论文名称:Mobilenetv2: Inverted residuals and linear bottlenecks
论文下载:https://arxiv.org/abs/1707.07012
论文年份:CVPR 2018
论文被引:9343(2022/05/15)
论文代码:https://github.com/tonylins/pytorch-mobilenet-v2
Abstract
In this paper we describe a new mobile architecture, MobileNetV2, that improves the state of the art performance of mobile models on multiple tasks and benchmarks as well as across a spectrum of different model sizes. We also describe efficient ways of applying these mobile models to object detection in a novel framework we call SSDLite. Additionally, we demonstrate how to build mobile semantic segmentation models through a reduced form of DeepLabv3 which we call Mobile DeepLabv3.
is based on an inverted residual structure where the shortcut connections are between the thin bottleneck layers. The intermediate expansion layer uses lightweight depthwise convolutions to filter features as a source of non-linearity. Additionally, we find that it is important to remove non-linearities in the narrow layers in order to maintain representational power. We demonstrate that this improves performance and provide an intuition that led to this design.
Finally, our approach allows decoupling of the input/output domains from the expressiveness of the transformation, which provides a convenient framework for further analysis. We measure our performance on ImageNet [1] classification, COCO object detection [2], VOC image segmentation [3]. We evaluate the trade-offs between accuracy, and number of operations measured by multiply-adds (MAdd), as well as actual latency, and the number of parameters.
在本文中,我们描述了一种新的移动架构 MobileNetV2,它提高了移动模型在多个任务和基准测试以及不同模型大小范围内的最新性能。我们还描述了称为 SSDLite 的新框架,将这些移动模型应用于目标检测的有效方法。此外,我们演示了如何通过 Mobile DeepLabv3 的 DeepLabv3 的简化形式来构建移动语义分割模型。
基于倒置残差结构,其中快捷连接位于薄瓶颈层 (thin bottleneck layers) 之间。中间扩展层 (expansion layer) 使用轻量级深度卷积来过滤特征,作为非线性源。此外,我们发现去除窄层 (narrow layers) 中的非线性以保持代表性很重要。我们证明这可以提高性能并提供导致这种设计的直觉。
最后,我们的方法允许将输入/输出域与转换的表达性分离,这为进一步分析提供了一个方便的框架。我们测量了我们在 ImageNet [1] 分类、COCO 目标检测 [2]、VOC 图像分割 [3] 上的性能。我们评估准确性和乘加 (multiply-adds, MAdd) 测量的操作数量以及实际延迟和参数数量之间的权衡。
