本文从代码提交关联需求任务的功能说起,探讨了其意义、功能扩展以及对研发效能提升带来的收益。
记得原来有一次听到一个开发同学抱怨说为啥每次Commit都必须要填写commit message呢?他觉得有些浪费时间,因此想出了各种办法来应对,比如输入一个句点或复制粘贴上个commit message等。这种一时偷懒的做法,却会给其他合作开发的伙伴带来很多烦恼,这些不知所云的commmit message
不仅不能很好代表每次代码提交的用途,还会成为垃圾信息给团队带来干扰。
| git commit -m “.” |
不过现在很多开发团队已经通过约定代码提交规范来约束提交信息的规范化,比如必须包含类型(新功能、修复缺陷或者增加测试等)和主题(提交代码的简短描述)信息。
| git commit -m “feature:用户查询接口开发” |
可以看到在代码提交信息中增加目的描述,是为了使代码的作用通过文字显式地展示出来。比如一看提交信息就知道这段代码是为了开发某个新的需求功能,而不用去通过逐行浏览代码才能了解其含义。更进一步的做法是,直接使代码的提交与需求、任务或者缺陷等建立关联。拿GitHub举例,需求和缺陷都可以通过issue来进行管理,而只每次在代码提交信息中输入issue的ID就可以了,如下:
| git commit -m “#10 issueid” |
还可以通过在commit信息中输入close等指令来实现issue状态的修改,如下:
| git commit -m “close #10 issueid” |
直接通过git命令就实现了issue的关闭:

为什么代码提交要关联需求和任务信息
看到这里,我想你可能要问:我为什么要每次提交代码的时候,要费劲地先去查询下IssueID呢,这样做能带来什么收益呢?下面我就来给你捋一捋:
1.研发过程资产的可度量
代码是一种很重要的研发过程资产,而其原生状态又是一种非结构化的数据信息,无法很直观的与管理者所关注的项目或者需求关联起来。如果没有好的数据管理和度量机制,管理者角度就只能通过会议和沟通等手段从一线工程师那里获取一些主观的描述。如需求和任务的工作量大小、细化到需求和任务维度的代码质量和风险等数据,这些数据在做项目复盘、资源评估、质量和风险评估等环节都是非常重要的参考依据。
通过提交信息中关联需求和任务ID,就可以得到以下的数据:
| 类型 |
提交次数 |
代码规模 |
质量评分 |
安全漏洞 |
| 需求A |
** |
**千行 |
** |
** |
| 任务A |
** |
**千行 |
** |
** |
| 缺陷A |
** |
**千行 |
** |
** |
以上是基础数据的汇总计算,还可以引入需求和任务维度的代码复杂度、代码当量和测试覆盖率等数据。
2.精细化的代码质量和风险管控
质量和风险的管控都是需要投入成本的,而通过实现代码和需求及任务的关联,可以设计更细粒度的质量和风险管控策略,在早期的质量预防、中期的风险发现和后期的问题复盘都可以很大程度上减少成本投入。目前大家所说的精准化测试的方法就是基于此策略,设计测试策略时可以依据需求来划定代码变更范围,再针对一定范围内的代码变更来设计高覆盖率的测试策略,从而避免由于全量执行测试用例带来的高成本。

另外还可以把代码扫描、单元测试和代码评审等质量卡点与需求和任务的流转状态相关联,做到需求和任务维度的质量内建和测试左移。
3.开发者视角的收益
如果你是一位一线工程师,看完以上两点收益,肯定会觉得这都是管理的诉求,那从工程师的视角来看又会有哪些收益呢?
