MIN(x, y) ({
\
typeof(x) _x = x; \
typeof(y) _y = y; \
(void)(&_x==&_y); \
_x < _y ? _x : _y;\
)}
int main(void)
{
float x, y;
scanf("%f%f", &x, &y);
printf("最小值: %f\n", MIN(x, y));
return 0;
}
(头文件格式) 【6】某头文件中有以下语句,解释其作用。
#ifndef _SOME_HEADER_H_
#define _SOME_HEADER_H_
… …
#endif
解析:
防止该头文件被重复包含。
(递归) 【7】下面函数实现数组 a 元素的逆转,k为数组的元素个数。请填写空白处使其完整。
void recur(int a[], int k)
{
if( ______ )
return;
recur( _____, _____ );
int tmp;
tmp = a[0];
a[0] = a[k-1];
a[k-1] = tmp;
}
解析:
写递归函数的基本思路是:
① 找到一个无需递归,直接返回结果的条件。
② 将原问题,拆解为规模更小的问题。
对于本题而言
①当数组的元素个数太少,比如 k小于等于1时,肯定是无需递归的。
②对原数组数组中nn个数据的逆转,可以分成两步:
首先,将中间的n-2n−2个数据进行逆转;
然后,将首尾两个数调换位置即可,此时会发现,第一步是个递归的问题。
参考代码:
void recur(int a[], int k)
{
if( k <= 1 )
return;
recur( a+1, k-2 );
int tmp;
tmp = a[0];
a[0] = a[k-1];
a[k-1] = tmp;
}