1. Introduction
神经网络彻底改变了机器智能的许多领域,为具有挑战性的图像识别任务提供了超人的准确性。然而,提高准确性的动力往往是有代价的:现代最先进的网络需要大量的计算资源,超出了许多移动和嵌入式应用程序的能力。
本文介绍了一种专门为移动和资源受限环境量身定制的新神经网络架构。我们的网络通过显着减少所需的操作和内存数量,同时保持相同的准确性,推动了移动定制计算机视觉模型的最新技术。
我们的主要贡献是一个新颖的层模块:具有线性瓶颈的倒置残差 (the inverted residual with linear bottleneck)。该模块将低维压缩表示作为输入,该表示首先扩展到高维并使用轻量级深度卷积进行过滤。随后将特征投影回具有线性卷积的低维表示。官方实现在 [4] 中作为 TensorFlow-Slim 模型库的一部分提供。
该模块可以在任何现代框架中使用标准操作有效地实现,并允许我们的模型使用标准基准在多个性能点上击败最先进的技术。此外,这种卷积模块特别适用于移动设计,因为它可以通过从不完全实现大型中间张量来显着减少推理期间所需的内存占用。这减少了许多嵌入式硬件设计中对主存储器访问的需求,这些设计提供少量非常快速的软件控制高速缓存。
2. Related Work
在过去几年中,调整深度神经架构以在准确性和性能之间取得最佳平衡一直是一个活跃的研究领域。由众多团队进行的手动架构搜索和训练算法的改进都导致了对早期设计(如 AlexNet [5]、VGGNet [6]、GoogLeNet [7])的显着改进。和 ResNet [8]。最近在算法架构探索方面取得了很多进展,包括超参数优化 [9, 10, 11] 以及各种网络修剪方法 [12, 13, 14, 15, 16, 17] 和连通性学习 (connectivity learning) [18, 19]。大量的工作也致力于改变内部卷积块的连接结构,例如在 ShuffleNet [20] 或引入稀疏性 [21] 和其他 [22]。
最近,[23,24,25,26] 开辟了将包括遗传算法和强化学习在内的优化方法引入架构搜索的新方向。然而,一个缺点是最终的网络非常复杂。在本文中,我们追求的目标是开发关于神经网络如何运行的更好直觉,并使用它来指导最简单的网络设计。我们的方法应该被视为对 [23] 中描述的方法和相关工作的补充。在这种情况下,我们的方法类似于 [20, 22] 所采用的方法,并允许进一步提高性能,同时提供对其内部操作的一瞥。我们的网络设计基于 MobileNetV1 [27]。它保留了简单性,不需要任何特殊的操作员,同时显着提高了准确性,在移动应用程序的多个图像分类和检测任务上实现了最先进的水平。
3. Preliminaries, discussion and intuition
3.1. Depthwise Separable Convolutions
深度可分离卷积是许多高效神经网络架构的关键构建块 [27,28,20],我们也在当前的工作中使用它们。基本思想是用将卷积分成两个独立层的分解版本替换完整的卷积算子。第一层称为深度卷积,它通过对每个输入通道应用单个卷积滤波器来执行轻量级滤波。第二层是 1×1 卷积,称为逐点卷积,负责通过计算输入通道的线性组合来构建新特征。
标准卷积采用 h i × w i × d i h_i × w_i × d_i hi×wi×di 输入张量 L i L_i Li,并应用卷积核 K ∈ R k × k × d i × d j K ∈ R^{k×k×d_i×d_j} K∈Rk×k×di×dj 以产生 h i × w i × d j h_i × w_i × d_j hi×wi×dj 输出张量 L j L_j Lj。标准卷积层的计算成本为 h i ⋅ w i ⋅ d i ⋅ d j ⋅ k ⋅ k h_i·w_i·d_i·d_j·k·k hi⋅wi⋅di⋅dj⋅k⋅k。
深度可分离卷积是标准卷积层的直接替代品。从经验上讲,它们的工作原理几乎与常规卷积一样好,但只是成本:
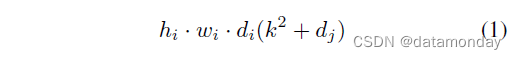
这是 depthwise 和1×1 pointwise卷积的总和。与传统层相比,有效的深度可分离卷积减少了几乎 k 2 k^2 k2 的计算量(更准确地说,乘以因子 k 2 d j / ( k 2 + d j ) k^2d_j/(k^2 + d_j) k2dj/(k2+dj))。 MobileNetV2 使用 k = 3( 3 × 3 3 × 3 3×3 深度可分离卷积),因此计算成本比标准卷积小 8 到 9 倍,而准确度仅略有降低 [27]。
3.2. Linear Bottlenecks