-
减少为了研发效能度量而做一些额外工作
研发效能度量,需要度量需求的在各个阶段的停留时长,比如开发时长,比较传统的做法是需要研发同学开始写代码的时候,在研发协同平台上更新下需求和任务的状态,写完了提交测试后再去更新状态。这些重复性的工作,还是需要占用不少时间的,那么通过需求任务和代码提交建立关联,就可以通过代码提交等事件来自动化触发需求和任务状态的流转,这样还能自动把对应的开始时间和结束时间都自动记录下来,从而便于高效和准确地开展研发效能度量。
-
从代码为主的技术视角逐步扩展到关注需求价值的全局视角
由于管理者和业务方更关注需求价值和项目交付进度,而一线研发工程师往往更加关注技术细节,这样就容易造成管理者和业务视角获得的信息和工程师视角之间的割裂,比如作为研发leader为了紧急的项目或者需求焦虑不已,而作为一线工程师又各自在沉浸在自己的代码世界里不明所以。那么通过代码提交和需求任务建立关联,开发工程师关注代码本身的同时,还可以通过汇总代码仓库级或者版本所实现的需求价值和完成的开发任务,从而能够更加关注业务价值,通过技术视角和业务视角的结合,助推技术职业生涯的更好发展。
代码关联需求和任务的功能扩展
文章的前面只是介绍了从命令行提交代码的时候,如何与需求和任务信息建立关联。而要带来更多的收益,只有这个功能就不能完全满足了。完整的功能一般通过与协作工具的配合来完成,如Jira就实现需求/任务和开发分支的关联,还可以通过配置工作流来实现在线创建分支的同时触发需求/任务的状态变化(进入开发状态)。下图为需求/任务卡片详情页面的开发信息的展示,可以看到关联了一个开发分支,可以通过点击分支到代码库的分支详情页面。
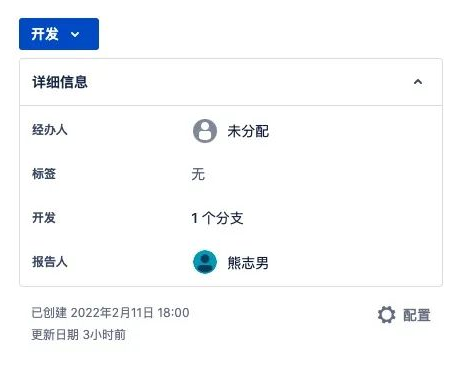
“功能拓展建议:在需求/任务已经关联一个代码分支的前提下,可以通过规则设定实现该分支下的所有代码提交都自动关联,这样就不需要每个Commit信息里都填写需求和任务ID信息了。”
目前很多协同平台的做法是,除了实现除了提交信息和分支与需求/任务的关联,还可以关联代码库的合并请求。另外还可以实现需求/任务与测试过程资产的关联。
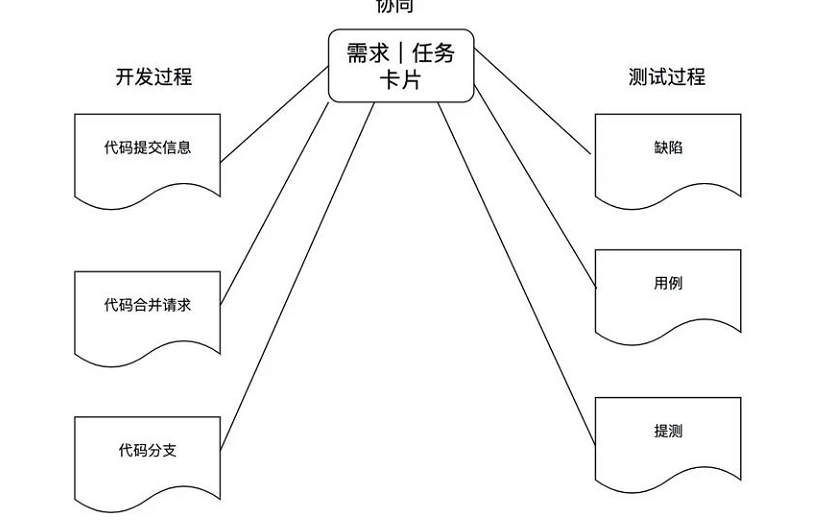
具体的实现方式有两种:一种是在协同平台的需求/任务卡片上通过手动操作来选择需要关联的信息,第二种是通过代码仓库和测试管理系统这样的三方工具平台主动上报关联的需求和任务信息。
结语
代码提交关联需求和任务的功能虽然不大,确实一个良好习惯的养成,在此基础上逐步实现更加丰富的代码过程资产与需求和任务的关联,从而为效能度量、质量和风险管控等提供更多的便利。研发效能提升包含两个层面,一个是单点任务的效能提升,如环境部署和测试等;另外一个就是不同角色成员之间的协同效能提升,而代码信息与需求任务信息的关联,就是通过过程数据的可视化使关注需求和任务的角色成员与关注代码的工程师实现更好的协同。