考虑一个由 n 层 Li 组成的深度神经网络,每个层都有一个维度为 hi × wi × di 的激活张量。在本节中,我们将讨论这些激活张量的基本属性,我们将其视为具有 di 维度的 hi × wi“像素”的容器。非正式地,对于一组输入的真实图像,我们说这组层激活(对于任何层 Li)形成了一个“感兴趣的流形”。长期以来,人们一直认为神经网络中感兴趣的流形可以嵌入到低维子空间中。换句话说,当我们查看深度卷积层的所有单个 d 通道像素时,这些值中编码的信息实际上位于某个流形中,而流形(manifold)又可以嵌入到低维子空间中。

图 1:嵌入在高维空间中的低维流形的 ReLU 转换示例。在这些示例中,使用随机矩阵 T 和 ReLU 将初始螺旋嵌入到 n 维空间中,然后使用 T -1 将其投影回二维空间。在上面的例子中 n = 2, 3 导致信息丢失,其中流形的某些点相互折叠,而对于 n = 15 到 30,变换是高度非凸的。
乍一看,可以通过简单地减少层的维数来捕获和利用这样的事实,从而减少操作空间的维数。这已被 MobileNetV1 [27] 成功利用,通过宽度乘数参数有效地在计算和准确性之间进行权衡,并已被纳入其他网络的有效模型设计中 [20]。按照这种直觉,宽度乘数方法允许人们减少激活空间的维数,直到感兴趣的流形跨越整个空间。然而,深度卷积神经网络具有非线性的每坐标变换(例如 ReLU)时,这种直觉就会被打破。例如,应用于一维空间中的一条线的 ReLU 会产生一条“射线”,而在 R^n 空间中,它通常会产生一条具有 n 个关节的分段线性曲线。
不难看出,一般来说,如果一个层变换的结果 ReLU(Bx) 的体积 S 非零,映射到内部 S 的点是通过输入的线性变换 B 得到的,因此表明对应于全维输出的输入空间仅限于线性变换。换句话说,深度网络仅在输出域的非零体积部分具有线性分类器的能力。我们参考补充材料以获得更正式的声明。
另一方面,当 ReLU 折叠通道时,它不可避免地会丢失该通道中的信息。但是,如果我们有很多通道,并且激活流形中有一个结构,那么信息可能仍会保留在其他通道中。在补充材料中,我们表明,如果输入流形可以嵌入到激活空间的显着低维子空间中,那么 ReLU 变换会保留信息,同时将所需的复杂性引入可表达的函数集。
总而言之,我们强调了两个属性,这些属性表明感兴趣的流形应该位于高维激活空间的低维子空间中:
-
如果感兴趣的流形在 ReLU 变换后保持非零体积,则对应于线性变换。
-
ReLU 能够保存有关输入流形的完整信息,但前提是输入流形位于输入空间的低维子空间中。
这两个见解为我们提供了优化现有神经架构的经验提示:假设感兴趣的流形是低维的,我们可以通过将线性瓶颈层插入卷积块来捕获这一点。实验证据表明,使用线性层至关重要,因为它可以防止非线性破坏太多信息。在第 6 节中,我们凭经验证明在瓶颈中使用非线性层确实会降低几个百分点的性能,进一步验证了我们的假设。我们注意到,在 [29] 中报告了有助于非线性的类似报告,其中非线性从传统残差块的输入中移除,从而提高了 CIFAR 数据集的性能。
在本文的其余部分,我们将使用瓶颈卷积 (bottleneck convolutions)。我们将输入瓶颈的大小与内部大小之间的比率称为扩展比率 (expansion ratio)。
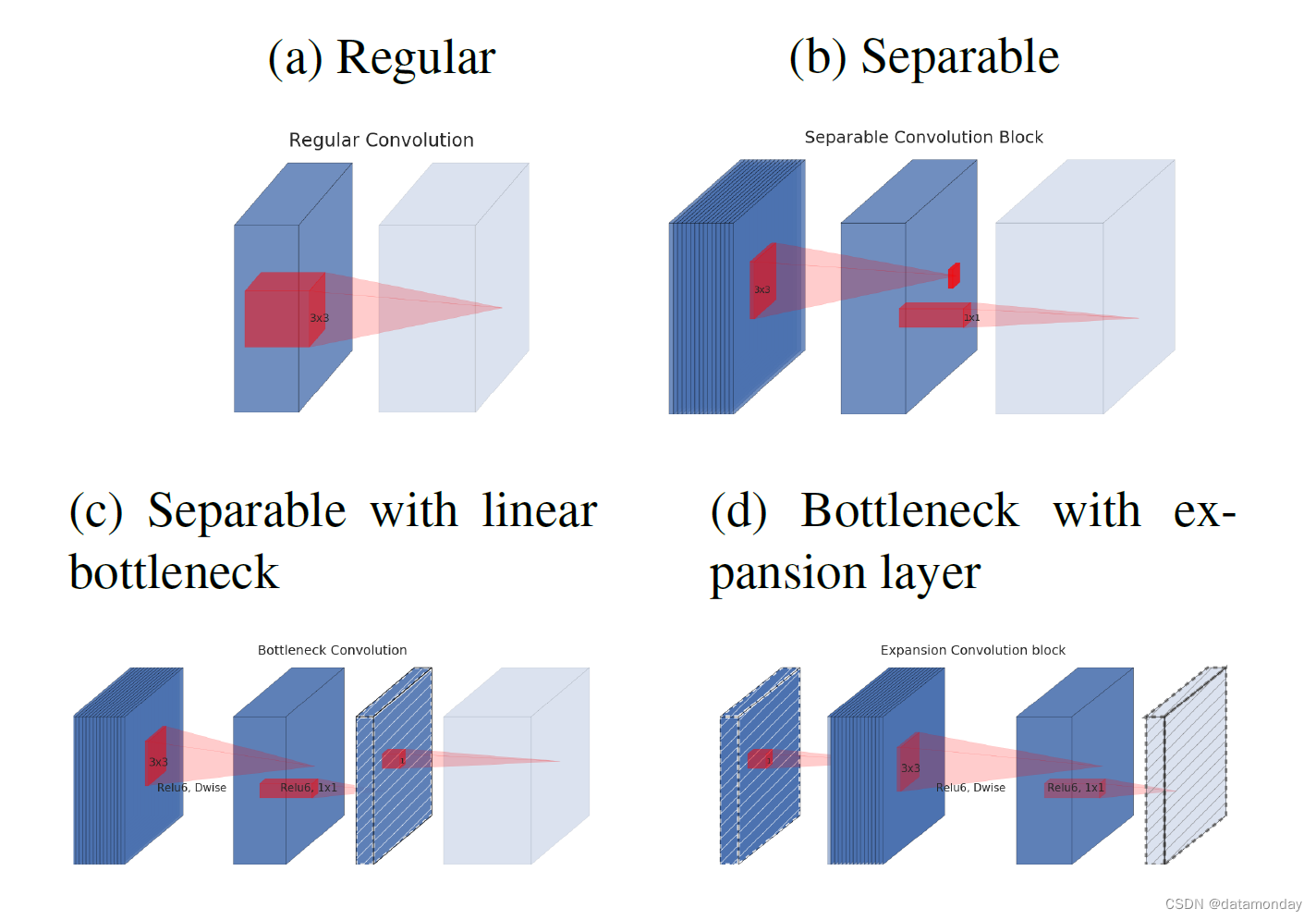
图 2:可分离卷积块的演变。斜阴影纹理表示不包含非线性的层。最后一层(浅色)表示下一个块的开始。注意:2d 和 2c 在堆叠时是等效的块。最好以彩色观看。
3.3. Inverted residuals
瓶颈块看起来类似于残差块,其中每个块包含一个输入,然后是几个瓶颈,然后是扩展 [8]。然而,受到瓶颈实际上包含所有必要信息的直觉的启发,而扩展层仅作为伴随张量非线性变换的实现细节,我们直接在瓶颈之间使用快捷方式。
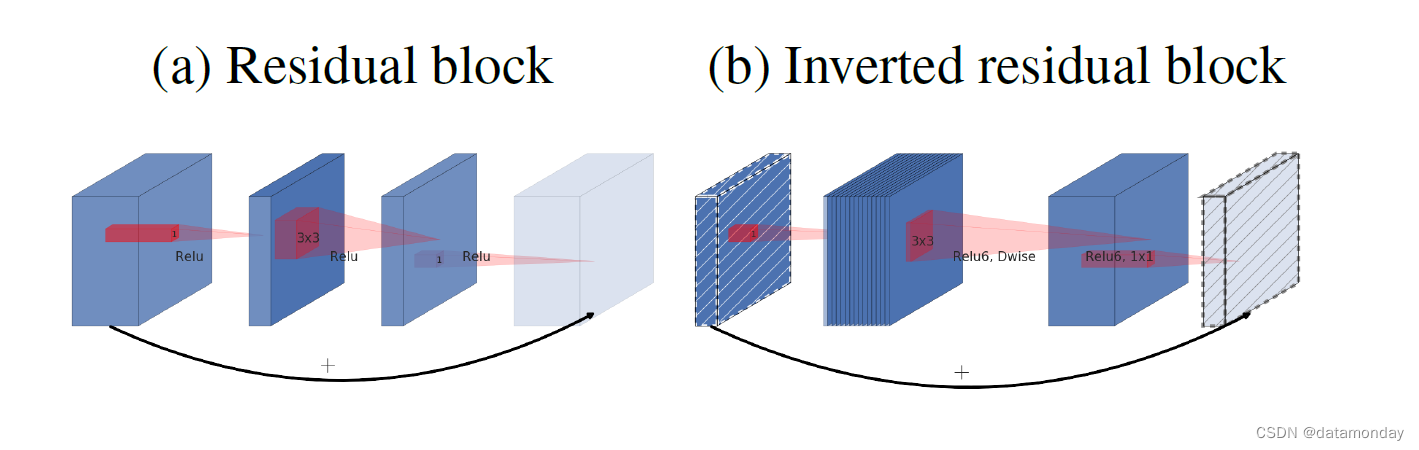
图 3:残差块 [8, 30] 和倒置残差之间的区别。对角线阴影层不使用非线性。我们使用每个块的厚度来表示其相对通道数。请注意经典残差如何连接具有大量通道的层,而反向残差如何连接瓶颈。最好以彩色观看。
图 3 提供了设计差异的示意图。插入快捷方式的动机类似于经典的残差连接:我们希望提高梯度在乘法器层中传播的能力。然而,倒置设计的内存效率要高得多(详见第 5 节),并且在我们的实验中效果更好。
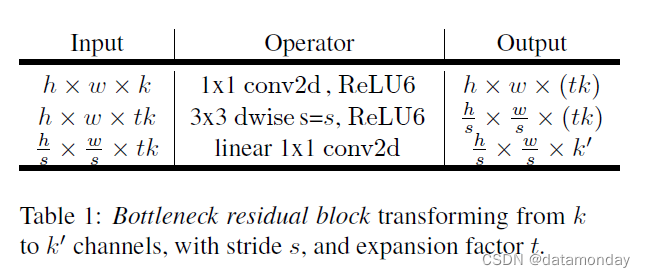
瓶颈卷积的运行时间和参数计数基本实现结构如表 1 所示。对于一个大小为 h × w,扩展因子为 t 和卷积核大小为 k 的块,具有 d’ 个输入通道和 d’’ 个输出通道,所需的乘加总数是 h · w · d’ · t(d’ + k2 + d’')。与(1)相比,这个表达式有一个额外的项,因为我们确实有一个额外的 1 × 1 卷积,但是我们网络的性质允许我们使用更小的输入和输出维度。在表 3 中,我们比较了 MobileNetV1、MobileNetV2 和 ShuffleNet 之间每种分辨率所需的大小。

表 3:不同架构在每个空间分辨率下需要实现的最大通道数/内存(以 Kb 为单位)。我们假设激活是 16 位浮点数。对于 ShuffleNet,我们使用与 MobileNetV1 和 MobileNetV2 的性能相匹配的 2x,g = 3。对于 MobileNetV2 和 ShuffleNet 的第一层,我们可以使用第 5 节中描述的技巧来减少内存需求。尽管 ShuffleNet 在其他地方使用了瓶颈,但由于非瓶颈张量之间存在捷径,非瓶颈张量仍然需要实现。
3.4. Information flow interpretation
我们架构的一个有趣特性是它提供了构建块(瓶颈层)的输入/输出域和层转换之间的自然分离——这是一种将输入转换为输出的非线性函数。前者可以看作是网络在每一层的容量,而后者可以看作是表现力。这与常规和可分离的传统卷积块形成对比,其中表达性和容量都纠缠在一起,并且是输出层深度的函数。
特别是,在我们的例子中,当内层深度为 0 时,由于快捷连接,底层卷积是恒等函数。当扩展比 (expansion ratio) 小于 1 时,这是一个经典的残差卷积块 [8, 30]。然而,为了我们的目的,我们表明大于 1 的扩展比是最有用的。
这种解释使我们能够将网络的表达能力与其容量分开研究,我们相信有必要进一步探索这种分离,以更好地理解网络属性。
4. Model Architecture
现在我们详细描述我们的架构。如上一节所述,基本构建块是带有残差的瓶颈深度可分离卷积。该块的详细结构如表1所示。MobileNetV2 的架构包含具有 32 个滤波器的初始全卷积层,随后是表 2 中描述的 19 个残差瓶颈层。使用 ReLU6 作为非线性,因为它在与低精度计算一起使用时具有鲁棒性 [27]。我们始终使用现代网络的标准卷积核大小 3 × 3,并在训练期间利用 dropout 和批量归一化。

表 2:MobileNetV2:每行描述 1 个或多个相同(模步幅)层的序列,重复 n 次。同一序列中的所有层具有相同数量的输出通道 c。每个序列的第一层有一个步幅 s,所有其他层使用步幅 1。所有空间卷积都使用 3 × 3 卷积核。扩展因子 t 始终应用于输入大小,如表 1 中所述。
除第一层外,我们在整个网络中使用恒定的扩展率。实验中,我们发现在 5 到 10 之间的扩展率会导致几乎相同的性能曲线,较小的网络在扩展率稍低的情况下效果更好,而较大的网络在扩展率较大的情况下性能稍好。
所有的主要实验,使用 6 的扩展因子应用于输入张量的大小。例如,对于采用 64 通道输入张量并产生具有 128 通道的张量的瓶颈层,则中间扩展层为 64·6 = 384 通道。
权衡超参数。如在[27]中,我们通过使用输入图像分辨率和宽度乘数作为可调超参数来定制我们的架构以适应不同的性能点,可以根据所需的精度/性能权衡进行调整。我们的主网络(宽度乘法器 1,224 × 224)的计算成本为 3 亿次乘加,并使用了 340 万个参数。我们探讨了性能权衡,输入分辨率从 96 到 224,宽度乘数从 0.35 到 1.4。网络计算成本范围从 7 乘加到 585M MAdds,而模型大小在 1.7M 和 6.9M 参数之间变化。
与 [27] 的一个小的实现差异是,对于小于 1 的乘数,我们将宽度乘数应用于除最后一个卷积层之外的所有层。这提高了较小模型的性能。
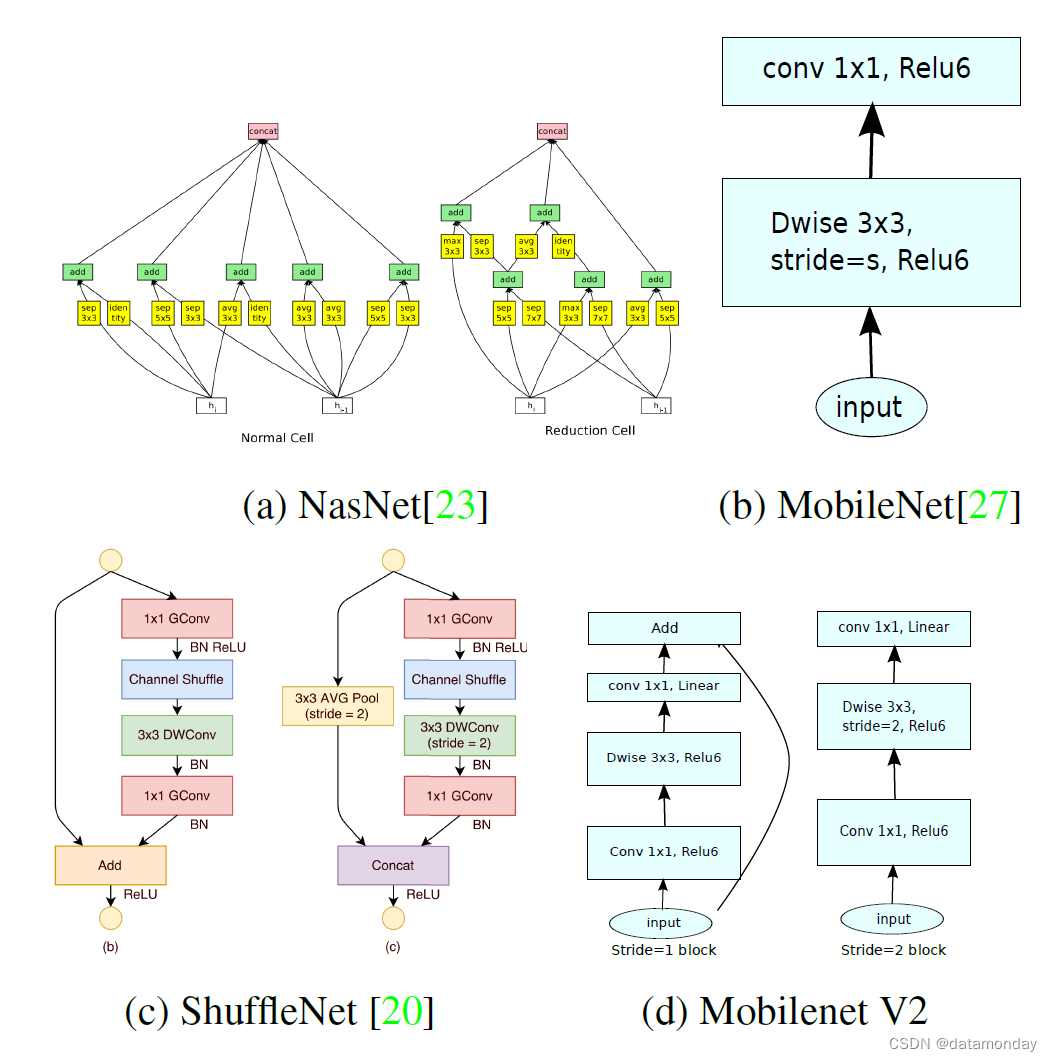
图4:不同架构的卷积块比较。ShuffleNet 使用组卷积[20]和混洗,它还使用传统的残差方法,其中内部块比输出窄。ShuffleNet 和 NasNet 插图来自各自的论文。
5. Implementation Notes
5.1. Memory efficient inference
倒置的残差瓶颈层允许实现特别高效的内存,这对于移动应用程序非常重要。使用例如 TensorFlow[31] 或 Caffe [32] 的标准高效推理实现构建了一个有向无环计算超图 G,由表示操作的边和表示中间计算张量的节点组成。计划计算以最小化需要存储在内存中的张量总数。在最一般的情况下,它搜索所有合理的计算顺序 Σ(G) 并选择最小化的
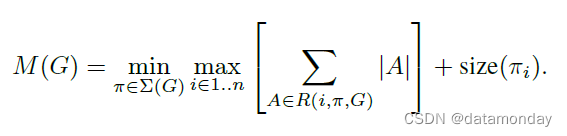
其中 R(i, π, G) 是连接到任何 πi … πn 个节点的中间张量的列表,|A|表示张量 A 的大小,size(i) 是操作 i 期间内部存储所需的内存总量。
对于仅具有平凡并行结构(例如残差连接)的图,只有一个非平凡的可行计算顺序,因此可以简化计算图 G 上推理所需的内存总量和界限:
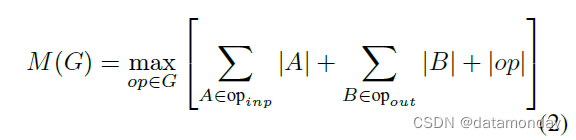
重申一下,内存量只是所有操作中组合输入和输出的最大总大小。如果将瓶颈残差块视为单个操作(并将内部卷积视为一次性张量),则内存总量将由瓶颈张量的大小决定,而不是由张量的大小决定在瓶颈内部(并且更大)。
瓶颈残差块。图 3b 所示的瓶颈块算子 F(x) 可以表示为三个算子的组合 F ( x ) = [ A ◦ N ◦ B ] x F(x) = [A ◦ N ◦ B]x F(x)=[A◦N◦B]x,其中
- A 是线性变换 A : R s × s × k → R s × s × n A : R^{s×s×k} → R^{s×s×n} A:Rs×s×k→Rs×s×n
- N 是每个通道的非线性变换: N : R s × s × n → R s ′ × s ′ × n N : R^{s×s×n} → R^{s'×s'×n} N:Rs×s×n→Rs′×s′×n
- B 再次是到输出域的线性变换: B : R s ′ × s ′ × n → R s ′ × s ′ × k ′ B : R^{s'×s'×n} → R^{s'×s'×k'} B:Rs′×s′×n→Rs′×s′×k′
对于我们的网络 N = R e L U 6 ◦ d w i s e ◦ R e L U 6 N = ReLU6 ◦ dwise ◦ ReLU6 N=ReLU6◦dwise◦ReLU6,但结果适用于任何每通道转换。假设输入域的大小为 ∣ x ∣ |x| ∣x∣并且输出域的大小是 ∣ y ∣ |y| ∣y∣,那么计算 F ( X ) F(X) F(X) 所需的内存可以低至 ∣ s 2 k ∣ + ∣ s ′ 2 k ′ ∣ + O ( m a x ( s 2 ; s ′ 2 ) ) |s^2k| + |s'^2k'| + O(max(s^2; s'^2)) ∣s2k∣+∣s′2k′∣+O(max(s2;s′2))。
该算法基于这样一个事实,即内部张量 I 可以表示为 t 个张量的串联,每个张量的大小为 n/t,然后我们的函数可以表示为
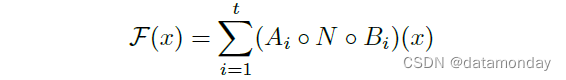
通过累积总和,只需要一个大小为 n/t 的中间块始终保存在内存中。使用 n = t,我们最终不得不始终只保留一个中间表示的通道。使我们能够使用此技巧的两个约束是(a)内部变换(包括非线性和深度方向)是每个通道的,以及(b)连续的非每个通道运算符具有输入大小与输出的显著比率。对于大多数传统的神经网络,这种技巧不会产生显着的改进。
我们注意到,使用 t 路分割计算 F(X) 所需的乘加运算符的数量与 t 无关,然而在现有实现中,我们发现用几个较小的矩阵乘法来替换一个矩阵乘法,会由于高速缓存未命中的增加而损害运行时性能。我们发现这种方法在 t 是 2 到 5 之间的一个小常数时最有帮助。它显着降低了内存需求,但仍然允许人们利用通过使用高度优化的矩阵乘法,并且卷积算子获得的大部分效率由深度学习框架提供。特殊的框架级优化是否会导致进一步的运行时改进还有待观察。
6. Experiments
6.1. ImageNet Classification
训练设置。我们使用 TensorFlow[31] 训练我们的模型。我们使用标准的 RMSPropOptimizer,衰减和动量都设置为 0.9。我们在每一层之后使用批量归一化,标准权重衰减设置为 0.00004。在 MobileNetV1[27] 设置之后,我们使用 0.045 的初始学习率和每个 epoch 0.98 的学习率衰减率。我们使用 16 个 GPU 异步工作器,批量大小为 96。
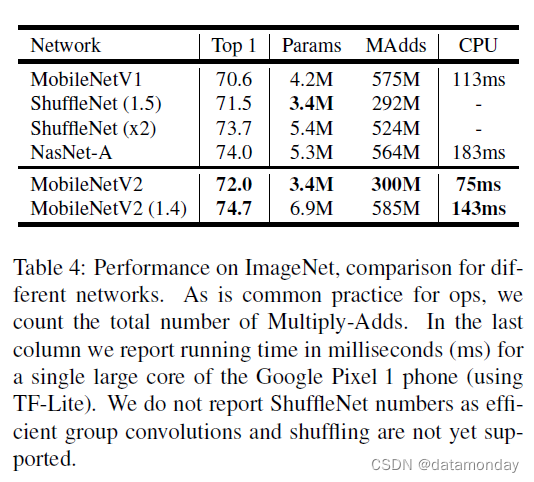
表 4:ImageNet 上的性能,不同网络的比较。作为操作的常见做法,我们计算乘加的总数。在最后一栏中,我们报告了 Google Pixel 1 手机(使用 TF-Lite)的单个大内核的运行时间(以毫秒 (ms) 为单位)。我们不报告 ShuffleNet 数字,因为尚不支持有效的组卷积和混洗。
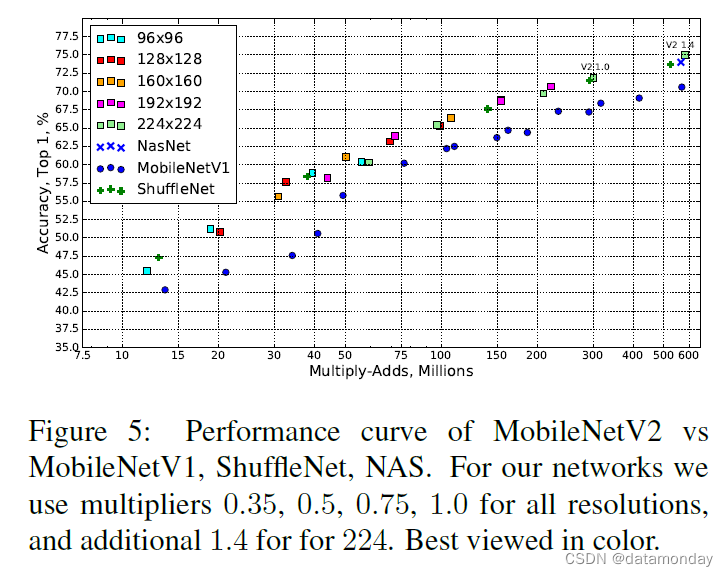
结果。我们将我们的网络与 MobileNetV1、ShuffleNet 和 NASNet-A 模型进行比较。一些选定模型的统计数据如表 4 所示,完整的性能图如图 5 所示。
6.2. Object Detection
我们在 COCO 数据集 [2] 上评估和比较 MobileNetV2 和 MobileNetV1 作为目标检测的特征提取器 [33] 与单次检测器 (SSD) [34] 的修改版本的性能。我们还将 YOLOv2 [35] 和原始 SSD(以 VGG-16 [6] 作为基础网络)作为基线进行了比较。我们没有将性能与其他架构进行比较,例如 Faster-RCNN [36] 和 RFCN [37],因为我们的重点是移动/实时模型。
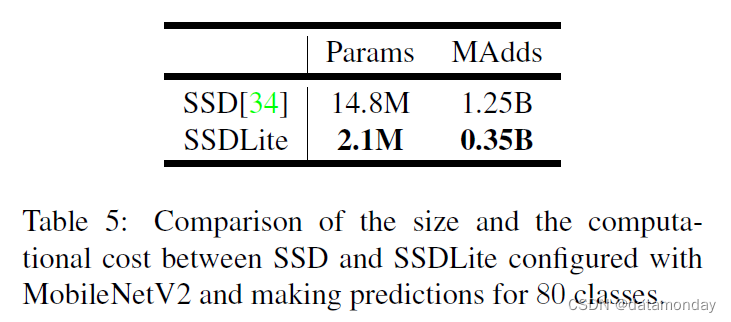
SSDLite:在本文中,我们介绍了常规 SSD 的移动友好型变体。我们用 SSD 预测层中的可分离卷积(深度后跟 1×1 投影)替换所有常规卷积。这种设计符合 MobileNets 的整体设计,并且被认为在计算上更加高效。我们将此修改后的版本称为 SSDLite。与常规 SSD 相比,SSDLite 显着减少了参数数量和计算成本,如表 5 所示。
对于 MobileNetV1,我们遵循 [33] 中的设置。对于 MobileNetV2,SSDLite 的第一层附加到第 15 层的扩展(输出步长为 16)。 SSDLite 的第二层和其余层附加在最后一层之上(输出步幅为 32)。此设置与 MobileNetV1 一致,因为所有层都附加到相同输出步幅的特征图上。
两种 MobileNet 模型都使用开源 TensorFlow 目标检测 API [38] 进行训练和评估。两种模型的输入分辨率均为 320 × 320。我们对 mAP(COCO 挑战指标)、参数数量和乘加数进行了基准测试和比较。结果如表 6 所示。MobileNetV2 SSDLite 不仅是最高效的模型,而且是三个模型中最准确的。值得注意的是,MobileNetV2 SSDLite 的效率提高了 20 倍,体积缩小了 10 倍,同时在 COCO 数据集上仍优于 YOLOv2。
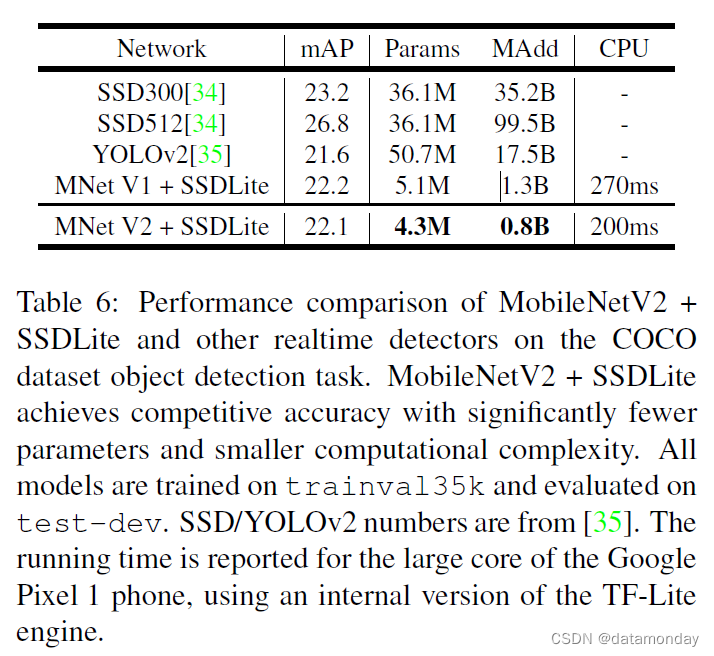
表 6:MobileNetV2 + SSDLite 与其他实时检测器在 COCO 数据集目标检测任务上的性能对比。 MobileNetV2 + SSDLite 以更少的参数和更小的计算复杂度实现了具有竞争力的准确性。所有模型都在 trainval35k 上训练并在 test-dev 上进行评估。 SSD/YOLOv2 数字来自 [35]。运行时间报告为 Google Pixel 1 手机的大核心,使用的是 TF-Lite 引擎的内部版本。
6.3. Semantic Segmentation
在本节中,我们将用作特征提取器的 MobileNetV1 和 MobileNetV2 模型与 DeepLabv3 [39] 进行移动语义分割任务的比较。 DeepLabv3 采用了 atrous 卷积 [40, 41, 42],这是一种显式控制计算特征图分辨率的强大工具,并构建了五个并行头,包括 (a) Atrous Spatial Pyramid Pooling module (ASPP) [43],其中包含三个 3 × 3具有不同开口率的卷积,(b)1×1卷积头,和(c)图像级特征[44]。
我们用输出步幅表示输入图像空间分辨率与最终输出分辨率的比率,这是通过适当地应用空洞卷积来控制的。对于语义分割,我们通常使用输出步幅 = 16 或 8 来获得更密集的特征图。我们在 PASCAL VOC 2012 数据集 [3] 上进行实验,使用来自 [45] 的额外注释图像和评估指标 mIOU。
为了构建移动模型,我们尝试了三种设计变体:(1) 不同的特征提取器,(2) 简化 DeepLabv3 头部以加快计算速度,以及 (3) 不同的推理策略以提高性能。我们的结果总结在表 7 中。
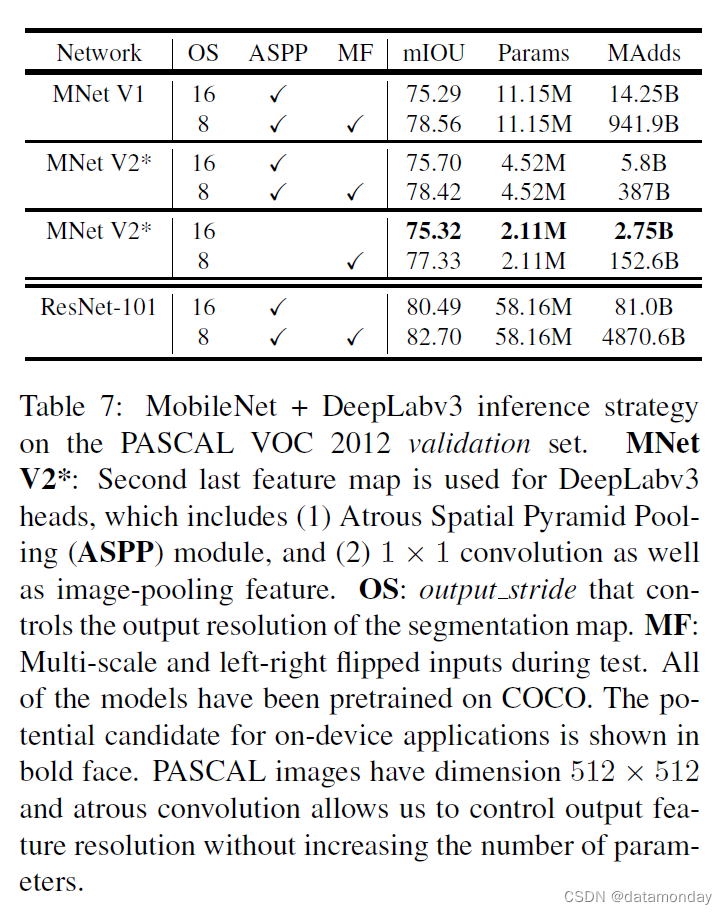
表 7:PASCAL VOC 2012 验证集上的 MobileNet + DeepLabv3 推理策略。 MNet V2*:倒数第二个特征图用于 DeepLabv3 头,包括 (1) Atrous Spatial Pyramid Pooling (ASPP) 模块,和 (2) 1 × 1 卷积以及图像池特征。 OS:输出步幅,控制分割图的输出分辨率。 MF:测试期间的多尺度和左右翻转输入。所有模型都在 COCO 上进行了预训练。设备端应用程序的潜在候选者以粗体显示。 PASCAL 图像的尺寸为 512 × 512,atrous 卷积允许我们在不增加参数数量的情况下控制输出特征分辨率。
我们观察到:(a) 推理策略,包括多尺度输入和添加左右翻转图像,显着增加了 MAdd,因此不适合设备上的应用程序,(b) 使用output stride = 16 比 output stride = 8 更有效,© MobileNetV1 已经是一个强大的特征提取器,只需要比 ResNet-101 [8] 少大约 4.9 - 5.7 倍的 MAdds(例如,mIOU:78.56 vs 82.70,以及MAdds:941.9B vs 4870.6B),(d)在 MobileNetV2 的倒数第二个特征图之上构建 DeepLabv3 头部比在原始最后一层特征图上更有效,因为倒数第二个特征图包含 320 个通道而不是 1280,通过这样做,我们获得了相似的性能,但所需的操作比 MobileNetV1 对应物少约 2.5 倍,并且(e)DeepLabv3 头计算成本很高,并且移除 ASPP 模块显着减少了 MAdds,只有轻微的性能e 退化。在表 7 的末尾,我们确定了设备端应用程序的潜在候选者(粗体),它达到 75.32% mIOU,并且只需要 2.75B MAdds。
6.4. Ablation study
反向残差连接。残差连接的重要性已被广泛研究 [8, 30, 46]。本文报告的新结果是,快捷连接瓶颈的性能优于连接扩展层的快捷方式(参见图 6b 进行比较)。
线性瓶颈的重要性。线性瓶颈模型严格来说不如具有非线性的模型强大,因为激活总是可以在线性状态下运行,并对偏差和缩放进行适当的更改。然而,我们在图 6a 中显示的实验表明线性瓶颈提高了性能,为非线性破坏低维空间中的信息提供了支持。
7. Conclusions and future work
我们描述了一个非常简单的网络架构,使我们能够构建一系列高效的移动模型。我们的基本架构单元具有使其特别适用于移动应用的几个特性。它允许非常节省内存的推理,并依赖于利用所有神经框架中存在的标准操作。
对于 ImageNet 数据集,我们的架构提高了广泛性能点的最新技术水平。
对于目标检测任务,我们的网络在准确性和模型复杂性方面都优于 COCO 数据集上最先进的实时检测器。值得注意的是,我们的架构与 SSDLite 检测模块相结合,计算量比 YOLOv2 少 20 倍,参数少 10 倍。
在理论方面:所提出的卷积块具有独特的属性,允许将网络表达能力(由扩展层编码)与其容量(由瓶颈输入编码)分开。探索这一点是未来研究的一个重要方向。
A. Bottleneck transformation
在本节中,我们研究算子 A ReLU(Bx) 的性质,其中 x ∈ Rn 表示一个 n 通道像素,B 是一个 m × n 矩阵,A 是一个 n × m 矩阵。我们认为,如果 m ≤ n,这种形式的变换只能以丢失信息为代价来利用非线性。相反,如果 n ≪ m n \ll m n≪m,这样的变换可以是高度非线性的,但仍然以高概率可逆(对于初始随机权重)。
首先,证明 ReLU 是位于其图像内部的任何点的恒等变换。
引理 1 令 S(X) = {ReLU(x)|x ∈ X}。如果 S(X) 的体积不为零,则内部 S(X) ⊆ X。
证明:令 S’ = 内部 ReLU(S)。首先我们注意到,如果 x ∈ S’,那么对于所有 i,xi > 0。确实,ReLU 的图像不包含负坐标的点,零值坐标的点不能是内部点。因此,对于每个 x ∈ S’,x = ReLU(x) 。
由此得出结论,对于交错的线性变换和 ReLU 算子的任意组合,如果它保留非零体积,则在这样的组合中保留的输入空间 X 的部分是线性变换,因此可能对深度网络的能力有较小的贡献。然而,这是一个相当薄弱的陈述。实际上,如果输入流形可以嵌入到 (n − 1) 维流形中(总共 n 维中),则引理是正确的,因为起始体积为 0。在下文中,我们展示了当输入流形的维度显着降低时,可以确保不会有信息丢失。
由于 ReLU(x) 非线性是将整个射线 x ≤ 0 映射到 0 的满射函数 (surjective function),因此在神经网络中使用这种非线性可能会导致信息丢失。一旦 ReLU 将输入流形的子集折叠为更小维度的输出,随后的网络层就无法再区分折叠的输入样本。在下文中,我们展示了具有足够大扩展层的瓶颈能够抵抗由 ReLU 激活函数的存在引起的信息丢失。
引理 2(ReLU 的可逆性) 考虑一个算子 ReLU(Bx),其中 B 是一个 m × n 矩阵,x ∈ Rn。令 y0 = ReLU(Bx0) 对于某个 x0 ∈ Rn,则方程 y0 = ReLU(Bx) 对 x 有唯一解当且仅当 y0 至少有 n 个非零值并且有 n 个线性独立的行B 对应于 y0 的非零坐标。
证明:将 y0 的非零坐标集合表示为 T 并令 yT 和 BT 是 y 和 B 对 T 定义的子空间的限制。如果 |T | < n,我们有 yT = BT x0,其中 BT 至少有一个解 x0 是欠定的,因此有无穷多个解。现在考虑 |T | 的情况。 ≥ n 且 BT 的秩为 n。假设有一个附加解 x1 6= x0 使得 y0 = ReLU(Bx1),那么我们有 yT = BT x0 = BT x1,除非 x0 = x1,否则不能满足。
这个引理的推论之一是如果 m ≫ n , m \gg n, m≫n,我们只需要 Bx 的一小部分值是正的,ReLU(Bx) 是可逆的。
引理 2 的约束可以针对真实网络和真实输入进行经验验证,因此我们可以确保信息确实得到了保留。我们进一步表明,关于初始化,我们可以确定这些约束以高概率得到满足。请注意,对于随机初始化,由于初始化对称性,引理 2 的条件得到满足。然而,即使对于经过训练的图,这些约束也可以通过在有效输入上运行网络并验证所有或大多数输入是否高于阈值来凭经验验证。在图 7 中,我们展示了此分布如何查找不同的 MobileNetV2 层。在第 0 步,激活模式集中在正通道的一半左右(如初始化对称性所预测的那样)。对于完全训练的网络,虽然标准差显着增长,但除两层外,其他所有层仍高于可逆阈值。我们相信对此进行进一步研究是有必要的,并且可能会对网络设计产生有益的见解。
定理 1 令 S 为 Rn 的紧致 n 维子流形。考虑由 m × n 矩阵 B ∈ B 参数化的从 Rn 到 Rm 的函数族 fB(x) = ReLU(Bx)。设 p(B) 是所有矩阵 B 的空间上满足的概率密度:
- 对于任何测量零子集 Z ⊂ B,P (Z) = 0;
- (对称条件)p(DB) = p(B) 对于任何 B ∈ B 和任何 m × m 对角矩阵 D,所有对角元素为 +1 或 -1。
然后,被 fB 折叠为低维流形的 S 子集的平均 n 体积为
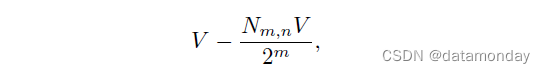
其中 V = vol S 和
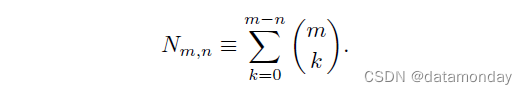
证明:对于任何具有 s k ∈ − 1 , + 1 s_k ∈ {−1, +1} sk∈−1,+1 的 σ = ( s 1 , . . . , s m ) σ = (s_1, . . . , s_m) σ=(s1,...,sm),令 Q σ = x ∈ R m ∣ x i s i > 0 Q_σ = {x ∈ R^m|x_is_i > 0} Qσ=x∈Rm∣xisi>0 是 R m R^m Rm 中的对应象限。对于任何 n n n 维子流形 Γ ⊂ R m Γ ⊂ R^m Γ⊂Rm,如果 σ σ σ 至少具有 n n n 个正值,ReLU 充当 Γ ∩ Q σ Γ ∩ Q_σ Γ∩Qσ 上的双射 (bijection),否则收缩 Γ ∩ Q σ Γ ∩ Q_σ Γ∩Qσ。还要注意, B S BS BS 与 R m / ( ∪ σ Q σ ) R^m/(∪_σQ_σ) Rm/(∪σQσ) 的交集几乎肯定是 (n − 1) 维的。因此,通过将 ReLU 应用于 BS,未折叠的 S 的平均 n 体积由下式给出:
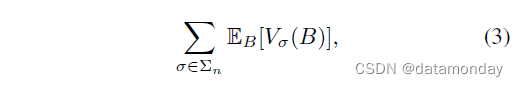
其中 Σ n = ( s 1 , . . . , s m ) ∣ ∑ k θ ( s k ) ≥ n Σ_n = {(s1, . . . , sm)| \sum_k θ(s_k) ≥ n} Σn=(s1,...,sm)∣∑kθ(sk)≥n, θ θ θ 是阶跃函数, V σ ( B ) V_σ(B) Vσ(B) 是由 B 映射到 Qσ 的 S 的最大子集的体积。

因此 ReLU(Bx) 执行非线性变换,同时以高概率保留信息。
我们讨论了瓶颈如何防止流形崩溃,但增加瓶颈扩展的大小也可能使网络能够表示更复杂的功能。根据 [47] 的主要结果,可以证明,例如,对于任何整数 L ≥ 1 和 p > 1,都存在一个由 L 个 ReLU 层组成的网络,每个层包含 n 个神经元和一个大小为 pn 的瓶颈扩展,使得它将 pnL 输入体积(与 [ 0 , 1 ] n [0, 1]^n [0,1]n 线性同构)映射到相同的输出区域 [ 0 , 1 ] n [0, 1]^n [0,1]n。因此,附加到网络输出的任何复杂的可能非线性函数都将有效地计算 p n L p^{nL} pnL 输入线性区域的函数值。
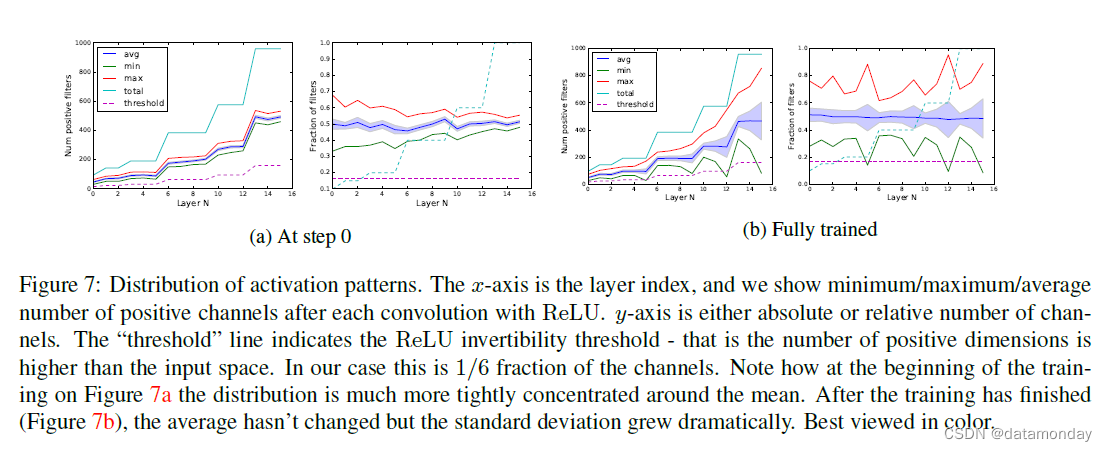
图 7:激活模式的分布。 x 轴是层索引,我们显示每次使用 ReLU 卷积后正通道的最小/最大/平均数。 y 轴是绝对或相对通道数。 “阈值”线表示 ReLU 可逆性阈值 - 即正维数高于输入空间。在我们的例子中,这是通道的 1/6。请注意,在图 7a 的训练开始时,分布更紧密地集中在均值附近。训练完成后(图 7b),平均值没有变化,但标准差急剧增加。最好以彩色观看。
B. Semantic segmentation visualization results

图 8:PASCAL VOC 2012 验证集上的 MobileNetv2 语义分割可视化结果。操作系统:输出步幅。 S:单刻度输入。 MS+F:多尺度输入,尺度 = {0.5, 0.75, 1, 1.25, 1.5, 1.75} 和左右翻转输入。使用输出步幅 = 16 和单个输入比例 = 1 可以在 FLOPS 和准确度之间取得良好的折衷。